Что нужно для внедрения Apache Superset
Apache Superset — это активно набирающий популярность open source продукт для построения бизнес-аналитики.
Уже много написано о его развертывании и о его технических особенностях, поэтому мне бы хотелось поговорить об опыте внедрения Superset с организационной точки зрения, а также я постараюсь описать техническое окружение и важные отличия от Power BI. Отдельно остановлюсь на системе прав доступа, т.к. в нашей компании этот вопрос важен.
Сначала расскажу о распределении обязанностей с сфере BI, которое мы используем.
В процессе участвуют 3 основных роли:
ИТ — основная функция ИТ — это поддержка аналитического хранилища данных, построенного на основе распределенной базы Postgres. ИТ решает поступающие от бизнеса задачи (запросы) по загрузке новых данных в хранилище. Основной фокус — это качество данных и надежность решения, а также создание архитектуры, обеспечивающей максимальное быстродействие. Также на ИТ ложится соблюдение конвенции имен и использование точных терминов при именовании полей и таблиц.
Аналитики — сотрудники из бизнес-подразделений. Собственно те люди, которые делают дашборды. Они хорошо понимают задачи и потребности их конечных пользователей и имеют навыки презентации и донесения информации, основанной на цифрах. При использовании Superset становится необходимо, чтобы аналитики знали SQL на базовом или среднем уровне. Если аналитикам нужны какие-то новые данные в хранилище, то они запрашивают интеграцию этих данных в ИТ.
Конечные бизнес-пользователи — их задача просто войти в систему и использовать дашборды в своих процессах. Они контактируют с аналитиками при возникновении новых запросов.
Далее опишу, что пришлось сделать, чтобы реализовать описанную схему взаимодействия с использованием Superset:
Сделать хранилище данных быстрым. Аналитическое хранилище должно быть быстрым, иначе пользоваться Superset практически не получится. Думаю, кэширование дашбородов, предусмотренное в superset, это не самый лучший путь по причине вариативности запросов с различными фильтрами.
В нашем случае из этого следует, что данные должны быть предобработаны на «мастер-нодах» таким образом, чтобы минимизировать нагрузку в основном хранилище. Для передачи данных в основное хранилище используется стандартная логическая репликация в Postgres.У нас данные обладают не столько большими объемами, сколько большим разнообразием и при этом часто обновляются. По этой причине мы используем традиционную базу данных, а не колоночную. (Замечу также, что в Postgres есть расширение Citus, которое можно использовать для колоночного или смешанного хранения для того, чтобы ускорить агрегированные запросы по большим таблицам.)
Настроить систему прав доступа в хранилище данных. Как мы понимаем, данные могут быть конфиденциальными, поэтому для аналитиков создаем группы доступа и определяем их права в базе.
Нам потребовалось настроить ldap в Postgres, чтобы не думать о паролях, об удалении уволившихся сотрудников и т.д.
Для каждой группы аналитиков (отдела) создаем схему, в которой даем полные права для создания собственных представлений (view).
Последнее необходимо сделать, т.к. если писать запрос в самом Superet (virtual), то работает это с Postgres намного медленнее, чем обращение к view (как physical). В этом несложно убедиться, например, проверив запросы в pg_stat_statements. В режиме «physical» система Superset строит вполне «адекватные» запросы к базе данных.Обучить аналитиков. Проблема в том, что не все аналитики знают SQL, хотя многие из них учили SQL в институте или на разных дополнительных курсах. Чтобы подтянуть знания, нам пришлось записать небольшой курс включающий: немного теории СУБД, структуру нашего хранилища, тренинги на тему того, как писать SELECT и создавать VIEW, а также как строить дашборды в суперсете. (Конечно, при этом ИТ поддерживает аналитиков при написании сложных запросов и при оптимизации медленных запросов.) В целом, для аналитиков «прокачка» таких знаний интересна, т.к. у них есть желание быть востребованными специалистами.
Организовать систему прав доступа в самом Superset.
Сначала поговорим об аутентификации пользователей. Чтобы «логинить» пользователей, мы используем сервер Keycloak, интегрированный с Superset. Keycloak пробрасывает запросы в Active Directory (AD) и сообщает данные пользователя в Superset, включая группы доступа из AD. Далее Superset, через настроенный мэппинг, автоматически присваивает пользователю его роли. Пользователь может быть авторизован как редактор дашбордов (аналитик) или как конечный пользователь с определенными ролями для просмотра дашбордов.
Для того, чтобы разграничить доступы редакторов (аналитиков), нужно дать права на подключение к базе (database connection). Т.е. по сути это подключение к базе данных с определенным системным логином, для которого заданы нужные права. (Как альтернативный вариант, можно разграничить доступ на уровне схем.)
Для того, чтобы разграничить доступы конечных пользователей, нужно включить в их роли нужные датасеты (это делает ИТ). Необычной особенностью Superset является то, что назначение прав к дашбордам происходит через датасеты. Т.е. пользователь видит список дашбордов в соответствии с доступностью использованных в них датасетов. (К такому подходу нужно привыкнуть).
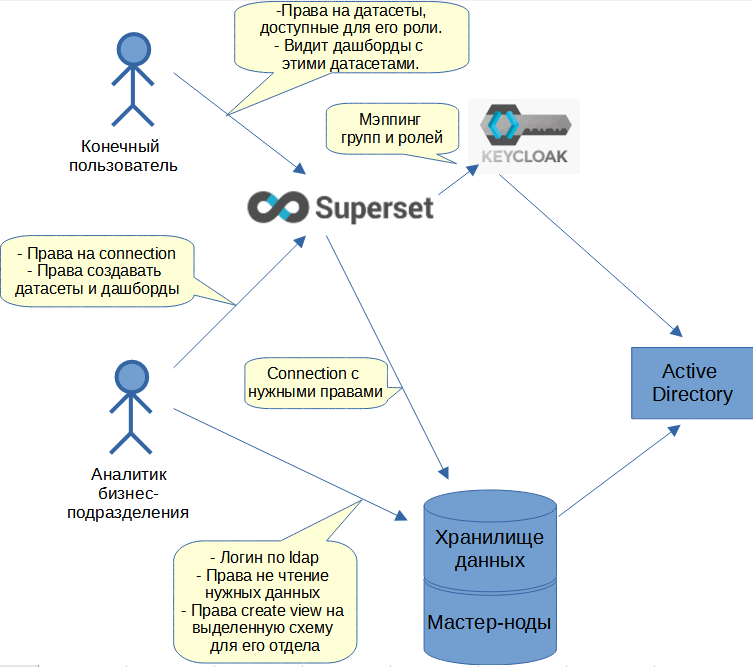
Общая архитектура системы прав доступа
Сделать в superset разные мелкие дополнительные настройки
Коды валют, форматы чисел, часовой пояс по умолчанию.
Настроить почтовый ящик и систему для рассылки дашбородов. Некоторые пользователи любят получать графики на email. Этот функционал в Superset вполне работоспособен, но требуется повозиться с конфигурированием.
Небольшое сравнение с Power BI
Можно говорить о множестве различий обеих систем, но хочу остановиться на том, что мне кажется ключевым при переходе на Superset:
Системе Superset необходимо быстродействие БД. Power BI может делать модель данных «офлайн» и обновлять конкретный дашборд по расписанию. В Superset, можно сказать, что такой возможности нет (кэширование отчасти помогает, но быстродействие БД все равно требуется).
Superset не может использовать Excel в качестве источника данных. Конечно, Excel это очевидное зло, но до пользователей эту идею донести непросто. При использовании Superset придется сначала загрузить Excel в БД или найти нужные данные в более надежном источнике.
Дизайн дашборда в Superset происходит в браузере (он-лайн). Power BI требует установки клиентского приложения и зачастую требует выгрузку данных на клиента. На мой взгляд, подход Superset выглядит более современным и позволяет работать с большими объемами непосредственно на сервере.
В Superset нет системы папок для упорядочивания дашбордов. Нужно отметить, что на момент написания этой статьи в Superset уже разрабатывается система тэгов, как некоторый аналог папок. Сейчас пока убираем лишние для пользователя дашборды, используя права доступа.
В Superset нет мобильного приложения. Как утешение, можно предложить только отправку дашбордов на почтовый ящик.
Дополнительно отмечу, что пользователям нравится эргономика и дизайн Superset. Думаю этот фактор немало помогает во внедрении.
Надеюсь, мне удалось рассказать о том, что находится вокруг системы Superset и поделиться полезным опытом.
Статья скорее получилась обзорная. Если кому-то интересны технические нюансы, то постараюсь ответить в чате или в личных сообщениях. Буду рад, если члены сообщества поделятся парой интересных идей или альтернативных мнений по этой теме.
