Экстремальная миграция на PostgreSQL: без остановки, потерь и тестирования

Буквально месяц назад в Яндекс.Деньгах завершился переезд сервиса профилей пользователей с Oracle на PostgreSQL. Так что теперь у нас есть опробованное решение по миграции больших объемов данных без потерь и остановки использующего их сервиса.
Под катом я расскажу подробнее о том, как все происходило, зачем мы выбрали для миграции SymmetricDS и почему без «ручных» усилий все равно не обошлось. Поделюсь также некоторыми наработками по вспомогательному коду для миграции.
Для первой миграции и обкатки решения выбрали сервис, обслуживающий пользовательские профили. К профилю относится история платежей, избранное, напоминалки и прочие подобные вещи — все важное, но для работы системы не критичное. База данных у нас без встроенной логики, поэтому перевезти на новую платформу нужно было только сами данные и секвенции.
Итак, через 3 месяца профили пользователей должны работать без Oracle
В связи с надвигающимися релизами по другим проектам решили завершить перенос за три месяца. Команда миграции состояла из 4 человек, зато это были разработчики уровня Senior и специалисты DBA. Чтобы небольшая команда смогла справиться в сжатый срок, под проект искали максимально автоматизированное решение: без написания кода миграции данных, ручной сборки схемы БД и т.п. База содержит около 50 таблиц, поэтому вероятность человеческой ошибки особенно высока при ручных преобразованиях.
Обычно такие миграции выполняются с остановкой сервиса — в нерабочее время. Но в Яндекс.Деньгах платежи проходят круглосуточно, поэтому останавливать систему ради внутренних «оптимизаций» было нельзя. Фактически для этого компонента бизнес согласовал нам приостановку на одну-две минуты, без потери данных.
В поисках идеального инструмента
Квартальный срок проекта не оставлял простора для изобретения собственных квазивелосипедов. Поэтому путем мозгового штурма мы собрали и отсеяли список подходящих продуктов для миграции:
Oracle GoldenGate — может показаться, что это та самая серебряная пуля. По крайней мере, до момента ознакомления с ценой.
SymmetricDS — есть миграция схемы, она будет создана или обновлена при регистрации узла PostgreSQL в мастер-узле Oracle. Есть возможность трансформировать данные при выгрузке или загрузке, используя BASH, Java или SQL.
Full Convert — умеет мигрировать схему и данные, но ограничены возможности кастомизации, нет изменяемых трансформеров (код для изменения данных при миграции).
Oracle to PostgreSQL Migration — переносит схему, данные, внешние ключи, индексы. Полуавтоматическая репликация, трансформации нет, но можно задать соответствие типов в разных БД.
ESF Database Migration Toolkit — переносит все то же, что и Oracle to PostgreSQL Migration. Данные передаются в пакетном режиме, возможность миграции в несколько потоков отсутствует.
Ora2Pg — переносит схему, данные, внешние ключи, индексы, возможна миграция в несколько потоков. Из минусов: медленный перенос таблиц с типами blob/clob (около 200 записей/сек), нет трансформатора.
- SQLData Tool — мигрирует только схему, ограничены возможности кастомизации.
Остальные представленные на рынке продукты или уже заброшены разработчиками, или не имеют развитой поддержки в сообществе.
В результате выбрали Ora2Pg для переноса схемы БД и SymmetricDS для миграции данных. Вообще, последний предназначен больше для синхронизации разных СУБД, чем для переноса данных. Но в нашем случае он позволил обеспечить миграцию без остановки сервисов.
Тысяча и одна мелочь для миграции
Когда обкатывали миграцию на копии продакшн-базы, то нашли целый набор «особенностей» и странностей в миграционном решении. PostgreSQL не корректно отрабатывал некоторые запросы, которые без проблем проходили в Oracle. Например, SELECT * вызывал ошибку и остановку работы всего зависящего от БД сервиса. Вообще, такие запросы — дурной тон, на самом деле они были другие, а эти я привел просто как дозволенный пример. Оказалось, что это скорее проблема Java-драйвера, поэтому на момент реализации проекта было проще не использовать проблемные запросы. Позже этот баг исправили.
Были сложности и с транзакциями при установленном флаге AutoCommit-OFF. В PostgreSQL код падал, если при его выполнении предварительно не была открыта транзакция. Oracle вел себя иначе: транзакция откатывалась или завершалась кодом, который пришёл в этот же поток выполнения. Решение для PostgreSQL — написать код, который бы проверял наличие явно открытой транзакции для всех запросов на изменение данных.
При выполнении запросов сервис пользовательских профилей не указывал порядок сортировки выводимых значений (ORDER BY), так как в Oracle отсутствие признака означает вывод в хронологическом порядке. И на этом мы поскользнулись в PostgreSQL, который выводил результаты запроса вразнобой — причесали код так, чтобы ORDER BY был везде.

Интересный нюанс был и с композитными транзакциями, которые изменяли данные как в исходной БД Oracle, так и в перенесенном на PostgreSQL экземпляре. Чтобы в обеих базах были одинаковые значения, наша команда разработала специальный менеджер транзакций. Он синхронно открывал и закрывал транзакции в обеих СУБД. Если в таких транзакциях возникали ошибки, то их уже приходилось решать вручную.
И понеслось
Миграция данных была поэтапной — по заранее утвержденному списку из 50 таблиц. Переключение решили сделать на уровне каждой таблицы в базе, что позволило достичь высокой гибкости и декомпозиции процесса. То есть в определенный момент, после переноса данных, для таблицы выставлялся специальный флаг, по которому сервис Я.Денег переключался на экземпляр данных в PostgreSQL.
Для удачной миграции Oracle-PostgreSQL важно заранее составить план, чтобы никакая досадная мелочь не забылась. Такой план был и у нас, вот он под спойлером:
Что нужно сделать разработчику:
получить DDL таблицы на PostgreSQL;
выделить интерфейс для DAO-класса;
создать DAO-класс для работы с PostgreSQL;
создать флаг для переключения работы с Oracle DAO на PostgreSQL DAO;
написать тесты на новое DAO с покрытием от 80% (очень помогает избежать ошибок в синтаксисе SQL запросов использование механизма jOOQ). Больше — лучше;
обкатать миграцию на тестовом стенде;
выполнить миграции на приемочном стенде, убедиться в прохождении приемочных тестов;
- Релиз изменений на боевую среду.
Методичка для DBA:
получить от разработчика DDL мигрируемой таблицы в БД PostgreSQL, создать таблицу и все связанные с ней сущности;
уточнить у разработчика способ миграции — нужна ли первичная прогрузка старых данных и синхронизация новых записей?
Если данных много, то по каким критериям можно ограничить объем первичной загрузки;настроить SymmetricDS на синхронизацию таблицы;
в одной транзакции запустить первичную загрузку (если требуется) и синхронизацию новых записей;
периодически проверять статус загрузки и синхронизации;
- непосредственно перед переключением сервисов на PostgreSQL передвинуть секвенции в таблице назначения для запаса по первичным ключам.
Что нужно не забыть ответственному за процесс:
убедиться, что на продакшене поддерживается работа с PostgreSQL для конкретной таблицы;
проверить, что на продакшене успешно выполнена первичная загрузка данных и включена синхронизация новых записей;
попросить DBA передвинуть секвенции в PostgreSQL;
переключить один экземпляр сервиса на работу с PostgreSQL, убедиться, что нет ошибок в логах и логике работы сервиса;
переключить оставшиеся экземпляры сервиса;
- после полного переключения попросить DBA переименовать мигрированные таблицы в Oracle. Внимательно следить за ошибками в системе — какая-то «забытая» логика сервиса может пытаться по-прежнему работать с Oracle.
В процессе миграции часть из 50 таблиц работала на Oracle, другая — на PostgreSQL. Здесь и пригодился SymmetricDS, который мигрировал данные из Oracle в PostgreSQL и тем самым обеспечивал консистентность как для логики с перенесенными таблицами, так и для тех, что еще работали по старой схеме.
После переноса данных в сервисе устанавливался флажок «работай с PostgreSQL» для каждой конкретной таблицы, и запросы переходили к новой СУБД. Сначала переключение проверялось на dev-стенде, потом на приемочном. Если ОК — переключение на продакшн и переименование таблицы в Oracle (чтобы понять, не используется ли еще где старая таблица).
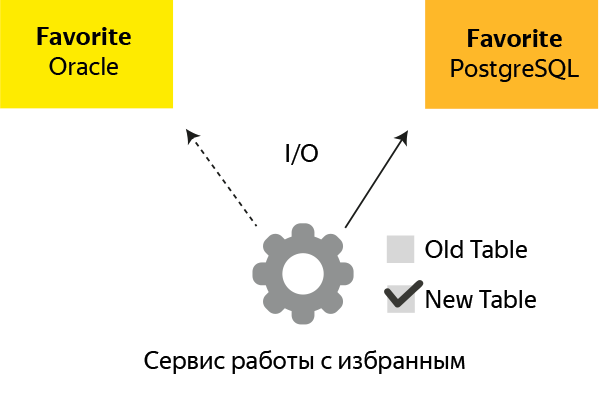
На схеме суть идеи: после создания дубликата базы на PostgreSQL в сервисе устанавливается флаг new db, после чего все обращения идут к новой базе.
Но самым сложным было правильно подобрать момент переключения. Фактически у нас было 3 варианта миграции, в зависимости от критичности и сложности таблицы:
Перенос таблицы целиком с последующим переключением. Вариант подходил в тех случаях, когда часть запросов можно было потерять (пользователя можно попросить нажать кнопку еще раз, или сработает автоматическое продолжение операции).
На уровне дата центра (ДЦ, всего их 2). Способ для переноса критичных таблиц, при котором сначала переводим на PostgreSQL первый ЦОД, а в процессе его включения отключаем второй (с Oracle). На время старта — остановки Oracle и PostgreSQL могли работать параллельно, поэтому тут и пригодились механизмы синхронизации и переключения данных. Простоя в работе сервисов при этом не было.
- По методике «остаточного дожатия». Оставляем 2 экземпляра: Oracle для обработки опоздавших к переключению запросов и новый PostgreSQL. Новые задачи обрабатывались в новой базе, а старые удалялись после выполнения в оставшемся Oracle. Так переезжали очереди базы — автоплатежи, напоминалки и т.п.
Не обошлось и без сложностей. При первичном формировании схемы БД под PostgreSQL конвертер выдал не на 100% готовый вариант, что и ожидалось, в общем-то. Пришлось вручную менять некоторые типы колонок, исправлять секвенции и разбивать схему по таблицам и индексам. Впрочем, последнее — это уже для порядка и общей эстетики.
Чуть позже оказалось, что SymmetricDS не синхронизирует таблицы объемом более 150 ГБ. Поэтому пришлось засесть за код и создать обходной вариант переноса на такие случаи.
Впрочем, серебряной пули и тут не получилось. SymmetricDS не переносил поля CLOB\BLOB, если из-за них был превышен суммарный объем таблицы, поэтому пришлось писать ручные очереди миграции. Столкнулись и с совсем экзотическими случаями, когда миграция с Oracle на PostgreSQL приводила к резкому проседанию производительности. Ничего не оставалось, кроме как вручную разбирать каждый отдельный случай. Например, для одной таблицы пришлось выделить поле CLOB в отдельную таблицу, перенести ее на SSD-диск и читать это поле только при необходимости.
Так как нужно было поддерживать одновременно активными старые и новые экземпляры БД, для новых мы сделали запас по секвенциям, чтобы не происходило наслоения и попыток переноса в PostgreSQL дублирующихся ключей.
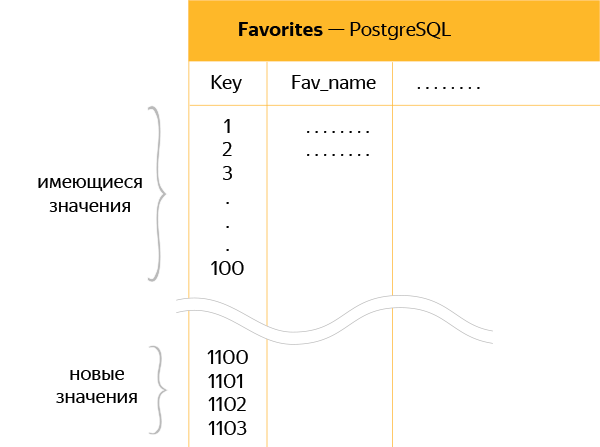
На схеме — схематичное изображение новой таблицы в PostgreSQL с «отступом» между старыми и новыми данными в 1000 ключей.
То есть если в таблице последний ключ был 100, то при переносе к этому значению добавлялась еще 1000, чтобы SymmetricDS мог свободно синхронизировать ключи 101, 102 и все остальные без перезаписи новых данных.
Финишная ленточка
За плановый квартал наша маленькая команда перенесла 80% таблиц на PostgreSQL. Оставшиеся 20% — это большие таблицы (в среднем более 150 ГБ), включая сборную таблицу с объемными полями CLOB\BLOB. Все это пришлось доделывать вручную следующие 1,5 месяца. Тем не менее связка SymmetricDS и Ora2Pg сделала большую часть рутинной работы, что и требовалось по условиям задачи. Наша команда разработки изрядно пополнила за этот проект внутреннюю копилку «грабель», часть из которых на момент выхода статьи наверняка осталась за кадром.
Но от Яндекс.Денег уже готовится десант на грядущую конференцию PG Days»17, которая пройдет в Санкт-Петербурге. Приходите на расширенный доклад и готовьте каверзные вопросы.
Впрочем, самые животрепещущие темы предлагаю поднять прямо тут, в комментариях. Очень любопытно почитать о вашем опыте миграции и, может быть, о том, что мы упустили из виду.
В репозитории Яндекс.Денег вы найдете немного кода описанных в статье решений:
Исходники Transaction Manager
- Код класса проверки наличия транзакции.
Комментарии (4)
20 апреля 2017 в 17:04
0↑
↓
зарплату DBA Oracle после этого урезали или нет? Плюшки какие от этого переезда вам? Dimmentio
Dimmentio
20 апреля 2017 в 17:59
0↑
↓
Зарплату, конечно, не урезали. В этом нет смысла, наши DBA активно участвуют в миграции и осваивают PSQL. А вот про плюшки можно долго говорить. Их много. Во-первых, это банальная экономия. Oracle очень дорогой и в стоимости лицензий, и в поддержке. Тарифицируется в долларах, скидки дает в единицах процентов. Во-вторых, для нас крайне актуально легкость в поднятии новых баз с учетом микро-сервисной модели, обилия тестовых стендов и необходимости, порой, иметь локальную БД на разработческом ноутбуке. Тут с PSQL все сильно проще. В-третьих, за счет лицензии open source и сообщества к PSQL достаточно быстро делают необходимый в администрировании и эксплуатации инструментарий. И он так же бесплатный.
20 апреля 2017 в 17:28
0↑
↓
А для каких данных использовали blob’ы, да еще и в таком количестве? chemtech
chemtech
20 апреля 2017 в 18:14
0↑
↓
Кроме бага pgjdbc и выкладывания oracle-to-postgres-migration-utils улучшали какие -либо opensource решения? (отправляли ли патчи, заводили ли баги)
