DevConf: переход Uber с PostgreSQL на MySQL
18 мая 2018 года в Digital October состоится DevConf 2018. И мы решили пересказать некоторые интересные доклады с прошлогодней конференции. Там был доклад с несколько холиварным заголовком: «О чём молчит политрук: к дискуссии о переходе Uber с PostgreSQL на MySQL». В нем разработчик MySQL Алексей Копытов рассмотрел различия InnoDb и PostgreSQL на самом низком уровне, включая организацию данных, памяти и репликаций. Предлагаем вашему вниманию краткий пересказ доклада.

История вопроса.
Uber перешел с MySQL на Postgres в 2013 году и причины, которые они перечисляют, были во-первых: PostGIS — это геоинформационное расширение для PostgreSQL и хайп. То есть, у PostgreSQL есть некий ореол серьезный, солидная СУБД, совершенный, без недостатков. По крайней мере, если сравнивать с MySQL. Они мало что знали о PostgreSQL, но повелись на весь этот хайп и перешли, а через 3 года пришлось переезжать обратно. И основные причины, если просуммировать их доклад — это плохие эксплуатационные характеристики при эксплуатации в production.
Понятно, что это был достаточно большой репутационный удар для PostgreSQL сообщества. Было очень много обсуждений на самых разных площадках, в том числе и в списках рассылки. Я прочитал все эти комментарии и постараюсь рассмотреть какие-то наиболее подробные, наиболее обстоятельные ответы.
Вот наши сегодняшние конкурсанты. Во-первых, это Robert Haas. Роберт Хаас — это один из двух ключевых разработчиков PostgreSQL. Он дал наиболее взвешенный, сбалансированный ответ. Он ни в чем не обвиняет Uber, наоборот, говорит, что, спасибо, молодцы, что рассказали про проблемы, нам есть над чем поработать, мы много уже чего сделали для PostgreSQL, но есть еще достаточно большое пространство для улучшений. Второй ответ от Christophe Pettus — это CEO какой-то компании, которая занимается консалтингом по PostgreSQL. Вот то, что я увидел в этом докладе, меня потрясло до глубины души, потому что такое ощущение, что человек даже не пытался быть объективным. Изначально ставил перед собой задачу выставить Uber дураками, а PostgreSQL белым и пушистым. Все выворачивается наизнанку и я спрашивал мнение инженеров Uber, что они думают по поводу этого доклада. Они сказали, что это какая-то ерунда. Мы совсем не это говорили. Это прямая противоположность ответу Роберта Хааса.
Так же есть Simon Riggs. Это CTO известной компании 2ndQuadrant, которая тоже делает и консалтинг, и много разрабатывают в самом PostgreSQL. Это что-то где-то между, посередине. На некоторые вопросы Саймон отвечает подробно, а на некоторые не дает никакого ответа и прячет некоторые вещи. И четвертый доклад Александра Короткова, директора по разработке российской компании PostgreSQL professional. Ожидаемый доклад, подробный и обстоятельный, но мне кажется, некоторые вещи Александр тоже заметает под ковер.
И моя минутка славы. Год назад, на прошлогоднем DevConf я делал тоже доклад про проблемы Postgres. И этот доклад был за месяц до того, как Uber опубликовал свой. Причем я рассматривал PostgreSQL исключительно с архитектурной точки зрения, не имея никакого реального опыта промышленной эксплуатации PostgreSQL, но большинство проблем, которые описывает Uber уже на основе реальной эксплуатации, я в смог определить правильно. Единственная проблема Uber, которую я вообще обошел вниманием в своем докладе — проблема с MVCC на репликах. Я видел, что там есть некоторые проблемы, что-то почитал на эту тему, но решил, что это не так важно в промышленном применении и решил все это опустить. Как выяснилось, Uber показывает, что для них тоже эта проблема была важной.
Здесь будет много картинок. Чтобы объяснить проблему Uber нужно немножко поговорить о различии в MVCC, реализации в MVCC и различии в организации данных между MySQL, конкретно InnoDB и PostgreSQL.
Организация данных

В InnoDB используют кластеризованный индекс, это значит, что пользовательские данные хранятся вместе с индексными значениями для какого-то выбранного одного индекса. В качестве такого индекса обычно выступает первичный ключ «PRIMARY KEY». Вторичные индексы используют указатели на записи, но используют не просто какое-то смещение, они используют первичный ключ для того, чтобы указывать на записи.
В PostgreSQL другая организация данных на диске. Сами пользовательские данные хранятся отдельно от индекса в объекте, который называется «heap» или «куча», а все индексы и первичные, и вторичные используют указатели на данные в виде номера страницы, грубо говоря, и смещения на этой странице. То есть, они используют некий физический указатель.
По сути, это значит, что все индексы в PostgreSQL вторичные. Первичный индекс это просто некий алиас для вторичного. Организационно он устроен точно так же, нет никакой разницы.
Если опуститься на уровень ниже, я здесь использую упрощенный пример доклада Uber, посмотреть как данные хранятся в страницах или в блоках. Вот допустим, у нас есть таблица с именами и фамилиями известных математиков, так же год их рождения по этой колонке с годом рождения построен вторичный индекс и есть первичный ключ по некоторому ID, просто число. Вот так это примерно выглядит в InnoDB, схематично, вот так это выглядит в PostgreSQL. 
Что происходит при неиндексном обновлении? То есть, мы выполняем update, не затрагивая никакие колонки, по которым есть какие-то индексы, неиндексируемые колонки. В случае с InnoDB данные обновляются прямо в: первичном ключе, там, где они хранятся по месту, но нам нужны строчки, которые видны другим транзакциям, нужна некоторая история для строчек. Эти исторические данные, уезжают в отдельный сегмент под названием UNDO лог. Причем, уезжает не вся строка целиком, а только то, что мы поменяли. Так называемый, update вектор.
Соответственно, указатель во вторичном индексе, если он у нас есть, менять не нужно, потому что мы используем PRIMARY KEY. PRIMARY KEY не изменился, мы меняем только неиндексированные колонки, значит, ничего менять не нужно, просто старые данные переносим в UNDO лог и новые данные заносим прямо в таблицу. В PostgreSQL принципиально другой подход. если мы делаем неиндексированный update, мы вставляем другую полную копию строчки с новыми данными, но, соответственно, тогда индексы нужно тоже поменять. Указатели во всех индексах должны указывать на самую последнюю версию строчки. Соответственно, в них тоже вставляется еще одна запись, которая уже указывает не на старую версию строчки, а на новую.
Что происходит при индексированном update? Что, если мы обновляем какую-то индексированную колонку, вот год рождения здесь. В этом случае, InnoDB опять же вносит новую запись в UNDO лог и опять же указывает только те данные, которые изменились. Опять же, вторичный индекс не меняется. Ну, точнее, там вставляется новая, поскольку мы сейчас заменили индексированную колонку, вставляется новая запись — вторичный индекс, который указывает на ту же самую строчку. В PostgreSQL происходит то же самое, что и при неиндексированном update. Мы вставляем еще одну полную копию строчки и опять же обновляем все индексы. Вставляем новые записи в каждый индекс. И в первичный, и во вторичный. Если вторичных несколько, то в каждый вторичный. 
И в InnoDB, и в PostgreSQL накапливается такой мультиверсионный мусор. Старые версии строчек, которые нужно со временем удалять, когда не остается транзакций, которые теоретически могут их видеть. В случае с InnoDB за эту операцию отвечает система purge (очистка). Она проходит по UNDO логу и удаляет те записи из UNDO лога, которые больше не видны ни одной транзакции.
В случае с PostgreS за это отвечает процесс под названием «vacuum», который сканирует данные, поскульку у нас мультиверсионный мусор хранится вперемешку с самими данными, он проходит по всем данным и решает, вот эту строчку уже можно пометить как доступную для повторного использования или нет. То же самое с индексами. Из них тоже нужно удалить старые версии строчек.
Чем плох вакуум? На мой взгляд, vacuum — это самая архаичная, самая неэффективная система PostgreSQL. На это есть много причин и не потому, что она плохо написана. Нет, написана она хорошо. Это следует из того, как PostgreS организует данные на диске.
Во-первых, это решается сканированием данных. Не сканированием собственной истории, как в случае с InnoDB в UNDO логе, а сканированием данных. Там, конечно, есть некоторые оптимизации, которые позволяют, по крайней мере, избежать всего сканирования данных, а только определенных сегментов, которые обновлялись недавно, есть некоторая битовая маска, которая отмечает, что эти данные чистые, они не обновлялись с момента последнего vacuum, туда смотреть не нужно, но все эти оптимизации работают только для того случая, когда данные в основном хаотичны. Если у вас есть какой-то большой набор часто обновляемых данных, все эти оптимизации — мертвому припарки. Все равно нужно пройти по всем недавно обновленным страницам, и определить — эту запись можно выкидывать или нет, для каждой записи.Он выполняется так же в один поток. То есть, vacuum составляет список таблиц, которые нужно обновить и медленно и печально идет по одной таблице, потом по другой и так далее.
В InnoDB purge, например, можно параллелить на произвольное число потоков. По умолчанию сейчас используются 4 потока. И кроме того, на vacuum, от того, насколько эффективно и часто работает vacuum, завязана эффективность работы самого PostgreSQL. Разные оптимизации, выполнение запросов, как HOT, мы про это еще поговорим, или index-only scans, эффективность работы репликации также завязана на то, прошелся vacuum недавно или нет. Есть у нас этот мультиверсионный мусор или нет.
Если кому нужны кровавые детали, то Алексей Лесовский делал доклад «Девять кругов ада или PostgreSQL Vacuum». Там есть такая большая огромная диаграмма, которая показывает алгоритм работы vacuum. И об нее можно сломать мозг, если захотеть.
Теперь, собственно, к проблеме Uber. Первая проблема, которую они показывают — это write amplification. Суть в том, что даже маленькое неиндексное обновление может привести к большой записи на диск. Потому что нужно, во-первых, записать новую версию строки в heap, в кучу, обновить все новые индексы, что сама по себе дорогая операция. С вычислительной точки зрения, обновление индекса — дорогая. Хорошо, если еще это btree-индекс, а это могут быть какие-нибудь gin-индексы, которые очень медленно обновляются. Добавить новые записи, все эти страницы измененные и в самом heap, и в индексах, в итоге поедут на диск, кроме того, все это нужно записать в транзакционный журнал. Очень много записей для сравнительно маленького обновления.
Тут можно поговорить еще про оптимизацию в PostgreSQL, которая существует довольно давно, она называется «Heap-Only Tuples», НОТ updates. Uber в докладе не упоминает, не понятно, знали они про нее или, может быть, в их случае это не работало просто. Просто они про нее ничего не говорят. Но такая оптимизация есть. 
Смысл в том, что если и старая, и новая версии записи при индексном обновлении находится на одной странице, вместо того, чтобы обновлять индексы, мы со старой записи делаем ссылку на новую. Индексы продолжают указывать на старую версию. Мы можем по этой ссылке прыгнуть и получить новую версию, не трогая индексы. Вроде как бы все хорошо. Если появится еще одна строчка, мы делаем еще одну ссылку и получаем вот такую вот цепочку, которая называется «Hot chain». На самом деле, счастья полного нет, потому что вот это все работает до первого индексного обновления. Как только у нас приезжает первый update, который затрагивает индексы для этой страницы, нужно всю эту hot chain схлопнуть, потому что все индексы должны указывать на одну и ту же запись. Мы не можем для одного индекса изменить ссылку, а для других оставить.
Соответственно, чем больше индексов, тем меньше шансов у НОТ сработать и даже Роберт Хаас, он пишет в своем отзыве, что да, действительно есть такая проблема, и многие компании от нее страдают. Многие разработчики поэтому аккуратно относятся к созданию индексов. Теоретически индекс может быть даже и полезен был бы, но если мы его добавим, то update перестанут пользоваться вот этой оптимизацией Heap-Only Tuples. Во-вторых, очевидно, что эта оптимизация работает только в том случае, если на странице есть место. Ссылку можно поставить, только если старая и новая версия записи находятся на одной странице. Если новая версия записи переезжает на другую страницу, всё, никакой Heap-Only Tuples оптимизации.
Для этого, опять же PostgreSQL сделал некий костыль, что, пока мы будем ждать, пока vacuum дойдет, освободит нам место на странице, давайте будем делать такой мини vacuum или single gauge vacuum это называется. При каждом обращении к конкретной странице, мы будем немножко еще тоже пропылесосивать. Смотреть, какие записи можно убрать, если они не видны уже другим транзакциям. Освобождать место на странице и, соответственно, увеличивать шанс того, что НОТ оптимизация будет работать.
Это все неэффективно, опять же, если у вас есть много параллельных транзакций. Тогда шанс того, что текущие версии строчек не видны никакой выполняющей транзакции, он уменьшается. Соответственно, НОТ оптимизация перестает работать. Так же это не работает, когда есть, даже не много параллельных, а одна длинная транзакция, которая может в виде старых версий строчек на странице. Соответственно, мы не можем их удалить, тогда запись эта начинает переезжать на следующую страницу и опять же никакой НОТ оптимизации.
Что отвечает сообщество? Роберт Хаас достаточно сбалансировано говорит: «Да, есть проблема, НОТ оптимизация — не панацея, многие компании от этого страдают, не только Uber». И вообще, по-хорошему, я давно уже об этом говорю, нам нужно делать storage engine в MySQL. В частности, нам нужен storage engine, основанный на undo, а не то, что у нас сейчас есть. Кристоф Петус и Саймон Ригс говорят: «Есть же НОТ оптимизация. Раз Uber про нее не упоминает, значит, они ничего не знают про нее. Значит, они дураки». Кристоф, он человек воспитанный, когда он хочет сказать, что Uber дураки, он вставлял в презентацию смайлик, пожимающий плечами. «Что с них взять».
Александр Коротков говорит, что есть НОТ оптимизация, есть ограничения определенные, но дальше начинает перечислять список разных экспериментальных патчей, которые в десятку предстоящую mager версию не войдут и после перечисления этих экспериментальных патчей он приходит к выводу, что на самом деле, по-хорошему, нужно делать storage engine, основанный на undo. Все остальные оптимизации — это, скорее, подпорки, костыли под неэффективную систему организации данных в PostgreSQL.
Что все отвечающие упускают? Есть такое поверье, я часто его вижу, в том числе в каких-то российских сообществах, что просто Uber был какой-то специфичный случай. На самом деле, в этом нет ничего специфического. Это обычные для OLTP операции, для интернет проектов, очереди, счетчики какие-то, метрики, когда нужно обновлять не индексируемые колонки. Я ничего не вижу в этом специфического.
Во-вторых, ни один из отвечающих не сказал, что MVCC и организация данных на диске в PostgreSQL плохо подходят для OLTP нагрузок.
Так же, никто не сформулировал простой вещи, что полного решения проблемы нет и видимо будет не скоро. Даже экспериментальные патчи, они появятся, в лучшем случае, в PostgreSQL 11 и то, они скорее — это костыли и подпорки, а не радикальное решение проблемы на корню. Также, что проблема write amplification, которую описывает Uber, это некий довольно частный случай более общей проблемы. И над более общей проблемой в MySQL работают уже давно, есть оптимизированные на запись движки TokuDB/MyRocks сейчас набирают популярность. В этом плане в PostgreSQL все еще хуже. Нет каких-то даже теоретических альтернатив даже на горизонте.
MMVC и репликация
Вторая проблема, которую отмечает Uber — это репликация и проблемы с MMVC на репликах. Допустим, у нас есть репликация, мастер → реплика. Репликация в PostgreSQL физическая, то есть она работает на файловом уровне и все изменения в файлах, которые происходят на мастере, переносятся на реплику один в один. Фактически, мы в итоге строим побайтовую копию мастера. Проблема возникает в том случае, если реплику мы также используем, для того, чтобы крутить какие-то запросы. А на read only, там изменения вносить нельзя, но можно читать. Что делать в том случае, если у нас селект на реплике, если этому селекту нужны какие-то старые версии строчек, которые на мастере уже удалены, потому что на мастере этих селектов нет. Vacuum прошелся и удалил эти старые версии не зная о том, что на реплике или на репликах выполняются какие-то запросы, которые версии еще нужны. Здесь не так много вариантов. Можно придержать репликацию, остановить репликацию на реплике, пока этот селект завершится, но поскольку репликацию нельзя задерживать бесконечное время, есть некий таймаут по умолчанию — это max_standby_streaming_delay. 30 секунд, после которого транзакции, которые используют какие-то старые версии строчек, начинают просто отстреливаться. 
Uber еще замечает, что вообще у них были длинные транзакции в основном по вине разработчика. Были транзакции, которые, например, открывалась транзакция, потом открывался e-mail или совершался какой-то блокирующий ввод/вывод. Конечно, по идее, Uber говорит, что так делать нельзя, но идеальных разработчиков не бывает, к тому же, часто они используют какие-то формы, которые скрывают общий факт. Там не так просто определить, когда транзакция начинается, когда она заканчивается. Используются высокоуровневые формы.
Такие случаи все-таки возникали и для них это было большой проблемой. Либо репликация задерживалась, либо транзакции отстреливались, с точки зрения разработчика, в непредсказуемый момент. Потому что, сами понимаете, если мы, например, ждем 30 секунд и задерживаем репликацию, а после этого отстреливаем запрос, то, к тому моменту, когда запрос будет отстрелен, репликация уже отстала на 30 секунд. Соответственно, следующая транзакция может быть отстрелена практически мгновенно, потому что эти 30 секунд, этот лимит исчерпается очень быстро. С точки зрения разработчика транзакция в какой-то случайный момент… мы только начали, еще не успели ничего сделать, а уже нас перебивают.
Ответ сообщества. Все говорят, что нужно было использовать опцию hot_standby_feedback=on, нужно было ее включить. Кристоф Петус добавляет, что Uber просто дураки.
Эта опция имеет свою цену. Есть некие негативные последствия, иначе она была бы включена просто по умолчанию. В данном случае, если возвращаясь к этой картинке, что она делает. Реплика начинает передавать на мастер информацию о том, какие версии, какие транзакции открыты, какие версии строчек еще нужны. И в этом случае, мастер фактически просто придерживает vacuum, чтобы он не удалял эти версии строчек. Здесь тоже есть много всяких проблем. Например, реплики часто используются для тестирования, чтобы разработчики поигрались не на боевой машине, а не некоторой реплике. Представляете себе, разработчик, при тестировании начал какую-то транзакцию и пошел на обед, а в это время на мастере останавливается vacuum и в итоге заканчивается место и перестает работать оптимизация и в итоге мастер может просто умереть.
Или же другой случай. Реплики часто используются для какой-то аналитики, долгоиграющих запросов. Здесь тоже проблема. Мы запускаем долгоиграющий запрос с включенной опцией hot_standby_feedback=on, vacuum на мастере тоже останавливается. И тут получается, что для некоторых каких-то длинных аналитических запросов вообще нет никакой альтернативы. Либо они просто убивают мастер с включенной опцией hot_standby_feedback=on, либо, если она выключена, то они просто будут отстреливаться и никогда не завершатся.
О чем все молчат? Как я уже сказал, опция, которую все советуют, она задерживает vacuum на мастере и в PostgreSQL в свое время собирались сделать ее включенной по умолчанию, но предлагающим тут же объяснили, почему так делать не надо. Так просто советовать ее без всяких оговорок — это не очень честно, я бы сказал.
Ошибки у разработчиков случаются. Кристоф Петус говорит, что раз Uber не смог нанять правильных разработчиков, то они дураки. Ломается там, где тонко. Разработчики ошибаются там, где им позволяют ошибаться. Чего никто не сказал, так это то, что физическая репликация плохо подходит для масштабирования чтения. Если мы используем реплики для того, чтобы масштабировать чтение, крутить какие-то селекты, физическая репликация в PostgreSQL просто по архитектуре плохо подходит. Это был некий хак, который было легко реализовать, но у него есть свои пределы. И это опять же не специфический случай. Репликацию можно для разных целей использовать. Использовать эту репликацию для масштабирования чтения тоже достаточно типичный случай. Еще одна проблема, о которой сообщает Uber — это репликация и write amplification. Как мы уже осудили, на мастере при каких-то определенных обновлениях тоже происходит write amplification. Слишком много данных пишется на диск, но поскольку репликация в PostgreSQL физическая, и все изменения в файлах едут на реплики, то все эти изменения, которые в файлах происходят на мастере, едут в сеть. Она достаточно несбыточная, физическая репликация, по своей натуре. Возникают проблемы по скорости между разными дата центрами. Если мы реплицируемся с одного побережья на другое, то купить достаточно широкий канал, который бы вместил в себя весь этот поток репликации, который идет с мастера — это проблематично да и не всегда даже возможно.
Что отвечает сообщество на это. Роберт Хаас говорит, что можно было попробовать компрессию WAL, который передается в репликации по сети или SSL, там тоже можно включить на уровне сетевого соединения компрессию. А так же, можно было попробовать логическое решение репликации, которое в PostgreSQL доступно. Он упоминает Slony/Bucardo/Londiste. Саймон Ригс проводит лекцию о плюсах и минусах физической репликации, я бы тоже здесь все это написал, но за последнее время я так часто об этом говорил, что мне это уже несколько надоело, я полагаю, что все примерно представляют себе, чем логическая репликация отличается от физической. Так же, добавляют, что скоро будет pglogical — это встроенное решение для логической репликации в PostgreSQL, которое разрабатывает его компания.
Кристоф Петус говорит, что не нужно сравнивать логическую и физическую репликацию. Но это странно, потому что именно это делает Uber. Он сравнивает плюсы и минусы логической и физической репликации, говоря, что физическая репликация для них не очень подходит, а вот логическая репликация в MySQL, как раз, хорошо. Не понятно, почему не надо сравнивать. Он добавляет, что Slony, Bucardo сложно установить и сложно ими управлять, но это же Uber. Раз они не смогли это сделать, значит, они дураки. И, к тому же, в версии 9.4 есть pglogical. Это стороннее пока что расширение для PostgreSQL, которое организует логическую репликацию. Нужно сказать, что Uber использовал более старые версии PostgreSQL, 9.2, 9.3, для которых нет pglogical, а переехать на 9.4 они не могли. Я дальше расскажу почему.
Александр Коротков говорит, что Uber сравнивает логическую репликацию в MySQL и физическую. Совершенно верно. Именно это он и делает. В MySQL нет физической репликации и Alibaba работает над тем, чтобы добавить физическую репликацию в MySQL — это тоже верно, только Alibaba это делает уже для совершенно другого use case. Alibaba это делает для обеспечения high availability для своего облачного приложения внутри одного датацентра. Они не используют кросс-региональную репликацию, они не используют чтение с реплик. Это используется только для того, если у облачных клиентов упадет сервер, чтобы они быстро могли переключиться на реплику. Только и всего. То есть, этот use case отличается от того, что использует Uber.
Еще одна проблема Uber, о которой они говорят — это кросс-версионные обновления. Нужно перейти с одной мажорной версии на другую и желательно бы это сделать без остановки мастера. Вот в PostgreSQL с физической репликацией эта проблема не решается. Потому что, обычно, в MySQL делают как. Апгрейдят сначала реплики, или одну реплику, если она только одна, на более старшую версию, потом переключают на нее запросы… фактически делают ее новым мастером, а старый мастер апгрейдится на новую версию. Получается, downtime минимальный. Но с физической репликацией в PostgreSQL нельзя реплицировать с младшей версии на старшую и вообще версии должны быть одинаковые и на мастере и на реплике. Pglogical, опять же, был для них не вариант, потому что они использовали более старые версии и на 9,4, с которого pglogical доступна, они переехать не могли, потому что не было репликации. Рекурсия такая.
Некоторые их legacy сервисы, а в Ubere они до сих пор остались, они до сих пор работают на PostgreSQL 9.2 по этой простой причине.
Ответ сообщества. Роберт Хаас никак это не комментирует. Саймон Ригс говорит, что вообще-то есть pg_upgrade — это процедура собственного апгрейда и с опцией -k, когда используются хардлинки этот процесс занимает меньше времени, поэтому downtime все равно будет, мастер придется останавливать и все запросы тоже придется останавливать. Ну, не так уж это может быть и долго. Кроме того, Саймон Риггс говорит, что у них в компании есть коммерческое решение, которое позволяет интегрировать старые версии на новые:).
Кристоф Петус говорит, что pg_upgrade — это не панацея, в частности PostGIS, геоинформационное расширение, из-за которого Uber перешли на PostgreSQL вызывают очень много проблем при апгрейде между мажорными версиями. Я не знаю, я ему здесь верю, потому что он консалтер по PostgreSQL. Он говорит, что Uber не осилили, опять же, Slony/Bucardo, pglogical, значит, они дураки. Александр Коротков показывает, как можно сделать апгрейд между мажорными версиями, используя pglogical.
Наш доклад называется: «Ответ Uber-у», то для Uber это был не вариант. Ответ текущим пользователям, то там тоже есть свои нюансы.
О чем все молчат? Да, действительно есть всякие сторонние решения для PostgreSQL, которые организуют логическую репликацию Slony/Bucardo/Londiste, но все они trigger-based, все они основаны на триггерах, то есть, на каждую таблицу развешивается триггер, при любом обновлении мы берем эти изменения, которые внесли и записываем их в специальную реляционную журналируемую таблицу, а потом, когда они переезжают на реплики, все эти изменения из реляционной таблицы, мы их удаляем. И тут возникают типичные проблемы. Болячка PostgreSQL с Vacuum, когда данные часто вставляются и удаляются, очень много работы для vacuum, соответственно, куча всяких проблем. Не говоря про то, что само trigger-based решение, оно не очень эффективно, сами понимаете, а данные из таблиц вытаскиваются вообще какими-то внешними скриптами. Не в самой СУБД, а написанными на перле или на питоне, там по-разному, все зависит от решения и перекладываются уже на реплики.
С pglogical все очень странно. Все посоветовали, что pglogical может быть использован для апгрейдов с младшей версии на новую. Я прочитал документацию, разработчики не обещают, что такая кросс-версионная репликация будет работать. Они говорят, что может работать, но в будущих версиях что-то может разъехаться и, в общем, мы ничего не обещаем.
Низкая «обкатность» даже сейчас, в 2017 году. Это сравнительно новая технология, она, конечно, прогрессивная, потенциально использует какие-то встроенные вещи в PostgreSQL, а не какие-то там внешние решения, но я не очень понимаю, как это Uber можно было рекомендовать для использования в productions в 2015 году, когда pglogical вообще только начал разрабатываться. Но чем хорош pglogical, тем, что в отличие от основного PostgreSQL, можно пойти и посмотреть багтрекер, чтобы оценить стабильность проекта, взрослость проекта, насколько широко он используется. Честно говоря, меня это не впечатлило. На меня это не произвело впечатления какого-то стабильного проекта. 
Активность очень низкая, есть некоторые баги, которые висят уже там годами. У кого-то проблемы с перфомансом, у кого-то проблема с потерей данных. Вот не производит впечатление какого-то стабильного проекта. У меня в хобби-проекте (sysbench) на гитхабе активность больше, чем в pglogical.
О чем все еще не говорят? Что у всех этих проблем, у всех этих решений, сторонних и встроенных pglogical есть проблемы с sequences, потому что на них нельзя повесить триггер и изменения не записываются в транзакционный журнал, а значит, приходится делать какие-то специальные сложные приседания, чтобы обеспечить репликацию sequences. DDL только через функции-обертки, потому что, опять же на DDL нельзя повесить триггеры и почему-то они в PostgreSQL не записываются в транзакционный журнал. У всех трех решений нет журнала как такового, то есть, нельзя взять какой-нибудь backup и накатить логические изменения из какого-то журнала как в MySQL. Можно только физический backup, но, чтобы сделать физический PITR, вам нужен физический backup. На логический back up вы его не накатите. Нет GTID, какие-то последние вещи, которые появились в репликации в MySQL. Я так и не понял, как с помощью этих решений сделать перепозиционирование. Скажем, переключить slave реплику с одного мастера на другой и понять какие транзакции уже были проиграны, а какие нет.
Наконец, нет никакого параллелизма. Единственный способ ускорить логическую репликацию — это ее распараллеливать. В MySQL проделана огромная работа в этом направлении. Все эти решения не поддерживают параллелизм вообще ни в каком виде. Его просто нет.
Что все упускают? Во-первых, есть только один правильный сценарий применения физической репликации в PostgreSQL или в MySQL, когда она где-нибудь появится или где-нибудь еще. Это High Availability внутри одного датацентра, когда у нас есть достаточно быстрый канал, и, когда не нужно читать с реплик. Это единственный правильный use case. Все остальное может работать, а может и нет, в зависимости от того, какая нагрузка и от многих других параметров.
На сегодня полной альтернативы репликации в MySQL PostgreSQL предложить не может. Рglogical странная вещь. Многие говорят, что в PostgreSQL 10 появится pglogical, встроенная логическая репликация, на самом деле мало кто в Postgres community знает, что войдет в 10 некий урезанный вариант рglogical. Я так и не нашел какого-то внятного описания, что же именно войдет, а что останется за бортом. Кроме того, что синтаксис в 10 будет использоваться несколько отличный от того, что использовало стороннее расширение рglogical. Не понятно, можно будет как-то их использовать совместно. Можно ли реплицировать рglogical со старых версий в PostgreSQL 10 или нет. Я нигде не нашел. Документация у рglogical тоже своеобразная.
Неэффективный кеш
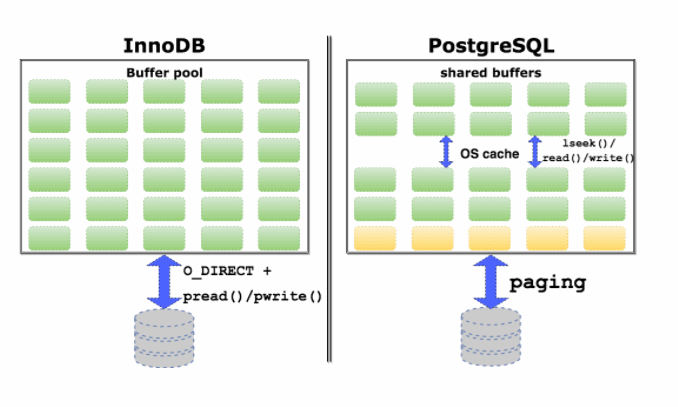
И, наконец, неэффективный кэш. В чем отличие реализации кэша в InnoDB и PostgreSQL. InnoDB использует небуферизованный ввод/вывод не полагаясь на собственный кэш операционной системы, поэтому, всю память, вся максимально доступная память на машине отводится под InnoDB кэш. InnoDB использует обыкновенные pread and pwrite системные вызовы, для того, чтобы осуществлять ввод/вывод небуферизованный. Не полагаясь на кэш операционной системы.
У PostgreSQL другая архитектура. Почему-то поддержку direct I/O небуферизованного ввода/вывода не сделали до сих пор, поэтому, PostgreSQL полагается и на свой собственный кэш и на кэш операционной системы одновременно. Кроме того, он почему-то использует не такие системные вызовы, которые позволяют сразу сместиться и прочитать что-либо и записать, а сначала отдельный системный вызов, чтобы сместиться на нужную позицию, а потом прочитать и записать. Два системных вызова на одну операцию. Тут происходит некоторое дублирование данных. Страницы памяти данных будут храниться и в собственном кэше и в кэше операционной системы.
Роберт Хаас и Саймон Ригс не отвечают ника на это. Кристоф Петус, что-то с ним случилось, он не называет Uber дураками здесь, согласен, что есть проблема, но не ясен эффект на практике. Александр Коротков говорит, что pread вместо lseek дает оптимизацию только 1,5 процента производительности, но это часть проблем, которые перечисляет Uber. Больше ничего не говорит.
Что все опускают? Что 1,5% были получены на одном бенчмарке на ноутбуке разработчика, который разработал этот патч. Экспериментально там было некое обсуждение в списке рассылок Postgres hackers, и патч, в итоге, застрял в обсуждениях. Роберт Хаас говорил, что этот патч нужно включить. Даже 1,5% это скорее всего на боевых системах будет больше, даже 1,5% — это уже хорошо, а Том Лэйн, другой ключевой разработчик PostgreSQL был против, говорил, что не нужно трогать стабильный код из-за каких-то 1,5%. В общем, два ключевых разработчика не нашли понимания и патч в итоге застрял. Он никуда не пошел.
Это далеко не единственная проблема в дизайне shared buffers, я в своем прошлогоднем докладе на DevConf это подробно все раскрывал. Там есть гораздо больше проблем, чем перечисляет Uber. Там есть дублирование данных, есть проблема с двойным вычислением контрольных сумм, есть проблема с «вымыванием» данных из кэша операционной системы, что InnoDB со своим кэшем может предотвратить. А в будущем, если в PostgreSQL появится компрессия и шифрование, там тоже начнутся проблемы с такой архитектурой.
Что мы видим в итоге. Uber, я разговаривал с ними, и они также делали доклады на конференциях, на Percona live. Они говорят, что: «Мы в целом довольны MySQL, мы не собираемся никуд
