Достоверный нагрузочный тест с учётом непредвиденных нюансов
Мы задумались о построении инфраструктуры больших нагрузочных тестов год назад, когда достигли отметки в 12K онлайн-пользователей, работающих в нашем сервисе одновременно. За 3 месяца мы сделали первую версию теста, которая показала лимиты сервиса.
Ирония судьбы в том, что одновременно с запуском теста мы достигли лимитов на проде, в результате чего сервис упал на 2 часа. Это дополнительно стимулировало нас начать двигаться от проведения тестов от случая к случаю к созданию эффективной нагрузочной инфраструктуры. Под инфраструктурой я подразумеваю все инструменты для работы с нагрузкой: инструменты для запуска и автозапуска, кластер для подачи нагрузки, кластер, аналогичный проду, сервисы для сбора метрик и для подготовки отчётов, код для управления всем этим и сервисы для масштабирования.
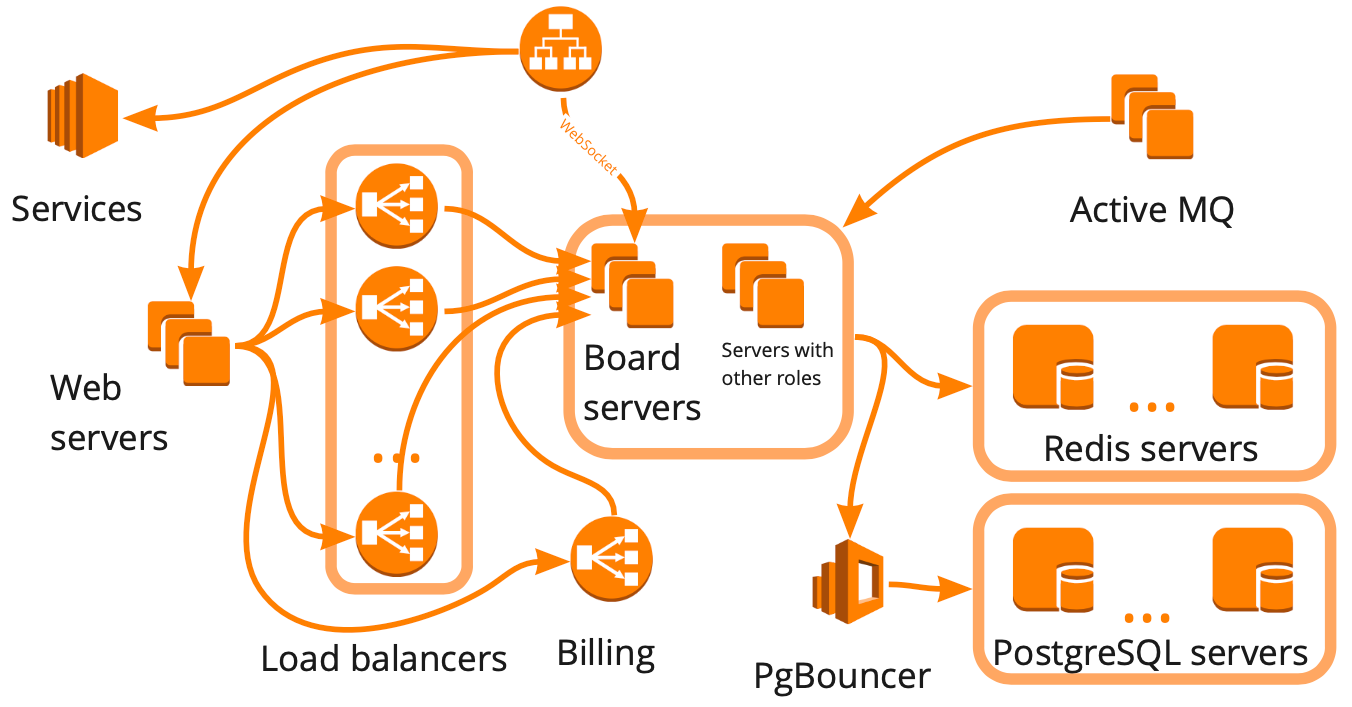
Так упрощённо выглядит схема miro.com: много разных серверов, которые как-то взаимодействуют друг с другом, при этом каждый выполняет специфичные задачи. Кажется, что для построения инфраструктуры нагрузочных тестов нам достаточно было нарисовать такую схему, учесть все взаимосвязи и начать покрывать сценариями каждый блок последовательно. Такой подход хорош, но он занял бы многие месяцы, что не подходило нам из-за быстрого роста — за последние полгода мы выросли с 12K до 20K онлайн-пользователей, работающих в сервисе одновременно. Кроме того мы не знали, как инфраструктура нашего сервиса будет реагировать на увеличение нагрузки: какие из блоков станут узким местом, а какие мы сможем масштабировать линейно.
В итоге мы решили протестировать сервис с помощью виртуальных пользователей, имитировав их реалистичную работу, то есть построить клон продакшена и сделать большой тест, который:
- нагрузит кластер, идентичный продакшену по структуре, но опережающий его по мощности;
- даст нам все данные для принятия решений;
- покажет, что вся инфраструктура способна выдерживать нужную нагрузку;
- станет основой для нагрузочных тестов, которые могут потребоваться нам в будущем.
Единственный минус такого теста — его себестоимость, потому что для него нам потребуется среда, которая будет больше среды продакшена.
Расскажу про создание реалистичного сценария, плагины — WS, Stress-client, Taurus, — кластер подачи нагрузки, кластер прода и покажу примеры использования тестов.
Создание реалистичного сценария
Для создания реалистичного сценария нам нужно:
- проанализировать работу пользователей на проде, а для этого определить важные для нас метрики, начать их регулярно собирать и анализировать скачки;
- сделать удобные настраиваемые блоки, которыми мы сможем эффективно нагружать нужную часть бизнес-логики;
- проверять реалистичность сценария метриками серверов.
Теперь подробнее про каждый пункт.
Анализ работы пользователей на проде
В нашем сервисе пользователи могут создавать доски и работать на них с разным контентом: фото, текстами, мокапами, стикерами, схемами и т.д. Первая метрика, которую нам важно собирать — количество досок и распределение контента на них.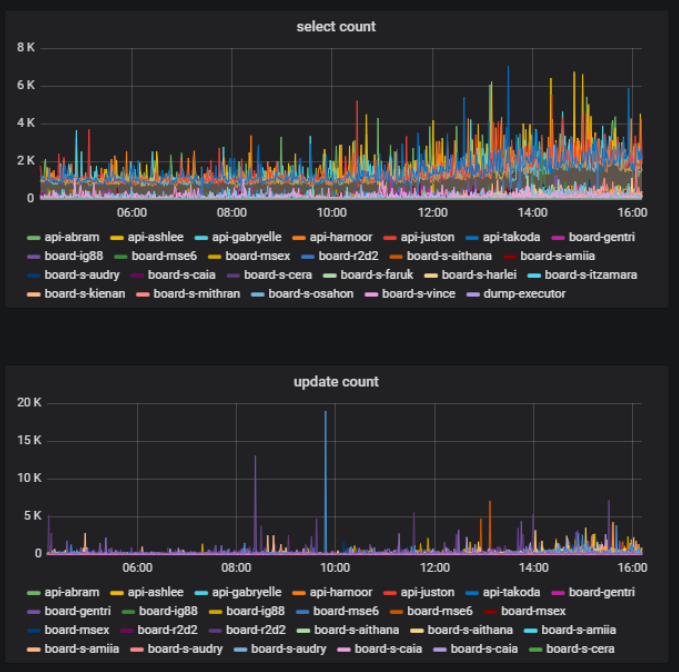
На одной и той же доске в один и тот же момент времени часть пользователей может что-то активно делать — создавать, удалять, редактировать —, а часть просто просматривает созданный материал. Это тоже важная метрика — отношение количества пользователей, меняющих контент на доске, к общему количеству пользователей одной доски. Это мы можем получать на основе статистики работы с базой данных.
В нашем бэкенде мы используем компонентный подход. Компоненты мы называем моделями. Мы так разбиваем наш код по моделям, чтобы за каждую часть бизнес-логики отвечала определённая модель. Мы можем посчитать количество обращений к базе, которые происходят через каждую модель и понять, какая часть логики больше всего нагружает базу.
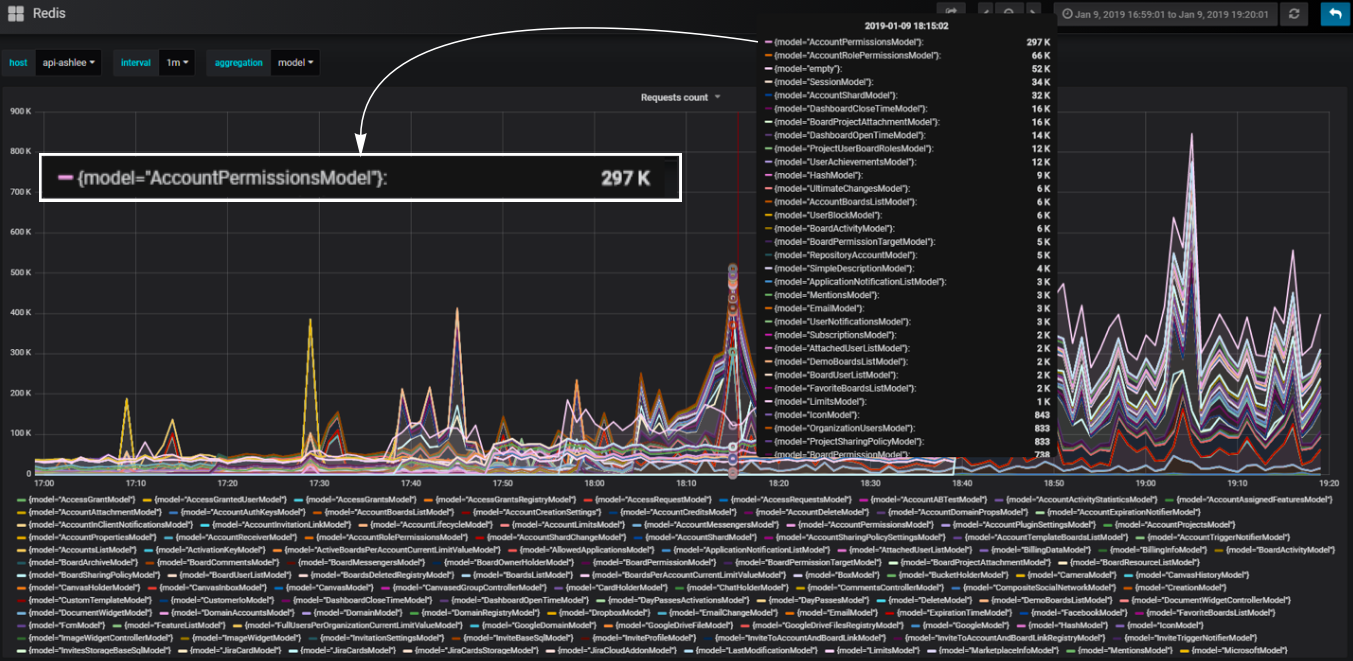
Удобные настраиваемые блоки
Например, нам нужно добавить в сценарий блок, который нагрузит наш сервис идентично тому, как это происходит при открытии страницы дашборда со списком досок пользователя. Во время загрузки этой страницы отправляются http-запросы с большим набором данных: количество досок, аккаунты, в которые у пользователя есть доступ, все пользователи аккаунта и так далее.

Как эффективно нагрузить дашборд? При анализе поведения продакшена мы увидели скачки нагрузки в базе данных во время открытия дашборда большого аккаунта. Мы можем воссоздать идентичный аккаунт и менять интенсивность использования его данных в сценарии, эффективно нагружая дашборд небольшим количеством обращений. Мы также можем создавать неравномерную нагрузку для большей реалистичности.
При этом нам важно, чтобы количество виртуальных пользователей и создаваемая ими нагрузка были максимально похожи на пользователей и нагрузку на продакшен. Для этого мы также воссоздаём в тесте фоновую нагрузку на среднестатистическом дашборде. Таким образом большинство виртуальных пользователей работают на небольших среднестатистических дашбордах, а губительную нагрузку создают всего несколько пользователей, как и бывает на продакшене.
Мы изначально не хотели покрывать каждую роль сервера и каждую взаимосвязь отдельным сценарием. Это видно на примере с дашбордом — мы просто повторяем во время теста то, что происходит при открытии дашборда на проде когда его открывает пользователь, а не покрываем синтетическими сценариями то, на что это влияет. Это позволяет по умолчанию покрывать тестом нюансы, которых мы даже не предполагали. Таким образом мы подходим к созданию теста инфраструктуры со стороны бизнес-логики.
Такую логику мы использовали для эффективной нагрузки всех остальных блоков сервиса. При этом, каждый отдельный блок с точки зрения логики использования функционала может не быть реалистичным; важно, чтобы он давал реалистичную нагрузку по метрикам на серверах. И тогда мы из этих блоков сможем создать сценарий, имитирующий реальную работу пользователей.

Данные — часть сценария
Стоит учитывать, что данные — это тоже часть сценария, и сама логика работы кода очень сильно зависит от данных. При построении большой базы данных для теста —, а она очевидно должна быть большой для большого инфраструктурного теста — нам нужно научиться создавать данные, которые потом не дадут крен в ходе выполнения сценария. Если наколотить мусорные данные, сценарий может оказаться нереалистичным, а большую базу будет сложно исправлять. Поэтому мы с помощью Rest API начали создавать данные так же, как это делают наши пользователи.
Например, для создания досок с имеющимися данными мы выполняем API-запросы загрузки доски из бэкапа. В результате получаем честные реальные данные — разные доски разного размера. При этом заполнение базы происходит достаточно быстро за счёт того, что мы многопоточно в скрипте дергаём запросы. По скорости это сравнимо с генерацией мусорных данных.
Итоги по этой части
- Используйте реалистичные сценарии, если хочется проверить всё разом;
- Анализируйте реальное поведение пользователей, чтобы проектировать структуру сценариев;
- Сразу создавайте удобные блоки для настройки;
- Настраивайте по реальным метрикам серверов, а не по аналитике использования;
- Не забывайте, что данные — это часть сценария.
Кластер для подачи нагрузки
Схема инструментария для подачи нагрузки:
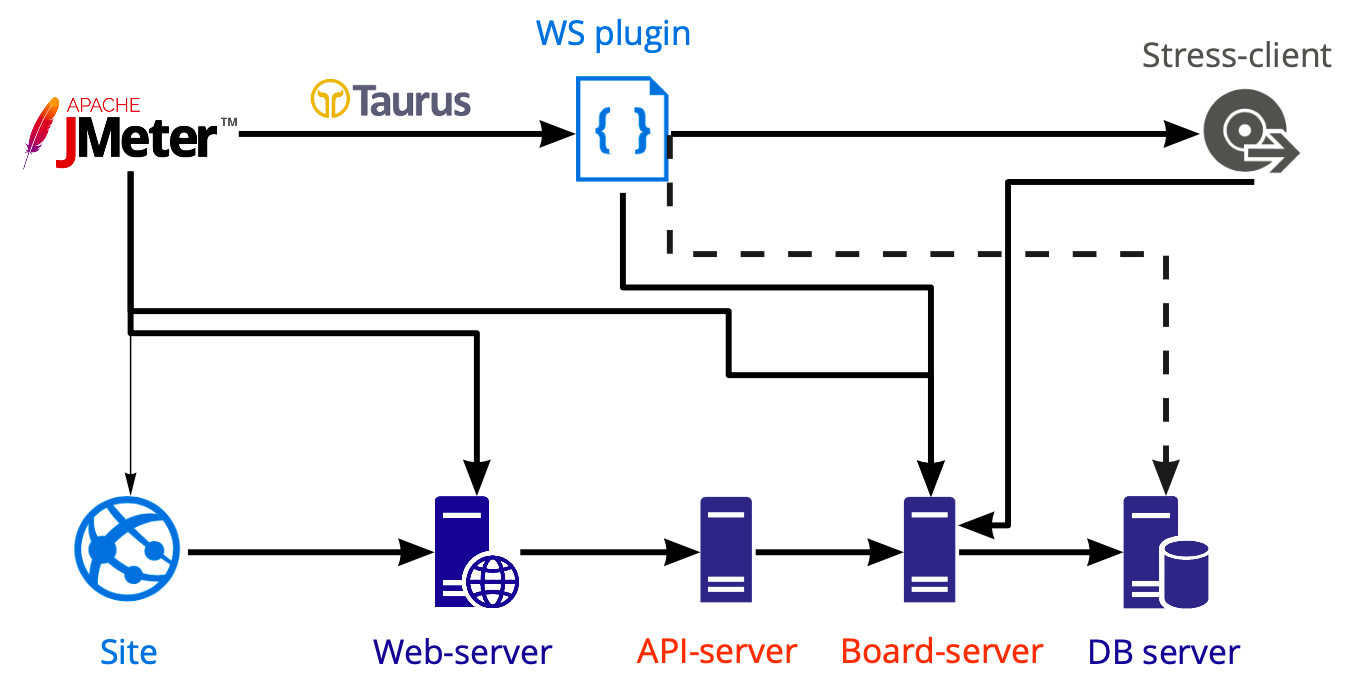
В Jmeter мы создаём сценарий, который запускаем при помощи Taurus и нагружаем им различные серверы: web, api, board-серверы. Тесты базы данных мы производим отдельно средствами Postgresql, а не Jmeter, поэтому на схеме показана пунктирная линия.
Кастомизированная работа внутри web-socket
Работа на доске происходит внутри WS-подключения, и именно на доске возможна многопользовательская работа. Сейчас в коробке Jmeter внутри плагин-менеджера есть несколько плагинов для работы с вэб-сокетом. Логика везде одинаковая — плагины просто открывают веб-сокетное подключение, но все действия, которые происходят внутри, в любом случае нужно писать самим. Почему? Потому что работать также как с http-запросами здесь не получается, то есть мы не можем записать сценарий, выдернуть экстракторами динамические значения и прокинуть их далее.
Работа внутри вэб-сокета обычно очень кастомизированная: вы кастомно вызываете определенные методы с определенными данными и, соответственно, вам своими же средствами нужно понимать, корректно ли выполнился запрос и как долго он выполнялся. Listener внутри этого плагина пишутся тоже самостоятельно, хорошего готового решения мы не нашли.
Stress-client
Мы хотим максимально просто повторять то, что делают реальные пользователи. Но мы пока не умеем записывать и воспроизводить то, что происходит в браузере внутри WS. Если мы внутри WS всё напишем с нуля, то у нас получится новый клиент, а не тот, который используют реальные пользователи. Не хочется писать новый клиент, если у нас уже есть работающий.
Поэтому мы решили поместить наш клиент внутрь Jmeter. И столкнулись с рядом сложностей. Например, выполнение js внутри Jmeter — это отдельная история, т.к. это абсолютно определённая версия поддерживаемых функций. И если вы хотите использовать ваш существующий код клиента, у вас скорее всего ничего не получится, потому что новомодные конструкции здесь не запустить, их придётся переписывать.
Вторая сложность — мы не хотим поддерживать код всего клиента для нагрузочных тестов. Поэтому мы убрали из клиента всё лишнее и оставили только клиент-серверное взаимодействие. Это позволило использовать клиент-серверные методы и делать всё, что может делать наш клиент. Плюс в том, что клиент-серверное взаимодействие меняется крайне редко, а значит и поддержка кода внутри сценария требуется редко. Например, за последние полгода я ни разу не вносил никаких изменений в код, потому что он прекрасно работает.
Третья сложность — появление больших скриптов существенно утяжеляет сценарий. Во-первых, это может стать узким местом в тесте. Во-вторых, мы скорее всего не сможем запустить большое количество потоков с одной машины. Сейчас у нас получается запустить только 730 потоков.
Наш пример на инстансе в Amazon
Тип Jmeter server в AWS: m5.large ($0.06 per Hour)
vCPU: 2
Mem (GiB): 8
Dedicated EBS Bandwidth (Mbps): Up to 3,500
Network Performance (Gbps): Up to 10
→ ~730 потоковГде взять сотни серверов и как сэкономить
Дальше возникает вопрос: 730 потоков с одной машины, а мы хотим 50K. Где поднять столько серверов? Мы создаём облачное решение, поэтому покупать серверы для тестирования облачного решения кажется странным. Плюс это всегда определённая медлительность процессов покупки нового железа. Поэтому нам нужно поднимать их также в облаке, так что мы выбирали в итоге между облачными провайдерами и облачными нагрузочными инструментами.
Облачные нагрузочные инструменты типа Blazemeter и RedLine13 мы не стали использовать, потому что у них есть ограничения по использованию, которые нам не подошли. У нас есть разные тестовые площадки, поэтому мы хотели найти универсальное решение, которое позволило бы 90% наработок использовать в том числе в локальных тестах.
В итоге мы выбирали между облачными провайдерами.
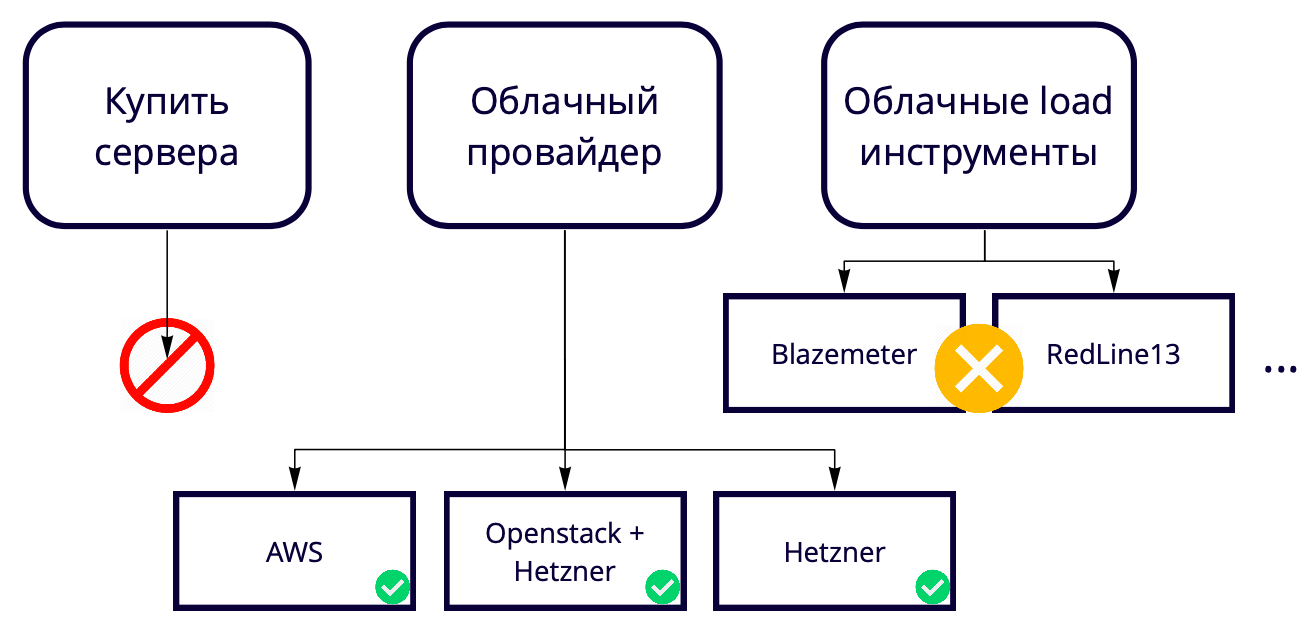
Наш продакшен на AWS, поэтому тестируем мы тоже в основном там и хотим, чтобы тестовый стенд был максимально похож на прод. У Amazon много платных фичей, некоторе из которых мы используем в проде, например, балансировщики. Если эти фичи именно в AWS не нужны, то можно использовать их в 17 раз дешевле в Hetzener. Либо можно держать сервера в Hetzener, использовать Openstack и самим написать балансировщики и другие фичи, так как с помощью Openstack можно повторить всю инфраструктуру. Нам это удалось.
Тестирование 50K пользователей с помощью 69 инстансов в AWS стоит нам в месяц примерно $3K. Как сэкономить? Например, в AWS есть временные инстансы — spot instances. Их крутость в том, что мы не храним их у себя постоянно, поднимаем только на время тестов и стоят они значительно дешевле. Нюанс в том, что их по большей цене может перекупить кто-то другой прямо в момент нашего теста. У нас пока, к счастью, такого не было ни разу, а вот минимум 60% стоимости мы уже экономим за их счёт.
Кластер для подачи нагрузки
Мы используем коробочный кластер Jmeter. Он работает великолепно, его не надо никак дорабатывать. У него есть несколько вариантов запуска. Мы используем самый простой, когда один мастер запускает N инстансов, при этом их могут быть сотни.
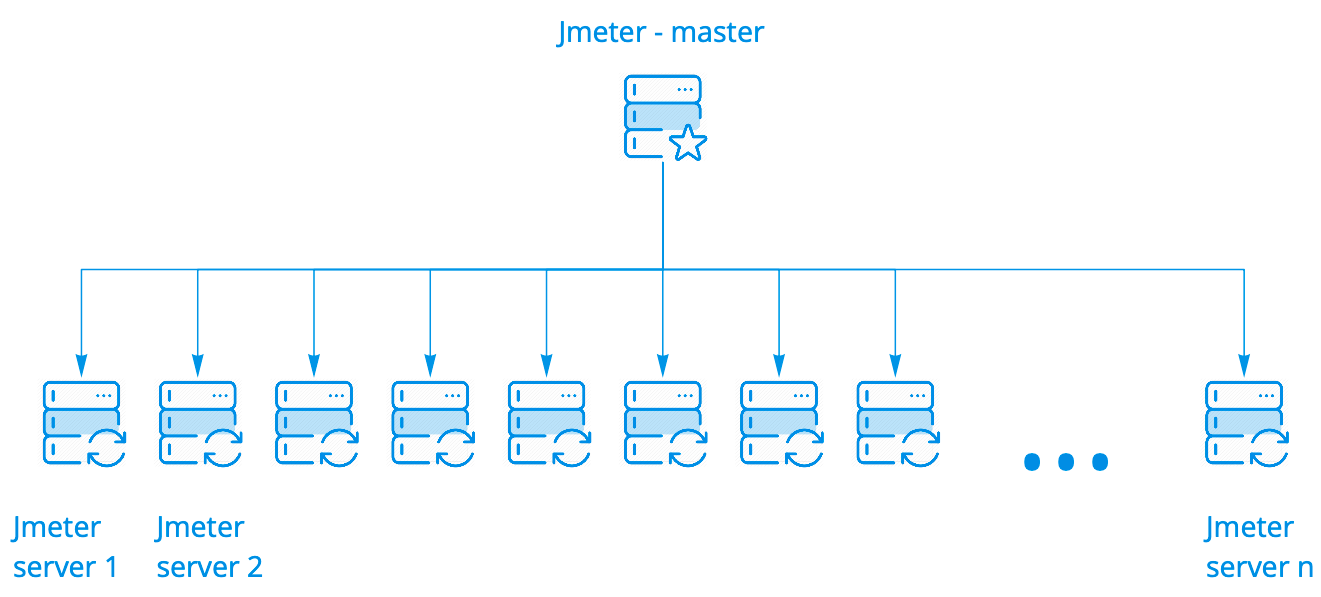
Мастер запускает сценарий на Jmeter серверах, при этом держит с ними связи, собирает общую статистику со всех инстансов в реальном времени и выводит в консоль. Всё это выглядит ровно также, как запуск сценария на одном сервере, хотя мы видим результаты запуска на сотне серверов.
Для подробного анализа результатов выполнения сценария на всех инстансах мы используем Kibana. Логи парсим с помощью Filebeat.

A Prometheus Listener for Apache JMeter
У Jmeter есть плагин для работы с Prometheus, который из коробки даёт всю статистику использования JVM и потоков внутри теста. Это позволяет видеть, как часто пользователи заходят, выходят и так далее. Плагин можно кастомизировать, чтобы отправлять данные по работе сценария в Prometheus и видеть их в реальном времени в Grafana.
Taurus
Ряд текущих проблем мы хотим решить с помощью Taurus, но ещё не занимались этим:
- Конфиги вместо клонов сценариев. Если вы тестировали на Jmeter, то наверняка сталкивались с необходимостью запускать сценарии с разными наборами исходных параметров, для чего приходилось создавать их клоны. В Taurus есть возможность иметь один сценарий, а с помощью конфигураций управлять параметрами запуска;
- Конфиги для управления Jmeter-серверами при работе с кластером;
- Анализатор онлайн-результатов, который позволяет собирать результаты отдельно от потоков Jmeter и не утяжелять сам сценарий;
- Удобная интеграция с CI;
- Возможность тестирования распределённой системы.
Итоги этой части
- Если мы используем код внутри Jmeter, то лучше сразу подумать о его производительности, потому что иначе мы можем тестировать Jmeter, а не наш продукт;
- Кластер Jmeter — прекрасная вещь: легко настраивается, к нему легко прикручивается мониторинг;
- Большой кластер можно содержать на спотовых инстансах, это будет гораздо дешевле;
- Будьте аккуратны с listeners внутри Jmeter, чтобы сценарий не тормозил работу на большом количестве серверов.
Примеры использования инфраструктурных тестов
Вся история выше во многом про создание реалистичного сценария для теста на лимиты сервиса. Примеры ниже показывают, как можно реиспользовать наработки инфраструктуры нагрузочных тестов для решения локальных задач. Я подробно расскажу про два теста, а вообще мы периодически проводим около 10 видов нагрузочных тестов.
Тестирование базы данных
Что мы можем нагрузочно тестировать в БД? Тяжёлые запросы — вряд ли, потому что мы можем их тестировать и в однопоточном режиме, если просто посмотрим планы запросов.
Интереснее ситуация, когда мы запускаем тест и видим нагрузку на диск. На графике видно, как поднимается iowait.
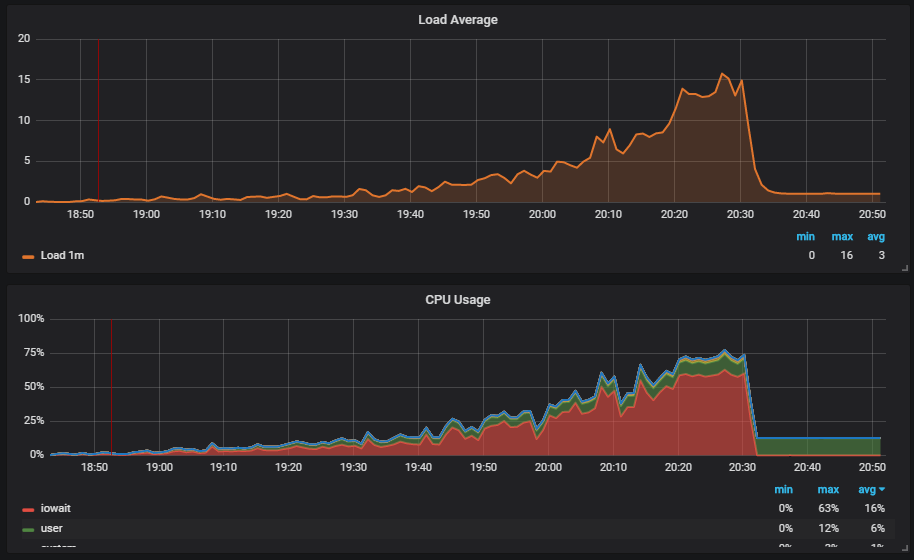
Дальше видим, что это влияет на пользователей.
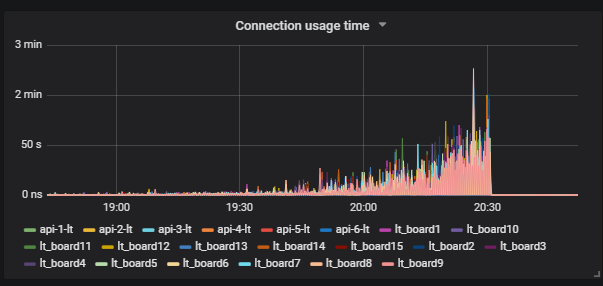
Понимаем в чём причина: Vacuum не сработал и не удалил из базы мусорные данные. Если вы с Postgresql не работали, то Vacuum — это примерно как Garbage collector в Java.

Дальше видим, что Checkpoint начал срабатывать не по расписанию. Для нас это сигнал, что конфиги Postgresql не соответствуют интенсивности работы с базой.
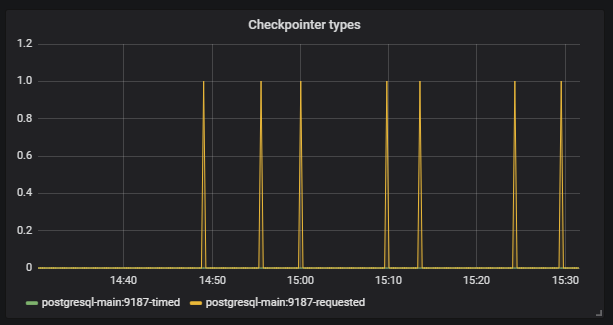
Наша задача — правильно настроить базу, чтобы такие ситуации не повторялись. У того же Postgresql есть множество настроек. Для тонкой настройки нужна работа короткими итерациями: поправили конфиг, запустили, проверили, поправили конфиг, запустили, проверили. Конечно, для этого нужно подать хорошую нагрузку на базу, а для этого как раз нужны большие инфраструктурные тесты.
Особенность в том, что для того, чтобы тест нормально разогнался и не упал там, где не нужно, разгон должен быть длительным. У нас на тест уходит порядка трёх часов, а это уже не похоже на короткие итерации.
Ищем решение. Находим один из инструментов Postgresql — Pg_replay. Он умеет многопоточно воспроизводить ровно то, что записано в логах и ровно так, как это происходило в момент их записи. Как мы можем его эффективно использовать? Мы сворачиваем дамп базы, затем записываем в логи всё, что происходит с базой после сохранения, а дальше у нас есть возможность развернуть дамп и воспроизвести всё, что происходило с базой многопоточно.
Где записать логи? Популярное решение по записи логов — собрать их на проде, так как это даёт максимально реалистичный воспроизводимый сценарий. Но здесь есть ряд проблем:
- Для теста нужно использовать данные прода, что не всегда возможно;
- В процессе используется дорогая операция syslog;
- Нагружается диск.
Здесь нам помогает наш подход к большим тестам. Мы снимаем дамп на тестовом окружении, запускаем большой тест и записываем логи всего, что происходит в момент выполнения реалистичного сценария. Дальше мы используем nanci_cli для проведения теста базы данных:
- Создаётся инстанс в AWS;
- Разворачивается нужный нам дамп;
- Запускается pg_replay и воспроизводит нужные логи;
- Скрипт формирует html-отчёт на основе системных таблиц pg_stat_…
При запуске nancy_cli мы можем передать небольшое количество параметров, которыми можно менять, например, интенсивность выполнения сценария.
В итоге, мы используем наш реалистичный сценарий для создания теста, а затем воспроизводим тест без использования большого кластера. Важно учесть, что для тестирования любых sql data base сценарий должен быть неравномерным, иначе сама база будет вести себя не как на проде.
Мониторинг деградации
Для тестов деградации мы используем наш реалистичный сценарий. Идея в том, что нам нужно гарантировать, что сервис не стал работать медленнее после очередного релиза. Если наши разработчики меняют в коде то, что приводит к увеличению времени выполнения запросов, мы можем сравнить новые значения с эталонными и сигнализировать, если в билде ошибка. За эталонные значения мы берём текущие значения, которые нас устраивают.
Контроль времени выполнения запросов — это полезно, но мы пошли дальше. Нам хотелось увидеть, что время отклика при работе реальных пользователей после релиза не стало больше. Мы подумали, что в момент нагрузочных тестов мы, наверное, можем зайти руками и что-то проверить, но это будут только десятки кейсов. Эффективнее запустить имеющиеся функциональные тесты и посмотреть тысячу кейсов за то же время.

Как у нас это работает. Есть мастер, который после сборки деплоится на тестовый стенд. Затем автоматически запускаются функциональные тесты параллельно с нагрузочными. После мы получаем отчёт в Allure о том, как прошли функциональные тесты под нагрузкой.
В этом отчёте, например, мы видим, что упал тест сравнения с эталонным значением.
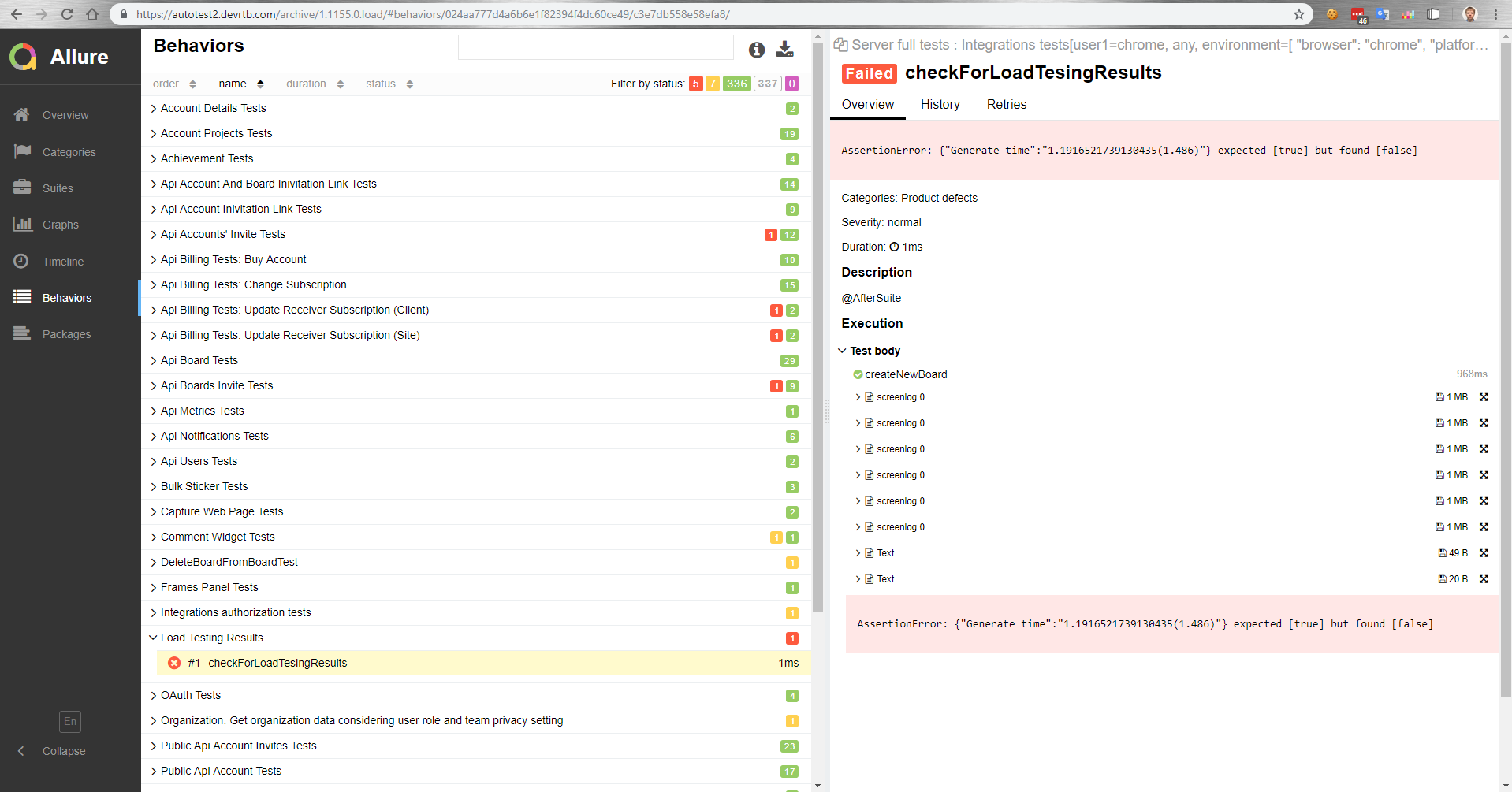
Также в функциональных тестах мы можем измерять время выполнения операции в браузере. Или функциональный тест просто не выполнится из-за увеличения времени выполнения операции под нагрузкой, потому что сработает тайм-аут на клиенте.
Итоги по этой части
- Реалистичный тест позволяет дёшево тестировать базу данных и легко её настраивать;
- Функциональное тестирование под нагрузкой возможно.
