DeepMind утверждает, что ее языковая модель на 280 млрд параметров превосходит аналоги в 25 раз крупнее
AI-лаборатория DeepMind опубликовала три исследовательские работы, посвященные возможностям больших языковых моделей. Компания пришла к выводу, что дальнейшее масштабирование этих систем должно привести к множеству улучшений.
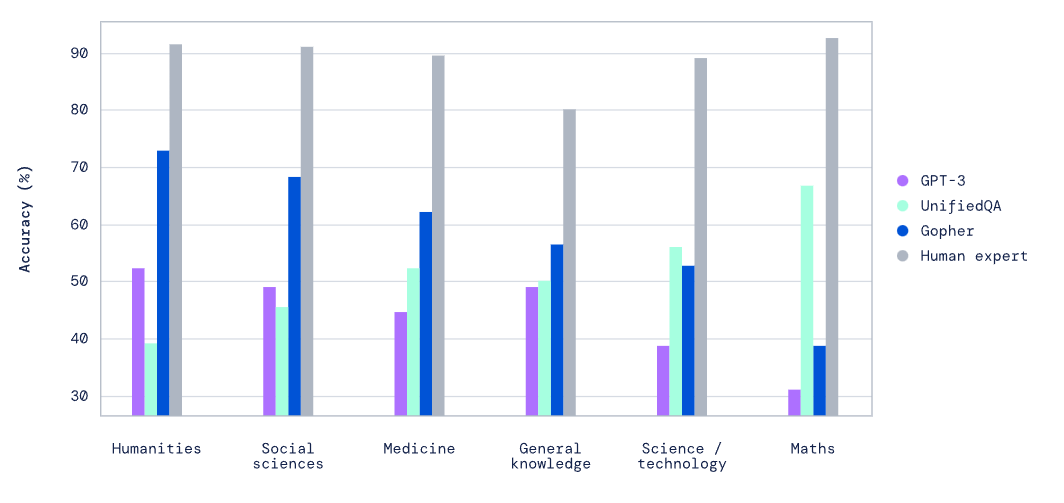 Производительность моделей в тесте Massive Multitask Language Understanding (MMLU) с разбивкой по категориям
Производительность моделей в тесте Massive Multitask Language Understanding (MMLU) с разбивкой по категориям
DeepMind создала языковую модель с 280 миллиардами параметров под названием Gopher. Она больше, чем GPT-3 от OpenAI (175 миллиардов параметров), но меньше, чем некоторые другие экспериментальные системы, такие как модель Megatron от Microsoft и Nvidia (530 миллиардов параметров).
Более крупные модели обычно обеспечивают более высокую производительность. Исследование DeepMind подтверждает это и предполагает, что расширение языковой модели действительно обеспечивает повышение производительности в наиболее распространенных эталонных тестах, таких как анализ настроений и обобщение. Однако исследователи также предупредили, что для исправления некоторых проблем, присущих языковым моделям, потребуются не только данные и вычисления, а «дополнительные процедуры обучения», основанные на отзывах пользователей-людей.
Исследователи предложили улучшенную архитектуру языковой модели, которая снижает затраты на обучение и упрощает отслеживание выходных данных модели до источников в корпусе обучения. Трансформатор с улучшенным поиском (RETRO) предварительно обучен с помощью механизма поиска в масштабе Интернета. Вдохновленный тем, как мозг использует специальные механизмы памяти при обучении, RETRO эффективно запрашивает отрывки текста, чтобы улучшить свои предсказания. Сравнивая сгенерированные тексты с отрывками, которые RETRO использовали для генерации, можно интерпретировать, почему модель делает определенные прогнозы и где их источник. При этом она обеспечивает производительность, сравнимую с производительностью обычного трансформатора, с меньшим количеством параметров.

Модель Gopher исследовали посредством прямого взаимодействия. Выяснилось, что у нее есть хороший потенциал побуждать к диалогу:

Gopher может обсудить клеточную биологию и дать правильную цитату, несмотря на отсутствие конкретной настройки диалога. Однако исследование также детализировало несколько видов отказов, которые сохраняются в разных размерах модели, в том числе тенденцию к повторению, отражение стереотипных предубеждений и уверенное распространение дезинформации.

Чтобы прийти к таким выводам, исследователи DeepMind оценили ряд моделей разного размера на 152 языковых задачах или тестах. Они обнаружили, что более крупные модели обычно дают лучшие результаты, а их система Gopher предлагает лучшие решения примерно в 80% тестов, выбранных учеными.
В другом документе компания исследовала широкий спектр потенциальных опасностей, связанных с развертыванием языковых моделей. К ним относятся использование системами токсичной лексики, их способность распространять дезинформацию и потенциал для использования в злонамеренных целях, таких как распространение спама или пропаганды. Все эти проблемы будут становиться все более важными по мере того, как языковые модели станут более широко распространяться, например, в виде чат-ботов и систем продаж. Исследователи разделили проблемы на шесть тематических областей, и подробно рассмотрели 21 случай риска. Они пришли к выводу, что в двух областях требуется дальнейшая работа. Во-первых, существующих инструментов сравнительного анализа недостаточно для оценки некоторых важных рисков, например, когда языковые модели выдают дезинформацию. Во-вторых, требуется дополнительная работа по снижению рисков.
Ранее DeepMind уже провела исследование токсичного поведения ИИ-систем. «Несмотря на эффективность принципа блокировки триггерных фраз и прекрасной оптимизации системы ответов без оскорблений, искусственный интеллект лишился почти всех слов, относящихся к меньшинствам, а также диалектизмов и в целом упоминаний маргинализированных групп. Помимо этого, система считает, что отлично справляется с поставленной задачей, однако тому есть обратные доказательства», ― заявили исследователи.
