Dagaz: Быстрее, Лучше, Умнее…
 — Как взмывают ангелы дружно в ряд…
— Как взмывают ангелы дружно в ряд…
— Дружно в ряд, дружно в ряд…
— Поднимают головы! И летят! И летят!…
сэр Терри Пратчетт «Ночная стража»
Рано или поздно, всегда наступает момент, когда количество неизбежно переходит в качество. Накапливаются новые игры, нуждающиеся в осмыслении, проект обрастает новыми возможностями, возможности комбинируются между собой. Если всё не рушится под собственной тяжестью, результат может превзойти самые смелые ожидания. То что не убивает — делает нас сильнее!
Вот пример подобной «суммы технологий». Игра, в общем-то не слишком сложная, но очень неожиданная. Апокалипсис — на поле четыре всадника и поддерживающая их пехота. Привычные нам ходы шахматных фигур. Пешки, дойдя до последней линии, ожидаемо превращаются во всадников, но количество всадников на каждой стороне не может превышать двух. Игрок, первым потерявший всех своих всадников, проигрывает. Дьявол, как всегда, скрывается в деталях. Фигуры ходят одновременно!
Разумеется, возможны коллизии. Например, оба игрока могут одновременно сходить на одно и то же пустое поле или пешка может попытаться съесть фигуру, уходящую тем же ходом от удара. Правила игры хорошо описывают эти нюансы. Пешке разрешается выполнять диагональный ход, при условии того, что она собралась кого-то побить, даже если фигура ушла с этой позиции, а результат конфликта за пустое поле определяется рангом фигур. Всадник всегда убивает пешку, если же фигуры равны — они уничтожаются обе (что, кстати, делает возможными ничейные исходы).
Dagaz.Model.join = function(design, board, a, b) {
var x = getPiece(design, board, a);
var y = getPiece(design, board, b);
if ((x !== null) && (y !== null)) {
var r = Dagaz.Model.createMove();
r.protected = [];
checkPromotion(design, board, a, x, b);
checkPromotion(design, board, b, y, a);
var p = a.actions[0][1][0];
var q = b.actions[0][1][0];
if ((p == q) && (x.type > y.type)) {
r.actions.push(b.actions[0]);
r.actions.push(a.actions[0]);
} else {
r.actions.push(a.actions[0]);
r.actions.push(b.actions[0]);
}
if (p == q) {
if (x.type > y.type) {
r.actions[0][2] = [ Dagaz.Model.createPiece(2, 2) ];
r.protected.push(x.player);
r.captured = p;
} else {
if (x.type == y.type) {
r.actions[0][2] = [ Dagaz.Model.createPiece(2, 1) ];
r.actions[1][2] = [ Dagaz.Model.createPiece(2, 1) ];
r.capturePiece(p);
} else {
r.actions[0][2] = [ Dagaz.Model.createPiece(2, 1) ];
r.protected.push(y.player);
r.captured = p;
}
}
}
return r;
} else {
return a;
}
}
Задача непростая, но механизм «расширения ходов» с ней прекрасно справляется. Действительно, как я уже неоднократно говорил раньше, на этапе постобработки мы можем не только запретить ход (нарушающий, например, инвариант игры), но и добавить в него вообще любые произвольные действия, в том числе, полученные из хода, сформированного ботом.
Есть правда одна тонкость — обычно, постобработка выполняется сразу после генерации, для всех сформированных ходов. В данном случае, так делать нельзя, поскольку это неизбежно приведёт к «комбинаторному взрыву» (игра хоть и небольшая, но всё равно приятного мало). Самое главное, делать этого и не нужно. Есть способ проще. Никто ведь не сказал, что мы не можем переписать контроллер. У модульности есть свои преимущества.
С точки зрения AI бота, игра, во многом, «оказуаливается». Здесь нет необходимости в выполнении просмотра на много ходов в глубину. Важно угадать, как будет ходить противник! Меняется тактика игры. Практически бесполезно пытаться атаковать всадников, находящихся «под боем» — они наверняка убегут. «Вилки» — более перспективны, но придётся выбирать, какого из всадников бить. Если же у противника остался всего один всадник (а у вас их полный комплект), можно попытаться «подкараулить» его, сходив на выбранное им поле. Только не делайте это пешкой! Есть нюансы связанные с превращением фигур, но, в целом…
...
var isCovered = function(design, board, pos, player, type) {
var r = false;
_.each(Dagaz.Model.GetCover(design, board)[pos], function(pos) {
var piece = board.getPiece(pos);
if ((piece !== null) && (piece.player == player)) {
if (_.isUndefined(type) || (piece.type == type)) {
r = true;
}
}
});
return r;
}
Ai.prototype.getMove = function(ctx) {
var moves = Dagaz.AI.generate(ctx, ctx.board);
if (moves.length == 0) {
return { done: true, ai: "nothing" };
}
timestamp = Date.now();
var enemies = 0;
var friends = 0;
_.each(ctx.design.allPositions(), function(pos) {
var piece = ctx.board.getPiece(pos);
if ((piece !== null) && (piece.type == 1)) {
if (piece.player == 1) {
enemies++;
} else {
friends++
}
}
});
var eval = -MAXVALUE;
var best = null;
_.each(moves, function(move) {
var e = _.random(0, NOISE_FACTOR);
if (move.isSimpleMove()) {
var pos = move.actions[0][0][0];
var trg = move.actions[0][1][0];
var piece = ctx.board.getPiece(pos);
if (piece !== null) {
var target = ctx.board.getPiece(trg);
if (piece.type == 1) {
if (isCovered(ctx.design, ctx.board, pos, 1)) e += MAXVALUE;
if (target === null) {
if (isCovered(ctx.design, ctx.board, trg, 1, 0)) e += LARGE_BONUS;
if (isCovered(ctx.design, ctx.board, trg, 1, 1)) {
if ((enemies == 1) && (friends == 2)) {
e += BONUS;
} else {
e -= MAXVALUE;
}
}
} else {
if (target.type == 1) {
e += SMALL_BONUS;
} else {
e += BONUS;
}
}
} else {
if (isCovered(ctx.design, ctx.board, pos, 1)) e += SMALL_BONUS;
if ((target === null) && isCovered(ctx.design, ctx.board, trg, 1)) e -= MAXVALUE;
if (friends == 1) e += BONUS;
if (target !== null) e += SMALL_BONUS;
if ((move.actions[0][2] !== null) && (move.actions[0][2][0].type != piece.type)) {
if (friends == 1) {
e += MAXVALUE;
} else {
e -= MAXVALUE;
}
}
}
}
}
if ((best === null) || (eval < e)) {
console.log("Move: " + move.toString() + ", eval = " + e);
best = move;
eval = e;
}
});
return {
done: true,
move: best,
time: Date.now() - timestamp,
ai: "aggressive"
};
}

Другая крайность — игры большие и сложные настолько, что мало мальский просмотр в глубину для них невозможен технически. Здесь мы вынуждены использовать более казуальный AI, просматривающий позицию всего на 1–2 хода вперёд, причем даже на эту глубину, просмотреть все имеющиеся ходы не удастся! Во всяком случае, за комфортное для человека время поиска хода ботом в течение 2–3 секунд.

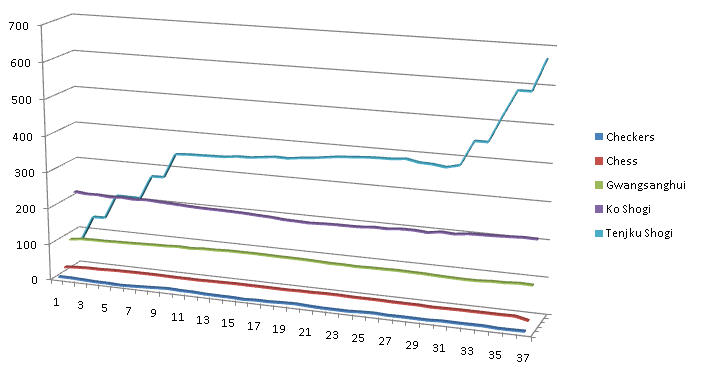
Всё дело в «Огненном демоне» (и подобных ему фигурах). Обратите внимание на диаграмму справа. Помимо обычных «range»-атак, «демон» имеет право, в любой момент, выполнить до трёх одно-шаговых перемещений в произвольном направлении, при этом, ему разрешается возвращаться на ранее пройденные поля. Это настоящий «комбинаторный убийца» производительности! В начальной позиции, когда все подобные фигуры «зажаты», этот эффект проявляется не так сильно, но когда они выходят на оперативный простор… Количество возможных вариантов ходов желающие могут подсчитать самостоятельно (на диаграмме ниже представлены графики изменения среднего количества допустимых ходов, в течение игры, для нескольких известных игр).
Здесь следует немного рассказать об архитектуре Dagaz. Главная идея заключается в том, что, прежде чем передавать управление пользователю или боту, модель игры генерирует все возможные ходы из текущей позиции. Это позволяет рассматривать совокупность ходов «целиком» и помогает решить ряд проблем Zillions of Games, связанных с составными ходами. Кроме того, такой подход очень удобен для разработки ботов. Но есть одна проблема.
Для пользователя, сложный составной ход представляет собой последовательность различных действий (перемещений, взятий и, возможно, сбросов новых фигур на доску). Где-то должен быть код, позволяющий по последовательности пользовательских «кликов» выбрать единственный ход из ранее сформированного и возможно большого списка. И такой код в Dagaz, разумеется есть.
MoveList.prototype.isUniqueFrom = function(pos) {
var c = 0;
_.each(this.moves, function(move) {
_.each(this.getActions(move), function(action) {
if ((action[0] !== null) && (_.indexOf(action[0], pos) >= 0)) c++;
});
}, this);
return c == 1;
}
MoveList.prototype.isUniqueTo = function(pos) {
var c = 0;
_.each(this.moves, function(move) {
_.each(this.getActions(move), function(action) {
if ((action[1] !== null) && (_.indexOf(action[1], pos) >= 0)) c++;
});
}, this);
return c == 1;
}
...
MoveList.prototype.getStops = function() {
var result = this.getTargets();
_.each(this.moves, function(move) {
var actions = _.filter(this.getActions(move), isMove);
if ((actions.length > 0) && (actions[0][0].length == 1) &&
(actions[0][1].length == 1)) {
if (Dagaz.Model.smartFrom) {
if (this.isUniqueFrom(actions[0][0][0]) && !this.canPass()) {
result.push(actions[0][0][0]);
}
}
if (Dagaz.Model.smartTo) {
if (this.isUniqueTo(actions[0][1][0])) {
result.push(actions[0][1][0]);
}
}
} else {
...
}
}, this);
return _.uniq(result);
}
Видите в чём проблема? Функция getStops строит список всех завершающий полей каждого хода и, для этого, перебирает все ходы в цикле, но при включенных опциях smartFrom или smartTo (опции немедленного выполнения хода по первому «клику», при отсутствии альтернативных вариантов), выполняется вложенный перебор всех ходов. А ходов формируется много!
На небольших играх, вроде шашек или шахмат, ошибка никак не проявлялась. Даже в начальной позиции Tenjiku shogi она не была заметна. Понадобились «убийцы производительности», чтобы её выявить. А для локализации ошибки очень пригодился модуль KPI, без которого я попросту не знал бы, где искать проблему. Сейчас ошибка исправлена и, в результате, весь код стал лучше.
Итак, мы ограничены в глубине просмотра и должны принять верное (или хотя бы не катастрофическое) решение за ограниченное время. При этом, крайне желательно, чтобы обеспечивалось выполнение следующих принципов:
- Безусловно, должен выбираться ход ведущий к немедленной победе
- Не должен выбираться ход, на который имеется ответ, ведущий к немедленной победе
- Выбранный ход должен обеспечивать наибольшее улучшение позиции
Dagaz.AI.eval = function(design, params, board, player) {
var r = 0;
_.each(design.allPositions(), function(pos) {
var piece = board.getPiece(pos);
if (piece !== null) {
var v = design.price[piece.type];
if (piece.player != player) {
v = -v;
}
r += v;
}
});
return r;
}
Вторым инструментом является эвристика. Это просто числовая оценка хода, а не позиции, позволяющая отличать «плохие» ходы от «хороших». Разумеется, в первую очередь, будут рассматриваться «хорошие» ходы, а на рассмотрение «плохих» времени попросту может не остаться. Простейшая эвристика может включать стоимость взятой фигуры, но помимо этого, желательно оценивать стоимость фигуры, выполняющей ход, возможные превращения, угрозы и т.п.
Dagaz.AI.heuristic = function(ai, design, board, move) {
var r = 0;
var player = board.player;
var start = null;
var stop = null;
var captures = [];
_.each(move.actions, function(a) {
if ((a[0] !== null) && (a[1] === null)) {
var pos = a[0][0];
var piece = board.getPiece(pos);
if ((piece !== null) && (piece.player != player)) {
r += design.price[piece.type] * ai.params.CAPTURING_FACTOR;
if (!_.isUndefined(board.bonus) && (board.bonus[pos] < 0)) {
r -= board.bonus[pos];
}
}
captures.push(pos);
}
if ((a[0] !== null) && (a[1] !== null)) {
if (start === null) {
start = a[0][0];
if (!_.isUndefined(board.bonus)) {
r += board.bonus[start];
}
}
stop = a[1][0];
}
});
var price = 0;
if (start !== null) {
var piece = board.getPiece(start);
if (piece !== null) {
price = design.price[piece.type];
}
}
_.each(move.actions, function(a) {
if ((a[0] !== null) && (a[1] !== null)) {
var pos = a[1][0];
var piece = board.getPiece(pos);
if (_.indexOf(captures, pos) < 0) {
if ((piece !== null) && (piece.player != player)) {
r += design.price[piece.type] * ai.params.CAPTURING_FACTOR;
if (!_.isUndefined(board.bonus)) {
r += Math.abs(board.bonus[pos]);
}
}
if (a[2] !== null) {
var promoted = a[2][0];
r -= price * ai.params.SUICIDE_FACTOR;
if (promoted.player == player) {
r += design.price[promoted.type] * ai.params.PROMOTING_FACTOR;
}
}
} else {
r -= price * ai.params.SUICIDE_FACTOR;
}
}
if ((a[0] === null) && (a[1] !== null) && (a[2] !== null) &&
(_.indexOf(captures, a[1][0]) < 0)) {
var pos = a[1][0];
var piece = board.getPiece(pos);
if (piece !== null) {
if (piece.player != player) {
r += design.price[piece.type] * ai.params.CAPTURING_FACTOR;
}
}
piece = a[2][0];
if (piece.player == player) {
r += design.price[piece.type] * ai.params.CREATING_FACTOR;
}
}
});
if (!_.isUndefined(board.cover) && (start !== null) && (stop !== null)) {
if (isAttacked(design, board, board.player, stop, start, price)) {
r -= price * ai.params.SUICIDE_FACTOR;
}
}
return r;
}
Важно понимать, что максимальное значение эвристики вовсе не означает, что именно этот ход будет выбран. Эвристика задаёт только порядок просмотра ходов. В рамках этого порядка, выбирается ход наибольшим образом увеличивающий значение оценочной функции (после выполнения ответного хода противника с максимальной эвристикой). Можно принудительно исключать часть ходов из рассмотрения, задавая им отрицательное значение эвристики, но это средство следует использовать с осторожностью, лишь в тех случаях, когда есть стопроцентная уверенность, что рассматриваемый ход не просто бесполезный, а именно вредный.
...
design.addPiece("King", 32, 10000);
design.addPiece("Prince", 33, 10000);
design.addPiece("Blind-Tiger", 34, 3);
design.addPiece("Drunk-Elephant", 35, 3);
design.addPiece("Ferocious-Leopard", 36, 3);
design.addPiece("Gold-General", 37, 3);
design.addPiece("Silver-General", 39, 2);
design.addPiece("Copper-General", 40, 2);
design.addPiece("Chariot-Soldier", 41, 18);
design.addPiece("Dog", 43, 1);
design.addPiece("Bishop-General", 44, 21);
design.addPiece("Rook-General", 46, 23);
design.addPiece("Vice-General", 48, 39);
design.addPiece("Great-General", 49, 45);
...
Помните, выше я говорил о трёх принципах? Королевским фигурам (типов таких фигур в игре может быть несколько) имеет смысл присваивать очень высокую стоимость. Этим мы убиваем сразу двух зайцев: во первых, ход берущий королевскую фигуру получит максимально-возможную эвристику (и всегда будет рассматриваться в первую очередь), кроме того, отсутствие на доске королевской фигуры заметным образом скажется на значении оценочной функции, что также весьма удобно. К сожалению, в применении к Шахматам этот трюк не актуален, поскольку король в них никогда не берётся.
Следует отметить, что оценивать позицию всегда следует лишь по завершении ответного хода противника! Если имеется цепочка разменов, следует просматривать её до конца, в противном случае, может получиться так, что атакующая фигура будет отдана за менее ценную.
Игры более чем двух игроков — ещё одно применение казуальных «одноходовых» AI. Всё дело в оценочной функции. Минимаксные алгоритмы работают только в том случае, если оценка с точки зрения одного игрока совпадает с оценкой другого, взятой с противоположным знаком. То что теряет один — приобретает другой. Если игроков трое (или больше) — всё ломается. Разумеется, всё ещё можно применять алгоритмы на основе метода «Монте-Карло», но с ними связаны другие трудности.

Yonin Shogi — вариант «японских шахмат» для четырёх игроков. Большинство правил, в этой игре, остаются неизменными, но изменяется цель игры. Понятие «мата», в известной степени, теряет смысл. В самом деле, если «восток» угрожает королю «юга» — это ещё не повод для защиты от «шаха», пока «запад» и «север» не скажут своё слово. С другой стороны, если угроза так и не будет устранена, следующим ходом «восток» съест короля. Таким образом, в Yonin Shogi разрешается брать королей (и это является целью игры).
Кроме того, игра не заканчивается взятием короля (подобный исход был бы слишком скушен, для оставшихся трёх игроков). Игрок теряющий короля выбывает из игры, теряя право своего хода. Так как королей разрешается брать, они, как и все прочие фигуры, попадают в резерв и могут быть в любой момент поставлены на доску. Игрок обязан выставить короля из резерва, если на доске его королей не осталось. После всего сказанного, цель игры становится очевидна — побеждает тот, кто соберёт всех четырёх королей (когда я делал игру для Zillions of Games, осознать этот нюанс мне помог Howard McCay).
eval = A * material-balance + B * mobility; где A >= 0, B >= 0, A + B = 1
При применении «одноходовых» алгоритмов, оценка мобильности творит чудеса. Тупая игра бота становится более «осмысленной». Есть правда один минус — для того чтобы оценить мобильность, необходимо построить (или хотя бы пересчитать) все возможные ходы за каждого из игроков, а это — очень дорогая операция. Поскольку мы, всё равно, вынуждены этим заниматься, хочется «выжать» из генерации ходов всё возможное, а также минимизировать количество таких операций.
Dagaz.AI.eval = function(design, params, board, player) {
var r = 0;
var cover = board.getCover(design);
_.each(design.allPositions(), function(pos) {
var defended = _.filter(cover[pos], function(p) {
var piece = board.getPiece(p);
if (piece === null) return false;
return piece.player == player;
});
if (defended.length > 0) r++;
});
return r;
}
Так я пришёл к идее «покрытия». Это просто массив массивов. Для каждого из полей (а любое поле в Dagaz всегда кодируется целым числом) сохраняется, возможно пустой, список позиций, на которых расположены фигуры, способные это поле побить. При этом (и это важно) не делается различий между пустыми и занятыми полями, а также владельцами «бьющих» фигур. Список возможных ходов вычисляется для всех игроков одновременно, а за счёт кэширования, ещё и однократно.
Разумеется, универсальный алгоритм построения «покрытия» пригоден далеко не для всех игр. Для Шахмат и Шашек он работает, а вот для Спока уже нет (поскольку, в этой игре фигуры могут беспрепятственно проходить через другие фигуры своего цвета). Это не должно смущать. Также как оценочную функцию и эвристики, алгоритм построения «покрытия» можно переопределять, используя имя Dagaz.Model.GetCover. Более того, даже в тех случаях, когда универсальный алгоритм работает, бывает полезно подумать о его кастомизации. Специализированные алгоритмы, как правило, более производительны.
Вот пример использования «покрытия» в реальной игре. Это по прежнему простейший «одношаговый» алгоритм и его очень легко обмануть, но действия бота кажутся осмысленными! Анализируя покрытие, AI никогда не оставляет свои фигуры без защиты и стремится максимально «развернуть» их на доске, максимизируя количество полей, находящихся под боем. Это хорошая тактика, безусловно приводящая к победе при игре против одного «Махараджи». Также хорошо этот алгоритм показывает себя в «Charge of the Light Brigade», «Dunsany’s Chess», «Horde Chess», «Weak!» и прочих «малых» шахматных играх. Для меня очевидно, что использование «покрытия» поможет улучшить и более сложные алгоритмы, но прежде чем перейти к ним, мне необходимо потренироваться.
Обратите внимание на то, что где-то в районе 5:39 все перемещения резко ускоряются. Это объясняется просто. Параллельно с анимацией движения плашек (просто, чтобы человек не скучал), бот ведёт поиск целевой позиции и после того как её находит, идёт к ней по прямой, не теряя время на дополнительные вычисления.
Для меня, это значительный шаг вперёд, по сравнению с предыдущей версией. Алгоритм представляет собой простейший поиск в ширину (не в глубину! это важно, нас ведь интересует кратчайшее решение?). Повторные позиции отсекаются, при помощи Zobrist hash, что кстати делает возможной (хотя и крайне маловероятной) ситуацию, при которой решение может быть не найдено в результате коллизии. Кроме того, приоритет при поиске отдаётся узлам, являющимся потомками текущего узла анимации (для того чтобы минимизировать количество необходимых возвратов, после обнаружения решения).

Согласитесь, это затягивает. А уж на то, как кто-то решает головоломки за тебя, можно вообще смотреть до бесконечности. Но это только половина дела! Как и практически любую опцию Dagaz, мой «progressive levels» можно кастомизировать.

Эта головоломка была посвящена избранию Джорджа Вашингтона на пост президента и, первоначально, я реализовал её не вполне корректно. Для правильного решения необходимо провести красный квадрат через все четыре угла поочерёдно, но в Dagaz можно задать только одну цель. Здесь и вступает в действие кастомный «progressive levels».
Как только мы доходим до очередной цели, загружается следующий уровень, но расстановка фигур, при этом, берётся из предыдущего! Мы просто продолжаем с того места где остановились. Модуль, используемый для передачи позиции между уровнями, ценен сам по себе. Теперь, если включить лог браузера вовремя, можно вернуться к любой ранее пройденной позиции, практически в каждой из игр. Достаточно скопировать в URL строку, следующую в логе за надписью «Setup:». Это здорово помогает в отладке!
Кастомный «progressive levels» применим в играх со сложным жизненным циклом, таких как Kamisado. Эта игра не заканчивается при достижении одной из фигур последней линии! По правилам, фигура вошедшая в лагерь противника получает ранг «сумоиста» и дополнительные возможности, после чего, фигуры расставляются по оговоренному алгоритму и начинается следующий раунд. Теперь, Dagaz умеет это! Не сомневаюсь, возможность будет полезной при реализации многих традиционных манкал. А при очень большом желании, на его основе, вполне можно сделать какой нибудь простенький рогалик.
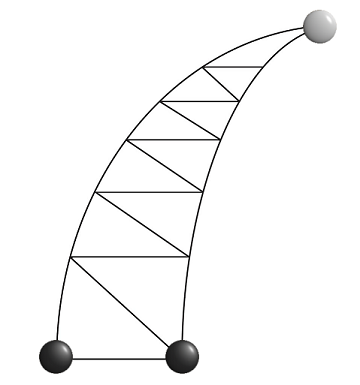
Это детская игра родом из Китая. Чёрные камни не могут перемещаться вниз, белый — двигается в любую сторону. Прежде чем читать дальше, попробуйте самостоятельно «зажать» белый камень в вершине «рога». Если не получается — ничего страшного:
Чем-то похоже на «Французскую военную игру» или «Игру гномов», но, на мой взгляд, «Роговые шахматы» намного глубже и сложнее этих игр. Если не верите, попробуйте справиться с этим. При всей внешней незатейливости, игра совсем не проста. Я видел пару научных статей (на китайском), посвящённых ей. И это хороший материал для отладки более сложных AI.
Dagaz.AI.eval = function(design, params, board, player) {
var r = 0;
var white = null;
var black = [];
for (var pos = 0; pos < design.positions.length - 3; pos++) {
var piece = board.getPiece(pos);
if (piece !== null) {
if (piece.player == 1) {
if (white === null) {
black.push(pos);
} else {
r += MAXVAL / 2;
}
} else {
white = pos;
}
}
}
if (white !== null) {
r += white;
}
if (black.length == 2) {
if ((black[0] + 1 == black[1]) && (black[1] + 1 == white)) {
if (board.player == 1) {
r = MAXVAL;
} else {
r = -MAXVAL;
}
if (player == 1) {
r = -r;
}
}
}
return r;
}
Dagaz.AI.heuristic = function(ai, design, board, move) {
var b = board.apply(move);
return design.positions.length +
Dagaz.AI.eval(design, ai.params, b, board.player) -
Dagaz.AI.eval(design, ai.params, board, board.player);
}
...
AbAi.prototype.ab = function(ctx, node, a, b, deep) {
node.loss = 0;
this.expand(ctx, node);
if (node.goal !== null) {
return -node.goal * MAXVALUE;
}
if (deep <= 0) {
return -this.eval(ctx, node);
}
node.ix = 0;
node.m = a;
while ((node.ix < node.cache.length) && (node.m <= b) &&
(Date.now() - ctx.timestamp < this.params.AI_FRAME)) {
var n = node.cache[node.ix];
if (_.isUndefined(n.win)) {
var t = -this.ab(ctx, n, -b, -node.m, deep - 1);
if ((t !== null) && (t > node.m)) {
node.m = t;
node.best = node.ix;
}
} else {
node.loss++;
}
node.ix++;
}
return node.m;
}
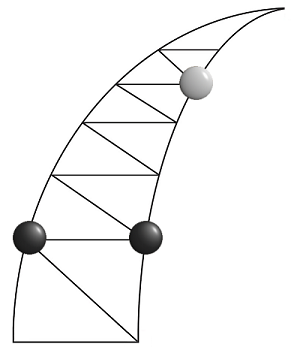
Вот один из ключевых моментов. Двигаем правый чёрный камень вверх. Более слабый «одношаговый» алгоритм идёт вниз, после чего чёрные легко загоняют его в угол. Минимаксная реализация — делает правильный ход, после которого может победить, если чёрные допустят ошибку. Это не означает, что поймать белых невозможно, но просмотр на несколько ходов вперёд значительно улучшает их игру!
Выше, на примере Tenjiku Shogi, я уже показывал, что различные настольные игры могут сильно отличаться друг от друга. Прежде всего, это касается вариативности — усреднённого количества допустимых ходов на той или иной стадии игры. Этот параметр определяет применимость алгоритма AI, при разработке бота. Совершенно очевидно, что минимаксный алгоритм, использованный мной в Horn Chess не будет работать нормально в действительно больших играх, наподобие Ko Shogi или Gwangsanghui. С другой стороны, применённый в них «агрессивный» алгоритм будет играть слишком слабо, в таких играх как «Шахматы». Но это только часть проблемы.
Главные отличия заключены в механике. К счастью, это именно то, что может быть кастомизировано оценочной функцией и эвристиками. Плохая новость заключается в том, что додуматься до того, как они должны быть простроены просто бывает далеко не всегда. Игры с «Custodian»-захватом (такие как тибетский «Минг-Манг») прекрасно иллюстрируют мой тезис.
var eval = Dagaz.AI.eval;
Dagaz.AI.eval = function(design, params, board, player) {
var r = eval(design, params, board, board.player);
var cover = board.getCover(design);
var cnt = null;
_.each(cover, function(list) {
var cn = 0;
_.each(list, function(pos) {
var piece = board.getPiece(pos);
if (piece !== null) {
if (piece.player == board.player) {
r--;
} else {
cn++;
}
}
});
if ((cnt === null) || (cnt < cn)) {
cnt = cn;
}
});
r += cnt * 3;
if (board.player != player) {
return -r;
} else {
return r;
}
}
var done = function(design, board, player, pos, dir, trace, captured) {
var p = design.navigate(player, pos, dir);
if (p !== null) {
var piece = board.getPiece(p);
if (piece !== null) {
if (piece.player == player) {
_.each(trace, function(pos) {
if (_.indexOf(captured, pos) < 0) {
captured.push(pos);
}
});
} else {
trace.push(p);
done(design, board, player, p, dir, trace, captured);
trace.pop();
}
}
}
}
var capture = function(design, board, player, pos, dir, dirs, trace, captured) {
var p = design.navigate(player, pos, dir);
if (p !== null) {
var piece = board.getPiece(p);
if (piece !== null) {
if (piece.player == player) {
_.each(trace, function(pos) {
if (_.indexOf(captured, pos) < 0) {
captured.push(pos);
}
});
} else {
trace.push(p);
capture(design, board, player, p, dir, dirs, trace, captured);
if (trace.length > 1) {
_.each(dirs, function(dir) {
var pos = design.navigate(player, p, dir);
if (pos !== null) {
var piece = board.getPiece(pos);
if ((piece !== null) && (piece.player != player)) {
trace.push(pos);
done(design, board, player, pos, dir, trace, captured);
trace.pop();
}
}
});
}
trace.pop();
}
}
}
}
var checkCapturing = function(design, board, pos, player, captured) {
var trace = [];
capture(design, board, player, pos, 3, [0, 1], trace, captured);
capture(design, board, player, pos, 1, [3, 2], trace, captured);
capture(design, board, player, pos, 2, [0, 1], trace, captured);
capture(design, board, player, pos, 0, [3, 2], trace, captured);
}
Dagaz.Model.GetCover = function(design, board) {
if (_.isUndefined(board.cover)) {
board.cover = [];
_.each(design.allPositions(), function(pos) {
board.cover[pos] = [];
if (board.getPiece(pos) === null) {
var neighbors = [];
var attackers = [];
_.each(design.allDirections(), function(dir) {
var p = design.navigate(1, pos, dir);
if (p !== null) {
var piece = board.getPiece(p);
if (piece !== null) {
neighbors.push(piece.player);
attackers.push(piece.player);
} else {
while (p !== null) {
piece = board.getPiece(p);
if (piece !== null) {
attackers.push(piece.player);
break;
}
p = design.navigate(1, p, dir);
}
}
}
});
if (neighbors.length > 1) {
var captured = [];
if ((_.indexOf(attackers, 1) >= 0) &&
(_.indexOf(neighbors, 2) >= 0)) {
checkCapturing(design, board, pos, 1, captured);
}
if ((_.indexOf(attackers, 2) >= 0) &&
(_.indexOf(neighbors, 1) >= 0)) {
checkCapturing(design, board, pos, 2, captured);
}
if (captured.length > 0) {
board.cover[pos] = _.uniq(captured);
}
}
}
});
}
return board.cover;
}
В оценочной функции, мне пришлось не просто использовать «покрытие», но и серьёзно переделать алгоритм его вычисления. Что касается эвристики, она в этой игре совершенно элементарна:
Dagaz.AI.heuristic = function(ai, design, board, move) {
return move.actions.length;
}
Чем больше фигур возьмёт ход (от этого зависит его размер) — тем лучше! Над оценочной функцией пришлось серьёзно потрудиться, но результат того определённо стоил:
Замечу, на видео представлена работа простейшего «одноходового» алгоритма (можно заметить, что при отсутствии «безопасных» ходов он не всегда играет достаточно эффективно). Как я уже говорил выше, учёт в оценке мобильности и «покрытия» творит чудеса!
И напоследок, видео ещё одной, крайне необычной, игры с custodian-захватом:
А всех дам спешу поздравить с наступающим праздником!
