CRDT: Conflict-free Replicated Data Types
Как считать хиты страницы google.com? А как хранить счётчик лайков очень популярных пользователей? В этой статье предлагается рассмотреть решение этих задач с помощью CRDT (Conflict-free Replicated Data Types, что по-русски переводится примерно как Бесконфликтные реплицированные типы данных), а в более общем случае — задачи синхронизации реплик в распределённой системе с несколькими ведущими узлами.
Мы уже давно привыкли пользоваться такими приложениями, как календарь или сервис заметок типа Evernote. Их объединяет то, что они позволяют работать оффлайн, с нескольких устройств и нескольким людям одновременно (над одними и теми же данными). Задача, стоящая перед разработчиками каждого такого приложения — как обеспечить максимально «гладкую» синхронизацию данных, изменённых одновременно на нескольких устройствах. В идеале участие пользователя не должно требоваться вообще для разрешения конфликтов слияния.
В предыдущей статье уже был рассмотрен подход для решения таких задач — Operational Transformation, здесь же будет описан очень похожий способ, обладающий как преимуществами, так и недостатками (например, пока ещё не придумали CRDT для JSON)
В последнее время было написано много работ и сделано много исследований в области eventual consistency. По моему мнению, сейчас идёт сильный тренд на смещение от strong consistency к различным вариантам согласованности, к исследованиям какую согласованность в каких ситуациях/системах выгоднее применять, к переосмыслению существующих определений. Это приводит к некоторой путанице, например, когда авторы одних работ, рассуждая о согласованности, имеют в виду eventual consistency с некоторым дополнительным свойством, а другие авторы используют определённую терминологию для этого.
Вопрос, поднятый авторами одной из статей, критикует текущее определение eventual consistency: согласно ему, если ваша система всё время на все запросы выдаёт ответ »42», то всё ОК, она eventually consistent.
Не нарушая корректности данной статьи, я, вслед за авторами оригинальных статей, буду использовать следующую терминологию (пожалуйста заметьте, это не строгие определения, это различия):
- Strong consistency (SC): все операции записи строго упорядочены, запрос на чтение на любой реплике возвращает одинаковый, последний записанный результат. Необходим консенсус в реальном времени для разрешения конфликтов (с вытекающими последствиями), выдерживает падение до n/2 — 1 нод.
- Eventual consistency (EC): обновляем данные локально, рассылаем обновление дальше. Чтение на разных репликах может вернуть устаревшие данные. В случае конфликтов либо откатываем, либо как-то решаем, что делать. Т.о. консенсус всё ещё необходим, но уже не в реальном времени.
- Strong eventual consistency (SEC): EC + для разрешения конфликтов у реплик есть заранее определённый алгоритм. Т.о. консенсус не нужен, выдерживает падение до n — 1 нод.
Заметим, что SEC (как бы) решает проблему CAP теоремы: все три свойства выполняются.
Итак, мы готовы пожертвовать SC и хотим иметь некий набор базовых типов данных для нашей потенциально нестабильной распределённой системы, который будет автоматически разрешать конфликты записи за нас (не требуется взаимодействие с пользователем или запрос в некий арбитр)
Несомненно, существует несколько алгоритмов решения таких задач. CRDT предлагает довольно элегантный и простой способ.
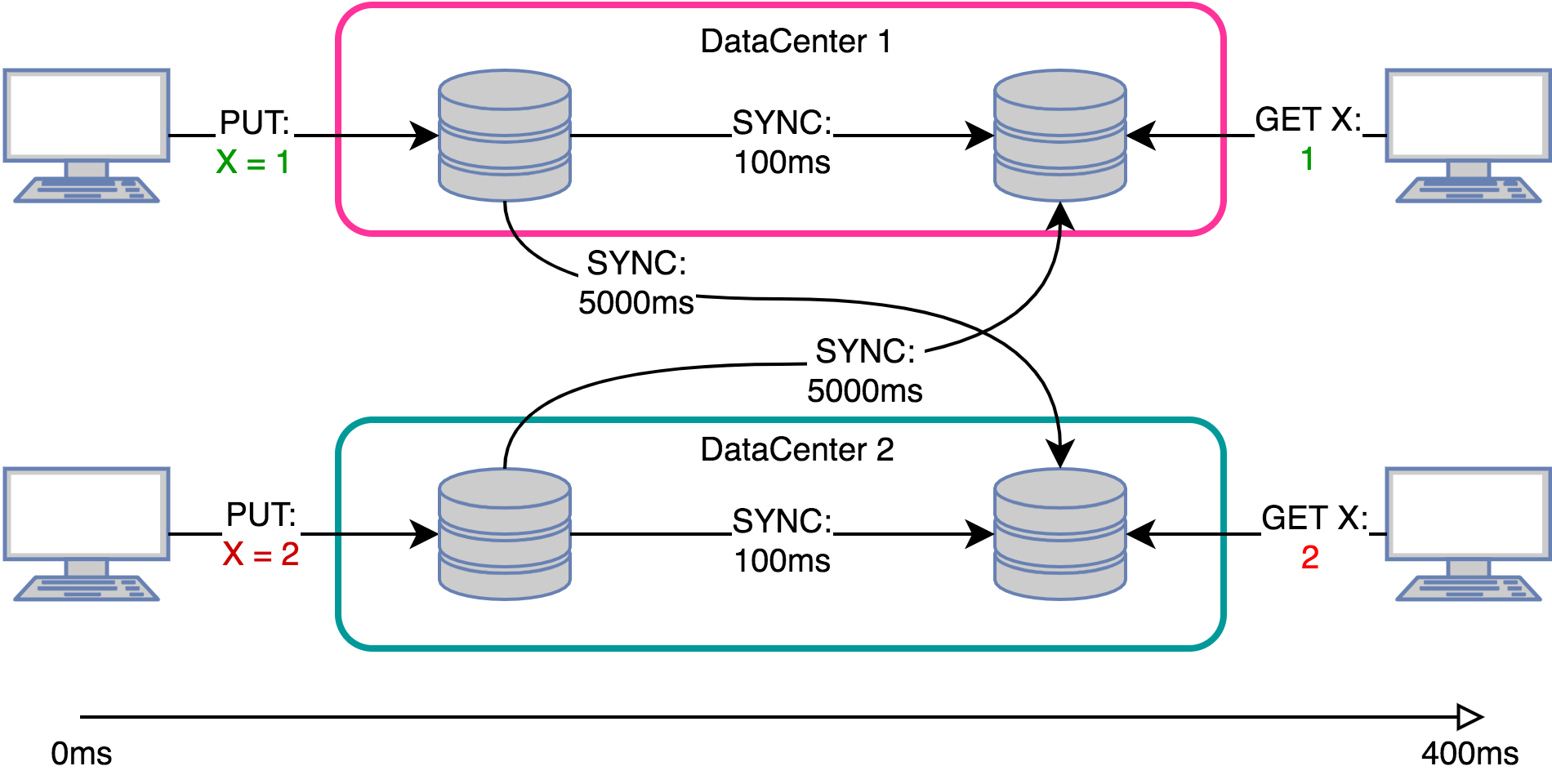
Подсчёт хитов google.com:
google.com обрабатывает примерно 150000 запросов в секунду со всех точек планеты. Очевидно, счётчик нужно обновлять асинхронно. Очереди решают проблему частично — например, если мы предоставляем внешний API для получения этого значения, то нам придётся делать репликацию, чтобы не положить хранилище запросами на чтение. А если уже есть репликация, может можно и без глобальных очередей?
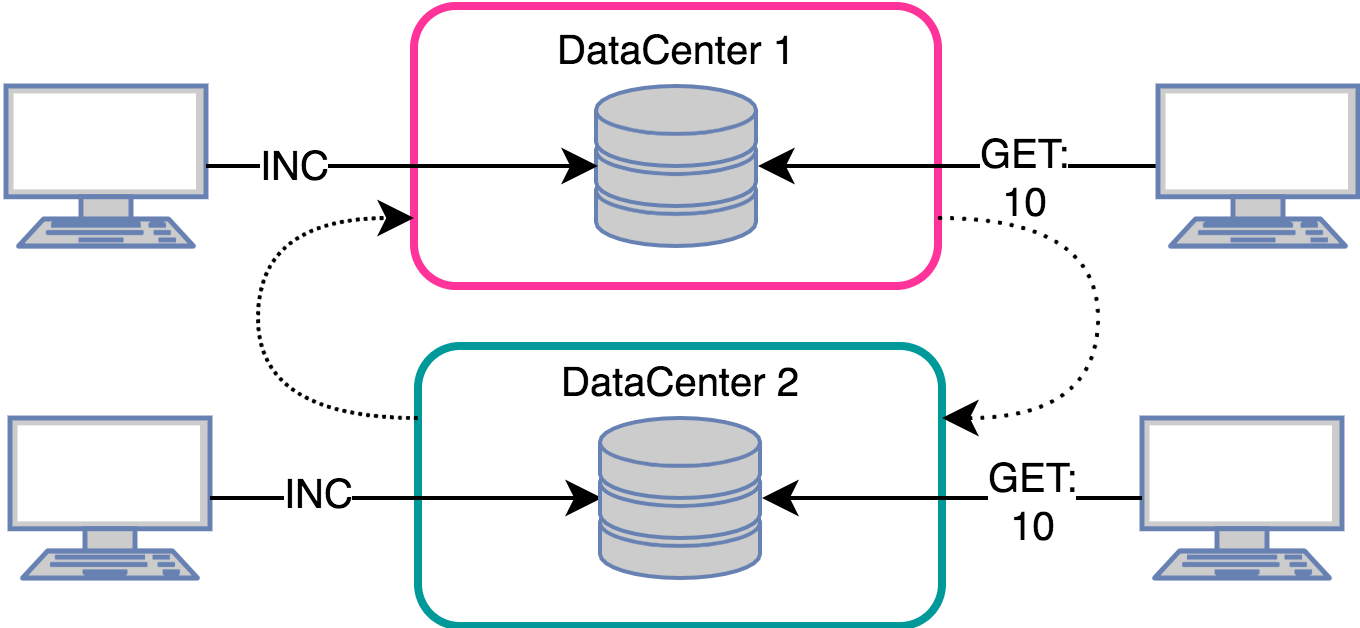
Подсчёт лайков пользователя:
Задача очень похожа на предыдущую, только теперь нужно считать уникальные хиты.
Для более полного понимания статьи необходимо знать о следующих терминах:
- Идемпотентность
Говорит о том, что применение операции несколько раз не изменяет результат.
Примеры — Операция GET или сложение с нулём:
- Коммутативность

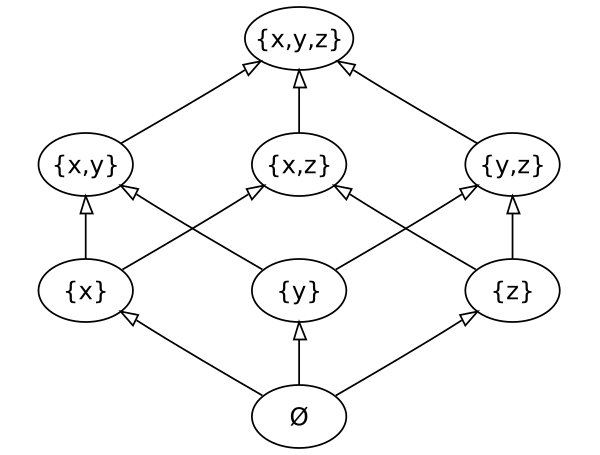
- Частичный порядок
Рефлексивность + Транзитивность + Антисимметричность - Полурешётка
Частично упорядоченное множество с точной верхней (нижней) гранью - Вектор версий
Вектор размерности равной количеству нод, и каждая нода при наступлении какого-то определённого события инкрементирует своё значение в векторе. При синхронизации данные передаются с этим вектором и это вводит отношение порядка, что позволяет определить у какой реплики старые/новые данные.
State-based (синхронизация состоянием):
Также называется пассивной синхронизацией, образует Convergent Replicated Data Type — CvRDT.
Используется в таких файловых системах, как NFS, AFS, Coda и в KV-хранилищах Riak, Dynamo
В этом случае реплики обмениваются непосредственно состояниями, принимающая реплика сливает (merge) полученное состояние со своим текущим состоянием.

Для выполнения сходимости реплик с использованием данной синхронизации необходимо, чтобы:
- Данные образовывали полурешётку
- Функция слияния производила точную верхнюю грань
- Реплики образовывали связный граф
Пример:
- Множество данных: натуральные числа

- Минимальный элемент:


Такие требования дают нам коммутативную и идемпотентную функцию слияния, которая монотонно растёт на заданном множестве данных:
Это гарантирует, что реплики рано или поздно сойдутся и позволяет не беспокоится о протоколе передачи данных — мы можем терять сообщения с новым состоянием, отправлять их несколько раз, и даже отправлять в любом порядке.
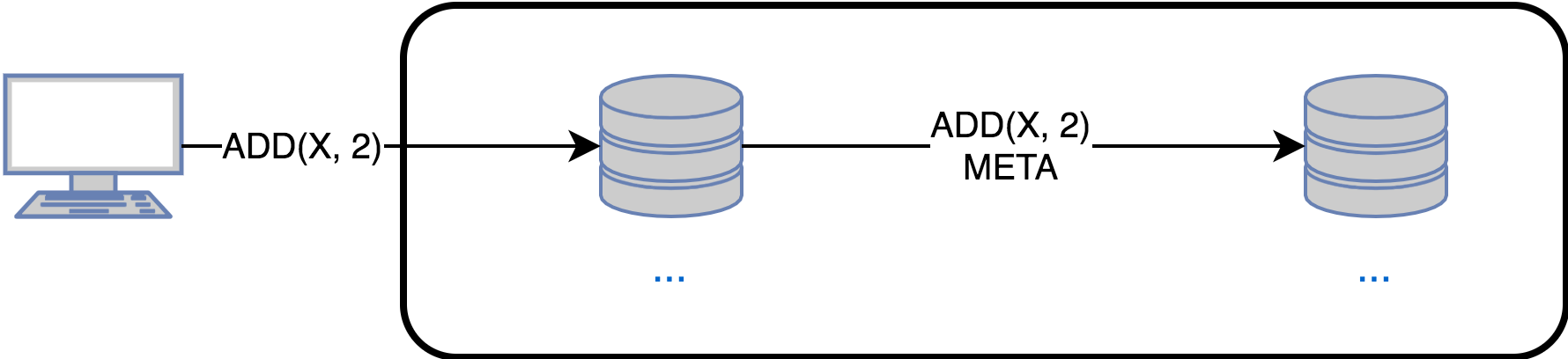
Operation-based (синхронизация операциями):
Также называется активной синхронизацией, образует Commutative Replicated Data Type — CmRDT.
Используется в таких кооперативных системах, как Bayou, Rover, IceCube, Telex.
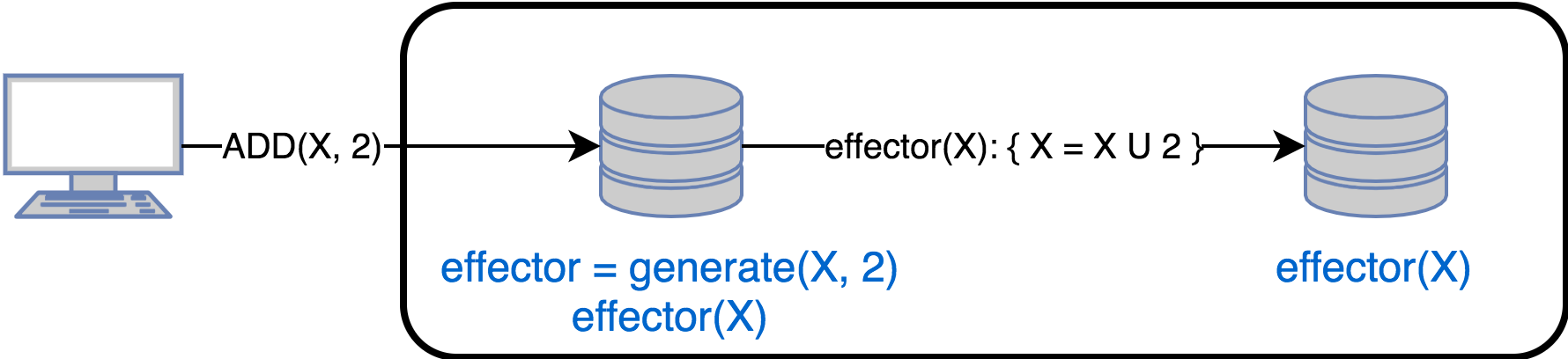
В этом случае реплики обмениваются операциями обновления состояния. При обновлении данных исходная реплика:
- Вызывает метод generate () который возвращает метод effector () для выполнения на остальных репликах. Другими словами — effector () это замыкание для изменения состояния остальных реплик
- Применение effector к локальному состоянию
- Рассылает effector на все остальные реплики
Для выполнения сходимости реплик необходимо выполнение следующих условий:
- Надёжный протокол доставки
- Если effector доставляется на все реплики в соответствии с введённым порядком (для данного типа), то одновременные effector — коммутативны, или
- Если effector доставляется на все реплики без учёта порядка, то все effector — коммутативны.
- В случае, если effector может быть доставлен несколько раз, то он должен быть идемпотентным
- Некоторые реализации используют очереди (Kafka) как часть протокола доставки.
Delta-based:
Рассматривая state/op based легко заметить, что если обновление изменяет только часть состояния, то нет смысла пересылать состояние целиком, а также если большое количество изменений затрагивает одно состояние (например, счётчик), то можно выслать одно, агрегированное изменение, а не все операции изменения.
Дельта-синхронизация объединяет в себе оба подхода и рассылает delta-mutators, которые обновляют состояние согласно последней даты синхронизации. При первоначальной синхронизации необходимо выслать состояние полностью, а некоторые реализации в таких случаях уже учитывают состояние остальных реплик при построении delta-mutators.
Следующий способ оптимизации — компрессия op-based лога, если разрешены задержки.

Pure operation-based (чистая синхронизация операциями):
В op-based синхронизации присутствует задержка на создание effector. В некоторых системах это может быть неприемлемо, тогда приходится рассылать оригинальное изменение ценой усложнения протокола и дополнительного количества метаданных.
Стандартные подходы использования:
Связь между Op-based и State-based:
Два подхода можно эмулировать друг через друга, так что в дальнейшем мы будем рассматривать CRDT без привязки к какой-либо конкретной модели синхронизации.
6.1 Счётчик (Counter)
Целое число с поддержкой двух операций: inc и dec. В качестве примера рассмотрим возможные реализации для op-based и state-based синхронизаций:
Op-based счётчик:
Достаточно очевидно, просто рассылаем обновления. Пример для inc:
function generator() { return function (counter) { counter += 1 } }
State-based счётчик:
Реализация уже не настолько очевидна, так как непонятно, как должна выглядеть функция слияния.
Рассмотрим следующие варианты:
Монотонно увеличивающийся счётчик (Increment only counter, G-Counter):
Данные будут храниться как вектор размерности равной количеству нод (вектор версий) и каждая реплика будет увеличивать значение в позиции со своим id.
Функция слияния будет брать максимум в соответствующих позициях, а итоговое значение — сумма всех элементов вектора
![$\begin{align} inc() &: V[id()] = V[id()] + 1\\ value() &: \sum_{i=0}^{n} V[i]\\ merge(C_1, C_2) &: i \in [1..n]\ Result[i] = max(C_1.V[i], C_2.V[i]) \end{align}$](https://habrastorage.org/getpro/habr/formulas/e29/d58/0d2/e29d580d2f50417881163d485d6f208a.svg)
Также можно использовать G-Set (см ниже)
Применение:
- Подсчёт количества кликов/хитов (sic!)
Счётчик с поддержкой декремента (PN-counter)
Заводим два G-counter — один для операций инкремента, второй — для декремента
Применение:
- Количество залогиненных пользователей в p2p сети, типа Skype
Неотрицательный счётчик (Non-negative counter)
Простой реализации пока не существует. Предлагайте в комментариях ваши идеи, обсудим.
6.2 Регистр (Register)
Ячейка памяти с двумя операциями — assign (запись) и value (чтение).
Проблема — assign не коммутативна. Существует два подхода для решения этой проблемы:
Регистр Last-Write-Wins (LWW-Register):
Вводим полный порядок через генерацию уникальных id на каждую операцию (timestamp, например).
Пример синхронизирования — обмен парами (значение, id):

Применение:
- Столбцы в cassandra
- NFS — файл целиком или часть
Регистр с несколькими значениями (Multi-Value Register, MV-Register):
Подход похож на G-счётчик — храним набор (значение, вектор версий). Значение регистра — все значения, при слиянии — LWW по отдельности на каждое значение в векторе.
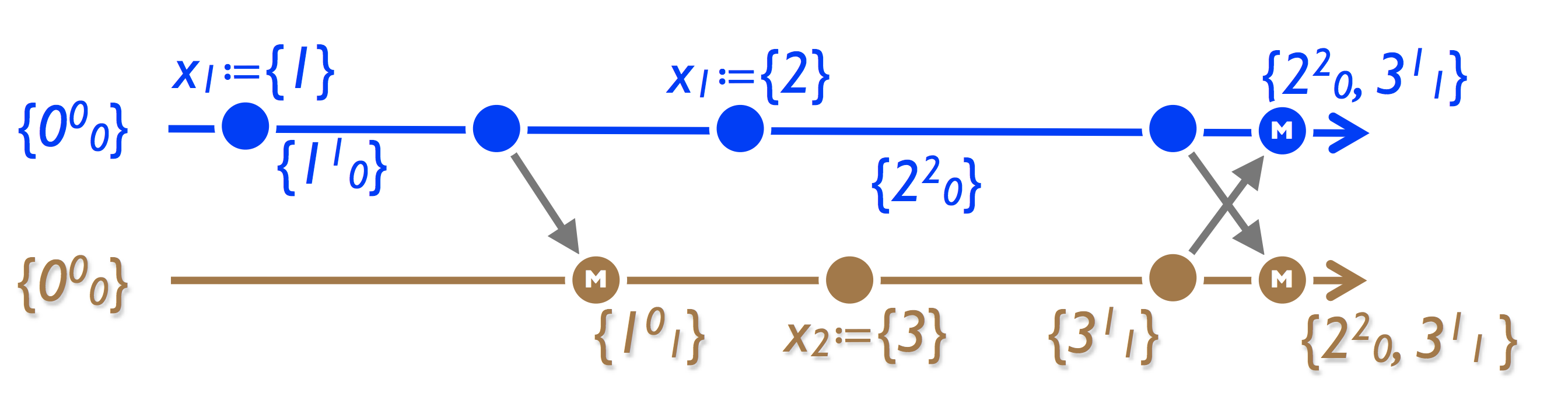
Применение:
- Корзина в амазоне. С этим связан известный баг, когда после удаления вещи из корзины она там снова появляется. Причина — несмотря на то, что регистр хранит набор значений — множеством он не является (см ниже картинку). Амазон, кстати, даже не считает это багом — на самом деле это повышает продажи.
- Riak. В более общем случае мы перекладываем проблему выбора актуального (заметьте — конфликта нет!) значения на приложение.
Объяснение бага в амазоне:

6.3 Множество
Множество является базовым типом для построения контейнеров, отображений и графов и поддерживает операции — add и rmv, которые не коммутативны.
Рассмотрим наивную реализацию op-based множества, в которой add и rmv выполняются по мере поступления (На 1 и 2 реплику одновременно приходит add, затем rmv на 1)

Как видно, в конечном итоге реплики разошлись. Рассмотрим различные варианты построения бесконфликтных множеств:
Растущее множество (Grow-Only Set, G-Set):
Самое простое решение — запретить удалять элементы. Остаётся только операция add, которая коммутативна. Функция слияния — объединение множеств.
Двухфазное множество (2P-Set):
Разрешаем удалять, но после удаления добавить ещё раз нельзя. Для реализации заводим отдельное множество удалённых элементов G-set (такое множество называется tombstone set)
Пример для state-based:

LWW-element Set:
Следующий способ реализации бесконфликтного множества состоит во введении полного порядка, один из вариантов — генерация уникальных timestamp для каждого элемента.
Заводим два множества — add-set и remove-set, при вызове add () добавляем (element, unique_id ()), при проверке есть ли элемент в множестве — смотрим где timestamp больше — в remove-set или в add-set

PN-Set:
Вариация с упорядочиванием множества — на каждый элемент заводим счётчик, при добавлении — увеличиваем, при удалении — уменьшаем. Элемент находится в множестве, если его счётчик положителен.

Заметьте интересный эффект — в третьей реплике добавление элемента не приводит к его появлению.
Observe-Remove Set, OR-Set, Add-Win Set:
В данном типе add имеет приоритет над remove. Пример реализации: каждому новому добавленному элементу присваиваем уникальный тэг (относительно элемента, а не всего множества). Rmv удаляет элемент из множества и рассылает все увиденные пары (элемент, тэг) на удаление репликам.

Remove-win Set:
Аналогично предыдущему, но при одновременном add/rmv выигрывает rmv.
6.4 Граф (Graph)
Данный тип строится на основе множества. Проблема состоит в следующем: если есть одновременные операции addEdge (u, v) и removeVertex (u) — как поступить? Возможны такие варианты:
- Приоритет у removeVertex, все рёбра, инцидентные данной вершине, удаляются
- Приоритет у addEdge, удалённые вершины восстанавливаются
- Откладываем выполнение removeVertex до тех пор, пока все одновременные addEdge не будут выполнены.
Самый простой вариант — первый, для его реализации (2P2P-Graph) достаточно завести два 2P-Set, один для вершин, второй для ребёр
6.5 Отображение (Map)
Отображение литералов (Map of literals):
Две проблемы, требующие решения:
- Что делать с одновременными операциями put? По аналогии со счётчиками можно выбрать или LWW или MV семантику
- Что делать с одновременными put/rmv? По аналогии со множествами, можно либо put-wins, либо rmv-wins, либо last-put-wins семантику.
Отображение CRDT (Map of CRDTs):
Более интересный случай, т.к. позволяет строить вложенные отображения. Мы не рассматриваем случаи изменения вложенных типов — это должно решаться самим вложенным CRDT.
Remove-as-recursive-reset map
Операция remove «сбрасывает» значение типа в некое стартовое состояние. Например, для счётчика — это нулевое значение.
Рассмотрим пример — общий список покупок. Один из пользователей добавляет муки, а второй делает чекаут (это приводит к вызову операции удаления на всех элементах). В итоге в списке остаётся одна единица муки, что выглядит логичным.

Remove-wins map
Операция rmv имеет приоритет.
Пример: в онлайн-игре у игрока Alice есть 10 монет и молоток. Далее одновременно происходит два события: на реплике А она добыла гвоздь, а на реплике В её персонаж удалён с удалением всех предметов:

Заметим, что при использовании remove-as-recursive в итоге остался бы гвоздь, что не является правильным состоянием, когда персонаж удалён.
Update-wins map
Обновления имеют приоритет, а точнее — отменяют предыдущие операции удаления одновременных rmv.
Пример: в онлайн игре персонаж Alice на реплике В удаляется из-за неактивности, но в это же время на реплике А активность происходит. Очевидно, операция удаления должна быть отменена.

Есть один интересный эффект при работе с такой реализацией — предположим, что у нас две реплики, А и В, и они хранят множество по какому-то ключу k. Тогда, если А удаляет значение ключа k, а В удаляет все элементы множества, то в итоге в репликах останется пустое множество по ключу k.
Заметим, что наивная реализация будет работать некорректно — нельзя просто отменить все предыдущие операции удаления. В следующем примере при таком подходе итоговое состояние было бы как изначальное, что неверно:

Список (List)
Проблема с этим типом состоит в том, что индексы элементов на различных репликах будут различными после локальный операций вставок/удаления. Для решения этой проблемы применяется Operational Transformation подход — при применении полученного изменения должен учитываться индекс элемента в оригинальной реплике.
В качестве примера рассмотрим CRDT в Riak:
- Counter: PN-Counter
- Set: OR-Set
- Map: Update-wins Map of CRDTs
- (Boolean) Flag: OR-Set где максимум 1 элемент
- Register: пары (value, timestamp)
Раздел в вики содержит хорошие примеры
