Demeter: реактивное профилирование Android-приложений

Всем привет, меня зовут Вадим Мезенцев, я Android‑разработчик в команде Яндекс Go. Сегодня я хочу рассказать историю о том, как мы искали подход к профилированию нашего приложения, с какими проблемами столкнулись и как в итоге реализовали библиотеку для измерения производительности.
Наша команда часто сталкивалась с проблемами при поиске «узких мест» в производительности приложения. Мы пробовали различные инструменты профилирования, но все они требовали слишком много времени на сбор метрик, анализ и фильтрацию нужных данных. Чтобы решить эту проблему, мы разработали собственное решение, которое сочетает скорость анализа и простоту поиска проблем. Мы создали библиотеку Demeter, которую легко интегрировать в отладочную версию Android‑приложения. Она позволяет получать отчёты о производительности во время использования приложения и переходов между экранами. Такую сборку можно передать команде тестирования, а затем проанализировать отчёты и изучить изменения.
Для чего нужно измерять производительность
Итак, первое, что нужно сделать, — определить цель, с которой мы хотим что‑то измерить. В нашем случае, когда пользователь открывает Яндекс Go, ему нужно быстро сделать заказ, сесть в машину и поехать. Долгий экран загрузки — потеря времени пользователя, у которого могут сорваться планы, и его уход в другое приложение. Это потери и для пользователя, и для бизнеса — нам такое точно не нужно.
Чтобы измерить производительность, обратимся к истокам: Google предлагает нам разделить на три части все существующие проблемы с производительностью: Slow Frames, Frozen Frames и ANRs.

В Slow Frames попадают проблемы от 16 мс, потому что они привязаны к времени отрисовки одного кадра. Например, для того чтобы обеспечить 60 FPS (60 кадров в секунду), время отрисовки одного кадра должно составлять не больше чем 11 мс. Всё, что выше, — это проблема. Для 90 и 120 FPS мы должны обеспечить и того меньшее время работы каждой функции. Мы будем фокусироваться на таких местах и исправлять их.
В идеале нужно не только придумать процесс поиска проблем с производительностью, но и автоматизировать его: разобраться, как запустить исследование, организовать сбор данных, получить отчёты и потом использовать наши инструменты для более точного анализа.
Прежде всего надо посмотреть, какими инструментами пользуются другие. В автоматике это Firebase Performance Metrics и сочетание Pulse и PerfTests (мы их тоже используем и дополняем кастомными метриками). По инструментам рассмотрим Profiler, Perfecto и YAMP — они принадлежат к одному семейству и помогают анализировать stack trace, а также нашу собственную библиотеку Demeter.
Инструменты для измерения производительности
Firebase. Этот инструмент автоматически замеряет время старта приложения — можно просто подключить библиотеку и получить готовые отчёты форграунда и бэкграунда. Firebase предоставляет данные о Slow‑ и Frozen Frames, позволяя классифицировать их по группам, а также визуализировать процент проблем, включая ANRs, на графиках в отчёте.

Firebase автоматически собирает все базовые метрики, но если всё же будет чего‑то не хватать — вы можете добавить собственные, и они автоматически прорастут в веб‑интерфейс. Так у вас на руках будет богатая информация о том, какие девайсы используют пользователи, и можно строить дальнейшие гипотезы, опираясь на эти данные.
PerfTests. Инструмент, который мы используем внутри Яндекса. Он позволяет запускать инструментальные тесты в изолированной среде. Эти тесты выполняются регулярно в замкнутом контуре и могут повторяться заданное количество раз. Интерфейсом для отображения результатов для PerfTests выступает Pulse.

PerfTests удобны тем, что мы можем понять, где конкретно «затаилась» проблема, запустить Bisect, найти нужный коммит и всё исправить. Но из‑за того, что писать PerfTests непросто, создаётся много false positive‑информации и, соответственно, задач. Чтобы разобрать их, уходит очень много времени.
Хотя тесты автоматически находят аномалию и автора PR (Pull Request), команда должна регулярно выделять время на то, чтобы разбирать эти инциденты. К тому же писать тесты довольно непросто: каждый из них должен быть изолирован, нужно уметь сохранять все сетевые ответы, поддерживать работоспособность этих тестов при написании нового функционала. В общем, работы очень много.
Далее рассмотрим способ сбора Custom Metrics (собственных метрик) через AppMetrica и их самостоятельный анализ.

Для отображения данных мы используем DataLens, куда собираем различные события приложения, включая события, связанные с производительностью. Для сбора такой информации можно в начале функции замерить время её выполнения, а в конце — отправить данные о времени в AppMetrica.
Например, для измерений мы отправляем параметр timeSinceAppLaunch. Здесь обозначается время с момента запуска приложения и продолжительность (duration) для отображения времени этого события. Это позволяет точно понимать, в какой момент мы начали измерение и сколько оно длилось.
Так мы можем получить информацию о работе конкретной функции у разных пользователей, а также узнать подробности об их окружении и о том, как метод работает на реальных устройствах. На основе этих данных мы можем строить гипотезы и принимать решения для устранения проблем с производительностью. Однако стоит учитывать, что эти данные поступают с задержкой, так как обновления приложений до пользователей доходят не сразу, и, соответственно, события появляются позже, чем нам хотелось бы.

Из плюсов этого ручного добавления событий: мы можем легко добавлять новую метрику, контролировать то, что измеряем, а также получать много дополнительной информации об окружении. Из минусов — команда должна выделять время на то, чтобы регулярно покрывать свой код новыми метриками и следить за их достоверностью.
Какие проблемы могут возникать с измерением производительности
Итак, у нас есть различные инструменты для сбора отчётов. Теперь важно определить, где именно возникают проблемы и как их можно решить.
Для этого мы можем воспользоваться Android Profiler или Perfetto, которые позволяют анализировать stacktrace и детально изучать происходящее. Эти инструменты помогают выявить задержки, визуализировать проблемные участки и точно определить, на каком этапе что‑то идёт не так.

Также есть инструмент YAMP. Это модифицированный Profiler, его тоже используют мобильные разработчики разных команд в Яндексе. Он удобен тем, что в нём можно фильтровать, подсвечивать и модифицировать все события.

Оба инструмента объединяет одна проблема — в них нельзя просмотреть все возможные методы. Например, чтобы добавить в Profiler нужный метод для анализа, необходимо вручную написать код, открыть секцию, указать метод, закрыть, перекомпилировать — и только после этого данные станут доступны. Это не всегда удобно.

Итак, у нас есть целый «зоопарк» полезных инструментов, но для того, чтобы ими пользоваться, нужно приложить много усилий для анализа либо дождаться момента, когда данные будут готовы. Но мы хотим уменьшить это время и упростить способ поиска проблем в коде.
При этом не хотим отказываться от имеющихся инструментов: наша цель — дополнить и ускорить исследования. Так появилась идея сделать библиотеку, которая будет автоматически показывать время выполнения методов во время работы приложения, добавлять информацию для профайлера для более детального stacktrace, а также отображать время инициализации зависимостей для Dagger и количество рекомпозиций для Compose.
Как мы сделали Demeter
Мы хотим понять, почему какая‑то функция выполняется очень долго. Хочется видеть, что привело к длительной загрузке, какая функция выполнялась долго, а главное — получить возможность видеть сразу такие функции в одном месте. Для этого мы начали делать Demeter.
Рассмотрим какую‑то абстрактную функцию heavyOperation. Как понять, что именно она долго загружается?

А теперь заменим логирование вызовом отдельной функции, например TraceMetricsHolder.log, чтобы собирать информацию в одном месте.


Но такой подход неудобен и трудозатратен, поэтому мы автоматизировали процесс (о деталях расскажу чуть ниже). В результате мы получили систему, которая анализирует все инжектированные объекты: фиксирует время выполнения методов, время создания классов и потоки исполнения, в которых они работают. Данные также можно экспортировать в CSV‑формат, чтобы было удобно загрузить в трекер и сравнить с предыдущими результатами.
Нам было интересно проанализировать время конструирования dagger‑зависимостей, поэтому мы написали такой анализатор, который работает с аннотациями @Inject.

Чтобы полностью разобраться в происходящем внутри приложения, мы покрыли мониторингом все методы, включая методы подключаемых библиотек. Это позволило отслеживать, какие операции выполняются в каждый момент времени.
Особенно полезно это оказалось в нашем приложении Яндекс Go, где используется множество SDK. Мы сразу видели, если новая библиотека замедляет работу, и могли быстро разобраться в причинах. Также мы оперативно выявляли медленные методы у коллег, заводили задачи и оперативно их исправляли.

Также мы разработали небольшой Compose‑анализатор, чтобы отслеживать частоту рекомпозиций и выявлять то, что вызвало эти рекомпозиции.

Чтобы добиться такой автоматики, мы использовали два подхода: один основан на ASM Visitor Factory, а второй — на Kotlin Compiler Plugin.
ASM Visitor Factory

Перед тем как приступить к написанию ASM Class Visitor, важно понять общий процесс сборки приложения: как исходный код превращается в исполняемый файл.
ASM преобразует код после того, как он будет упакован в.dex‑файл, а это значит, что все подключённые библиотеки, в том числе и сторонние, уже будут в dex‑файлах, а мы можем влиять на них и изменять код. В нашем случае сможем его проанализировать.

Наша цель — добавить вызов специального метода во все методы приложения, чтобы замерять их время выполнения. Для этого ASM позволяет переопределить ClassVisitor, где мы создаём собственный визитор и указываем, с какими пакетами будем работать, какие методы переопределять и какую логику применять.
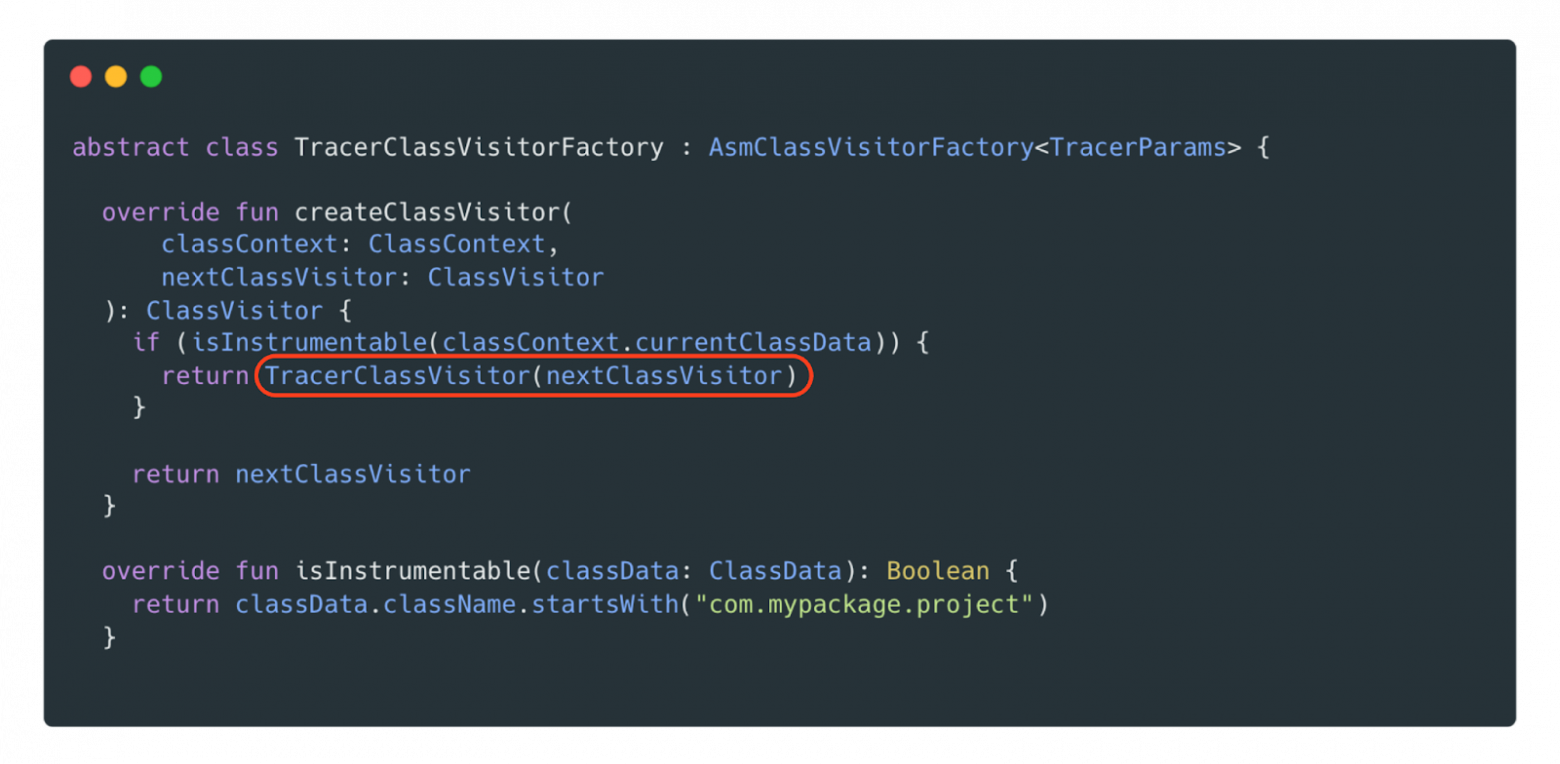
В переопределённом методе isInstrumentable определяются места, с которыми будет работать наш Visitor, и в данном случаем мы указали пакет com.mypackage.project. Если метод isInstrumentable будет возвращать true, то значит, мы будем анализировать абсолютно весь код, который есть в нашем приложении, в т. ч. все подключённые библиотеки. Так как нам нужно переопределить всего лишь методы, то мы возьмём из Class Visitor метод visitMethod и воспользуемся вспомогательным классом AdviceAdapter.
Переопределяем visitMethod, воспользовавшись помощью AdviceAdapter. В данном случаем мы создаём новую реализацию ExampleMethodAdapter, унаследованную от AdviceAdapter. Это поможет использовать более высокий уровень абстракции, чтобы совсем глубоко не погружаться в работу Opcodes и использовать готовые реализации.

Из AdviceAdapter возьмём и переопределим два метода: onMethodEnter и onMethodExit. В onMethodEnter нам необходимо вызвать метод для замера текущего времени и сохранить результат. Однако, в отличие от Kotlin и Java, здесь мы не можем просто сохранить значение в переменную. Нам нужно определить смещение в стеке, куда оно будет записано. Для этого AdviceAdapter предоставляет метод newLocal, который автоматически находит подходящее смещение и резервирует необходимое место в локальных переменных.
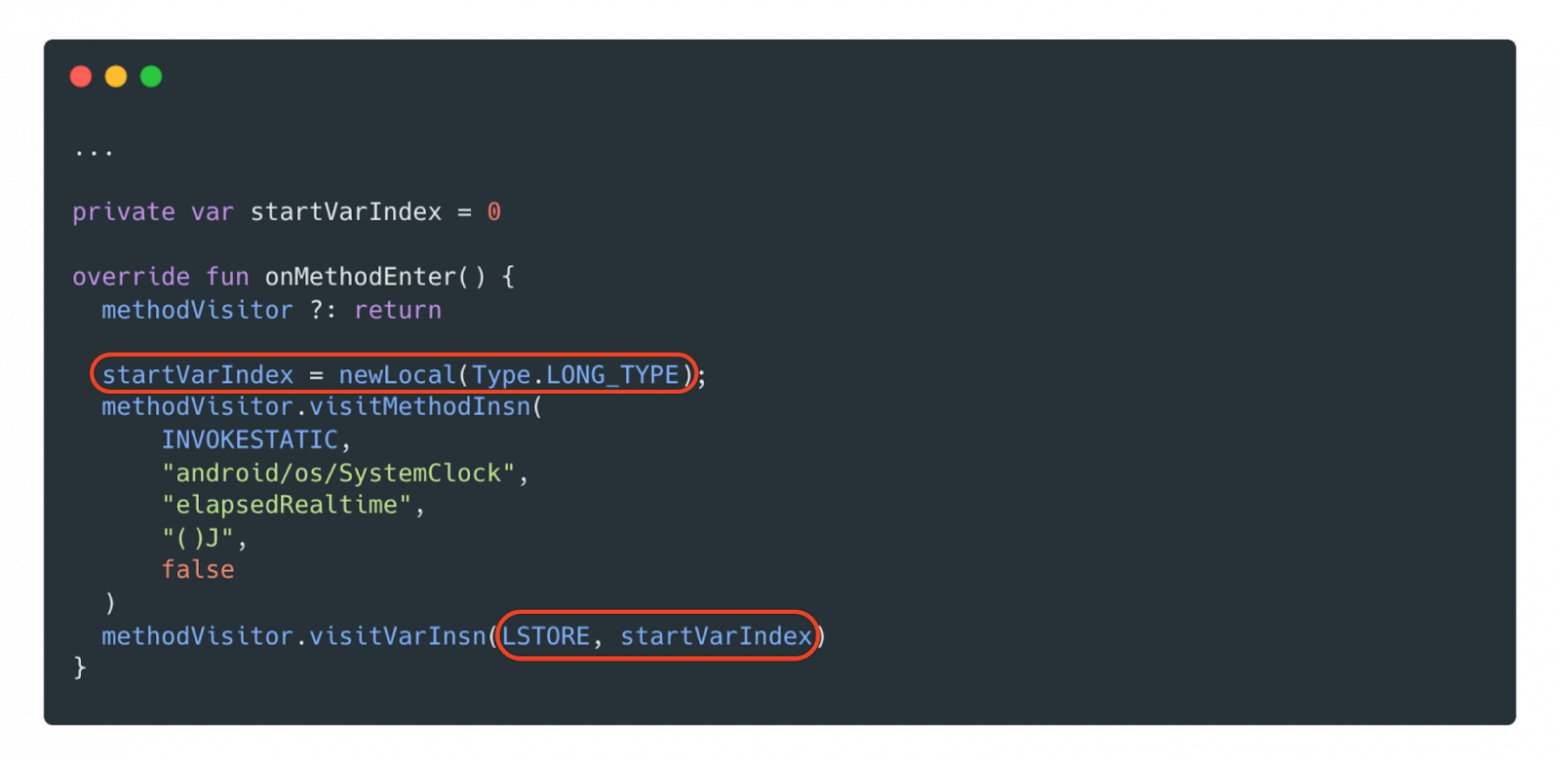
После этого мы должны сохранить переменную при помощи Opcode LSTORE с указанием смещения. Вызванный метод SystemClock.elapsedRealtime запишет текущее время в эту переменную, а дальше на выходе из функции эту переменную будем считывать.
На onMethodExit нас интересует только Opcode RETURN, поэтому ограничимся только им и получим данные из ранее сохранённой переменной через LLOAD. Осталось только вызвать статическую функцию TraceMetricsHolder, куда передадим значение начала замера.

Теперь нам осталось настроить плагин для Gradle, чтобы он выполнялся при компиляции после упаковки.dex. Тут нам достаточно указать наш Visitor Class и scope, где мы будем исследовать и трансформировать наш код. Если, например, указан all, то это значит, что мы будем трансформировать вообще все подключённые библиотеки. Но можно ограничиться только своим проектом, указав PROJECT.

Kotlin Compiler Plugin

Второй подход, который мы использовали, — Kotlin Compiler Plugin. Возвращаясь к той же схеме преобразования кода, можно обратить внимание, что он работает на преобразование именно исходного кода. Это значит, он не умеет взаимодействовать с подключёнными библиотеками. Посмотрим, как это происходит, на примере исследования Compose‑рекомпозиций в Demeter.

Фронтенд‑часть Kotlin Compiler Plugin отвечает за построение синтаксического дерева и анализ исходного кода, но в моём примере это неважно. Меня интересует генерация и модификация кода, поэтому я буду работать с бэкенд‑частью, а именно с JVM.
Допустим, у нас есть простая @Composable‑функция, отвечающая за ввод текста. Чтобы замерить количество рекомпозиций, посмотрим, как эта функция транслируется в java‑код.
Изначальная функция:

То, как компилятор преобразует Compose‑функцию в java‑код:

Как видно, сгенерированный код стал более объёмным. Чтобы определить, когда функция начинает рекомпозицию, нужно найти и залогировать метод updateScope. Для этого нужно добавить логирование сразу после вызова updateScope, и как раз для этого нам понадобится Kotlin Compiler Plugin, а именно transform с переопределением visitCall.
Добавим свой метод notifyRecomposition после updateScope:

Чтобы сделать это, создадим Transformer, унаследовав от класса IrElemetTransformerVoidWithContext из Kotlin Compiler Plugin и переопределив метод visitCall. В нём найдём вызов updateScope и попробуем сразу же его преобразовать — в коде это transformRecomposeCall.

transformRecomposeCall ищет по названию целевую функцию и при помощи irBlockBodyBuilder добавляет необходимый вызов для логирования. Не стоит забывать добавить в visitCall текущую функцию, иначе она потеряется и просто «вырежется».

irRecompose — extension‑функция для преобразования, которую рассмотрим ниже.

Если преобразование удалось, то сначала нужно добавить «модифицированную» функцию, а после — свой метод.
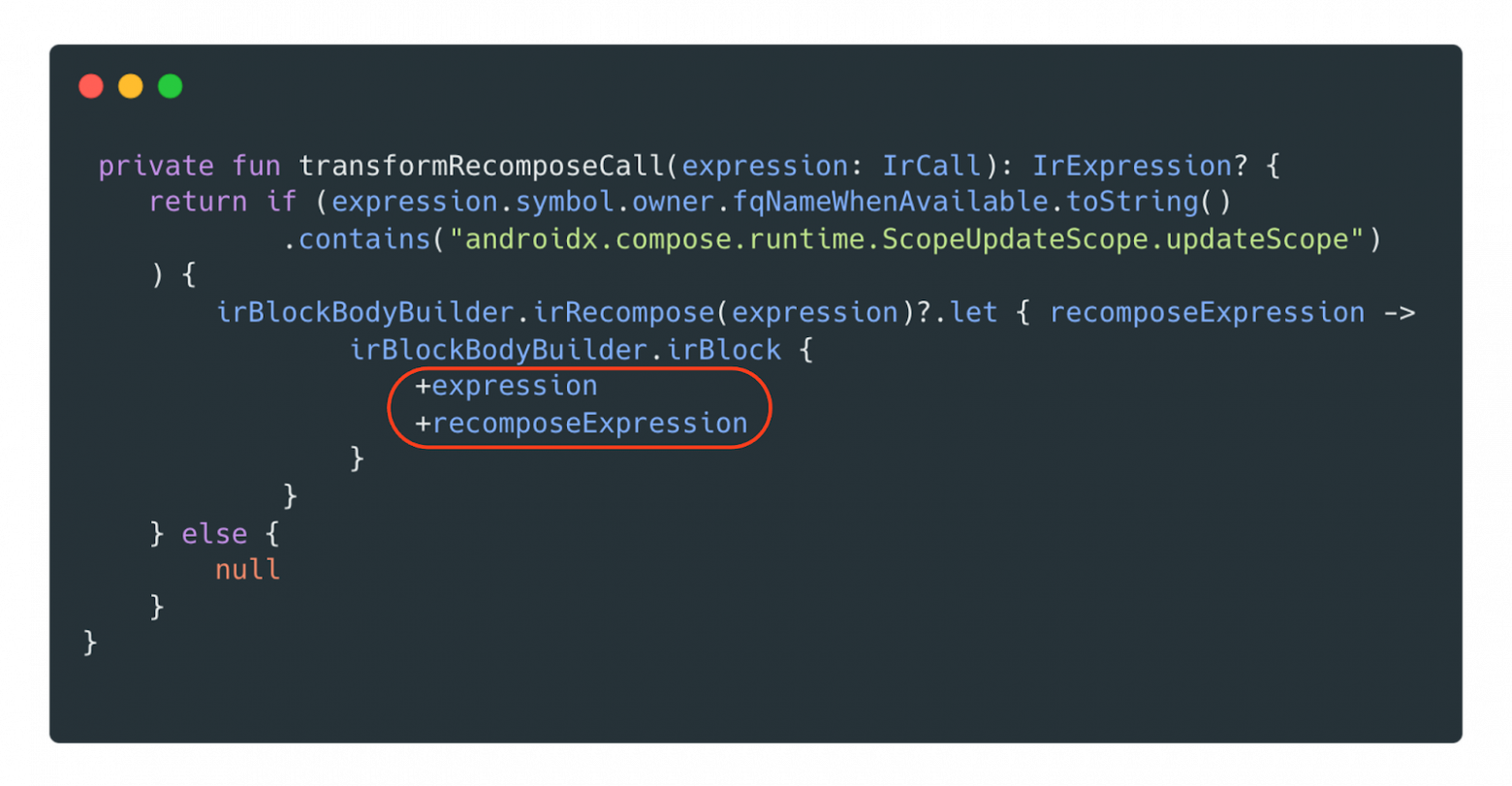
Чтобы добавить в проект свой вызов, нужно извлечь из текущего контекста нашу функцию — в данном случае notifyRecomposition из Demeter. Мы уверены, что этот метод есть, поэтому вызываем его без дополнительных проверок. Так получаем callable, с которым будем работать.

Возвращаемся к реализации extension‑функции irRecompose. Так как анализируемая функция должна быть @Composable, то значит, её первым аргументом должен быть composer. Если этот аргумент присутствует — отлично, мы можем модифицировать код и добавлять нужную нам функцию.

Создаём новый call, который добавим в функцию, существующий RecomposeNotifyFunction и передаём ей нужный аргумент.

Итак, в нашем проекте используется два подхода: ASM и Kotlin Compiler Plugin. Их плюсы и минусы:

Мы использовали два подхода ещё и потому, что, когда разработчики видят код на ASM, это обычно не вызывает у них радости: мало кто горит желанием с ним разбираться. Зато есть удобный и дружелюбный Kotlin Compiler Plugin, с которым работать гораздо приятнее. Благодаря ему мы можем вносить нужные изменения без лишних сложностей, и при этом не всегда приходится залезать в сторонние библиотеки.
Вывод
Мы искали способ ускорить поиск просадок в коде. Существующие инструменты достаточно хорошие, но не позволяют быстро находить слабые места. И мы написали свой инструмент, который позволяет быстро находить проблемные участки кода.
Достаточно собрать проект — и эту сборку можно передавать QA. Они смогут протестировать нужные экраны, зафиксировать замеры, а затем экспортировать данные разработчикам. Это поможет понять, сколько времени заняло выполнение кода на разных устройствах и что происходило в процессе.
Кроме того, мы сможем выявлять просадки производительности ещё на этапе пул‑реквеста, не дожидаясь выхода в прод. А с помощью Demeter можно анализировать и сторонние библиотеки. Для этого мы разработали систему расширения функциональности, которая позволяет легко добавлять новые плагины, что значительно упростило жизнь разработчикам.
Мы выложили библиотеку в опенсорс — она доступна на GitHub — и будем рады предложениям, как её улучшить для ещё большего ускорения анализа.
