Что делают дата-инженеры, когда данные сами движутся между десятками систем?

Привет, Хабр! Меня зовут Андрей Гончаров, я дата-инженер в Garage Eight, и сегодня я расскажу о том, как мы подходим к батч-процессингу и нашей self-service платформе данных. Почему self-service? Традиционный подход к работе с данными подразумевает, что данные готовят и перемещают между информационными системами дата-инженеры.
Однако, с ростом data-driven компаний растут и потребности бизнеса, нужно анализировать и перемещать все больше данных между все большим количеством информационных систем, и требуется это все большему количеству потребителей данных: аналитикам, продакт-менеджерам, разработчикам и другим. В связи с чем растет и нагрузка на дата-инженеров, они работают со всё растущим количеством данных, бизнес-сущностей, и, по сути, владеют ими. Остается мало времени на модернизацию дата-инженерных инструментов, растет техдолг. Для снижения нагрузки можно увеличивать дата-инженерный штат, что является не лучшим вариантом — в таком случае, нам потребуется дата-департамент, растущий пропорционально с бизнесом.
Давайте посмотрим, как мы решаем эти проблемы.
Требования к платформе данных
Чтобы не наступить на грабли описанных выше процессов нами были сформированы требования к платформе данных:
Данными должны владеть и манипулировать их потребители
Дата-инженеры отвечают за инфраструктуру
Хранилище: BigQuery

В центре любой платформы данных должно лежать надёжное и отвечающее потребностям хранилище. Для нас это Google Bigquery, выбрали мы его благодаря многочисленным преимуществам этого облачного сервиса:
Масштабируемость. Нам не нужно думать, где хранить постоянно растущие объемы данных, и как их обрабатывать. Google Bigquery сам позаботится об этом, и справится с анализом петабайтов данных. Можно обойтись без администратора баз данных, который бы занимался поддержкой «железа» хранилища, увеличивал бы объем памяти и вычислительные ресурсы.
Отказоустойчивость. Google Bigquery обеспечивает SLA «четыре девятки», за 3.5 года использования мы столкнулись с одним часовым периодом недоступности. И снова нам не нужен администратор баз данных, который бы следил за доступностью сервиса.
Отличный SQL-диалект. Множество агрегатных функций, в том числе оконных, нативная работа с JSON, структурные типы данных, писать запросы для Google Bigquery — одно удовольствие.
Низкий порог входа. Google Bigquery не требует чрезмерной оптимизации запросов, не нужно быть гуру SQL, чтобы делать аналитику. Эта фича для нас особенно важна, ибо нашей платформой данных пользуются сотрудники с совершенно различными компетенциями.
Гибкая система оплаты. Мы платим только за выполненные запросы, а точнее — за прочитанный объем данных. Загрузка и выгрузка целых таблиц бесплатна, хранение данных почти ничего не стоит.
Оркестрация: Apache Airflow

Понятно, что данные сами собой в хранилище не попадут, поэтому нужен какой-то оркестратор, который будет управлять pipeline«ами. Для нас это Apache Airflow.
Это зрелый, надежный и популярный инструмент. Поддержка не прекращается, обновления выходят, комьюнити растет — что еще нужно?
Он легко масштабируется.
Позволяет динамически генерировать графы задач.
Легко расширяется кодом.
Классический подход при работе с Apache Airflow это использовать его примитивы для операций с данными, коннекторы для информационных систем, описывать потоки данных, и все это делать путем написания Python кода. Однако, с ростом ETL проекта, будет расти кодовая база — нужно описывать все больше задач по перемещению данных. Также, через некоторое время жизни проекта, когда уже реализована функциональность для перемещения данных, описано их перемещение, может возникнуть необходимость развернуть аналогичный сервис, но для другого бизнес-продукта, или для другого региона. Что тогда делать? Копировать код, и потом поддерживать его в двух экземплярах? Или пытаться внедрить новые задачи в существующие графы?
Чтобы избежать подобных проблем, мы используем Apache Airflow сугубо как оркестратор, не связывая себя использованием его встроенной функциональности, которой все равно не хватает. Мы сами реализуем коннекторы для работы с различными информационными системами, получая таким образом больше контроля и понимания, как данные движутся. И, в случае необходимости, мы сможем легко перейти с Apache Airflow, если он внезапно перестанет нас устраивать как оркестратор.
Кроме того, мы разделили функциональную и декларативную части работы с данными. Функциональная часть характеризует как мы работаем с данными, а декларативная часть описывает какие данные мы перемещаем, трансформируем и отправляем дальше в целевые информационные системы.

Функциональная часть
Функциональная часть называется «генератором графов» и делает именно то, что следует из названия: динамически генерирует графы AirFlow на основе описаний задач. Узлом графа является задача по перемещению данных, реализованная нами через кастомный оператор Apache Airflow, выполняющий нужный для перемещения данных код.
Задачи по перемещению данных состоят из компонентов; например, для перемещения данных из MySQL в Google Bigquery, служит следующая цепочка:
MySQL → CSV
CSV → Google Cloud Storage (S3-подобное облачное файловое хранилище)
Google Cloud Storage → Google Bigquery
Эти компоненты переиспользуются в других задачах, чтобы создавать новые связки источников и назначений данных, и интеграций у нас реализовано достаточно много:

Декларативная часть
В то время как генератор графов реализован единожды и служит бэкендом для всех наших экземпляров платформ данных, декларативная часть уникальна для каждого экземпляра и представляет собой набор YAML-файлов с описанием задач и общие для всего проекта параметры — именованные коннекты к источникам данных, вроде микросервисных баз, креды для доступа к API маркетинговых и аналитических систем и подобное.
Рассмотрим описание задачи на примере перемещения данных из реляционной базы микросервиса в хранилище.
task_id: countries_raw
type: rdb_to_bigquery
connection: main
sql_path: countries.sql
dataset: raw_data
table: countries
schedule: dailytask_id — уникальное имя задачи
type — тип задачи, в нашем случае — перемещение данных из реляционное базы в Google Bigquery
connection — имя коннекта-источника данных; поскольку при описании коннекта мы также указываем и его тип, нет нужды создавать отдельные типы задач под разные СУБД, нужный коннектор можно выбрать на этапе выполнения задачи
sql_path — путь к скрипту, результат которого мы хотим поместить в хранилище
dataset — датасет-назначение в Google Bigquery (аналог схемы в традиционных БД). Имя Google Cloud проекта хранилища указывается в общих для экземпляра платформы конфигах
table — таблица-назначение в Google Bigquery
schedule— как часто будет выполняться задача — ежедневно, ежечасно и т.д. По умолчанию задачу считаем ежедневной
На основе ключа schedule генератор графов относит задачи к одному графу — нашей платформой пользуются много сотрудников из разных подразделений, задачи порой сложно отнести к какой-то конкретной области, поэтому было принято решение не пытаться это сделать и не плодить графы.
В предыдущем примере описана задача, которая перемещает сырые данные в хранилище. Но что делать, если нужно подготовить перемещенные данные, и выполнить такую задачу строго, когда сырые данные перемещены в хранилище, как указать, что у задачи есть зависимость от других задач? В таком случае нам на помощь приходит ключ depends_on:
task_id: users
type: bq_create_table
dataset: prepared
table: users
sql_path: users.sql
depends_on:
- users_rawГенератор графов компонует задачи с учетом указанных зависимостей.
Чтобы исключить зависимость от имени таблицы, в SQL скриптах мы преобразуем имена таблиц в имена задач (да, да, как в dbt — когда мы начинали разрабатывать нашу платформу, dbt не пользовался особой популярностью). Таким образом скрипт
SELECT * FROM raw_data.usersиспользующий таблицу из задачи с task_id: users_raw, преобразуется в
SELECT * FROM `%TASK_users_raw%`При построении графа шаблон будет преобразован в имя таблицы из задачи; даже если с прошлого запуска эта таблицы была переименована, запрос выполнится успешно. Для облегчения шаблонизации пользователи платформы имеют в своей распоряжении скрипт, который преобразует имена таблиц в имена задач и наоборот, и добавляет необходимые зависимости в определение задачи.
К этому момент пазл должен сложиться — генератор графов получает на вход набор YAML. Графы компонуются из задач указанных типов, на основе указанных расписаний и зависимостей. Задачи используют уникальные для экземпляра платформы данных конфиги, такие, как коннекты к базам и креды для API.
В итоге мы получаем не завязанную строго на Apache Airflow платформу данных, единую кодовую базу под разные наборы задач, одновременную доставку обновлений и улучшений на все экземпляры платформы данных (которых у нас в данном моменте 5).
А что на практике?
Рассмотрим некоторые возможности нашей платформы данных и ее использование на практике.
Простота подготовки данных для аналитики
Одной из основных аналитических систем в Garage Eight является Tableau. Отчетов у нас больше 200, большой размер витрин для них исключает получение данных на лету — отчеты нужно формировать заранее, когда их витрины обновились после ежедневной загрузки данных. Как же синхронизировать формирование отчета и готовность витрин? Можно, конечно, подсчитать примерное время, когда все витрины данных готовы, и установить соответствующее расписание для обновления отчета. Однако возникают проблемы:
В процессе подготовки витрин может возникнуть ошибка, данные в них могут обновиться некорректно, или вообще не обновиться. В таком случае отчет тоже будет сформирован на этих некорректных данных
Время обновления витрин может меняться, и отчет может быть сформирован или слишком рано, или слишком поздно
Каждый раз, когда аналитик добавляет новый отчет, ему нужно выяснять время обновления всех его витрин и выставлять расписание, что, конечно же, неудобно
Решением для нас стал «умный» подход к работе с Tableau: специальный микросервис регулярно получает список отчетов, парсит их определение и находит имена витрин-таблиц в хранилище, которые использует отчет. А задачи по обновлению отчета генерируются автоматически на основе этих данных, и встраиваются в графы после всех зависимостей. Если задача для обновления витрин выполнилась с ошибкой — отчет не обновится, отчеты обновляются максимально близко к идеальному времени и не нужно гадать о расписании их обновления.
Доступность
Бывает, что есть необходимость следить за некими бизнес-метриками, но не хочется для этого выгружать отчет. Для этого нами предусмотрена возможность отправки результатов запроса, который вычисляет эти метрики себе в Slack. Настроить подобную отправку очень просто:
Нужно написать SQL-скрипт
Сформировать YAML-описание задачи с определенным типом — отправкой данных в Slack
Отправить задачу в репозиторий
И спустя 10 секунд ваша задача будет подхвачена платформой данных и готова к выполнению — реализован CD сервис, который регулярно подтягивает изменения из репозитория с задачами, платформа данных всегда работает с последней версией набора задач. А чтобы у пользователя была возможность самому запускать задачи, имеется Slack-бот, отправляющий сообщений с предложением запустить созданную или измененную задачу:

После запуска статус задачи будет обновляться, будет доступна ссылка на ее лог выполнения:

Результат выполнения задачи также будет отправлен, а в случае ошибки пользователь сможет по логам понять, как эту ошибку исправить.

Таким образом, любой желающий может заниматься дата-инженерией, и в кратчайшие сроки автоматизировать свои расчеты.
Открытость
Если же какая-то функциональность или тип задачи еще не реализованы, желающий может модернизировать платформу данных по своему желанию — код открыт для редактирования. И новые возможности будут доступны всем нуждающимся потребителям данных, их поставка не завязана на дата-инженерах (хотя, мы, конечно, проверяем все изменения).
Любой язык
Для запуска специализированного или уже написанного кода на отличном от Python языке предусмотрена возможность запуска контейнеров. Все, что нужно пользователю — это обернуть код в среду для его запуска и создать соответствующую задачу. Код будет запущен в нужное время, когда данные для него готовы.
Data lineage
У всего есть цена, и цена удобства нашей платформы данных в том, что ей пользуются. Бесплатный ежемесячный терабайт данных в Google Bigquery расходуется за 1 минуту, а ежедневный граф на 2200+ в самом крупном проекте выглядит так:

Для того, чтобы поддерживать порядок в данных, получать информацию об их происхождении и описывать их, мы используем систему описания метаданных DataHub. Она позволяет вести Data lineage, описывать сущности, указывать владельца данных.
Удобство использования достигается интеграцией с платформой данных — метаданные таблиц со всеми полями, типами данных, зависимостях и владельце таблицы автоматически отправляются в DataHub при изменении или создании таблицы в результате работы задачи платформы данных. Автору изменений отправляется в Slack сообщение с предложением описать таблицу или обновить существующее описание.

Интеграции со Slack
Ранее я уже упоминал несколько интеграций, вот еще несколько удобных механизмов:
Сообщения об недоступности микросервисных баз позволяют сразу обратиться к их владельцам, не дожидаясь очередного выполнения графа задач
Статус выполнения графов, со списком успешных, ошибочных и задач в работе, вместе с логами
Единый бот, позволяющий найти, запустить задачу, получить ее SQL-запрос на любом экземпляре платформы данных
Качество данных
За качество данных отвечают владельцы соответствующих задач, достигается оно за счет тестов на данных, которые сами владельцы и пишут. Тест — такая же задача, как все остальные, если он не выполняется, не выполняются и все зависимости.
Защита от факапов
Как уже упоминал, наша платформа данных открыта для всех желающих, и в процессе ее использования, при наличии CD, постоянно доставляющего задачи в прод, не исключены оплошности, когда в репозиторий приезжает некорректный YAML. На такой случай у нас есть механизм отката:
После получения новой ревизии из репозитория пробуем сформировать графы задач.
Если не получилось — откатываемся назад по ревизиям, до последней работоспособной версии. Платформа данных продолжает функционировать, автору «плохого» коммита и дата-инженерам, мейнтейнерам платформы, приходит сообщение с ошибкой, к которой привели изменения:
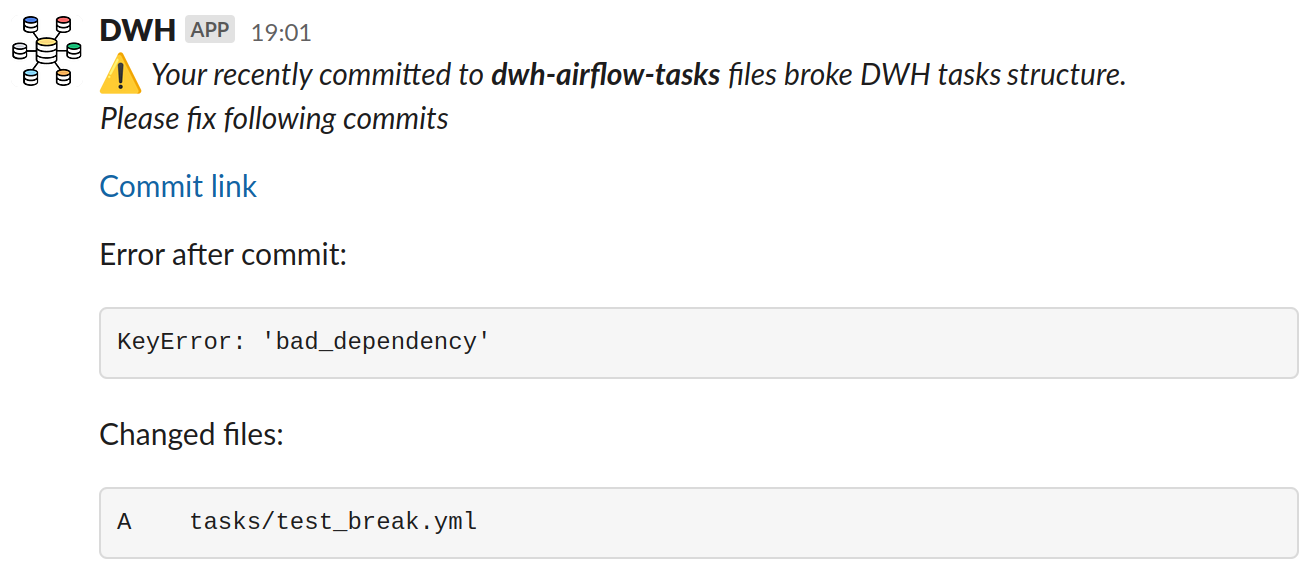
В дальнейшем, когда ошибка исправлена, платформа данных получает задачи из свежей, работающей ревизии.
Итог
После описания всех возможностей платформы данных, возникает вопрос: чем занимаются дата-инженеры, если они свободны от перемещения данных?
Поддержка платформы. Мы предоставляем большие возможности для работы с данными, но у пользователей совершенно разные уровни компетенций, и это нужно учитывать. Поэтому, мы постоянно мониторим показатели платформы данных, чтобы все работало как задумано, например:
Статистика использования отчетов, задач; неиспользуемые ресурсы удаляются после опроса возможных заинтересованных лиц
Ценовая эффективность работы с данными; в облачных сервисах легко потратить лишнее, чего хотелось бы избежать
Время готовности важных отчетов; следим, чтобы условный топ-25 отчетов был обновлен до начала рабочего дня
Доступность платформы данных в условиях множества интеграций и сервисов-зависимостей
Время выполнения задач, чтобы вовремя выявлять не оптимальные запросы
Онбординг, обучаем работе с платформой данных, рассказываем о ее возможностях и практиках для увеличения количества пользователей и распространения дата-инженерных компетенций среди сотрудников, консультации по оптимизации задач.
Производительность, стараемся улучшать саму платформу данных, чтобы задачи запускались и работали максимально быстро и эффективно.
Новые инструменты, как для эффективной дата-инженерии, так и аналитические. Недавно интегрировались с системой продуктовой аналитики Amplitude для отправки событий, обогащенных информацией из хранилища данных, об этом удивительном опыте будет отдельный рассказ.
Безопасность, выдаем доступы к ресурсам хранилища, аналитическим сущностям.
А как построены дата-инженерные процессы в вашей компании?
