Эффективные методы сжатия данных при тренировке нейросетей. Лекция в Яндексе
Не так давно в Яндекс приезжал Геннадий Пехименко — профессор Университета Торонто и PhD Университета Карнеги-Меллон. Он прочитал лекцию об алгоритмах кодирования, которые позволяют обходить проблему ограничения памяти GPU при обучении глубоких нейронных сетей.
— Я вхожу в несколько групп Университета Торонто. Одна из них — Computer Systems and Networking Group. Есть еще моя собственная группа — EcoSystem Group. Как видно из названий групп, я не специалист непосредственно в машинном обучении. Но нейронные сети сейчас достаточно популярны, и людям, которые занимаются компьютерной архитектурой и сетями, компьютерными системами, приходится сталкиваться с этими приложениями на постоянной основе. Поэтому последние полтора-два года этой темой я тоже плотно занимаюсь.
Расскажу, как правильно делать компрессии в памяти, в процессорном кэше. Это была тема моей докторской диссертации в Америке, в Карнеги — Меллон. И это поможет понять, с какими проблемами мы столкнулись, когда хотели применить подобные механизмы для других приложений, таких как нейронные сети.
Одной из главных проблем в компьютерной архитектуре является то, что мы хотим получить высокопроизводительные системы — графические карточки, сопроцессоры, телефоны, ноутбуки — с хорошими параметрами энергоэффективности.
На данный момент несложно получить достаточно высокую производительность, если не ограничивать себя памятью. Можно получить и экзофлоп-компьютер, если нужно. Вопрос в том, какое количество электричества придется для этого потратить. Поэтому одна из главных проблем — получать хорошие результаты по производительности с имеющимися ресурсами и при этом не нарушать баланс энергоэффективности.
Одна из главных проблем на пути энергоэффективности заключается в том, что у многих ключевых приложений, используемых и в облачных вычислениях, и на различных мобильных устройствах, есть серьезные затраты по данным — как по пересылке, так и по хранению. Это и современные БД, и графические карточки, и конечно, машинное обучение. Все это требует очень серьезных ресурсов со всех уровней стека, от ядра вплоть до сетевых ресурсов.
Вот одна из ключевых проблем, которые возникают, когда приходится проводить различные оптимизации: ты можешь один вид ресурса фактически подменять другим. Раньше очень часто в компьютерной архитектуре сами вычислительные ресурсы, такие как сложение, умножение, арифметические операции, были очень дорогими. Однако эта ситуация изменилась в последние годы, и это связано с тем, что развитие ядра процессоров продвигалось значительно быстрее, чем скорость доступа к памяти.
В результате одна арифметическая операция сложения в плане энергии будет стоить вам приблизительно 1 пикоджоуль. При этом одна операция с плавающей точкой, floating point, будет стоить приблизительно 20 пикоджоулей. Если ты захочешь прочитать 4 или 8 байт из памяти, это будет тебе стоить по крайней мере на два порядка больше по энергии. И это существенная проблема. Любая попытка работы с памятью стоит достаточно дорого. Причем неважно, про какие устройства мы говорим. Ситуация одинаковая что для мобильных телефонов, что для крупных кластеров и суперкомпьютеров.
Из этого следует, что очень многие ресурсы, которые есть даже у текущего мобильного телефона, не могут быть в полной мере использованы по энергетическим ресурсам. Если взять современный телефон, неважно, Android или iPhone, имеющуюся пропускную способность между памятью и ядром мы можем использовать в пике и только приблизительно на 50%. Если мы этого не сделаем, телефон будет перегреваться, а вернее никто ему перегреваться не даст — будет понижена частота шины при общении между памятью и ядром, и производительность тоже упадет.
Многие ресурсы сейчас невозможно использовать, если не применять хитрые оптимизации.
Один из способов борьбы с нехваткой различных ресурсов на разных уровнях — это сжатие данных. Это не новая оптимизация, ее успешно применяли и для сетей, и для дисков, все мы пользовались различными утилитами. Скажем, на Linux многие пользовались утилитами gzip или BZip2. Все эти утилиты очень успешно применялись на этом уровне. Применяются обычно алгоритмы или на базе Huffman encoding или Lempel-Ziv.
Все эти алгоритмы обычно требуют большого словаря, и проблема, что их алгоритмы очень последовательны, и не очень ложатся на современную архитектуру, очень параллельную. Если мы посмотрим на существующее железо, компрессия на уровне памяти, кеша или процессора практически не применялась, по крайней мере, до некоторых из наших первых работ пять лет назад.
Я расскажу, почему так произошло, и что можно сделать, чтобы компрессия была доступна на различных уровнях, то есть сжатие непосредственно в кеше. Cache compression — имеется в виду, что сжатие происходит непосредственно в железе, то есть меняется часть логики самого процессорного кеша. Вкратце расскажу, какие у этого бонусы. Расскажу про компрессию в памяти, какие проблемы там. Кажется, что это одно и то же, но заимплементировать эффективно компрессию в памяти — совсем другие, не такие, как в кеше. Расскажу про совместную работу с компанией NVidia, где мы сделали Bandwidth Compression в реальном железе для современных GPU, и оптимизация, что мы сделали, есть в последнем поколении GPU карточек — Volt. И расскажу про совсем радикальную оптимизацию, когда исполнение происходит напрямую на сжатых данных без декомпрессии вообще.
Несколько слов о сжатии в кеше. Это была статья на конференции PACT в 2012 году, и работа была совместно с компанией Intel. Чтобы было понятно, какая основная проблема, если ты хочешь превратить твой 2 МБ или 4 МБ процессорный кеш в 4 МБ или 8 МБ. Ты сделал L-компрессию, и в чем же проблема?
Грубо говоря, когда у тебя происходит операция обращения к памяти, если мы говорим про x86 архитектуру, load или store в память, то если данных нет на регистрах, то мы идем в кеш первого уровня. Обычно это три-четыре такта на современном процессоре. Если данные есть, они идут на CPU обратно. Если их нет, то запрос в память идет дальше по иерархии, доходит в L2-кеш.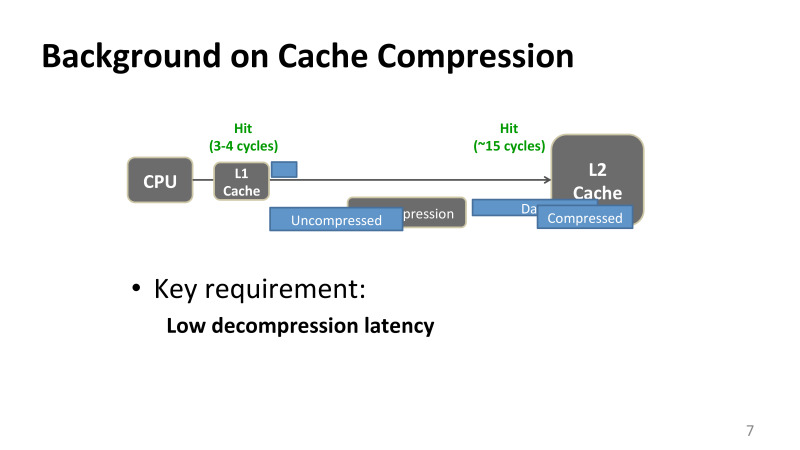
L2-кеш на большинстве интеловских процессорах 15–20 тактов, в зависимости от размера кеша. И дальше данные обычно едут обратно, если были найдены в L2-кеше, если ты не пошел в память. Данные идут и на процессор сразу, и в L1-кеш, сохраняются, если вдруг ты продолжаешь эти данные переиспользовать, чтобы они были ближе процессору.
Проблема в том, что если данные сжаты, то неважно, как ты оптимизируешь процесс компрессии, декомпрессия всегда на критическом пути запуска. Если раньше обращение в кеш второго уровня занимало 15 тактов, то любая задержка, связанная с декомпрессией, добавляется в задержку твоего запроса. И это ограничение правдиво практически для всех применений компрессии, и в памяти, и когда мы применяем для реальных приложений, таких как для тренировки нейронных сетей, декомпрессия всегда на критическом пути, и ее задержки, время на ее исполнение очень критично.
Что это означает для нас? Если вы понимаете, что задержки в кеше на уровне 15 циклов, декомпрессия должна быть очень оптимизированной. Мы можем себе позволить всего несколько процессорных тактов. Для понимания того, насколько это мало, один плюсик занимает порядка двух тактов, одна такая простая операция. То есть ничего сверхсложного ты сделать не можешь.
Во многом из-за этого Intel в какой-то момент остановился на разработке компрессия кеша. У них была целая группа, которая там занималась, они в 2005–2006 году разработали алгоритм, который давал декомпрессию порядка 5 тактов. Эта задержка увеличилась приблизительно на 30%, но кеш становился почти в два раза больше. Тем не менее их дизайнеры посмотрели на большинство приложений и сказали, что это слишком затратно.
Когда я начал работать над этой темой в 2011 году, они сказали, что если ты сможешь сделать чего-то за 1–2 такта, то это можно будет сделать в реальном железе, попробовать.
Я пробовал разные алгоритмы, и одна из причин, почему не получилось использовать алгоритмы, которые уже имелись в литературе, это то, что все они были сделаны изначально в софте. В софте другие ограничения, люди используют различные словари и тому подобные техники. Если эти техники пытаться сделать в реальном железе, они достаточно медленно работают. IBM сделал алгоритм Lempel-Ziv полностью такой, как в gzip используется, полностью в железе, и декомпрессия занимала 64 такта. Понятно, в кеше ты не будешь такое применять, только в памяти.
Я попытался поменять стратегию. Вместо того, чтобы пытаться оптимизировать софтверные алгоритмы, я решил посмотреть, какие реально данные хранятся в кеше, и попытаться сделать алгоритм, который будет хорошо работать для этих данных.
Я увидел, что парадоксально много нулей, от 20% до 30%. Если вы возьмете большой пакет приложений от Intel, там 200 разных приложений, которые люди используют для вычислений — очень много нулей. Это инициализация, это матрицы с большим количеством нулей, это нулевые указатели. Причин для этого много.
Очень часто есть повторяющиеся значения. В каком-то небольшом участке памяти, в кеше, могут повторяться очень похожие значения. Это, например, и если вы работаете с графикой, у вас куча пикселей, и если у вас часть картинки с одинаковыми цветами, то у вас все пиксели, подряд идущие, будут одинаковые. Кроме того, narrow values, однобайтовые и двухбайтовые значения, которые хранятся в 2, 4 и 8 байтах. Почему так происходит и чья эта ошибка? Откуда такая избыточность?
Избыточность связана с тем, как мы программируем код. Используем какой-то язык, например, С++. Если мы хотим выделить память под какой-то объект, допустим, под целый массив, представьте, что в массиве мы храним статистику о каких-то событиях, и эти события могут быть как очень частыми, скажем, миллиарды, так и единичные. Например, обращение в память с какой-то конкретной инструкцией. Большинство инструкций в память не обращается, но некоторые могут обращаться миллиарды раз за время запуска.
Программист вынужден выделять массив восьмибайтовых чисел, потому что в худшем случае у него целочисленные значения могут принимать крупные значения. Однако это избыточно. Многие из этих значений на самом деле не нужны, и там будет куча нулей неполных, но часть впереди идущих нулей.
Кроме того у нас много других значений, которые тоже обладают разными типами избыточности. Например, указатели. Все, кто когда-то отлаживал код и смотрел на указатели, можно заметить, что они и меняются достаточно крупно. Но если у тебя указателей приблизительно одна область памяти, то большая часть впереди идущих бит будет одними и теми же. Этот тип избыточности тоже налицо.
Я увидел много типов избыточности. Первый вопрос — насколько их много? 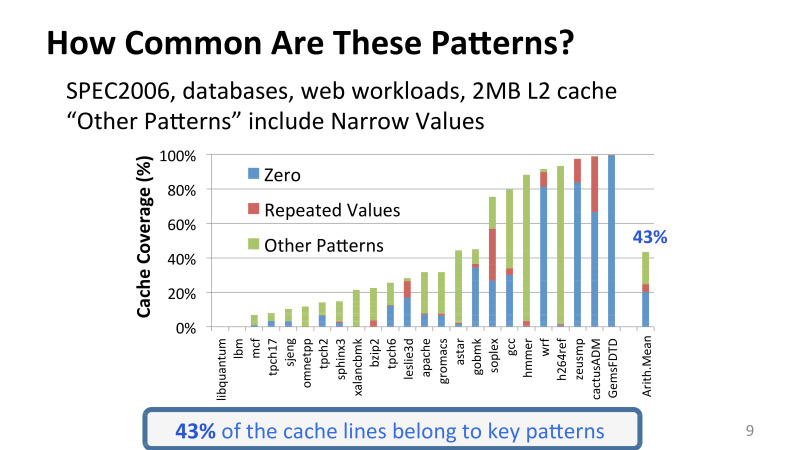
Здесь эксперимент, в котором я брал периодически данные из кеша второго уровня, сохранял снепшот этого кеша и смотрел, какое количество там нулей, повторяющихся значений. На оси Х различные приложения из пакета SPEC2006, который используется активно в компьютерной архитектуре, а также другие разные приложения от Intel — это и БД, и различные web workflow, такие как сервер Apachi, например. И здесь предположение, что это 2-мегабайтовый L2-кеш.
Можно заметить, что есть большая вариативность между избыточностью в разных приложениях, но даже эти очень простые паттерны встречаются достаточно часто. Только они покрывают 43% всех cache lines, все данных, что хранятся в кеше.
Можно придумать что-нибудь достаточно простое, что покроет эти и, может, какие-то другие паттерны, и даст нам хорошую производительность по компрессии.
Однако вопрос в том, что же роднит эти паттерны? Придется ли мне делать какой-то алгоритм компрессии, который будет работать специфично для каждого из этих паттернов или можно сделать что-то общее?
Общей была идея наблюдения. Все эти значения, они могут быть и большие, и маленькие, между ними очень маленькая разница. Грубо говоря, динамический диапазон значений в каждой конкретной линии кеша очень маленький. И можно представить значения, хранящиеся в кеше, например 32-байтовую линию кеша можно представить просто с помощью Base+Delta Encoding.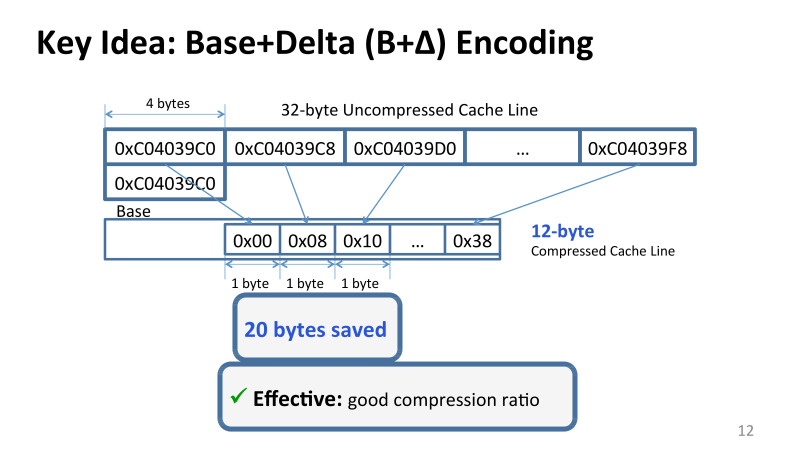
Взять, например, первое значение за базу, а все остальные представить как смещение от этой базы. И поскольку значения друг от друга отличаются в большинстве случаев не сильно, то наша дельта помещается в один байт, и вместо 32 или 64 байтов мы можем обойтись всего 12 байтами, и сохранить порядка 20 байт места.
Не буду рассказывать обо всех деталях, как имплементировать это в реальном железе. Мы сделали реальный прототип, написали на Verilog прототип, погоняли его на современных FPGA, с Intel поговорили по поводу имплементации. Можно сделать алгоритм, основанный на этой идее, который будет требовать в декомпрессии всего один-два такта. Этот алгоритм применим, и он дает и хорошую компрессию… 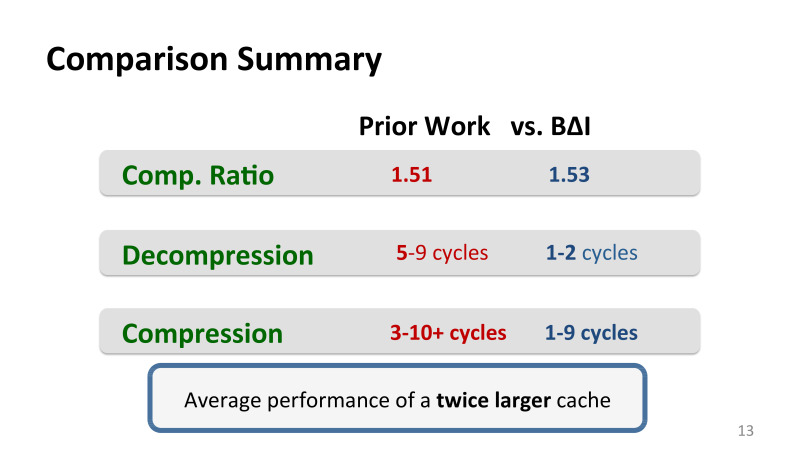
Лучшие предыдущие работы, которые применялись в кеше, давали порядка 50% дополнительного места. Это не чистая компрессия — она может дать намного больше — это реальный бонус эффективной компрессии, то есть насколько кеш выглядит больше для пользователей. Тут еще всякие проблемы с фрагментацией и так далее, которые нужно решать.
Компрессия у нас на уровне лучших предыдущих механизмов, которые были у Intel, но главный выигрыш в середине слайда — это декомпрессия. Предыдущие алгоритмы, у них лучшая декомпрессия была 5–9 тактов. Нам удалось сделать за 1–2 такта, при этом компрессия у нас тоже достаточно эффективная.
Алгоритмы такого рода можно делать в реальном железе и применять в кеше, например, в памяти.
Эффект от применения такой оптимизации в кеше ведет к тому, что кеш выглядит для пользователя часто почти в два раза больше по эффективности. Что это значит? Если посмотреть на современный процессор, на фотографии, там самих ядер почти нет. Там бóльшую часть места занимают процессорные кеши — 40–50% запросто и у IBM, и у Intel. На самом деле Intel не может просто взять и удвоить кеш, там просто нет места для большего количества кеша. И такие оптимизации, которые стоят всего несколько процентов от самого ядра, конечно, очень интересны.
Мы работали с различными оптимизациями во второй работе, о которой сегодня не буду рассказывать, о том, как же работать с такими кешами, у которых теперь cache lines могут быть различного размера. Все эти проблемы были успешно решены.
Хочу рассказать о нашей третьей работе, которая тоже была сделана с Intel, о том как сжимать память.
Какие там проблемы? 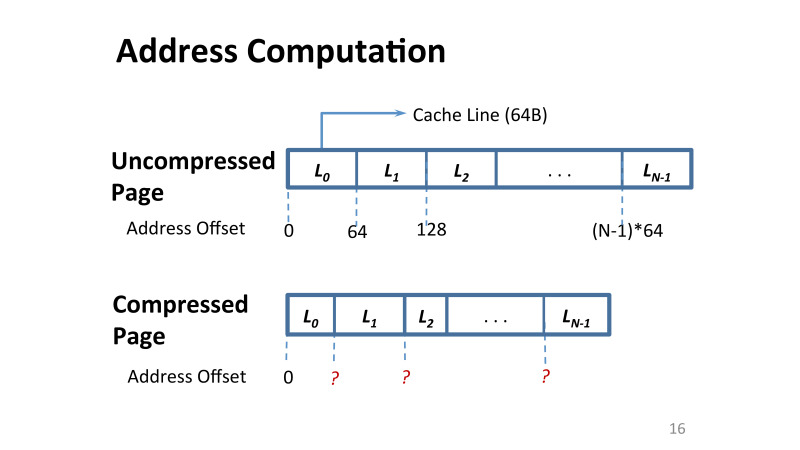
Основная проблема, что если в Linux или Windows у меня есть страница памяти 4 Кб, то для того, чтобы ее сжать, нужно решить следующую проблему: нужно решить проблему того, как изменятся адреса данных на этой странице. Изначально у тебя есть 4 КБ, и в ней каждая cache line тоже 64 байта. И смещение любой линии кеша внутри этой страницы памяти найти тривиально: берешь 64 и умножаешь на нужное тебе смещение.
Однако если ты применяешь компрессию, каждая линия теперь потенциально различного размера. И если тебе сейчас в кеш нужно читать из памяти какую-то страницу, этих смещений у тебя нет.
Можно сказать, что можно их где-то сохранить. А где их сохранить? Либо снова в памяти, либо в кеше. Но если ты хочешь для каждой памяти сохранить все смещения, у тебя никакого кеша не хватит, тебе нужны ресурсы порядка сотен МБ, чтобы обслужить всю память. Ты не можешь сохранить эти данные в чипе, а в памяти ты не хочешь их хранить, потому что каждое обращение к памяти — это теперь будет несколько обращений в память. Вначале ты будешь идти за метаданными, а потом за реальными данными.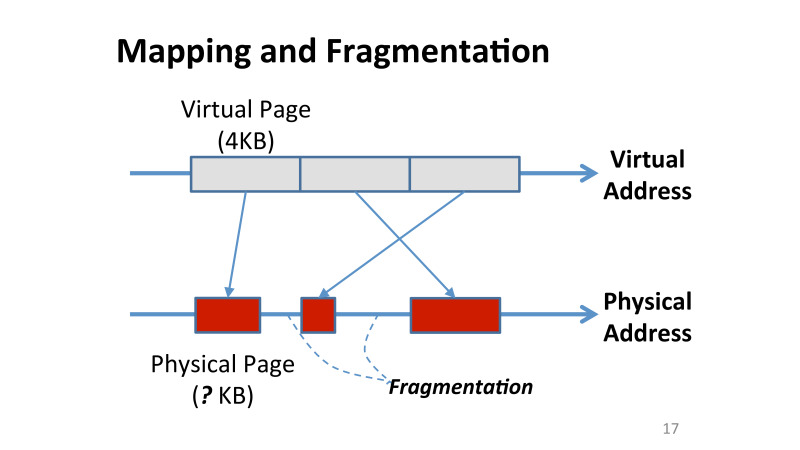
Вторая проблема, с которой все сталкивались, когда работали с ОС, это фрагментация данных. Здесь она становится экстремально сложной, потому что каждая страница занимает тоже различное место в памяти. При этом в виртуальном адресном пространстве все страницы по-прежнему 4 Кб, но после компрессии они все занимают совершенно разные размеры. И это проблема, как же теперь с этим пустым место работать. ОС не в курсе, что мы разрешили страницы сделать меньшего размера, она просто не видит этих фрагментированных кусков. Просто так, ничего не поменяв, мы не получим бонусы от компрессии.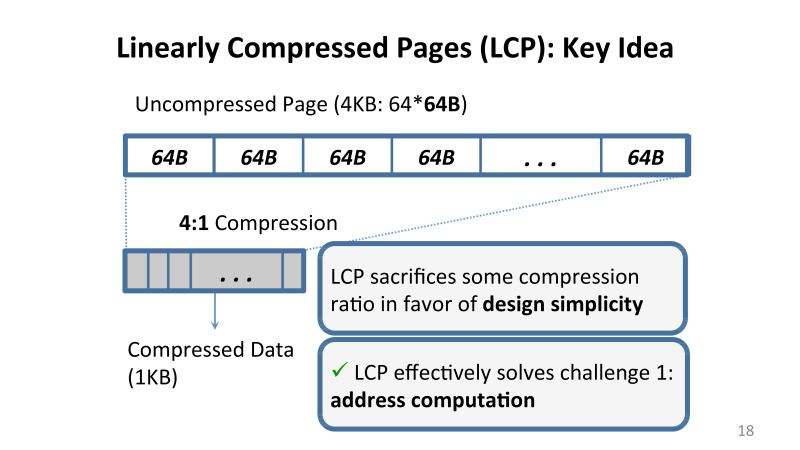
Что мы предложили для решения этой проблемы? Сжатие с использованием линейного коэффициента. Мы наложили набор определенных ограничений, которые подробно описаны в статье, но суть сводится к тому, что если я применяю компрессию для памяти, я применяю такой алгоритм, который гарантирует, что в каждой cache line на этой странице либо сжимается с определенным коэффициентом, допустим, 4 к 1, 3 к 1 или не сжимается вовсе.
Мы теряем потенциально что-то в плане сжатия данных, потому что мы налагаем дополнительные ограничения, но при этом главный бонус в тмо, что дизайн очень прост, его можно реализовать, что мы успешно делали, например, в Linux.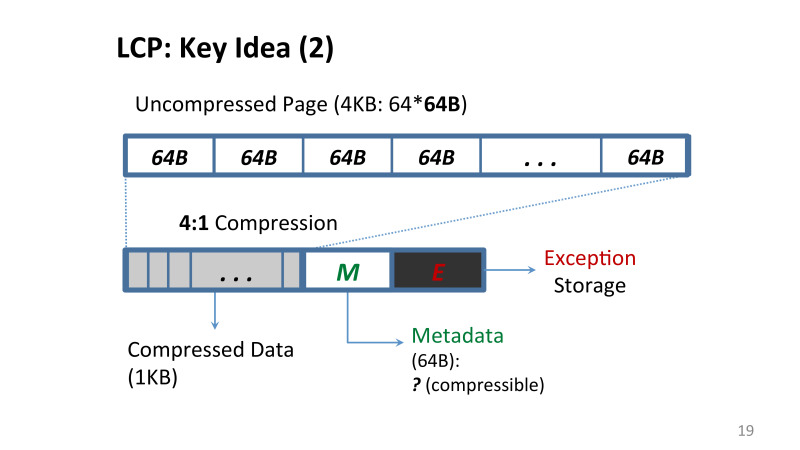
Linearly Compressed Pages (LCP), техника, что мы предложили, справляется с главной проблемой, что теперь адреса всех данных находятся достаточно просто. У нас есть небольшой блок метаданных, который хранится на этой же странице, и есть либо оригинальные данные, которые хранятся в сжатом виде, либо так называемый exception storage, там хранятся cache lines, которые мы не смогли сжать таким способом.
Основываясь на этих идеях, нам удалось получить и хорошее сжатие данных, и самое главное, я сравниваю с лучшими предыдущими работами, которые были сделаны в основном IBM, у них тоже были хорошие алгоритмы для сжатия.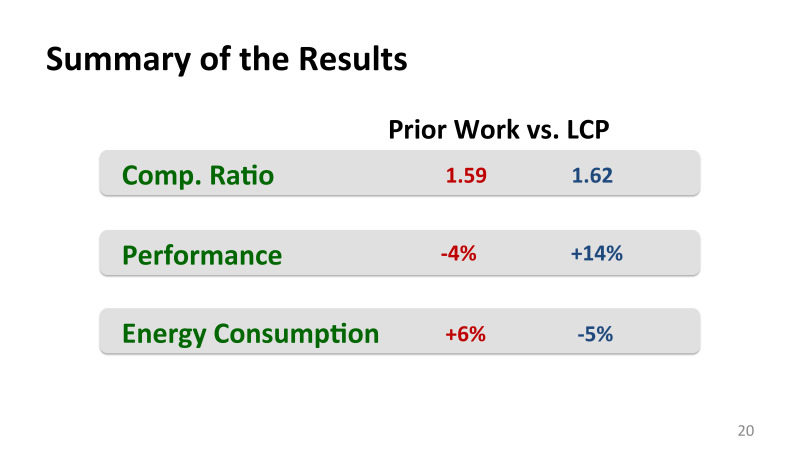
У нас компрессия не была особо лучше, чем у них, но самое главное, мы получили больше памяти, не платя за это дополнительную производительность. Грубо говоря, они получили больше память, но за это у них была потеря производительности, пусть небольшая, но была. И потеря по энергоэффективности. А нам удалось в плюсе получить все, мы получили и производительность лучше, и более низкие энергозатраты.
Вкратце о последней работе, что есть в реальном железе. Это наша работа с Nvidia. Проблема была в энергоэффективности при транспортировке данных по каналам связи из памяти в чип. В графических карточках памяти самой намного меньше, но намного больше пропускная способность этой памяти, в 5–6 раз запросто на большинстве графических карточек. Потому что многим графическим приложениям требуется сумасшедший объем этой bandwidth, чтобы эффективно обрабатывать большие массивы данных.
Проблема, с которой столкнулась Nvidia, когда я там делал свою стажировку в 2014 году, была связана с тем, что они заимплементировали компрессию в реальном железе, и она практически на всех приложениях давала хорошие бонусы. Но проблема была в том, что на некоторых приложениях вдруг наблюдался следующий эффект: вдруг включался такой механизм, который называется DVFS, который замечал, что транспортировка памяти начинает тратить сумасшедшее количество энергоресурсов, и чтобы эту проблему победить, есть определенный переключатель на канале связи, который если видит, что энергопотребление превышает допустимые пороги, то надо повышать частоту передачи данных.
Частота понижается — эти проводки, которыми соединена память с чипом, охлаждаются. Проблема в том, что когда ты понижаешь частоту, у тебя падает скорость передачи. Компрессия в итоге оказывала негативное влияние на производительность. Было понятно, что это как-то связано с компрессией, но это случалось не всегда, и непонятно, как с этим бороться. С этой проблемой они пришли в отдел исследований Nvidia к одному из моих менторов, с которым эту проблему исследовали.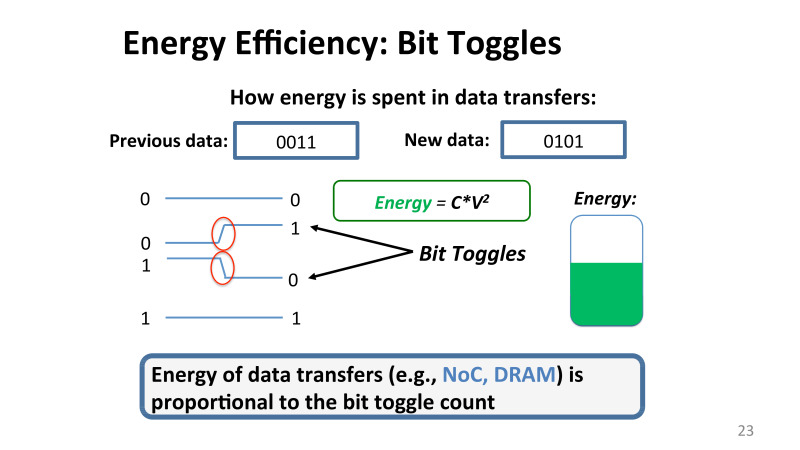
Проблема была в том, что здесь нужно понимать не только низкоуровневый механизм, но надо понимать и физику процесса. Покажу на простом примере. Представьте, вы пересылали по проводам, скажем, 0011. По четырем проводам вы переслали четыре бита. А теперь вы пересылаете 0101. С точки зрения пересылки памяти, если ты переслал 0 и пересылаешь снова 0, энергия практически не тратится, потому что тебе не нужно производить так называемый bit toggle, тебе не надо менять напряжение на этом пине, и энергия, грубо говоря, пропорциональна квадрату напряжения, и энергия тратится тогда, когда ты переходишь с 0 на 1 или с 1 на 0. Если у тебя много бит переключения происходит на пин, у тебя тратится много энергии. А если биты не меняются, энергия практически не тратится. Инженеры хорошо знакомы с этим феноменом, но программисты об этом обычно не задумываются.
Эти так называемые тогглы — это причина того, что у нас тратится существенная энергия для пересылки памяти. И фактически для большинства протоколов, допустим, для networks of chip или для DRM количество энергии, затрачиваемой на пересылку данных, прямо пропорциональна количеству тогглов.
Что же происходит? Почему компрессия ни с того ни с сего может сделать ситуацию настолько плохой? 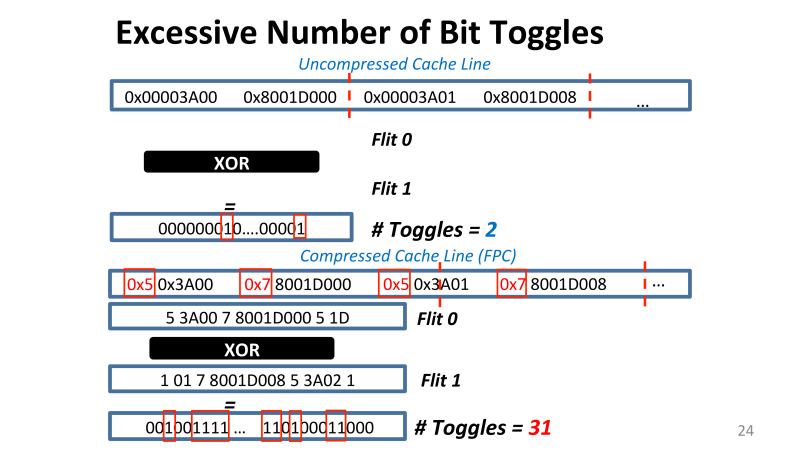
Вот пример одного из участков данных из одного приложения Nvidia, с реальными данными. Пересылаются эти данные по частям, обычно 32 байта или 16 байт, эти куски данных называются флитами. Как они пересылаются? Вначале первая часть, потом по пинам вторая часть. Если посмотрим, что произошло, если мы сделаем обычный XOR, то у нас всего два бита флипнуло на 16 или 8 байт, потому что данные были очень хорошо уложены до этого, они были очень регулярные.
Теперь мы применили какой-то алгоритм, например, frequent pattern compression, алгоритм от Intel, и вуаля, у нас каждый второй бит практически флипает. Количество флипов может вырасти и в 15, и в 16 раз. Компрессия фундаментально меняет энтропию, количество информации, которая хранится в каждом бите, и кроме того полностью ломает alignment. То есть если у тебя байты были очень хорошо уложены, то теперь они уложены совершенно случайным образом. Это позволяет тебе пересылать меньше, но тебе приходится пересылать дороже. Это проблема, с которой Nvidia и столкнулась. Я проанализировал их приложение, и те, где возникали у них проблемы, это те, где было сумасшедшее превышение средних порогов этих тогглов. Могло быть так, что раньше их было 2%, а потом становилось 40%. И это причина того, что энергоэффективность падала.
Мы исследовали эту проблему, и нашли ее решение. Мы нашли определенные хорошие метрики, которые позволяли нам, не вдаваясь в детали, сделать небольшую коробочку в процессоре, которая может заранее посчитать, сколько тогглов нас ожидает, посмотреть, какая компрессия нас ждет, и сделать так, что мы пересылаем только тогда, когда нам это выгодно.
Такая проблема была в реальном железе воплощена спустя несколько лет после этого. Я это рассказал, чтобы было понимание, с какими проблемами ты сталкиваешься, если хочешь применять компрессию так близко к вычислительному ядру. Тебе нужны очень низкие задержки, тебе очень часто нужно внимательно изучать твои приложения, не пытаться надеяться, что какие-то стандартные алгоритмы тебе помогут, потому что самые лучшие алгоритмы компрессии — это те, которые специально оптимизированы под твои структуры данных. И знать, что не только производительность важна, а энергопотребление. Грубо говоря, ты применил компрессию, она может ничего тебе не стоить, может быть буквально бесплатной, но она может менять данные таким образом, что ты будешь затрачивать больше энергии.
Эту свою экспертизу я стал применять порядка полутора лет назад к различным приложениям, и одно из основных приложений, которое я применял, я тогда работал в Microsoft Research в Редмонде, это был machine learning.
Расскажу о том, где же я их применял, какие результаты нам удалось получить, и какие интересные проблемы нам там удалось решить, и какие еще остались. Основной фокус этой части будет на очень растиражированной ныне DNNs. Я буду фокусироваться собственно на тренировке данных. Есть много других интересных алгоритмов, но DNNs — это то, с чем мы столкнулись в майкрософтовском дата-центре в Ajura, очень много пользователей тренируют различные виды сетей, и очень много из них тренирует их, мягко говоря, неэффективно. Это значит, что производительность от потенциального железа меньше 10%. Нам было интересно посмотреть, почему так происходит, что пользователи делают не так, что делают неправильно потенциально создатели всех популярных фреймворков: TensorFlow, CNTK, MXNet. Они все тоже недостаточно оптимизированы, на мой взгляд, несмотря на потраченные там ресурсы.
Фокус на DNNs связан с тем, что это было то самое приложение, которое большую часть серверов нагружала, которые использовали GPU.
DNNs используется для большого количества приложений. Это и перевод, и распознавание речи, и система рекомендаций, и детектирование объектов, и классификация картинок. Разные типы сетей применяются. На мой взгляд, там до сих пор меньше науки, и очень много магии вуду, но эти сетки тренируются на реальных машинах, тратят реальные ресурсы. Какими бы они ни были, мы должны их достаточно эффективно наоптимизировать.
Фокус моей работы в основном связан с тренировкой, а не с использованием сетей. Обе проблемы очень важны, как тренировка сетей, и так и inference.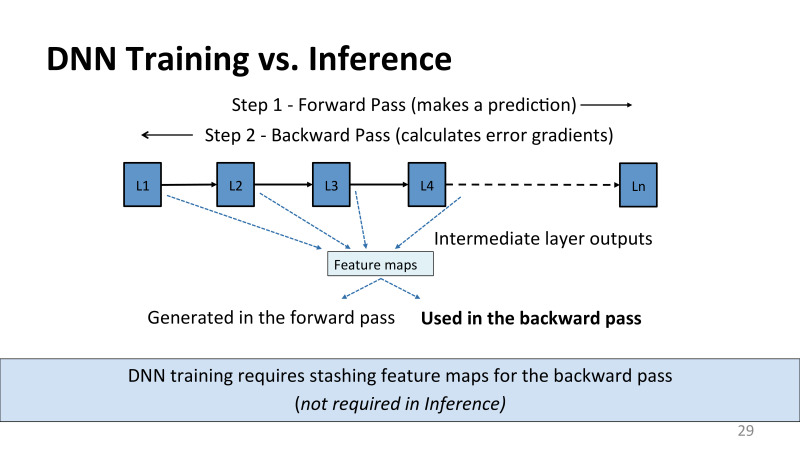
Когда я начал заниматься этой проблемой, у Google уже был TPU первой версии, сделанный в реальном железе, и соревноваться с несколькими компаниями, которые уже делают имплементацию inferent в реальном железе мне казалось не особо интересным, поэтому я фокусировался на тренировке, которая была очень важна для Microsoft.
Чем же они отличаются фундаментально? Почему оптимизация и железо для них нужно потенциально разное? Если посмотреть на анонсы от Google, все видели, что TPU первой версии годился вообще только для inference. Второй годится частично для тренировки, но тоже не особенно хорошо. Первый шаг, у тренировки inference, он одинаковый. Это так называемый forward pass. Ты проходишь по всем уровням сети, генерируешь какой-то ответ, и в inference на этом все заканчивается. Ты получил результат — это предсказание твоей сетки. К сожалению, на тренировке на этом все не заканчивается. Тебе нужно делать так называемый backward pass, тебе нужно пропагировать градиенты по уровням сетей, минимизировать свою ошибку, повторять этот процесс многократно для всех своих входных данных.
Это основное отличие, особенно для проблемы, с которой мы столкнулись. А главная проблема для нас оказалась в том, что эти сетки потребляют большое количество памяти. Память потребляется потому, что между этими слоями генерируется промежуточные результаты, которые в англоязычной литературе обычно называются feature maps или activations. В inference эти данные тоже вычисляются, но они потребляются следующим уровнем и больше ни для чего не нужны. При back propagation, типичном алгоритме, который используется для тренировки нейросетей, все эти результаты нужны на обратном проходе, чтобы правильно вычислить градиенты. Грубо говоря, если у меня есть уровень L2, я вынужден хранить его результат, весь forward pass и весь обратный, потому что он понадобится аж в самом конце, и никакого варианта у меня здесь нет, эти данные нужны, чтобы правильно вычислить градиент.
Если у меня есть глубокие сетки, мы знаем, есть сетки и по 100, и 200 уровней, например, ResNet, используемые для image classification. Все эти промежуточные данные надо где-то хранить. Результат этого — это то, что у нас, если взять ResNet даже 101 уровень, стандартная сетка, которая используется, если ты хочешь более-менее нормальный mini batch использовать, скажем, 64 картинки за раз, тебе требуется часто больше памяти, чем влезает на одну графическую карточку, больше 16 Гб. Самая даже дорогая карточка, P100 Pascal или даже Volt100, там нет больше 16 Гб. И если оно не влезает в память одной графической карточки, надо использовать несколько.
Для компании, такой как Facebook, не проблема купить и много. Но вопрос в том, что если ты смотришь, что карточка используется только для ее памяти, ее вычислительные ресурсы полноценно не используются. И глупо использовать много карточек только для того, чтобы покрывать нехватающую память.
Одна из ключевых проблем в том, что нейронные сетки потребляют большое количество памяти. Если ты начинаешь использовать много GPU, то вычислительные ресурсы неэффективно используются. Ты просто разделяешь эти ресурсы на две карточки, и каждая из них использует меньше половины ресурсов.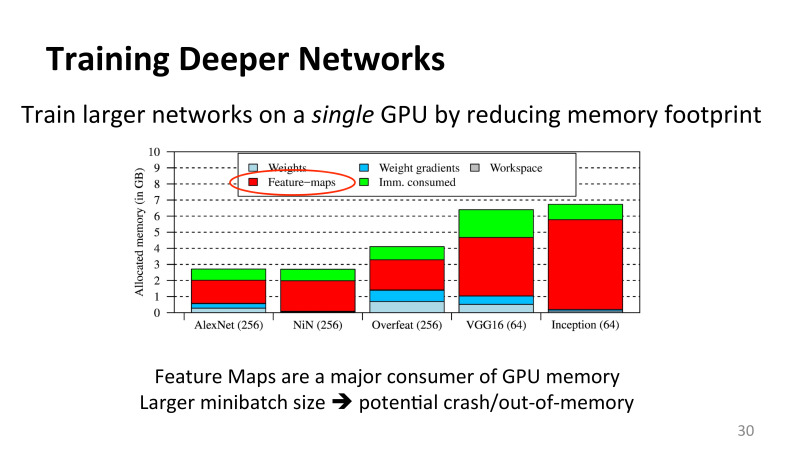
Первый шаг, который мы сделали, чтобы проанализировать и понять, куда деваются эти данные, мы сделали профиль по популярным сеткам, использующийся для классификации картинок. На оси X здесь AlexNet, с который начиналась эта DNN революция, и другие популярные сетки: Overfeat, VGG16, Inception (эта сетка известна так же как Google version 3, одна из популярных сеток, которую использует Google). В скобках указан размер mini batch. Это параметр, указывающий, сколько картинок мы обрабатываем в параллели. И данные, что использовались для этого теста, это классический ImageNet, классификация картинок приблизительно 220 на 220 пикселей глубиной 3, и на выходе 1000 классов: кошки, собачки, люди и так далее.
Куда уходит память? Даже на достаточно маленьких старых сетях AlexNet потребление памяти уже было несколько ГБ, это в 2011 году, когда карточки были еще меньше. И основная масса памяти, чем глубже сетки мы делаем, тем больше памяти потребляется этими feature maps, промежуточными результатами.
А почему не веса? Веса действительно важны, но веса не меняются, не растут линейно с изменением размера mini batch, когда ты начинаешь обрабатывать больше и больше картинок в параллели, веса для них используются те же самые, а вот параметры активации растут линейно с изменением количества inputs. Для чего мы увеличиваем количество картинок в параллели? Чтобы хорошо использовать GPU ресурсы. Современный GPU может в параллели запросто запускать 8000 threads, и чтобы его нагрузить полноценно, нужно в прааллели обрабатывать большое количество картинок, иначе GPU не будет полностью загружен. А раз так, зачем его использовать? Он не будет более эффективным, чем даже CPU или ISAC.
Чтобы использовать эффективно акселератор, его надо полностью загружать. И тут возникает проблема, связанная с памятью. Это одна из главных проблем, и когда мы стали ее исследовать, главная проблема, с которой мы столкнулись, что в моей области, в компьютерной архитектуре, в эффективных системах, все сфокусированы на DNN inference, на наших ключевых конференциях, таких как ISCA, MICRO, в 2015 году было по 15 статей на одной, посвященной deep neural networks, и все занимались inference, все оптимизировали только веса.
Во-первых, архитекторам проще оптимизировать inference, веса уже найдены, и тебе нужно просто сделать один forward pass, больших затрат по памяти там нет, и можно оптимизировать конволюционные уровни до потери сознания, и радоваться полученным результатам.
Проблема, что когда ты эту проблему решил, тренировке это особо не помогает. Все методы, что они предложили для inference, такие как удалять какие-то веса, использовать квантизацию, фактически это взять 32-битный floating point, плавучку, и превратит ее в 16 бит, 8 или 4. Все эти механизмы для тренировки не работают, потому что теряется качество вычислений, и обычно используется какой-то алгоритм stochastic gradient descend, он просто перестает сходиться. Мы пересмотрели эти алгоритмы, никто из них к тренировке напрямую не применим. Также они не очень хорошо ложатся на современные GPU, все эти статьи предлагают сделать новый ISAC, что-то похоже на TPU или давайте используем в лучшем случае какую-то программируемую логику типа FPGA для этого. На GPU все эти техники не очень хорошо ложились.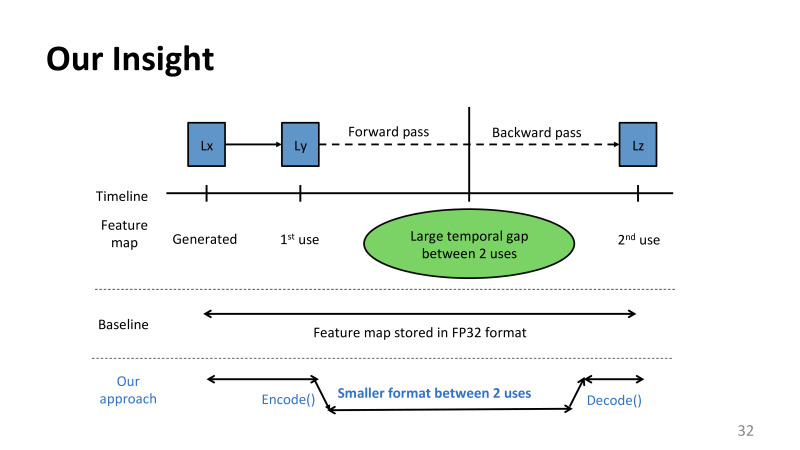
Мы решили посмотреть, что мы можем сделать нового и интересного специально для тренировки этих сетей. Одно из основных наблюдений, что мы сделали, что если посмотреть на то, как используются данные, которые хранятся так долго в памяти, основная причина, почему они хранятся там так долго, это то, что у нас есть одно место, где данные генерируются, например, на первом уровне LX, и на следующем уровне идет потребление результатов предыдущего уровня. После этого может пройти еще сотня уровней, пока мы идем, пока потребуется переиспользовать эти данные. И ради этого все время мы храним эти данные. Но использование сгенерированных результатов всего в двух местах: сразу же и после.
У нас есть большой промежуток времени, где эти данные не используются никак. Мы предлагаем исп
