Dictionary: очень специальный

Как-то раз была поставлена задача ускорить работу с Dictionary
В статье, как и в предыдущей, речь пойдёт о наносекундах и экономии байтиков. Уверен, что 99% программистов этого не нужно, а подобные эксперименты без изучения environment’a будут даже опасны. Однако, если ваш профиль high-load или геймдев, данная информация может быть востребована.
Как проектируем?
Так как всё, что делает этот словарь связано со структурами, было решено сделать и его структурой. Это чуть-чуть уменьшит время, которое мы будем тратить на вызов методов — runtime’у не надо будет выяснять по таблице виртуальных методов, кому принадлежит этот метод. Это, в свою очередь, облегчит inline методов — одну из самых эффективных методик оптимизации скорости. Ну, если мы говорим о наносекундах, конечно.
Далее, мы не будем изобретать велосипед и воспользуемся всеми наработками dotnet-community для того, чтобы реализовать словарь. Так как ключ это всегда int, мы можем смело выбрасывать всё, что касается сравнения ключей и получения hash-кода. Для того, чтобы размер внутренней коллекции совпадал с вычисленными эмпирическим путём значениями, будем использовать и вот этот класс.
Добавление элементов в словарь
Метод добавления очень похож на метод из настоящего Dictionary. С одним исключением: мы можем, например, добавить ключ и сразу получить ссылку на значение во внутренней коллекции словаря. Классическое добавление тоже, конечно, присутствует.
Если запустить benchmark и измерить скорость добавления элементов, то мы увидим интересную картину:

Benchmark: C# get value from Dictionary vs custom special dictionary
Результаты, в принципе, ожидаемые, поскольку алгоритм не нуждается в сравнении с использованием EqualityComparer, а значит убираются лишние вызовы и код становится более предсказуемым для процессора.
Из интересного: для того, чтобы иметь возможность отдавать ref в методе GetValue, приходится использовать дополнительное статическое поле, которое содержит значение по-умолчанию. Оно никогда не вернётся, так как чуть выше находится Exception (сам он кидается в методе статического класса Errors). Мотивы, которые побудили меня сделать так описаны в предыдущей статье про inline и throw.
Следующий тест — читаем и записываем новый результат в словарь. Это то самое, ради чего всё затевалось.
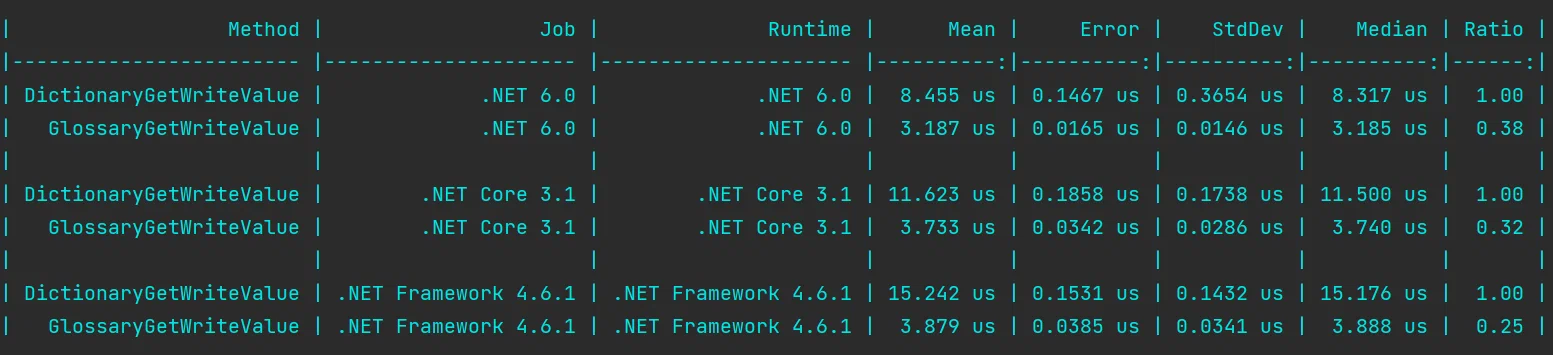
Benchmark: C# get write to Dictionary vs custom special dictionary
В нашем случае неоспоримым преимуществом является то, что мы можем получить ссылку на значение внутренней коллекции, а значит изменить её прямо по ссылке, без необходимости снова инициировать поиск ключа и ячейки, в которой лежит значение. В связи с этим, разница в скорости весьма велика.
Короче говоря, никаких неожиданностей: запись по ссылке во много раз быстрее, чем повторный поиск ячейки со значением по ключу.
Выводы
Иногда стоит писать свои коллекции. Даже такие сложные, как Dictionary. Тем более, что основной алгоритм поиска значения по ключу давно известен и даже лежит на github.
Иногда не стоит писать свои коллекции. Да-да, именно так. Не смотря на то, что результаты достаточно впечатляющие, они не гарантируют на 100%, что покрыты абсолютно все случаи добавления/удаления данных из коллекции. А что, если множественное добавление и удаление понизит производительность? А как быть с многопоточностью? Если вам хочется отвечать на все эти вопросы — вперёд. Это интересно.
P.S.: Начал писать в телегу про производительность. Заглядывайте, если интересно.
