Что такое Docker: краткий экскурс в историю и основные абстракции
10 августа в Слёрм стартовал видеокурс по Docker, в котором мы разбираем его полностью — от основных абстракций до параметров сети.
В этой статье поговорим об истории появления Docker и его основных абстракциях: Image, Cli, Dockerfile. Лекция рассчитана на новичков, поэтому вряд ли будет интересна опытным пользователям. Здесь не будет крови, аппендикса и глубокого погружения. Самые основы.

Что такое Docker
Посмотрим на определение Docker из Википедии.
Docker — это программное обеспечение для автоматизации развёртывания и управления приложениями в средах с поддержкой контейнеризации.
Из этого определения ничего непонятно. Особенно непонятно, что значит «в средах с поддержкой контейнеризации». Чтобы разобраться, вернёмся в прошлое. Начнём с эпохи, которую я условно называю «Монолитной эрой».
Монолитная эра
Монолитная эра — это начало 2000-х, когда все приложения были монолитными, с кучей зависимостей. Разработка шла долго. При этом серверов было не так много, мы все их знали по именам и мониторили. Есть такое забавное сравнение:
Pets — это домашние животные. В монолитной эре мы относились к своим серверам, как к домашним животным, холили и лелеяли, пылинки сдували. А для лучшего управления ресурсами использовали виртуализацию: брали сервер и пилили на несколько виртуальных машин, тем самым обеспечивая изоляцию окружения.
Системы виртуализации на базе гипервизора
Про системы виртуализации наверняка все слышали: VMware, VirtualBox, Hyper-V, Qemu KVM и т. д. Они обеспечивают изоляцию приложений и управление ресурсами, но у них есть и минусы. Чтобы сделать виртуализацию, нужен гипервизор. А гипервизор — это оверхед ресурсов. Да и сама виртуальная машина обычно целая махина — тяжелый образ, на нём операционная система, Nginx, Apache, возможно и MySQL. Образ большой, виртуальной машиной неудобно оперировать. Как следствие, работа с виртуалками может быть медленной. Чтобы решить эту проблему, создали системы виртуализации на уровне ядра.
Системы виртуализации на уровне ядра
Виртуализацию на уровне ядра поддерживают системы OpenVZ, Systemd-nspawn, LXC. Яркий пример такой виртуализации — LXC (Linux Containers).
LXC — система виртуализации на уровне операционной системы для запуска нескольких изолированных экземпляров операционной системы Linux на одном узле. LXC не использует виртуальные машины, а создаёт виртуальное окружение с собственным пространством процессов и сетевым стеком.
По сути LXC создаёт контейнеры. В чём разница между виртуальными машинами и контейнерами?

Контейнер не подходит для изолирования процессов: в системах виртуализации на уровне ядра находят уязвимости, которые позволяют вылезти из контейнера на хост. Поэтому если вам нужно что-то изолировать, то лучше использовать виртуалку.
Различия между виртуализацией и контейнеризацией можно увидеть на схеме.
Бывают аппаратные гипервизоры, гипервизоры поверх ОС и контейнеры.
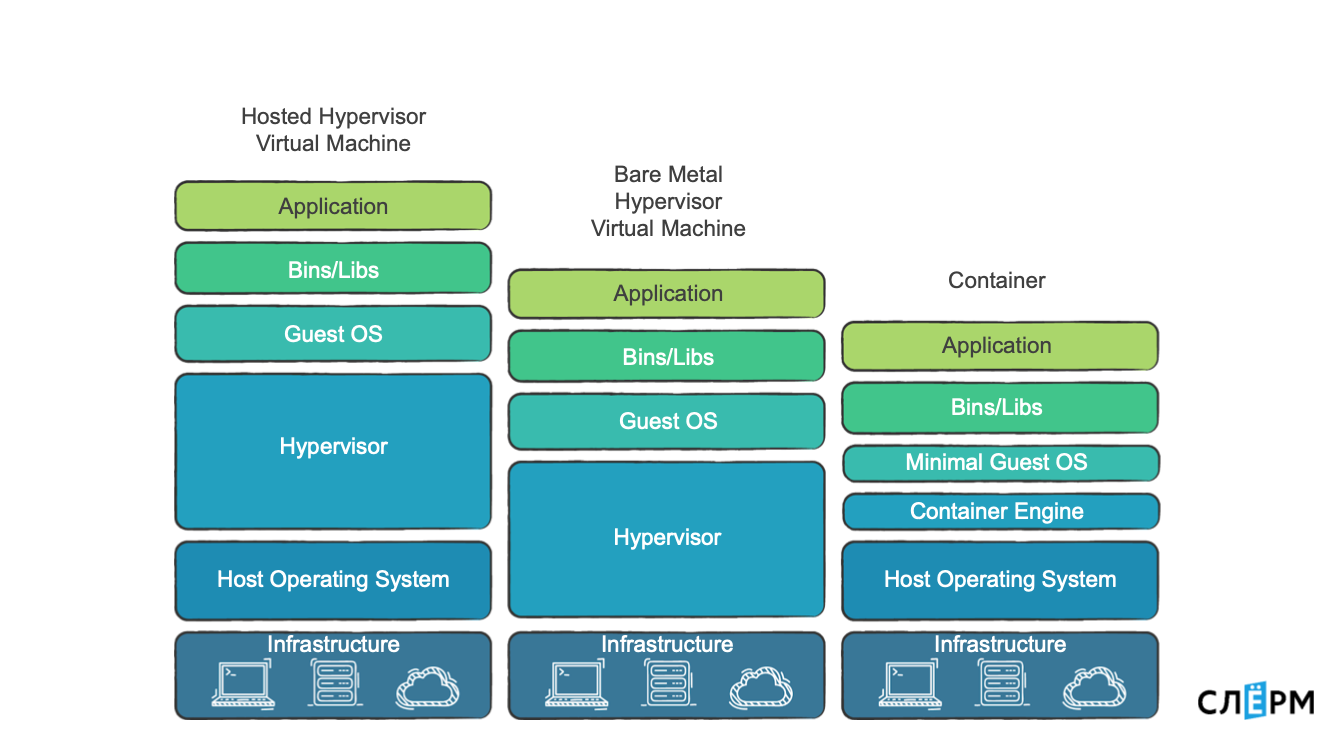
«Железные» гипервизоры — это крутая штука, если вы действительно хотите что-то изолировать. Потому что там есть возможность изолировать на уровне страниц памяти, процессоров.
Есть гипервизоры как программа, и есть контейнеры, о них мы и будем говорить дальше. В системах контейнеризации гипервизора нет, но есть Container Engine, который создаёт контейнеры и управляет ими. Штука это более легковесная, поэтому за счет работы с ядром оверхед меньше, или его нет совсем.
Что используется для контейнеризации на уровне ядра
Основные технологии, которые позволяют создавать изолированный от других процессов контейнер, — это Namespaces и Control Groups.
Namespaces: PID, Networking, Mount и User. Есть ещё, но для простоты понимания остановимся на этих.
PID Namespace ограничивает процессы. Когда мы, например, создаём PID Namespace, помещаем туда процесс, то он становится с PID 1. Обычно в системах PID 1 — это systemd или init. Соответственно, когда мы помещаем процесс в новый namespace, он тоже получает PID 1.
Networking Namespace позволяет ограничить/изолировать сеть и внутри уже размещать свои интерфейсы. Mount — это ограничение по файловой системе. User — ограничение по юзерам.
Control Groups: Memory, CPU, IOPS, Network — всего около 12 настроек. Иначе их ещё называют Cgroups («Cи-группы»).
Control Groups управляют ресурсами для контейнера. Через Control Groups мы можем сказать, что контейнер не должен потреблять больше какого-то количества ресурсов.
Чтобы контейнеризация полноценно работала, используются дополнительные технологии: Capabilities, Copy-on-write и другие.
Capabilities — это когда мы говорим процессу, что он может делать, а чего не может. На уровне ядра это просто битовые карты со множеством параметров. Например, пользователь root имеет полные привилегии, может делать всё. Сервер времени может изменять системное время: у него есть capabilities на Time Capsule, и всё. С помощью привилегий можно гибко настроить ограничения для процессов, и тем самым обезопасить себя.
Система Copy-on-write позволяет нам работать с образами Docker, использовать их более эффективно.
На данный момент Docker имеет проблемы с совместимостью Cgroups v2, поэтому в статье рассматриваются именно Cgroups v1.
Но вернёмся к истории.
Когда появились системы виртуализации на уровне ядра, их начали активно применять. Оверхед на гипервизор пропал, но некоторые проблемы остались:
- большие образы: в ту же OpenVZ толкают операционку, библиотеки, кучу разного софта, и в итоге образ всё равно получается немаленьким;
- нет нормального стандарта упаковки и доставки, поэтому остаётся проблема зависимостей. Бывают ситуации, когда два куска кода используют одну библиотеку, но с разными версиями. Между ними возможен конфликт.
Чтобы все эти проблемы решить, пришла следующая эра.
Эра контейнеров
Когда наступила Эра контейнеров, сменилась философия работы с ними:
- Один процесс — один контейнер.
- Все нужные процессу зависимости доставляем в его контейнер. Это требует распиливать монолиты на микросервисы.
- Чем меньше образ, тем лучше — меньше возможных уязвимостей, быстрее раскатывается и так далее.
- Инстансы становятся эфемерными.
Помните, я говорил про pets vs cattle? Раньше инстансы были подобны домашним животным, а теперь стали как cattle — скот. Раньше был монолит — одно приложение. Теперь это 100 микросервисов, 100 контейнеров. У каких-то контейнеров может быть по 2–3 реплики. Нам становится не столь важно контролировать каждый контейнер. Нам скорее важна доступность самого сервиса: того, что делает этот набор контейнеров. Это меняет подходы в мониторинге.
В 2014–2015 годах случился расцвет Docker — той технологии, о которой мы и будем сейчас говорить.
Docker изменил философию и стандартизировал упаковку приложения. С помощью Docker мы можем упаковать приложение, отправить его в репозиторий, скачать оттуда, развернуть.
В Docker-контейнер мы закладываем всё необходимое, поэтому решается проблема зависимостей. Docker гарантирует воспроизводимость. Я думаю, многие сталкивались с невоспроизводимостью: у тебя всё работает, пушишь на продакшен, там это перестает работать. С Docker эта проблема уходит. Если твой Docker-контейнер запускается и делает то, что требуется делать, то с большой долей вероятности он запустится на продакшене и там сделает то же самое.
Отступление про оверхед
По поводу оверхед постоянно идут споры. Кто-то считает, что Docker не несёт дополнительную нагрузку, так как использует ядро Linux и все его процессы, необходимые для контейнеризации. Мол, «если вы говорите, что Docker — это оверхед, то тогда и ядро Linux оверхед».
С другой стороны, если углубиться, то в Docker и правда есть несколько вещей, про которые с натяжкой можно сказать, что это оверхед.
Первое — это PID namespace. Когда мы в namespace помещаем какой-то процесс, ему присваивается PID 1. В то же время у этого процесса есть ещё один PID, который находится на хостовом namespace, за пределами контейнера. Например, мы запустили в контейнере Nginx, он стал PID 1 (мастер-процесс). А на хосте у него PID 12623. И сложно сказать, насколько это оверхед.
Вторая штука — это Cgroups. Возьмём Cgroups по памяти, то есть возможность ограничивать контейнеру память. При её включении активируются счётчики, memory accounting: ядру надо понимать, сколько страниц выделено, а сколько ещё свободно для этого контейнера. Это возможно оверхед, но точных исследований о том, как он влияет на производительность, я не встречал. И сам не замечал, что приложение, запущенное в Docker, вдруг резко теряло в производительности.
И ещё одно замечание о производительности. Некоторые параметры ядра прокидываются с хоста в контейнер. В частности, некоторые сетевые параметры. Поэтому если вы хотите запустить в Docker что-то высокопроизводительное, например то, что будет активно использовать сеть, то вам, как минимум, надо эти параметры подправить. Какой-нибудь nf_conntrack, к примеру.
О концепции Docker
Docker состоит из нескольких компонентов:
- Docker Daemon — то самое Container Engine; запускает контейнеры.
- Docker CII — утилита по управлению Docker.
- Dockerfile — инструкция по тому, как собирать образ.
- Image — образ, из которого раскатывается контейнер.
- Container.
- Docker registry — хранилище образов.
Схематично это выглядит примерно вот так:
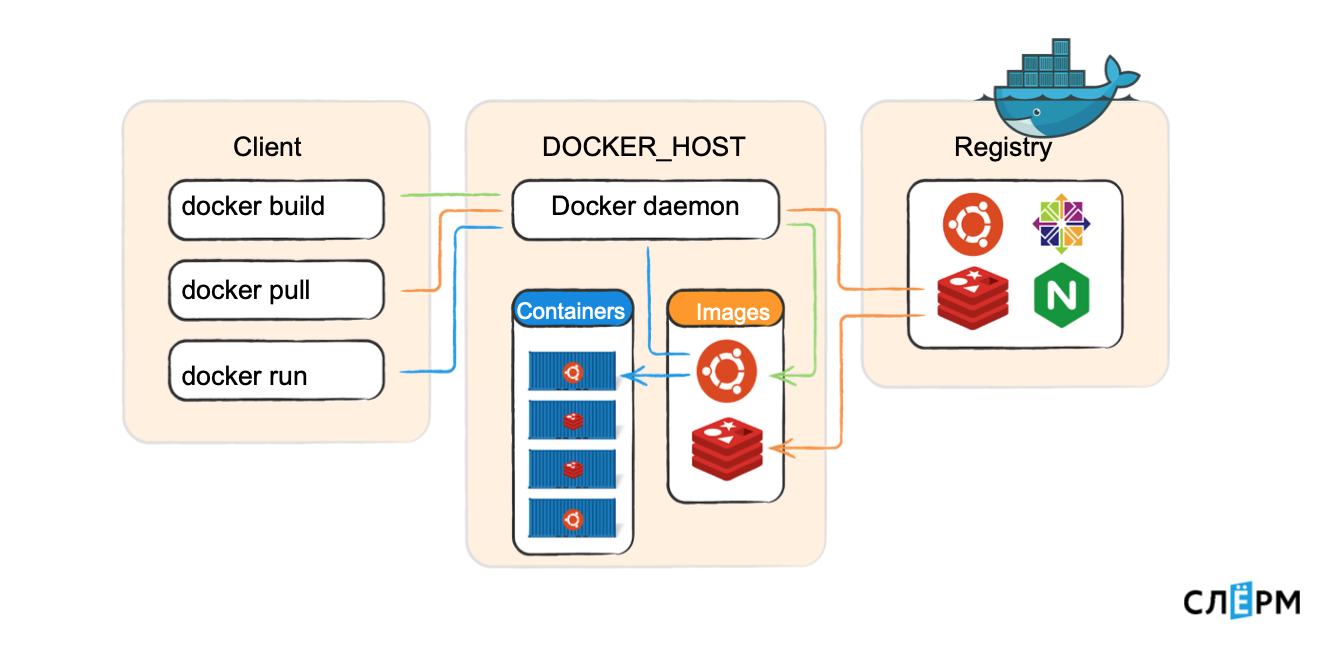
На Docker_host работает Docker daemon, запускает контейнеры. Есть Client, который передаёт команды: собери образ, скачай образ, запусти контейнер. Docker daemon ходит в registry и выполняет их. Docker-клиент может обращаться и локально (к юникс-сокету), и по TCP с удалённого хоста.
Пройдёмся по каждому компоненту.
Docker daemon (демон) — это серверная часть, она работает на хост-машине: скачивает образы и запускает из них контейнеры, создаёт сеть между контейнерами, собирает логи. Когда мы говорим «создай образ», этим тоже занимается демон.
Docker CLI — клиентская часть Docker, консольная утилита для работы с демоном. Повторю, она может работать не только локально, но и по сети.
Базовые команды:
docker ps — показать контейнеры, которые сейчас запущены на Docker-хосте.
docker images — показать образы, скачанные локально.
docker search <> — поиск образа в registry.
docker pull <> — скачать образ из registry на машину.
docker build <> — собрать образ.
docker run <> — запуск контейнер.
docker rm <> — удалить контейнер.
docker ps — список работающих контейнеров.
docker logs <> — логи контейнера
docker start/stop/restart <> — работа с контейнером
Если вы освоите эти команды и будете уверенно ими пользоваться, то считайте, что на 70% освоили Docker на уровне пользователя.
Dockerfile — инструкция для создания образа. Почти каждая команда инструкции — новый слой. Посмотрим на примере.

Примерно так выглядит Dockerfile: слева команды, справа — аргументы. Каждая команда, что здесь есть (и вообще пишется в Dockerfile), создаёт новый слой в Image.
Даже глядя на левую часть, можно примерно понять, что происходит. Мы говорим: «создай нам папку» — это один слой. «Сделай папку рабочей» — это ещё один слой, и так далее. Слоёный пирог упрощает жизнь. Если я создам ещё один Dockerfile и в последней строчке что-то изменю — запущу не «python» «main.py», а что-нибудь другое, или установлю зависимости из другого файла — то предыдущие слои будут переиспользованы, как кеш.
Image — это упаковка контейнера, из образа запускаются контейнеры. Если смотреть на Docker с точки зрения пакетного менеджера (как будто мы работаем с deb или rpm-пакетами), то image — это по сути rpm-пакет. Через yum install мы можем поставить приложение, удалить его, найти в репозитории, скачать. Здесь примерно то же самое: из образа запускаются контейнеры, они хранятся в Docker registry (по аналогии с yum, в репозитории), и каждый image имеет хеш SHA-256, имя и тег.
Image собирается по инструкции из Dockerfile. Каждая инструкция из Dockerfile создаёт новый слой. Слои могут использоваться повторно.
Docker registry — это репозиторий образов Docker. По аналогии с ОС, у Docker есть общедоступный стандартный реестр — dockerhub. Но можно собрать свой репозиторий, свой Docker registry.
Container — то, что запускается из образа. По инструкции из Dockerfile собрали образ, затем мы его из этого образа запускаем. Этот контейнер изолирован от остальных контейнеров, он должен содержать в себе всё необходимое для работы приложения. При этом один контейнер — один процесс. Случается, что приходится делать два процесса, но это несколько противоречит идеологии Docker.
Требование «один контейнер — один процесс» связано с PID Namespace. Когда в Namespace запускается процесс с PID 1, если он вдруг умрёт, то весь контейнер тоже умирает. Если же там запущено два процесса: один живёт, а второй умер, то контейнер всё равно продолжит жить. Но это к вопросу Best Practices, мы про них поговорим в других материалах.
Более детально изучить особенности и полную программу курса можно по ссылке: «Видеокурс по Docker».
Автор: Марсель Ибраев, сертифицированный администратор Kubernetes, практикующий инженер в компании Southbridge, спикер и разработчик курсов Слёрм.
