Делаем поиск в веб-приложении с нуля
В статье «Делаем современное веб-приложение с нуля» я рассказал в общих чертах, как выглядит архитектура современных высоконагруженных веб-приложений, и собрал для демонстрации простейшую реализацию такой архитектуры на стеке из нескольких предельно популярных и простых технологий и фреймворков. Мы построили single page application с server side rendering, поддерживающее просмотр неких «карточек», набранных в Markdown, и навигацию между ними.
В этой статье я затрону чуть более сложную и интересную (как минимум мне, разработчику команды поиска) тему: полнотекстовый поиск. Мы добавим в наш контейнерный рай ноду Elasticsearch, научимся строить индекс и делать поиск по контенту, взяв в качестве тестовых данных описания пяти тысяч фильмов из TMDB 5000 Movie Dataset. Также мы научимся делать поисковые фильтры и копнём совсем немножко в сторону ранжирования.
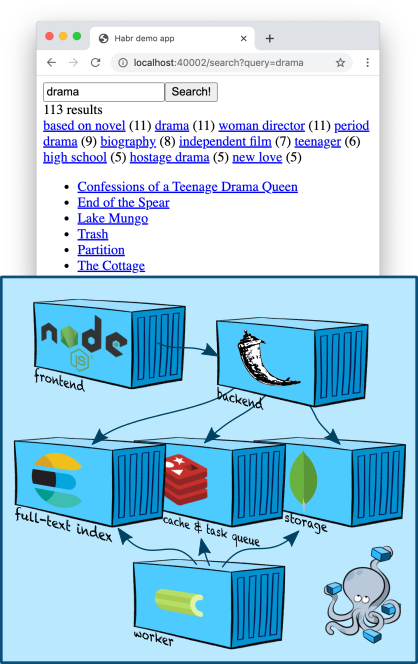
Инфраструктура: Elasticsearch
Elasticsearch — популярное хранилище документов, умеющее строить полнотекстовые индексы и, как правило, используемое именно как поисковый движок. Elasticsearch добавляет к движку Apache Lucene, на котором он основан, шардирование, репликацию, удобный JSON API и ещё миллион мелочей, которые сделали его одним из самых популярных решений для полнотекстового поиска.
Давайте добавим одну ноду Elasticsearch в наш docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
Переменная окружения discovery.type=single-node подсказывает Elasticsearch, что надо готовиться к работе в одиночку, а не искать другие ноды и объединяться с ними в кластер (таково поведение по умолчанию).
Обратите внимание, что мы публикуем 9200 порт наружу, хотя наше приложение ходит в него внутри сети, создаваемой docker-compose. Это исключительно для отладки: так мы сможем обращаться в Elasticsearch напрямую из терминала (до тех пор, пока не придумаем более умный способ — об этом ниже).
Добавить клиент Elasticsearch в наш вайринг не составит труда — благо, Elastic предоставляет минималистичный Python-клиент.
Индексация
В прошлой статье мы положили наши основные сущности — «карточки» в коллекцию MongoDB. Из коллекции мы умеем быстро извлекать их содержимое по идентификатору, потому что MongoDB построила для нас прямой индекс — в ней для этого используютсяB-деревья.
Теперь же перед нами стоит обратная задача — по содержимому (или его фрагментам) получить идентификаторы карточек. Стало быть, нам нужен обратный индекс. Для него-то нам и пригодится Elasticsearch!
Общая схема построения индекса обычно выглядит как-то так.
- Создаём новый пустой индекс с уникальным именем, конфигурируем его как нам нужно.
- Обходим все наши сущности в базе и кладём их в новый индекс.
- Переключаем продакшн, чтобы все запросы начали ходить в новый индекс.
- Удаляем старый индекс. Тут по желанию — вы вполне можете захотеть хранить несколько последних индексов, чтобы, например, удобнее было отлаживать какие-то проблемы.
Давайте создадим скелет индексатора и потом разберёмся подробнее с каждым шагом.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# Построение нового индекса.
# Сначала придумываем для индекса оригинальное название.
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# Создаём пустой индекс.
# Здесь мы укажем настройки и опишем схему данных.
self.create_empty_cards_index(index_name)
# Кладём в индекс все наши карточки одну за другой.
# В настоящем проекте вы очень скоро захотите
# переписать это на работу в пакетном режиме.
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
Индексация: создаём индекс
Индекс в Elasticsearch создаётся простым PUT-запросом в /имя-индекса или, в случае использования Python-клиента (нашем случае), вызовом
elasticsearch_client.indices.create(index_name, {
...
})
Тело запроса может содержать три поля.
- Описание алиасов (
"aliases": ...). Система алиасов позволяет держать знание о том, какой индекс сейчас актуальный, на стороне Elasticsearch; мы поговорим про неё ниже. - Настройки (
"settings": ...). Когда мы будем большими дядями с настоящим продакшном, мы сможем сконфигурировать здесь репликацию, шардирование и другие радости SRE. - Схема данных (
"mappings": ...). Здесь мы можем указать, какого типа какие поля в документах, которые мы будем индексировать, для каких из этих полей нужны обратные индексы, по каким должны быть поддержаны агрегации и так далее.
Сейчас нас интересует только схема, и у нас она очень простая:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Мы пометили поля name и text как текстовые на английском языке. Анализатор — это сущность в Elasticsearch, которая обрабатывает текст перед сохранением в индекс. В случае english анализатора текст будет разбит на токены по границам слов (подробности), после чего отдельные токены будут лемматизированы по правилам английского языка (например, слово trees упростится до tree), слишком общие леммы (вроде the) будут удалены и оставшиеся леммы будут положены в обратный индекс.
С полем tags чуть-чуть сложнее. Тип keyword предполагает, что значения этого поля — некие строковые константы, которые не надо обрабатывать анализатором; обратный индекс будет построен по их «сырым» значениям — без токенизации и лемматизации. Зато Elasticsearch создаст специальные структуры данных, чтобы по значениям этого поля можно было считать агрегации (например, чтобы одновременно с поиском можно было узнать, какие теги встречались в документах, удовлетворяющих поисковому запросу, и в каком количестве). Это очень удобно для полей, которые по сути enum; мы воспользуемся этой фичей, чтобы сделать клёвые поисковые фильтры.
Но чтобы по тексту тегов можно было искать и текстовым поиском тоже, мы добавляем к нему подполе "text", настроенное по аналогии с name и text выше — по существу это означает, что Elasticsearch во всех приходящих ему документах будет создавать ещё одно «виртуальное» поле под названием tags.text, в которое будет копировать содержимое tags, но индексировать его по другим правилам.
Индексация: наполняем индекс
Для индексации документа достаточно сделать PUT-запрос в /имя-индекса/_create/id-документа или, при использовании Python-клиента, просто вызвать нужный метод. Наша реализация будет выглядеть так:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
Обратите внимание на поле tags. Хотя мы описали его как содержащее keyword, мы отправляем не одну строку, а список строк. Elasticsearch поддерживает такое; наш документ будет находиться по любому из значений.
Индексация: переключаем индекс
Чтобы реализовать поиск, нам надо знать имя самого свежего полностью достроенного индекса. Механизм алиасов позволяет нам держать эту информацию на стороне Elasticsearch.
Алиас — это указатель на ноль или более индексов. API Elasticsearch позволяет использовать имя алиаса вместо имени индекса при поиске (POST /имя-алиаса/_search вместо POST /имя-индекса/_search); в таком случае Elasticsearch будет искать по всем индексам, на которые указывает алиас.
Мы заведём алиас под названием cards, который всегда будет указывать на актуальный индекс. Соответственно, переключение на актуальный индекс после завершения построения будет выглядеть так:
def switch_current_cards_index(self, new_index_name: str):
try:
# Нужно удалить ссылку на старый индекс, если она есть.
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# Ого, старого индекса-то и не существует вовсе.
# Наверное, мы впервые запустили индексацию.
remove_actions = []
# Одним махом удаляем ссылку на старый индекс
# и добавляем ссылку на новый.
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
Я не стану подробнее останавливаться на alias API; все подробности можно посмотреть в документации.
Здесь надо сделать ремарку, что в реальном высоконагруженном сервисе такое переключение может быть довольно болезненным и может иметь смысл сделать предварительный прогрев — нагрузить новый индекс каким-то пулом сохранённых пользовательских запросов.
Весь код, реализующий индексацию, можно посмотреть в этом коммите.
Индексация: добавляем контент
Для демонстрации в этой статье я использую данные из TMDB 5000 Movie Dataset. Чтобы избежать проблем с авторскими правами, я лишь привожу код утилиты, импортирующей их из CSV-файла, который предлагаю вам скачать самостоятельно с сайта Kaggle. После загрузки достаточно выполнить команду
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
, чтобы создать пять тысяч карточек, посвящённых кино, и команду
docker-compose exec backend python -m tools.build_index
, чтобы построить индекс. Обратите внимание, что последняя команда на самом деле не строит индекс, а только ставит задачу в очередь задач, после чего она выполнится на воркере — подробнее об этом подходе я рассказывал в прошлой статье. docker-compose logs worker покажут вам, как воркер старался!
Прежде, чем мы приступим к, собственно, поиску, нам хочется своими глазами увидеть, записалось ли что-нибудь в Elasticsearch, и если да, то как оно выглядит!
Наиболее прямой и быстрый способ это сделать — воспользоваться HTTP API Elasticsearch. Сперва проверим, куда указывает алиас:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
Отлично, индекс существует! Посмотрим на него пристально:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
Ну и, наконец, посмотрим на его содержимое:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
Итого в нашем индексе 4704 документа, а в поле hits (которое я пропустил, потому что оно слишком большое) можно даже увидеть содержимое некоторых из них. Успех!
Более удобным способом просмотра содержимого индекса и вообще всевозможного баловства с Elasticsearch будет воспользоваться Kibana. Добавим контейнер в docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
После повторного docker-compose up мы сможем зайти в Kibana по адресу localhost:5601 (внимание, сервер может стартовать небыстро) и, после короткой настройки, просмотреть содержимое наших индексов в симпатичном веб-интерфейсе.
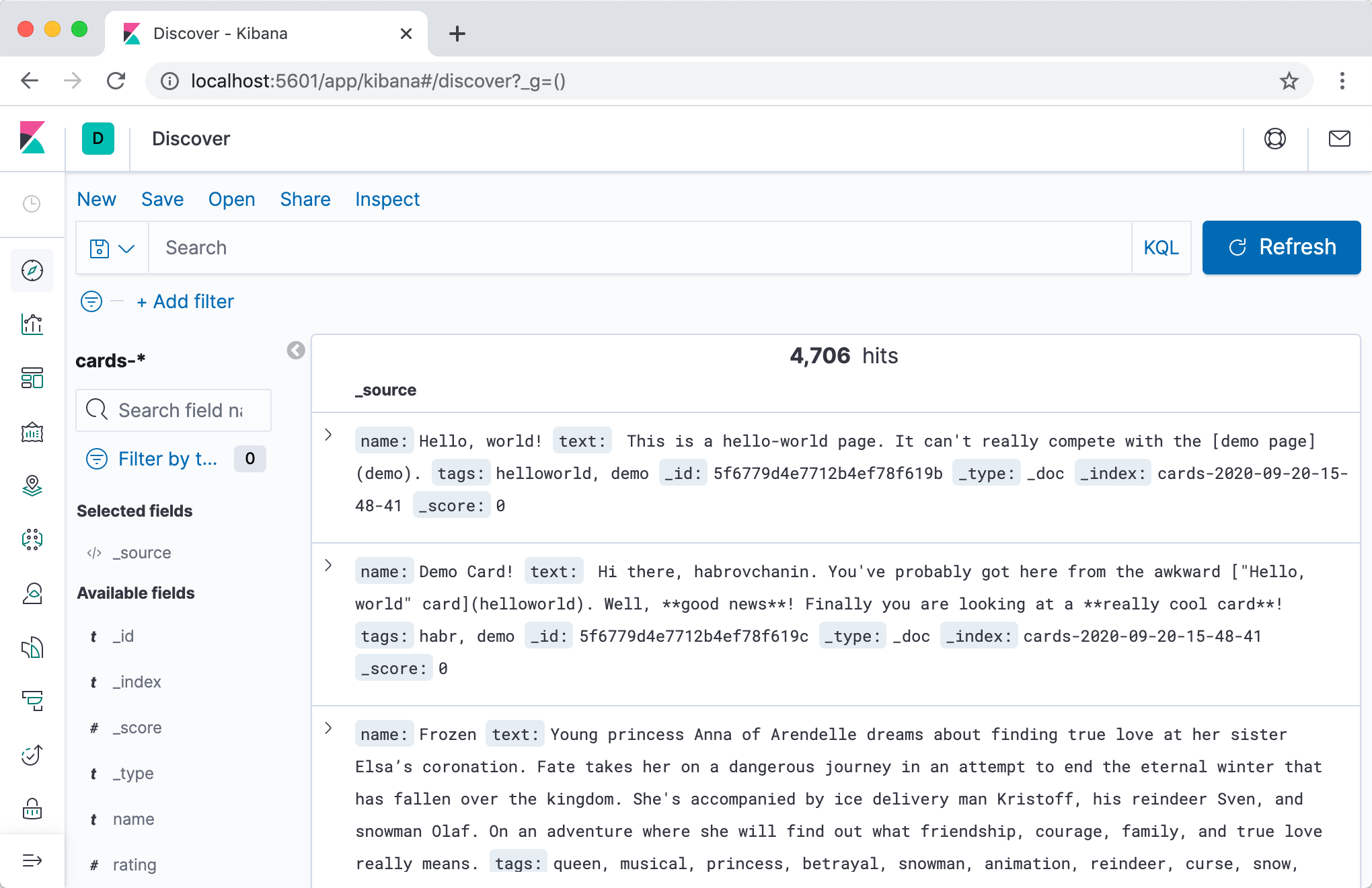
Очень советую вкладку Dev Tools — при разработке вам часто нужно будет делать те или иные запросы в Elasticsearch, и в интерактивном режиме с автодополнением и автоформатированием это гораздо удобнее.
Поиск
После всех невероятно скучных приготовлений пора нам уже добавить функциональность поиска в наше веб-приложение!
Разделим эту нетривиальную задачу на три этапа и обсудим каждый в отдельности.
- Добавляем в бэкенд компонент
Searcher, отвечающий за логику поиска. Он будет формировать запрос к Elasticsearch и конвертировать результаты в более удобоваримые для нашего бэкенда. - Добавляем в API эндпоинт (ручку/роут/как у вас в компании это называют?)
/cards/search, осуществляющий поиск. Он будет вызывать метод компонентаSearcher, обрабатывать полученные результаты и возвращать клиенту. - Реализуем интерфейс поиска на фронтенде. Он будет обращаться в
/cards/search, когда пользователь определился, что он хочет искать, и отображать результаты (и, возможно, какие-то дополнительные контролы).
Поиск: реализуем
Не так сложно написать менеджер, осуществляющий поиск, как его задизайнить. Давайте опишем результат поиска и интерфейс менеджера и обсудим, почему он такой, а не иной.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
Какие-то вещи очевидны. Например, пагинация. Мы амбициозный молодой убийца IMDB стартап, и результаты поиска никогда не будут вмещаться на одну страницу!
Какие-то менее очевидны. Например, список ID, а не карточек в качестве результата. Elasticsearch по умолчанию хранит наши документы целиком и возвращает их в результатах поиска. Это поведение можно отключить, чтобы сэкономить на размере поискового индекса, но для нас это явно преждевременная оптимизация. Так почему бы не возвращать сразу карточки? Ответ: это нарушит single-responsibility principle. Возможно, когда-нибудь мы накрутим в менеджере карточек сложную логику, переводящую карточки на другие языки в зависимости от настроек пользователя. Ровно в этот момент данные на странице карточки и данные в результатах поиска разъедутся, потому что добавить ту же самую логику в поисковый менеджер мы забудем. И так далее и тому подобное.
Реализация этого интерфейса настолько проста, что мне было лень писать этот раздел :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any # для аннотаций типов
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query делает текстовый поиск по
# совокупности полей документов (в отличие от match
# query, которая ищет по одному полю).
"multi_match": {
"query": query,
# Число после ^ – приоритет. Найти фрагмент текста
# в названии карточки лучше, чем в описании и тегах.
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
По сути мы просто ходим в API Elasticsearch и аккуратно достаём ID найденных карточек из результата.
Реализация эндпоинта тоже довольно тривиальна:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# Здесь не нужны все поля, иначе данных на одной
# странице поиска будет слишком много, и она будет
# долго грузиться.
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
Реализация фронтенда, пользующегося этим эндпоинтом, хоть и объёмна, но в целом довольно прямолинейна и в этой статье я не хочу заострять на ней внимание. На весь код можно посмотреть в этом коммите.

So far so good, идём дальше.
 Поиск: добавляем фильтры
Поиск: добавляем фильтры
Поиск по тексту — это клёво, но если вы когда-нибудь пользовались поиском на серьёзных ресурсах, вы наверняка видели всякие плюшки вроде фильтров.
У наших описаний фильмов из базы TMDB 5000 помимо названий и описаний есть теги, так что давайте для тренировки реализуем фильтры по тегам. Наша цель — на скриншоте: при клике на тег в выдаче должны остаться только фильмы с этим тегом (их число указано в скобках рядом с ним).

Чтобы реализовать фильтры, нам нужно решить две проблемы.
- Научиться по запросу понимать, какой набор фильтров доступен. Мы не хотим показывать все возможные значения фильтра на каждом экране, потому что их очень много и при этом большинство будет приводить к пустому результату; нужно понять, какие теги есть у документов, найденных по запросу, и в идеале оставить N самых популярных.
- Научиться, собственно, применять фильтр — оставить в выдаче только документы с тегами, фильтр по которым выбрал пользователь.
Второе в Elasticsearch элементарно реализуется через API запросов (см. terms query), первое — через чуть менее тривиальный механизм агрегаций.
Итак, нам надо знать, какие теги встречаются у найденных карточек, и уметь отфильтровывать карточки с нужными тегами. Сперва обновим дизайн поискового менеджера:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
Теперь перейдём к реализации. Первое, что нам нужно сделать — завести агрегацию по полю tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
Теперь в поисковом результате от Elasticsearch будет приходить поле aggregations, из которого по ключу TAGS_AGGREGATION_NAME мы сможем достать бакеты, содержащие информацию о том, какие значения лежат в поле tags у найденных документов и как часто они встречаются. Давайте извлечём эти данные и вернём в удобоваримом виде (as designed above):
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
Добавить применение фильтра — самая лёгкая часть:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
Подзапросы, включённые в must-клаузу, обязательны к выполнению, но также будут учитываться при расчёте скоров документов и, соответственно, ранжировании; если мы когда-нибудь будем добавлять ещё какие-то условия на тексты, их лучше добавить сюда. Подзапросы в filter-клаузе только фильтруют, не влияя на скоры и ранжирование.
Осталось реализовать _make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
На фронтенд-части опять-таки не стану останавливаться; весь код — в этом коммите.
Ранжирование
Итак, наш поиск ищет карточки, фильтрует их по заданному списку тегов и выводит в каком-то порядке. Но в каком? Порядок очень важен для практичного поиска, но всё, что мы сделали за время наших разбирательств в плане порядка — это намекнули Elasticsearch, что находить слова в заголовке карточки выгоднее, чем в описании или тегах, указав приоритет ^3 в multi-match query.
Несмотря на то, что по умолчанию Elasticsearch ранжирует документы довольно хитрой формулой на основе TF-IDF, для нашего воображаемого амбициозного стартапа этого вряд ли хватит. Если наши документы — это товары, нам надо уметь учитывать их продажи; если это user-generated контент — уметь учитывать его свежесть, и так далее. Но и просто отсортировать по числу продаж/дате добавления мы не можем, потому что тогда мы никак не учтём релевантность поисковому запросу.
Ранжирование — это большое и запутанное царство технологий, которое никак не покрыть за один раздел в конце статьи. Поэтому здесь я перехожу в режим крупных мазков; я попробую рассказать в самых общих словах, как может быть устроено industrial grade ранжирование в поиске, и раскрою немного технических деталей того, как его можно реализовать с Elasticsearch.
Задача ранжирования очень сложна, так что неудивительно, что один из основных современных методов её решения — машинное обучение. Приложение технологий машинного обучения к ранжированию собирательно называется learning to rank.
Типичный процесс выглядит так.
Определяемся, что мы хотим ранжировать. Мы кладём интересующие нас сущности в индекс, научаемся для заданного поискового запроса получать какой-то разумный топ (например, какой-нибудь простой сортировкой и отсечением) этих сущностей и теперь хотим научиться его ранжировать более умным способом.
Определяемся, как мы хотим ранжировать. Мы решаем, по какой характеристике надо отранжировать нашу выдачу, в соответствии с бизнес-целями нашего сервиса. Например, если наши сущности — это товары, которые мы продаём, мы можем хотеть отсортировать их по убыванию вероятности покупки; если мемы — по вероятности лайка или шера и так далее. Эти вероятности мы, конечно, не умеем считать — в лучшем случае прикидывать, да и то только для старых сущностей, для которых у нас набрано достаточно статистики, —, но мы попытаемся научить модель предсказывать их, исходя из косвенных признаков.
Извлекаем признаки. Мы придумываем для наших сущностей какое-то множество признаков, которые могли бы помочь нам оценить релевантность сущностей поисковым запросам. Помимо того же TF-IDF, который уже умеет для нас вычислять Elasticsearch, типичный пример — CTR (click-through rate): мы берём логи нашего сервиса за всё время, для каждой пары сущность+поисковый запрос считаем, сколько раз сущность появлялась в выдаче по этому запросу и сколько раз её кликали, делим одно на другое, et voilà — простейшая оценка условной вероятности клика готова. Мы также можем придумать признаки для пользователя и парные признаки пользователь-сущность, чтобы сделать ранжирование персонализированным. Придумав признаки, мы пишем код, который их вычисляет, кладёт в какое-то хранилище и умеет отдавать в real time для заданного поискового запроса, пользователя и набора сущностей.
Собираем обучающий датасет. Тут много вариантов, но все они, как правило, формируются из логов «хороших» (например, клик и потом покупка) и «плохих» (например, клик и возврат на выдачу) событий в нашем сервисе. Когда мы собрали датасет, будь то список утверждений «оценка релевантности товара X запросу Q примерно равна P», список пар «товар X релевантнее товара Y запросу Q» или набор списков «для запроса Q товары P1, P2, … правильно отранжировать так-то», мы ко всем фигурирующим в нём строкам подтягиваем соответствующие признаки.
Обучаем модель. Тут вся классика ML: train/test, гиперпараметры, переобучение, перфовидеокарты и так далее. Моделей, подходящих (и повсеместно использующихся) для ранжирования, много; упомяну как минимум XGBoost и CatBoost.
Встраиваем модель. Нам остаётся так или иначе прикрутить вычисление модели на лету для всего топа, чтобы до пользователя долетали уже отранжированные результаты. Тут много вариантов; в иллюстративных целях я (опять-таки) остановлюсь на простом — Elasticsearch-плагине Learning to Rank.
Ранжирование: плагин Elasticsearch Learning to Rank
Elasticsearch Learning to Rank — это плагин, добавляющий в Elasticsearch возможность вычислить ML-модель на выдаче и тут же отранжировать результаты согласно посчитанным ею скорам. Он также поможет нам получить признаки, идентичные используемым в real time, переиспользовав при этом способности Elasticsearch (TF-IDF и тому подобное).
Для начала нам нужно подключить плагин в нашем контейнере с Elasticsearch. Нам потребуется простенький Dockerfile
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
и сопутствующие изменения в docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
Также нам потребуется поддержка плагина в Python-клиенте. С изумлением я обнаружил, что поддержка для Python не идёт в комплекте с плагином, так что специально для этой статьи я её запилил. Добавим elasticsearch_ltr в requirements.txt и проапгрейдим клиент в вайринге:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
Ранжирование: пилим признаки
Каждый запрос в Elasticsearch возвращает не только список ID документов, которые нашлись, но и некоторые их скоры (как вы бы перевели на русский язык слово score?). Так, если это match или multi-match query, которую мы используем, то скор — это результат вычисления той самой хитрой формулы с участием TF-IDF; если bool query — комбинация скоров вложенных запросов; если function score query — результат вычисления заданной функции (например, значение какого-то числового поля в документе) и так далее. Плагин ELTR предоставляет нам возможность использовать скор любого запроса как признак, позволяя легко скомбинировать данные о том, насколько хорошо документ соответствует запросу (через multi-match query) и какие-то предрассчитанные статистики, которые мы заранее кладём в документ (через function score query).
Поскольку на руках у нас база TMDB 5000, в которой лежат описания фильмов и, помимо прочего, их рейтинги, давайте возьмём рейтинг в качестве образцово-показательного предрассчитанного признака.
В этом коммите я добавил в бэкенд нашего веб-приложения некую базовую инфраструктуру для хранения признаков и поддержал подгрузку рейтинга из файла с фильмами. Дабы не заставлять вас читать очередную кучу кода, опишу самое основное.
- Признаки мы будем хранить в отдельной коллекции и доставать отдельным менеджером. Сваливать все данные в одну сущность — порочная практика.
- В этот менеджер мы будем обращаться на этапе индексации и класть все имеющиеся признаки в индексируемые документы.
- Чтобы знать схему индекса, нам надо перед началом построения индекса знать список всех существующих признаков. Этот список мы пока что захардкодим.
- Поскольку мы не собираемся фильтровать документы по значениям признаков, а собираемся только извлекать их из уже найденных документов для обсчёта модели, мы выключим построение по новым полям обратных индексов опцией
index: falseв схеме и сэкономим за счёт этого немного места.
Ранжирование: собираем датасет
Поскольку, во-первых, у нас нет продакшна, а во-вторых, поля этой статьи слишком малы для рассказа про телеметрию, Kafka, NiFi, Hadoop, Spark и построение ETL-процессов, я просто сгенерирую случайные просмотры и клики для наших карточек и каких-то поисковых запросов. После этого нужно будет рассчитать признаки для получившихся пар карточка-запрос.
Пришла пора закопаться поглубже в API плагина ELTR. Чтобы рассчитать признаки, нам нужно будет создать сущность feature store (насколько я понимаю, фактически это просто индекс в Elasticsearch, в котором плагин хранит все свои данные), потом создать feature set — список признаков с описанием, как вычислять каждый из них. После этого нам достаточно будет сходить в Elasticsearch с запросом специального вида, чтобы получить вектор значений признаков для каждой найденной сущности в результате.
Начнём с создания feature set:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# Создать feature store обязательно для работы,
# но при этом его нельзя создавать дважды ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# Создаём feature set с невероятными ТРЕМЯ признаками!
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
# Совпадение поискового запроса с названием
# карточки может быть более сильным признаком,
# чем совпадение со всем содержимым, поэтому
# сделаем отдельный признак про это.
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR позволяет параметризовать
# запросы, вычисляющие признаки. В данном
# случае нам, очевидно, нужен текст
# запроса, чтобы правильно посчитать
# скор match query.
"name": "{{query}}"
}
}),
# Скор запроса, которым мы ищем сейчас.
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
# Добавляем все имеющиеся предрассчитанные
# признаки через механизм function score.
# Если по какой-то причине в документе
# отсутствует искомое поле, берём 0.
# (В настоящем проекте вам стоит
# предусмотреть умолчания получше!)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Теперь — функция, вычисляющая признаки для заданного запроса и карточек:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# Нам не нужно проверять, находятся ли карточки
# на самом деле по такому запросу — если нет,
# соответствующие признаки просто будут нулевыми.
# Поэтому оставляем только фильтр по ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# Это — специальный новый тип запроса,
# вводимый плагином SLTR. Он заставит
# плагин посчитать все факторы из указанного
# feature set.
# (Несмотря на то, что мы всё ещё в разделе
# filter, этот запрос ничего не фильтрует.)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# Та самая параметризация.
# Строка, переданная сюда,
# подставится в запросах
# вместо {{query}}.
"query": query
}
}
}
]
}
},
# Следующая конструкция заставит плагин запомнить все
# рассчитанные признаки и добавить их в результат поиска.
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# Осталось достать значения признаков из (несколько
# замысловатого) результата поиска.
# (Чтобы понять, где в недрах результатов нужные мне
# значения, я просто делаю пробные запросы в Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
Простенький скрипт, принимающий на вход CSV с запросами и ID карточек и выдающий CSV с признаками:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
Наконец можно это всё запустить!
# Создаём feature set
docker-compose exec backend python -m tools.initialize_search_ranking
# Генерируем события
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
# Считаем признаки
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
Теперь у нас есть два файла — с событиями и признаками — и мы можем приступить к обучению.
