Elasticsearch — сортируем выдачу руками
Благодаря своей гибкости и масштабируемости, сегодня Elasticsearch находит применение во все более широком круге задач — от поиска до аналитики. Однако есть ряд вопросов, с которыми Elasticsearch не справится в одиночку.Например, ваша поисковая выдача меняется от пользователя к пользователю. И сортировка, основанная только на данных самого документа (TF/IDF или сортировки по любым полям документа), не дает нужного результата. При этом в поисковой выдаче интернет-магазина вы хотите показать товар, который пользователь уже смотрел на первых позициях.
Другой пример. Параметр, влияющий на сортировку, меняется слишком часто: Elasticsearch построен на базе Lucene и использует append-only хранилище, обновление документов фактически отсутствует. Каждое изменение документа приводит к его переиндексации и влечет периодическое перестроение сегментов хранилища. Иными словами, если вы хотите отсортировать выдачу по количеству просмотров документа на сайте, то самое тупое, что можно сделать, — это записывать каждый просмотр в Elasticsearch. И здесь, похоже, назрел вопрос использования внешнего хранилища мета-информации, используемой для сортировки документов.
В одном из своих проектов мы используем Elasticsearch в качестве основного хранилища. Это позволяет нам масштабировать систему под десятки миллионов документов без лишних телодвижений и при этом сохранять отклик, измеряемый десятками миллисекунд. Основу нашего проекта составляют документы (странички сайтов, посты в пабликах, GIF или Youtube-ролики. Каждый документ представляет собой страничку с распарсенным контентом. Документы имеют мета-информацию: оригинальный url, теги и т.д. Elasticsearch позволяет нам делать очень быстрые пересечения для построения фидов по интересам (несколько сайтов в одном фиде), а также использовать функциональность Google Alert, в рамках которой можно создать фид по любому словосочетанию.
Проблемы начались, когда мы решили добавить в наше приложение возможности голосований и сортировки документы по популярности. Как мы уже говорили, не стоит писать такие часто меняющиеся данные в ES.
Мы храним данные о голосованиях в Redis. Это очень быстрое хранилище, идеально подходящее для подобного рода задач. Нам необходимо отсортировать документы, хранящиеся в Elasticsearch (выборка по запросу), по данным, которые хранятся в Redis (голоса пользователей, количество просмотров документа). Начиная с версии 0.90.4, Elasticsearch предоставляет механизм Function Score Query (далее FSQ). Это довольно гибкое решение. В общем, FSQ разрешает «вручную» вычислять вес документа, используемый при сортировке выдачи.Нам достаточно того, что FSQ позволяет:
установить callback (java), на вход которого поступает очередной документ из выборки; присвоить переданному на вход документу вес (поле _score), равное результату вычисленному в callback-е. Следует заметить, что для установки callback необходимо написать плагин Elasticsearch. Здесь я приведу упрощенный код плагина, по которому проще будет понять основную идею: public class AbacusPlugin extends AbstractPlugin { @Override public String name () { return «myScore.plugin»; } @Override public String description () { return «My Score Plugin»; } // called by Elasticsearch in a initialization phase (reflection magic) public void onModule (ScriptModule module) { module.registerScript ( «myScore», // NOTE: script name MyScriptFactory.class ); } /* * Script Factory should implement NativeScriptFactory */ public static class MyScriptFactory implements NativeScriptFactory { // Some Score Calculation Service private final MyScoreService service;
public MyScriptFactory () { service = new MyScoreService (); }
@Override
public ExecutableScript newScript (
@Nullable Map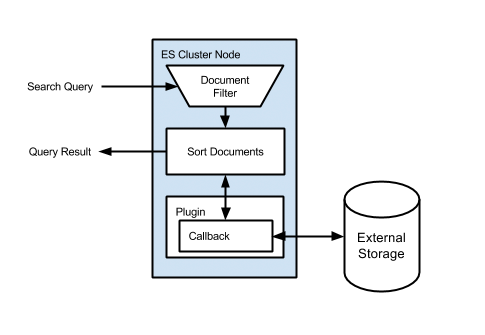
Как видно, сначала исполняется любой стандартный запрос ElastiSearch, затем для каждого документа исполняется скрипт Custom Score. Вот как выглядит запрос:
{ «function_score»: { «boost_mode»: «replace», // to ignore score «query»: …, // some query «script_score»: { «lang»: «native», «script»: «myScore» // script name «params»: { // script params (optional) «param1»: 3.14, «param2»: «foo» }, }, } } Вроде бы, все довольно просто. Запрос пришел на одну из нод ES, ушел на шарды и другие ноды. Каждый шард посчитал и выполнил запрос, сбегал за дополнительными данными в Redis и вернул результаты ноде инициатору. Но есть подводные камни. Обратим внимание на «для каждого документа исполняется скрипт Custom Score». Что это значит? Например, ваш query в Elasticsearch нашел один миллион документов. После этого для каждого такого документа надо сходить в Redis и взять оттуда количество голосов. Даже если мы успеваем обернуться за 1ms, получается 16 минут. На самом деле, конечно, меньше, потому что запрос пошел параллельно с нескольких шардов, но все равно цифра будет внушительная. Для каждого случая решение этой проблемы будет своим. Например, если речь идет о кастомной сортировке и выдаче для конкретного пользователя, то получив единожды всю мета-информацию о пользователе, для каждого следующего документа мы уже берем ее из памяти локально. Это будет работать очень быстро.Но в нашем случае для каждого документа есть своя мета-информация (количество голосов). Здесь сработает подход, когда мы разносим горячие и холодные данные. Горячие данные хранятся в Redis, холодные сбрасываются в ES. Вот как это работает: по прошествии 3 суток в с момента публикации статья практически перестает получать голоса, и их можно сбросить в ES и переиндексировать документ со значением накопившихся голосов. А для свежих статей мы берем голоса из Redis.
При этом если старый документ все же получает новые голоса, они не теряются, а накапливаются в кеше и периодически все равно уходят на индексацию в ES. В этой схеме существует небольшой момент времени, когда старые документы сортируются с необновленными голосами, но нас это устраивает.
Также если вы смотрели код плагина для расчета score, то обратили внимание, что он синхронный, и выполняется по одному документу (нельзя сформировать batch запрос в redis). Однако есть довольно сложные техники, когда можно считать score батчами, и делать запрос в redis не на каждый документ, а формируя пакеты, например, по 1000 документов.
Описанное решение, конечно, гораздо сложнее того, что можно получить одним запросом к MySQL. Однако мы используем Elasticsearch в качестве основного хранилища из-за необходимого функционала поиска и больших масштабов, и в таком случае подобные подходы оправданы и работают.Посмотреть, как работает система, можно здесь: https://play.google.com/store/apps/details? id=com.indxnews
