EasyPortrait — портретная сегментация и анализ лиц

EasyPortrait Dataset
Всем привет! Наверняка, кто-то из вас уже пользовался сервисом видеоконференций SberJazz. Мы в нашей RnD команде решили помочь ребятам с задачей замены фона, для чего создали подходящий датасет и провели ряд исследований в направлении удаления фона (background removal). На этом мы не остановились и разметили данные для задачи анализа лица (face parsing). Это позволит пользователям применять эффекты бьютификации: сглаживание кожи, изменение размера и цвета губ или глаз, отбеливание зубов и т. д.
В данной статье мы расскажем о новом наборе данных EasyPortrait, опишем процесс его создания от идеи до разметки, и представим обученные на нем нейронные сети.Датасет и веса моделей мы выложили в открытый доступ — ссылки лежат в конце статьи и в нашем репозитории.
Введение
В последние несколько лет, появился большой спрос на удаленную работу, что сделало сервисы видеоконференций незаменимыми. Такая плотная интеграция подобных сервисов в нашу жизнь требует от них создания множества практических функций: от удаления фона до шумоподавления. Однако сервисы видеоконференций все еще страдают от плохого качества замены фона. Одной из причин этой проблемы является недостаток данных для этого домена, который включает в себя некоторые особенности, например наличие наушников у субъекта или близкий к субъекту задний план. Большинство наборов данных для задачи удаления фона были размечены или автоматически, или с использованием зеленого экрана (green screen), или с помощью фотошопа, что говорит об их не очень высоком качестве. Оставшиеся, размеченные вручную, имеют низкую разнородность по субъектам и сценам или не подходят по домену.
Для многих не новость, что у SberDevices есть свой сервис видеоконференций — SberJazz. Помимо нашего желания улучшить в SberJazz замену фона, мы решили, что неплохо было бы добавить и некоторые функции бьютификации. Создание такого функционала требует моделей, которые обучены на данных фейс парсинга. Существующие датасеты с такой разметкой также имеют некоторые недостатки: автоматически сгенерированные маски, низкое разрешение изображений, неподходящие условия для разметки тех или иных частей лица (об этом ниже). Чтобы упростить жизнь нашим коллегам из продуктовых команд, мы решили создать новый датасет EasyPortrait с разметкой сразу для двух задач: портретной сегментации и фейс парсинга.

Интерфейс сервиса видео-конференций SberJazz
Помимо очевидных приложений новый набор данных может стать ключевым и для других задач, ввиду того, что содержит полезную информацию о человеческом лице и его составляющих. Вот некоторые из возможных приложений:
Виртуальные и дополненный реальности. Портретная сегментация и фейс парсинг могут использоваться для создания аватаров и виртуальных персонажей;
Face Editing. Датасет, размеченный под задачу фейс парсинга, может быть использован для обучения генеративных моделей, с целью редактирования частей лица, например для отбеливания зубов или сглаживания кожи лица;
Яркий пример использования моделей, обученных на датасетах типа EasyPortrait можно увидеть в известном редакторе фотографий Adobe Lightroom или Photoshop, экосистему которого в последнее время стали активно дополнять нейросетевые пресеты. С помощью них можно производить адаптивную коррекцию фотографий, что упрощает процесс их ретуши: автоматически выделить зубы и отбелить их, скорректировать текстуру или оттенок кожи на основе её сегментационной маски от встроенной в пресет модели, а также поработать над яркостью бровей или бороды.

Пресеты Abode Lightroom
Описание датасета
Изображения
EasyPortrait состоит из 20000 RGB-изображений, на каждом из которых представлен один из 8377 уникальных пользователей. Датасет разбит на тренировочную (train), валидационную (valid) и тестовую (test) выборки с 16000, 2000 и 4000 сэмплами соответственно.
Преимущественно все фотографии были собраны в домашних условиях или в закрытых помещениях. На каждой из них человек делал фото самого себя или на веб-камеру, или на фронтальную камеру мобильного телефона. Изображения собирались в различных условиях освещения, а расстояние субъектов до камеры варьируется в среднем от 0,5 до 2 метров. Большая часть данных, около 17500 изображений, имеют FullHD-разрешение. Датасет сбалансирован по полу субъектов, возраст которых от 14 до 65 лет.
Сегментационные маски
Каждому изображению соответствует качественная сегментационная маска, разделенная на 9 классов: background, person, skin, left brow, right brow, left eye, right eye, lips, teeth. Сегментационные маски представляют собой двумерные массивы в виде PNG-картинок, каждый класс в массиве представлен своим значением от 0 до 8. Для более подробного анализа изображений в нашем репозитории предоставлена дополнительная информация о данных — ширина и высота изображений, средняя яркость фотографий, анонимизированные ID субъектов, с помощью которых датасет может быть разделен на выборки самостоятельно.
В итоге, мы собрали датасет EasyPortrait, который можно сравнить с другими наборами данных. На следующем рисунке представлены изображения сегментационных масок других популярных датасетов — это Helen, CelebAMask-HQ, LaPa, IBugMask и Face Synthetics. В разметке EasyPortrait есть несколько важных нюансов, отличающих его от большинства наборов данных фейс парсинга:
Борода, грубая щетина и усы не считаются частью маски кожи. Это даст возможность улучшить визуальное качество сглаживания кожи и использовать датасет для задач бьютификации;
Внутренняя часть рта отделена от зубов, что позволяет решать задачу отбеливания зубов без использования эвристик.

Сравнение EasyPortrait с другими датасетами
Краудсорсинг
Для сбора и разметки данных мы использовали две российские краудсорсинг-платформы: Yandex.Toloka и ABC Elementary. На первой площадке мы собирали изображения, а на второй размечали. Полный цикл создания датасета достаточно тривиален и состоит из нескольких этапов: сбор → проверка качества сбора + извлечение дубликатов → разметка → проверка качества разметки. Далее о каждом подробно.
Сбор данных
Самая простая стадия краудсорсинга — сбор данных. Мы попросили исполнителей сфотографироваться перед монитором или сделать селфи. Так как одной из основных проблем в наборах данных парсинга лиц и портретной сегментации является разметка окклюзий (occlusions), пользователей также просили делать фотографии с руками перед лицом, в очках, с высунутым языком, с открытым ртом, в наушниках и другое. Каждый исполнитель мог прислать более одного фото, однако лишь в различные даты, что позволяло нам контролировать разнообразие заднего фона, освещения и позы одного и того же субъекта. После этапа сбора мы оставили только фотографии в высоком разрешении — в результате было получено 28 633 изображений от 11 074 исполнителей. Некоторые из собранных изображений представлены на следующем рисунке:

Пример фотографий из датасета
Отметим, что на стадии сбора данных мы заручились согласием исполнителей на сбор данных, в том числе для последующего обучения нейросетей.
Проверка качества сбора
Многим известно, что исполнители на краудсорсинг-платформах часто выполняют задания некачественно. Поэтому большинство заказчиков вынуждены использовать этапы проверки качества тех или иных заданий. Наша проверка качества сбора изображений заключалась в следующих пунктах:
Встроенные в задание блокировки исполнителей. Бан в задании можно было получить за 1) быстрые ответы или пропуски; 2) неверные ответы (путем подмешивания контрольных заданий); 3) грубые нарушения условий задания;
Отдельное задание на Яндекс.Толоке. Оно заключалось в проверке каждого из собранных изображений несколькими (от 3 до 5) специально обученными пользователями на соответствие условиям (например, условию «фото должно быть сделано перед монитором или на фронтальную камеру телефона»). Все полученные бинарные ответы (верно / неверно) были сведены к одному путем мнения большинства;
Еще одно задание, но теперь на ABC Elementary для того, чтобы избежать большого пересечения проверяющих. Тут изображения проверяются на провокационный контент (например, чтобы извлечь из финального списка фото с людьми без одежды). Чтобы в полной мере использовать отсутствие пересечения проверяющих, мы попросили и их обратить внимание на выполнение условий. В остальном все так же, как в предыдущем пункте;
Поиск дубликатов. Несмотря на то, что одни и те же исполнители могли присылать фото в разные дни, дубликаты все же попадали в набор собранных изображений, после чего мы избавлялись от них путем расчета хешей изображений.
Разметка
Следующий рисунок наиболее подробно иллюстрирует этапы разметки и проверки ее качества:

Пример пайплайна разметки масок
Подробное описание пайплайна:
Image Labelling. Все оставшиеся после проверки качества фотографии постепенно отправлялись на разметку отдельных пар классов: человек и фон, кожа и не кожа (включает все части лица, которые кожу перекрывают, например: глаза, очки, борода, ноздри, высунутый язык и другие), глаза и брови, губы и зубы. Такое разбиение разметки на пары позволило нам значительно упростить задание для исполнителей, что, очевидно, благоприятно сказалось на качестве. В разрезе одного изображения для каждой из пар 5 специально обученных исполнителей создают 5 сегментационных масок;
Aggregation. Все полученные 4 пачки сводятся к 4 маскам посредством усреднения внутри пачки с проверкой по метрике IoU (Intersection over Union, отношение пересечения к объединению маски). Если какая-то маска была очень непохожа на остальные, она исключалась из пачки и усреднялись только оставшиеся. Если для какой-то фотографии та или иная маска не агрегировалась, то эта фотография выбрасывалась из датасета;
Eyes & Brows Dividing. Маска для глаз и бровей была разделена на 4 маски с помощью примитивных эвристик;
Mask Merging. Объединения масок в одну осуществлялось посредством наложения масок каждого из классов в следующем порядке: человек, кожа, брови, глаза, губы и зубы.
Краудсорсинг-платформы позволяют размечать маски с помощью замкнутых полигонов, которые затем можно перевести в бинарные сегментационные маски. На следующем рисунке представлен пример разметки некоторых частей лица человека.

Пример разметки сегментационных масок на площадке ABC Elementary
Условия разметки
В инструкции к каждому заданию разметки подробно описывались те или иные нюансы при разметке каждого из классов. Все они представлены в следующей таблице:
Класс | Правила |
Человек | — наушники и предметы заслоняющие субъект считаются частью этого класса — отдельные волоски и области между частями тела человека из описываемого класса извлекаются |
Брови | отделяются от кожи по видимой границе, исключая отдельные волоски |
Глаза | должны быть выделены по белкам, не включая в разметку ресницы и веки |
Кожа | — маска кожи включает в себя кожу без волос, глаз и других частей лица — границы кожи лица (или человека) выделяются логически на слишком засвеченных или темных фото (там, где границ не видно) — редкая борода считается частью кожи — уши, второй подбородок и ноздри должны быть исключены из маски кожи |
Зубы | отделяются от губ и рта, оставшаяся часть открытого рта считается окклюзией |
Окклюзии | — макияж и пирсинг считаются окклюзиями — часть очков, закрывающая кожу, должна быть отделена от кожи как окклюзия (то же касается и солнцезащитных очков, и бликов) — высунутый язык и борода с четкой границей также отделяются от остальных классов |
Отметим, что окклюзии в разметке для портретной сегментации и фейс парсинга отличаются: закрывающие часть человека предметы должны входить в класс человека, однако окклюзии, которые закрывают кожу и другие части лица, должны извлекаться из этих классов, но все еще принадлежать классу человека. Такое различие определяется целью двух поставленных задач: цель портретной сегментации извлечь человека от фона, тогда как цель фейс парсинга не извлечь лицо от человека, а выделить определенные части лица.
Отдельно отметим разметку бороды, щетины и усов. На рисунке ниже представлена визуализация разметки описанных частей лица в зависимости от их видимости. Редкую растительность на лице было решено оставить частью кожи, так как ее сглаживание будет выглядеть реалистично (верхний ряд рисунка). Борода и усы с четкими границами извлекаются из маски кожи, иначе этот участок после сглаживания будет слишком темным (нижний ряд рисунка).

Пример разметки бороды и усов
В среднем каждое изображение было размечено с помощью 254 точек, образующих замкнутые полигоны. Такое число точек говорит о высоком качестве разметки. Распределение количества точек для каждого класса отдельно представлено на рисунке ниже.
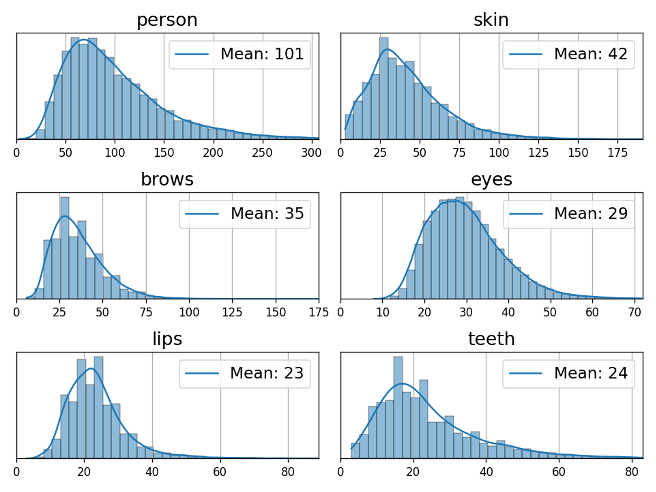
Распределение числа точек для полигонов разметки
На следующем рисунке показан пример деталей полученных сегментационных масок:

Пример разметки разных участков лица
Проверка качества разметки
Несмотря на то, что на этапе агрегации некоторые аналитически неверные маски удаляются и на ответ не влияют, мы все же решили ввести проверку модераторами на краудсорсинг-платформе. Они проверяли каждую маску на корректность, ориентируясь на условия в заданиях разметки. Такой подход позволил нам достичь очень высокого качества сегментационных масок.
Для простоты изложения мы опустили некоторые нюансы разметки и проверки ее качества, о которых более подробно написано в статье.
Набор нейросетей
Мы стремились продемонстрировать, что модель, обученная на нашем наборе данных, с любой архитектурой и с любым количеством параметров может показывать достаточно высокую точность без дополнительных трюков обучения. Для этого мы обучили 17 нейросетей для задачи сегментации. Все они были обучены с использованием популярного фреймворка MMSegmentation. Каждая выбранная модель обучалась с одинаковыми гиперпараметрами (настройками обучения) и единым пайплайном аугментации данных. Мы обучали модели SegFormer, FCN, LR-ASPP и FPN с разными архитектурами. Все модели обучались на видеокартах NVIDIA Tesla V100 с 32 Гб оперативной памяти. Полный список моделей, метрики, код обучения моделей и предобученные веса доступны в репозитории по ссылкам на гитхабе. Подробное описание обучения моделей можно посмотреть в нашей статье.
Заключение
В этой статье мы представили датасет EasyPortrait суммарным объемом 27 ГБ для портретной сегментации и фейс парсинга, на котором можно обучить нейросетевые модели для сервисов видеоконференций и решать с их помощью задачи удаления фона, бьютификации и другие. Все изображения, разметка и обученные модели выложены в открытый доступ по ссылкам ниже.
Датасет и модели распространяются под переработанной версией лицензии Creative Commons Corporation (Attribution-ShareAlike 4.0). Будем очень признательны за фидбек, а также мы готовы к совместным проектам!
Коллектив авторов:
