Эксплуатация Ceph: флаги для управления восстановлением и перемещением данных

Продолжаем рассказывать об эксплуатации Ceph. Сегодня поговорим о процессе восстановления данных и флагах, которые позволяют его контролировать: norebalance, nobackfill и norecover.
Статья подготовлена на основе лекции Александра Руденко, ведущего инженера в группе разработки «Облака КРОК». Лекция доступна в рамках курса по Ceph в «Слёрме».
Для полного понимания рекомендуем сначала прочесть статью о флагах для управления состояниями OSD.
rebuild и rebalance в Ceph
Если вы работали с СХД, то сталкивались с процессами rebuild и rebalance, где rebuild — это восстановление утерянных копий данных, а rebalance — перемещение существующих копий данных с места на место по тем или иным причинам.
Обычно эти процессы имеют разные приоритеты. rebuild отдают большую полосу пропускания, его меньше лимитируют, потому что важно быстро восстановить утерянные данные. rebalance зажимают, так как в процессе перемещения недостатка в данных нет.
В Ceph процессы rebuild и rebalance обозначены не так чётко: одна placement group может быть сразу в 6 статусах. Но с точки зрения восстановления и перемещения данных имеют значение два состояния объектов: degraded и misplaced.

Если объект в состоянии degraded, это означает, что какая-то placement group не имеет копий. Например, есть пул с тройной репликацией: у placement group три копии, одна из них в состоянии primary, другие синхронно получают от неё репликацию. Если какая-то из этих копий будет утеряна, объекты окажутся в состоянии degraded. Восстановление degraded объектов — это процесс rebuild с точки зрения общепринятых условностей.
Напомню, что placement group в Ceph представлена несколькими placement groups на разных OSD. Состояние misplaced означает, что объекты перемещаются с места на место. Количество копий их placement group правильное, они все синхронны, но где-то создана новая placement group, которая должна заменить одну из существующих копий и ждёт окончания бэкфиллинга. Когда он закончится, старую копию placement group Ceph удалит. Это процесс rebalance в общем понимании.
Глядя на строки degraded и misplaced, вы понимаете, сколько у вас данных деградирует и нуждается в процессе rebuild, и сколько данных нуждается в перемещении с целью rebalance.
Останавливать процессы восстановления и перемещения данных позволяют следующие флаги:
- nobackfill и norecover,
- norebalance.
nobackfill и norecover
nobackfill и norecover делают одно и то же. В коде они отключают процесс recover немного по-разному, но результат один: полная остановка recovery io.
Посмотрим на примере.
Устанавливаем какой-то из флагов:
ceph osd set norecoverТеперь остановим одну из OSD и отправим её в out, чтобы запустился процесс recovery.
systemctl stop ceph-osd@0ceph osd out 0Проверяем результат и видим recovery, но это на этапе пиринга placement group. Он относится к recovery io, но по факту ничего не восстанавливает.

Прошло некоторое время и этот процесс закончился.
У нас есть объекты в состоянии degraded и множество статусов placement group, но они заморожены, потому что recovery остановлен.
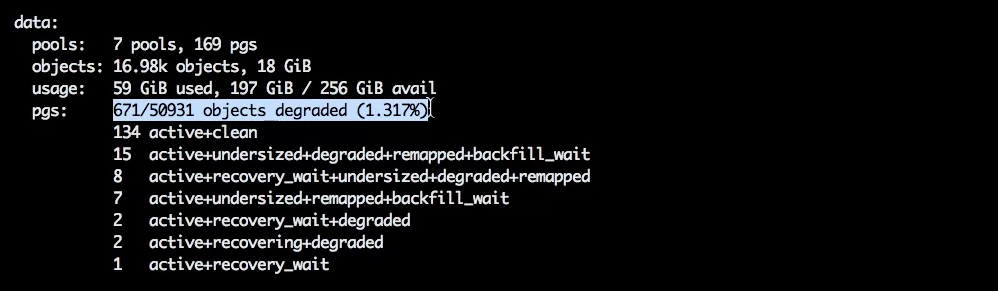
Надо заметить, что флаг norecover работает не совсем так, как noout (о нём было в предыдущей статье).
Когда мы ставим noout, мы всё ещё можем вручную отправить OSD в out. Здесь не так: мы ставим norecover, тем самым останавливаем идущий прямо сейчас процесс recovery и блокируем любой возможный в будущем recovery.
Флаг norecover блокирует любой вид перемещения данных, будь то с целью восстановления объектов, будь то с целью перемещения неправильно лежащих объектов, которые сейчас в состоянии misplaced.
Теперь снимем флаг:
ceph osd unset norecoverКак результат: пошёл полноценный процесс recovery io.

Если установить флаг nobackfill, то recovery io так же прекратится. Эти флаги работают одинаково.
norebalance
Флаг norebalance отличается. Он позволяет процессу recovery io идти только в случае, если placement group находится в состоянии degraded.
Устанавливаем флаг norebalance:
Флаг установили, но процесс recovery всё равно идёт, потому что есть placement group и объекты в состоянии degraded.
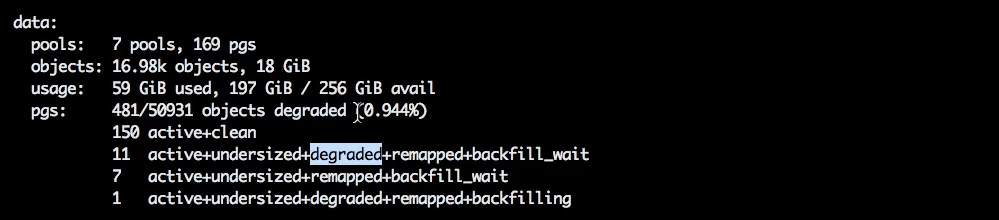
Покажу ещё кое-что.
Вдобавок к установленному флагу norebalance снова установим флаг norecover (флаги можно ставить вместе, они друг другу не противоречат):

После этого выведем в out одну из OSD (под номером 1).
ceph osd out 1
Напомню, к этому моменту одна OSD уже отправлена в out и при этом выключена. Её данные недоступны, это degraded состояние для placement group и объектов.
При этом OSD 1 мы просто отправили в out. Она сейчас отдаёт с себя placement group другим OSD. Появился второй статус — misplaced.
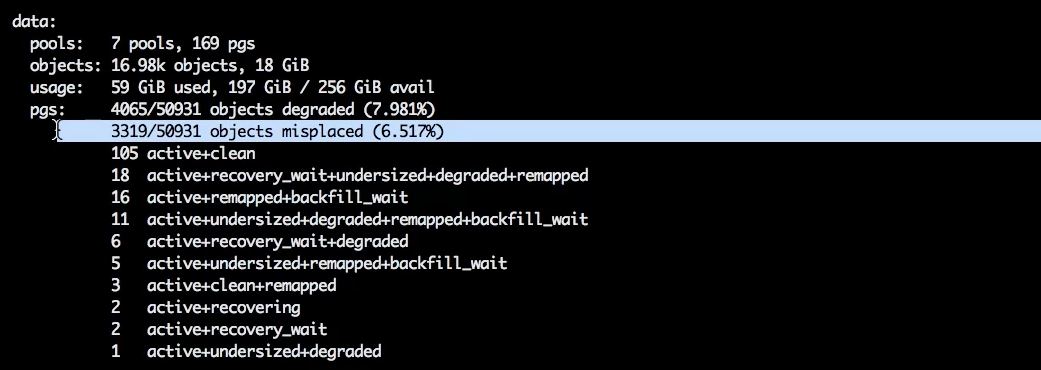
Теперь уберём флаг norecover и оставим только norebalance.
Таким образом мы заблокировали процессы переноса объектов в статусе misplaced, но разрешили процессы восстановления placement group в статусе degraded.
Это тот случай, когда нужно отдать максимальный приоритет именно восстановлению degraded объектов.
Случаи применения флагов norecover и norebalance
Общее замечание: не нужно ставить эти флаги просто для перезагрузки сервера. Если хотите перезапустить сервер, используйте флаг noout.
Авария. Бывают ситуации, когда по какой-то причине отключается целая стойка или отдельный сервер. Как и положено, Ceph обнаруживает потерю копий placement group и начинает восстанавливать их на других хостах. Если объём потерянных данных по-настоящему большой (а он может исчисляться сотнями терабайт), то процесс восстановления окажется губительным для всего кластера. В таком случае разумно установить флаг norecover, чтобы на некоторое время остановить recovery io.
Важно понимать, что речь идёт о ситуации, когда потеряна одна копия или домен данных. При этом все placement group находятся в состоянии active, то есть принимают запись и чтение.
Установив флаг norecover, администратор выясняет масштабы аварии. Если у стойки отошло питание или серверу требуется перезагрузка, то в течение короткого времени потерянные данные можно будет поднять, не гоняя их лишний раз по кластеру. Если проблемы серьёзнее и сервер действительно отказал, то флаг norecover нужно снять и позволить Ceph восстановить потерянные копии.
При этом флаг norebalance можно оставить, чтобы дать максимальный приоритет процессам восстановления данных. Особенно это актуально, если в момент потери хоста rebalance уже шёл (например, после добавления нескольких новых хостов).
Высокая нагрузка. Само recovery io может быть очень высокое, и из-за этого возникают проблемы: появляются slow ops, падает производительность. Тогда можно временно приостановить всё recovery io с помощью флага norecover, либо остановить перемещение объектов misplaced флагом norebalance. Опять же, до выяснения причин.
pause
Флаг pause по сути останавливает клиентское io. Никто из клиентов не сможет ни читать, ни писать из пулов Ceph.
ceph osd set pause
Обратите внимание, что Ceph не важно, это восстановление degraded объектов или перемещение misplaced объектов, — всё io, которое занимается этим, называется recovery. Когда говорят «остановить recovery io», имеют в виду остановить всё вместе.
После установки флага pause останавливается всё, кроме recovery io. Даже MDS не может закоммитить свои данные в пулы или считать данные.

Но восстановление продолжает идти.

Если у вас есть публичный пользовательский сервис, то устанавливать этот флаг нельзя. Его установка сродни катастрофе для бизнеса.
Но есть среды (например, на предприятиях), где можно сказать пользователям, что сервис не будет доступен для обслуживания 3–5–10 часов.
Это может быть полезно при тяжелой DDoS-атаке. Когда какое-нибудь io разрушает кластер, а вы не можете легитимно его отфильтровать или остановить. Чтобы разобраться в проблеме, можно остановить вообще всё с помощью флага pause.
Ещё один вариант использования pause: у вас пострадала значительная часть кластера, и вы хотели бы восстановить её как можно скорее, отдав максимальный приоритет recovery io и заблокировав пользователей, чтобы они не занимали полосу и не замедляли процесс.
Применять осторожно
В заключение скажу: все описанные флаги можно использовать только при внимательном контроле за кластером. Нельзя оставлять их и уходить спать. Они нужны для блокирования естественных процессов, протекающих в Ceph, а сами по себе эти процессы правильные. Система способна сама себя восстанавливать и балансировать. Поэтому блокировать естественные состояния Ceph можно только находясь у компьютера и контролируя процесс.
