«Чтение — всему голова!» Переводим электронные книги формата .EPUB с помощью Python

Разберёмся что «под капотом» формата EPUB и как перевести текст, но не переводить код в книге. Познакомимся с библиотекой Ebook Lib, а также узнаем для чего нам понадобиться библиотека Beautiful Soup.
Занимаясь программированием, в русскоязычном сегменте интернета, столкнулся с тем, что много литературы на интересующие меня темы на английском языке. Либо есть перевод, но специфика отрасли такая, что все очень быстро меняется и если заграничные авторы книг исправно выпускают обновление, то перевод зачастую отстает на 2–3 года, что достаточно критично. Прекрасно понимаю, что такие книги и документацию необходимо уметь читать на английском языке, над чем я собственно усердно работаю. С другой стороны читая монументальную литературу на языке оригинала, все еще хочется открыть перевод в соседнем окне и свериться правильно ли ты уловил мысль автора.
Кажется, в чем проблема? Закинул PDF в любом переводчике, а то и в самом браузере перевод автоматический подтягивается, только такие переводчики в основном не распознают код в тексте. Тут возникает основная проблема, которая и сподвигла меня на поиск решения и автоматизации всего процесса. А для этого есть язык программирования Python.
Чем переводить
Для перевода текста я использовал библиотеку Googletrans и написал небольшую функцию, чтобы удобнее было пользоваться.
def translation_func(text):
translator = Translator()
result = translator.translate(text, dest='ru')
return result.textТак мы подходим к предмету нашего изучения, коим является один из самых популярных форматов электронных книг — EPUB. Все дело в том, что PDF не содержит никакой информации о параметрах текста. А вот EPUB включает в себя набор XHTML- или HTML-страниц, что существенно облегчает перевод текста по нужным нам параметрам.
Чтобы посмотреть структуру электронной книги я воспользовался программой Sigil — EPUB Editor.
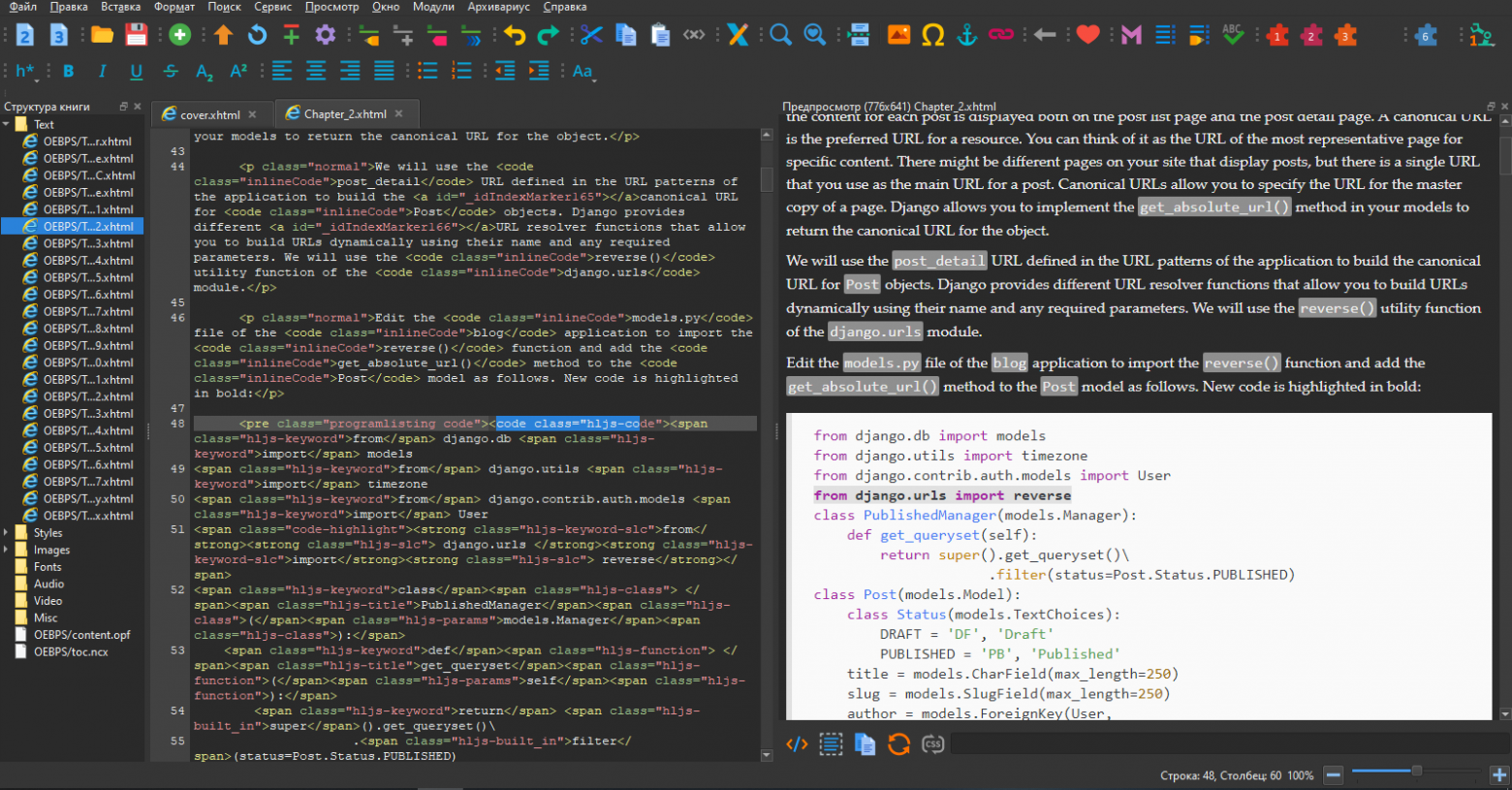
Тут можно определить на какие части делится документ, его форматы (XHTML, HTML или PDF), а главное посмотреть разметку в каких тегах у нас содержится код и по каким признакам его можно будет исключить из перевода.
Вот пример таких тегов:
tag_exeption = ['code', 'a', 'strong', 'pre', 'span', 'html', 'div', 'body', 'head']Теперь, воспользуемся библиотекой Ebook Lib, примеры ее использования можно посмотреть здесь.
С помощью функции ebooklib.epub.read_epub () читаем файл и получаем экземпляр класса ebooklib.epub.EpubBook.
from ebooklib import epub
book = epub.read_epub('book.epub')Все ресурсы в электронной книге (таблицы стилей, изображения, видео, звуки, скрипты и HTML-файлы) являются элементами. Их можно извлечь по типу с помощью функции ebooklib.epub.EpubBook.get_items_of_type ().
Вот список элементов которые можно использовать:
ITEM_UNKNOWN = 0ITEM_IMAGE = 1ITEM_STYLE = 2ITEM_SCRIPT = 3ITEM_NAVIGATION = 4ITEM_VECTOR = 5ITEM_FONT = 6ITEM_VIDEO = 7ITEM_AUDIO = 8ITEM_DOCUMENT = 9ITEM_COVER = 10
Мы воспользуемся методом book.get_items () который позволяет получать нам итератор по всем элементам книги — объекты ebooklib.epub.EpubItem. Для перевода нам нужны элементы навигации ITEM_NAVIGATION = 4 и главы книги которые содержатся в элементах ITEM_DOCUMENT = 9, чтобы их получить по типу используйте метод item.get_type ().
for item in book.get_items():
if item.get_type() == 4:
…
if item.get_type() == 9:
…Также мы можем получить имя элемента item.get_name (), уникальный идентификатор для этого элемента item.get_id () и его содержимое item.get_content ().
for item in book.get_items():
if item.get_type() == ebooklib.ITEM_DOCUMENT:
print('==================================')
print('NAME : ', item.get_name())
print('----------------------------------')
print('ID : ', item.get_id())
print('----------------------------------')
print(item.get_content())
print('==================================')...
==================================
NAME : Text/Chapter_6.xhtml
----------------------------------
ID : Chapter_6
----------------------------------
b'\r\n\r\n\r\n
==================================
... Получив содержимое главы в формате XHTML, осталось отделить мух от котлет для этого нам поможет библиотека Beautiful Soup. Получаем объект soup:
soup = BeautifulSoup(item.get_content(), features="xml")Теперь нам нужно пробежаться по всем элементам внутри этого объекта, для этого будем использовать атрибут .descendants. Он хорош тем, что в отличие от атрибутов .contents и .children которые учитывают только прямых потомков, позволяет рекурсивно перебирать все дочерние элементы прямых дочерних элементов. Что из себя представляют такие элементы можно посмотреть используя атрибуты: .name — имя тега, .attrs — атрибуты тега (class, id) в формате словаря.
for child in soup.descendants:
if child.name and child.string:
print(child.name, '->', child.attrs)***
h1 -> {'class': 'chapterNumber'}
h1 -> {'class': 'chapterTitle', 'id': '_idParaDest-65'}
p -> {'class': 'normal'}
li -> {'class': 'bulletList'}
a -> {'href': 'https://github.com/example/tree/main/Chapter02'}
***Атрибут .descendants перебирает все отдельные элементы, которые содержит soup, в том числе и строки между тегов и пустые теги. Через условие отбираем нам нужные элементы, исключая tag_exeption, голый текст (child.name) и теги которые напрямую не содержащие текст (child.string). Полученный атрибутом .string текст переводим функцией translation_func () и потом присваиваем переведенный текст нашему дочернему элементу тем же атрибутом .string .
for child in soup.descendants:
if child.name not in tag_exeption and child.name and child.string:
child.string = translation_func(child.string)Теги, которые не содержат на прямую текст отдельно прогоняем через атрибут .contents, исключая имена тегов (not content.name), пробелы и переносы ['\n', ' '].
elif not child.name in tag_exeption and child.name: #and count < 10:
for content in child.contents:
new_contents = []
if content.string and content.string not in ['\n', ' '] and not content.name:
translation_text = translation_func(content.string)
content = NavigableString(translation_text)
new_contents.append(content)
new_contents.append(" ")
child.clear()
child.extend(new_contents)Beautiful Soup использует для хранения фрагментов текста класс NavigableString, переведенный текстделаем объектами этого класса, очищаем содержимое нашего потомка child.clear (), добавляем эти объекты в содержимое потомка используя child.extend (new_contents).
Осталось элементу book присвоить новый контент в виде нашего объекта soup, используя метод .set_content (), не забывая перекодировать.
item.set_content(soup.encode())Дополнительно, мне понравилось использовать просмотр контента элементов book в браузере с помощью метода .open_in_browser (contents) библиотеки lxml, для этого нужно предварительно перекодировать наш контент воспользовавшись утилитой из библиотеки Ebook Lib — utils.parse_string (item.get_content ()).
from ebooklib import epub, utils
…
contents = utils.parse_string(item.get_content())
html.open_in_browser(contents)И последнее, что нам нужно — это сохранить переведенную книгу.
epub.write_epub('new_book.epub', book, {})Весь код выглядит вот так:
from googletrans import Translator
from ebooklib import epub, utils
from bs4 import BeautifulSoup, NavigableString
import lxml.html as html
def open_epub():
tag_exeption = ["code", 'a', 'strong', 'pre', 'span', 'html',
'div', 'body', "head"]
book = epub.read_epub('Django 4 By Example 2022.epub')
for item in book.get_items():
if item.get_id() == "Chapter_7":
print('NAME : ', item.get_name())
print('----------------------------------')
print('ID : ', item.get_id())
print('----------------------------------')
print('ITEM : ', item.get_type())
soup = BeautifulSoup(item.get_content(), features="xml")
for child in soup.descendants:
if child.name not in tag_exeption and child.name and child.string:
tag_text_before = child.string
translation_text = translation_func(tag_text_before)
child.string = translation_text
elif not child.name in tag_exeption and child.name:
new_contents = []
class_attr = child.attrs.get('class')
for content in child.contents:
if content.string and content.string not in ['\n', ' '] and not content.name:
content = NavigableString(translation_func(content.string))
new_contents.append(content)
new_contents.append(" ")
child.clear()
child.extend(new_contents)
item.set_content(soup.encode())
contents = utils.parse_string(item.get_content())
html.open_in_browser(contents)
print('==================================')
epub.write_epub('new_book.epub', book, {})
def translation_func(text):
translator = Translator()
result = translator.translate(text, dest='ru')
return result.text
def main():
open_epub()
if __name__ == "__main__":
main()В дополнение еще нужно отметить про файлы CSS, в книги их можно прочитать в файлах типа ITEM_STYLE = 2 или посмотреть в программе Sigil — EPUB Editor в заголовках элементов книги,
а находятся они в папке Styles.
Example book
После перезаписи элементов книги ссылки на CSS в заголовке пропадают их можно вернуть с помощью программы Sigil — EPUB Editor, нужно выбрать все элементы книги в папке text и правой кнопкой в контекстном меню выбрать «Связать с таблицей стилей…».
Это все! Наша книга готова!
В заключении хочется сказать, что автоматизировать процессы — интересно, повышает общую эрудицию, учит работать с разными библиотеками, что называется залезть под «под капот», да и просто разнообразить рутину.
