DBA: «Кто-то слишком много ест!»
Тема «распухания» таблиц и индексов из-за реализации MVCC — больная для пользователей и администраторов PostgreSQL.
Однажды я уже поднимал ее в статье «DBA: когда пасует VACUUM — чистим таблицу вручную», разобрав на конкретных примерах, насколько драматический эффект для производительности запросов может оказывать невовремя проведенный или бесполезно отработавший из-за конкурентных транзакций VACUUM.
Но, помимо влияния на скорость, есть еще и факт влияния на занятое место. Наверное, вы сильно удивитесь, если таблица с единственной «живой» записью после успешного прохода autovacuum продолжит занимать гигабайты пространства на дорогих SSD.
Сегодня немного поисследуем структуру хранения данных в файлах и копнем pg_catalog — схему с описанием базы PostgreSQL, чтобы понять, как можно определить таблицы, которые явно занимают подозрительно много места.
Как быстро наступить на грабли
Для определенности скажем, что все тесты мы проводим на PostgreSQL 12, потому что с каждой новой версией разработчики стараются снизить сайд-эффекты MVCC.
CREATE TABLE bloat AS SELECT 0 i;
CREATE INDEX ON bloat(i);
-- вспомогательные функции удобно "прятать" в pg_temp, чтобы не зачищать потом вручную
CREATE OR REPLACE PROCEDURE pg_temp.upd() AS $$
UPDATE bloat SET i = i + 1;
$$ LANGUAGE sql; -- и да, это plainSQL-процедура, а не функция
DO $$
DECLARE
i integer;
ts timestamp;
BEGIN
FOR i IN 1 .. 1 << 14 LOOP
ts := clock_timestamp();
CALL pg_temp.upd();
RAISE NOTICE '% : %', i, clock_timestamp() - ts;
END LOOP;
END;
$$ LANGUAGE plpgsql;В процессе выполнения этого скрипта можно прямо глазами видеть, насколько сильно деградирует среднее время выполнения UPDATE нашей единственной записи. Точно единственной?
TABLE bloat; i
-----
16384И сколько же все это счастье из единственной записи занимает?
SELECT pg_relation_size('bloat');
-- 598016Оу… больше полумегабайта! Замечу, что при отсутствии индекса фокус не пройдет, и таблица не разрастется благодаря HOT-update. Но и тут нам же должен помочь VACUUM — ведь никаких мешающих транзакций у нас нету!
VACUUM bloat;
-- ... и нет!
SELECT pg_relation_size('bloat');
-- 598016Хранение данных в таблице
Чтобы понять, почему так произошло, впору вспомнить про организацию физического хранения данных в PostgreSQL, которая в предельно упрощенном виде выглядит так:
каждая таблица — отдельный файл (
pg_class.relfilenode)каждый файл делится на сегменты, не превышающие 1GB
каждый сегмент состоит из последовательности страниц данных по (обычно) 8KB
страница данных содержит непосредственно набор записей
«Обычный» VACUUM (неVACUUM FULL) никак не перемещает сами записи — ни между страницами, ни в рамках самой страницы, поэтому может уменьшить размер файла, только отрезав «хвост» из целиком пустых страниц.
А наша единственная «живая» запись лежит ровно на самой последней странице, потому что все предыдущие были заняты «мертвыми» — потому VACUUM ничего и не срезал.
В недрах pg_catalog
pg_catalog — это системная схема, описывающая все внутреннее мироустройство данной конкретной базы — схемы, таблицы, индексы, поля, статистика, … Чтобы понять, насколько там всего много, достаточно взглянуть на схему от Joel Jacobson. Но нам сегодня понадобятся всего несколько таблиц, описывающих отдельные аспекты базы:
pg_namespace — схемы (schema)
pg_class — основные объекты — таблицы, индексы, matview, …
pg_depend — зависимости между объектами, в нашем случае — схем и таблиц
pg_attribute — столбцы таблиц
pg_statistic — статистика о распределении данных
Теперь попробуем составить алгоритм для оценки «раздутости» нашей таблицы (или нескольких):
она относится (
pg_depend) к конкретной схеме (pg_namespace)public(чтобы в анализ не попадали всякие системные таблицы изpg_catalogиinformation_schema)количество страниц (
pg_class.relpages) в ней существенно больше необходимого для хранения такого количества записей (pg_class.reltuples)чтобы оценить это самое «необходимое количество» мы по статистике распределения данных (
pg_statistic) для каждого из столбцов таблицы (pg_attribute) поймем, сколько там NULL-значений (pg_statistic.stanullfrac) и средний размер хранимых данных (pg_statistic.stawidth) с учетом выравнивания (pg_attribute.attalign)и все это попробуем максимально плотно «разложить» в соответствии с компоновкой страницы на минимальное их количество
Упаковываемся на страницу
Итак, в нашем распоряжении есть страница данных — сколько записей реально туда «упаковать»?
Физический размер страницы определяется на моменте компиляции движка PostgreSQL, поэтому обычно его никто не меняет и оставляет равным 8KB. Но более правильным, чем захардкодить константу, будет в явном виде спросить ее у сервера из параметра block_size:
SELECT current_setting('block_size')::integer;
-- 8192Теперь перейдем к логическому размеру, для этого нам необходимо вычесть всю служебную информацию:
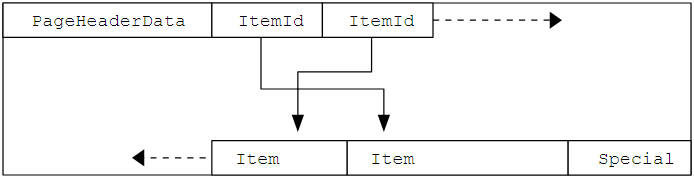 структура размещения данных в таблице
структура размещения данных в таблицеТут стоит обратить внимание, что если начать считать по табличке в документации, то будет упорно выходить 27 байт, если не обратить внимание на один факт:
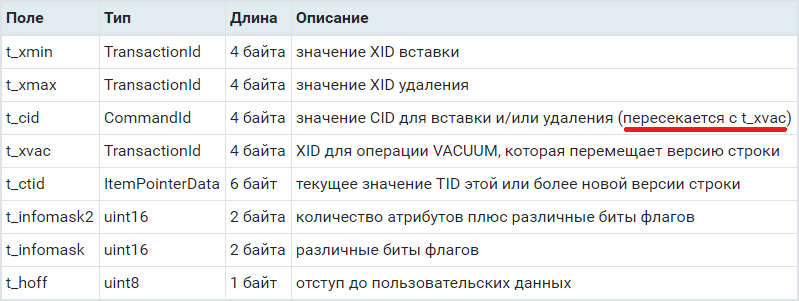 структура HeapTupleHeaderData
структура HeapTupleHeaderDataВ исходниках, t_cidи t_xvac описаны как C-union, то есть занимают одни и те же 4 байта.
«Почти бесплатные» NULL’ы
Отдельно стоит отметить момент хранения NULL-значений столбцов записи. Если конкретная запись содержит NULL-значение в любом из полей, то в HeapTupleHeaderData к 23 «стабильным» байтам заголовка будет добавлена битовая маска по количеству полей.
То есть если у вас в записи 8 полей и любое из них NULL, то добавлен будет 1 байт, что в сумме даст 24 байта заголовка и с учетом выравнивания. А вот если полей 9, то ой… добавится 2 байта, что в сумме даст уже 25, а с учетом выравнивания на 64-bit системах — уже 32 байта.
При этом в «теле» записи NULL не хранится никак и дополнительного места не занимает.
Немного математики
Заметим, что для определения общего размера записи нам необходимо знать о наличии NULL в любом из ее полей, а в pg_statistic.stanullfrac хранится доля NULL-значений для конкретного поля.
Поэтому, чтобы получить долю записей, содержащих хотя бы один NULL, нам всего лишь надо перемножить вероятности. А для этого нам пригодился бы агрегат-произведение, которого, увы, нету среди стандартных sum/avg/min/max/count.
Не беда! Тут нам на помощь придет математический «хак», который я приводил в статье «SQL HowTo: 1000 и один способ агрегации»:
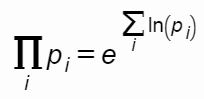 P = exp (sum (ln (…)))
P = exp (sum (ln (…)))Пора писать код!
Для самопроверки добавим точно такую же таблицу, как наша, но не будем над ней издеваться:
CREATE TABLE nobloat AS
SELECT 0 i;
CREATE INDEX ON nobloat(i);
-- objects-in-scheme
WITH dep AS (
-- https://postgrespro.ru/docs/postgresql/12/catalog-pg-depend
SELECT
objid
FROM
pg_depend
WHERE
(
refclassid
, refobjid
, classid
) = (
'pg_namespace'::regclass
, (
-- https://postgrespro.ru/docs/postgresql/12/catalog-pg-namespace
SELECT
oid
FROM
pg_namespace
WHERE
nspname = 'public' -- schema
LIMIT 1
)
, 'pg_class'::regclass
)
)
-- objects
, cl AS (
-- https://postgrespro.ru/docs/postgresql/12/catalog-pg-class
SELECT
oid
, relname
, relpages
, reltuples
FROM
pg_class cl
WHERE
oid = ANY(ARRAY(TABLE dep)::oid[]) AND
relkind IN ('r', 'm', 'p') -- relation | matview | partition
)
SELECT
T.*
, cl.*
, CASE
WHEN ratio >= 1 THEN (ratio - 1) * def.PAGESIZE
END::bigint repack_effect_size
FROM
(
-- https://postgrespro.ru/docs/postgresql/12/storage-page-layout
SELECT
current_setting('block_size')::integer PAGESIZE
, CASE
WHEN version() ~ 'mingw32' OR version() ~ '64-bit' THEN 8
ELSE 4
END MAXALIGN
) def
, cl
, LATERAL (
WITH cols AS (
SELECT
*
, (sz + szq - 1) / szq * szq sza -- aligned size
FROM
(
-- https://postgrespro.ru/docs/postgresql/12/catalog-pg-attribute
-- https://postgrespro.ru/docs/postgresql/12/catalog-pg-statistic
SELECT
attname
, attnum
, coalesce(st.stanullfrac, 0) nfr
, CASE
WHEN attlen = -1 THEN
CASE
WHEN attstorage IN ('p', 'm') OR stawidth < 2048 THEN -- toast_tuple_target
stawidth
ELSE 8 -- len + toast_id
END
ELSE attlen
END sz
, CASE attalign
WHEN 'c' THEN 1
WHEN 's' THEN 2
WHEN 'i' THEN 4
WHEN 'd' THEN 8
END szq
FROM
pg_attribute at
LEFT JOIN
pg_statistic st
ON (st.starelid, st.staattnum) = (at.attrelid, at.attnum)
WHERE
at.attrelid = cl.oid AND
NOT at.attisdropped AND -- without dropped columns
at.attnum > 0 -- without system columns (tableoid, ctid, ...)
ORDER BY
attnum
) T
)
SELECT
CASE
WHEN reltuples = 0 AND relpages = 0 THEN 1
WHEN reltuples = 0 AND relpages > 0 THEN NULL
ELSE
relpages /
ceil( -- need pages
reltuples /
(
(PAGESIZE - 24) / -- PageHeaderData
ceil(szt::double precision / reltuples)::bigint -- avg tuple size
) -- tuples-per-page
)
END ratio
FROM
(
SELECT
reltuples * 4 + -- ItemIdData
(
(reltuples - fnnt) * hdr_tuple_w_nulls + -- hdr, tuples w/nulls
fnnt * hdr_tuple_wo_nulls -- hdr, tuples wo/nulls
) +
sztc szt -- size of tuples
FROM
(
SELECT
sztc
, fnnt
-- aligned headers
, ceil(hdr_cols_sys::double precision / MAXALIGN)::integer * MAXALIGN hdr_tuple_wo_nulls
, ceil((hdr_cols_sys + hdr_cols_null)::double precision / MAXALIGN)::integer * MAXALIGN hdr_tuple_w_nulls
FROM
(
SELECT
-- https://doxygen.postgresql.org/htup__details_8h_source.html#l00121
-- 4 : t_xmin
-- 4 : t_xmax
-- 4 : t_cid | t_xvac
-- 6 : t_ctid
-- 2 : t_infomask2
-- 2 : t_infomask
-- 1 : t_hoff
23 hdr_cols_sys
, ceil(count(*)::double precision / 8)::integer hdr_cols_null
, sum(ceil(sza * reltuples * (1 - nfr))) sztc -- size of tuples cols
, trunc(exp(sum(ln(CASE WHEN nfr < 1 THEN 1 - nfr ELSE 1 END))) * reltuples) fnnt -- full-not-null-tuples
FROM
cols
) T
) T
) T
) T;
Что в результате?
ratio | oid | relname | relpages | reltuples | repack_effect_size
-------------------------------------------------------------------
73 | 41333 | bloat | 73 | 15 | 589824
1 | 41337 | nobloat | 1 | 1 | 0Заметим, что PostgreSQL считает, что в bloat у нас 15 записей, а не 1, как в реальности — это следствие неактуальной статистики как результат не выполненного вовремя ANALYZE. Ровно по той же причине может получиться, что ratio окажется меньше 1.
А дальше — сами определяйтесь, какие из таблиц вы будете «сжимать» и чем:
