Compile time обфускация используя NAND/NOR
Введение.
Все, кто хорошо знаком с современным С++ слышал, что начиная с С++11 в стандарт был введен спецификатор constexpr, при помощи которого можно проводить лимитированные compile-time вычисления. В последующие стандарты были добавлены if constexpr и constexpr lambdas которые в некоторой степени снимают ограничения и помогают писать код с compile time вычислениями. Сегодня мы поговорим об случайной кодогенерации в compile time.
Выбираем базу для compile-time ГПСЧ
Для того чтобы выбирать конкретный path для кода в compile time, нужен constexpr ГПСЧ c хорошими выходными данными, для этого я выбрал генератор xorshift, кстати xorshift проходит эмпирические тесты BigCrush (TestU01).
#include
/* This is xoshiro256++ 1.0, one of our all-purpose, rock-solid generators.
It has excellent (sub-ns) speed, a state (256 bits) that is large
enough for any parallel application, and it passes all tests we are
aware of.
For generating just floating-point numbers, xoshiro256+ is even faster.
The state must be seeded so that it is not everywhere zero. If you have
a 64-bit seed, we suggest to seed a splitmix64 generator and use its
output to fill s. */
static inline uint64_t rotl(const uint64_t x, int k) {
return (x << k) | (x >> (64 - k));
}
static uint64_t s[4];
uint64_t next(void) {
const uint64_t result = rotl(s[0] + s[3], 23) + s[0];
const uint64_t t = s[1] << 17;
s[2] ^= s[0];
s[3] ^= s[1];
s[1] ^= s[2];
s[0] ^= s[3];
s[2] ^= t;
s[3] = rotl(s[3], 45);
return result;
}
/* This is the jump function for the generator. It is equivalent
to 2^128 calls to next(); it can be used to generate 2^128
non-overlapping subsequences for parallel computations. */
void jump(void) {
static const uint64_t JUMP[] = { 0x180ec6d33cfd0aba, 0xd5a61266f0c9392c, 0xa9582618e03fc9aa, 0x39abdc4529b1661c };
uint64_t s0 = 0;
uint64_t s1 = 0;
uint64_t s2 = 0;
uint64_t s3 = 0;
for(int i = 0; i < sizeof JUMP / sizeof *JUMP; i++)
for(int b = 0; b < 64; b++) {
if (JUMP[i] & UINT64_C(1) << b) {
s0 ^= s[0];
s1 ^= s[1];
s2 ^= s[2];
s3 ^= s[3];
}
next();
}
s[0] = s0;
s[1] = s1;
s[2] = s2;
s[3] = s3;
}
/* This is the long-jump function for the generator. It is equivalent to
2^192 calls to next(); it can be used to generate 2^64 starting points,
from each of which jump() will generate 2^64 non-overlapping
subsequences for parallel distributed computations. */
void long_jump(void) {
static const uint64_t LONG_JUMP[] = { 0x76e15d3efefdcbbf, 0xc5004e441c522fb3, 0x77710069854ee241, 0x39109bb02acbe635 };
uint64_t s0 = 0;
uint64_t s1 = 0;
uint64_t s2 = 0;
uint64_t s3 = 0;
for(int i = 0; i < sizeof LONG_JUMP / sizeof *LONG_JUMP; i++)
for(int b = 0; b < 64; b++) {
if (LONG_JUMP[i] & UINT64_C(1) << b) {
s0 ^= s[0];
s1 ^= s[1];
s2 ^= s[2];
s3 ^= s[3];
}
next();
}
s[0] = s0;
s[1] = s1;
s[2] = s2;
s[3] = s3;
}
Из этого нам понадобятся только функции rotl и next, чтобы не делать вычисления слишком долгими. Передаю пламенный привет разработчикам компилятора MSVC, ввиду багов компилятора которые обнаружились в процессе написания, об этом будет сказано ниже.
Как видно из кода выше, нам нужно четыре 64 битных статических переменных для хранения состояния, для того чтобы данный код работал в compile time, нужно от них избавиться передавая случайное состояние в качестве параметров. Организовать это можно используя constexpr hash fnv1 и макрос __COUNTER__ , перепишем код в соответствии с этим и получим следующее:
#include
#define STRING(s) #s
// an enumeration can also be used here
template
constexpr T ensure_constexpr() {
return value;
}
#define CONSTEXPR(x) ensure_constexpr()
constexpr uint64_t fnv1impl(uint64_t h, const char* s) {
return (*s == 0)
? h
: fnv1impl((h * 1099511628211ull) ^ static_cast(*s),
s + 1);
}
constexpr uint64_t fnv1(const char* s) {
return fnv1impl(14695981039346656037ull, s);
}
template
constexpr uint64_t get_seed(const uint64_t x,
const uint64_t y = CONSTEXPR(fnv1(STRING(n)))) {
return x ^ y * n;
}
#define SEED CONSTEXPR(get_seed<__COUNTER__ + 1>(fnv1(__TIME__)))
//! Rotate left by
constexpr uint64_t rotl(uint64_t x, int k) {
return (x << k) | (x >> (64 - k));
}
//! XorShift 256 compile time random implementation
template
constexpr uint64_t xorshift256_next() {
uint64_t s[4] = {a, b, c, d};
const uint64_t t = s[1] << 17;
s[2] ^= s[0];
s[3] ^= s[1];
s[1] ^= s[2];
s[0] ^= s[3];
s[2] ^= t;
s[3] = rotl(s[3], 45);
return rotl(s[0] + s[3], 23) + s[0];
}
#define RND \
xorshift256_next< \
CONSTEXPR(SEED + __COUNTER__), CONSTEXPR(SEED + __COUNTER__), \
CONSTEXPR(SEED + __COUNTER__), CONSTEXPR(SEED + __COUNTER__)>()
Под капотом
Теперь нам нужно убедиться, что компиляторы действительно «сворачивают» код в compile time.
Собираем код ниже используя GCC 9.2.1 в дебаге g++ _.cpp -S -masm=intel
#include "compile_random.h"
#include
int main() {
std::cout << RND << std::endl;
std::cout << RND << std::endl;
}
.file "_.cpp"
.intel_syntax noprefix
.text
.section .text._Z4rotlmi,"axG",@progbits,_Z4rotlmi,comdat
.weak _Z4rotlmi
.type _Z4rotlmi, @function
_Z4rotlmi:
.LFB4:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov QWORD PTR [rbp-8], rdi
mov DWORD PTR [rbp-12], esi
mov eax, DWORD PTR [rbp-12]
mov rdx, QWORD PTR [rbp-8]
mov ecx, eax
rol rdx, cl
mov rax, rdx
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE4:
.size _Z4rotlmi, .-_Z4rotlmi
.section .rodata
.type _ZStL19piecewise_construct, @object
.size _ZStL19piecewise_construct, 1
_ZStL19piecewise_construct:
.zero 1
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.text
.globl main
.type main, @function
main:
.LFB1528:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
call _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
mov rsi, rax
mov edi, OFFSET FLAT:_ZSt4cout
call _ZNSolsEm
mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov rdi, rax
call _ZNSolsEPFRSoS_E
call _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
mov rsi, rax
mov edi, OFFSET FLAT:_ZSt4cout
call _ZNSolsEm
mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov rdi, rax
call _ZNSolsEPFRSoS_E
mov eax, 0
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1528:
.size main, .-main
.section .text._Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv,"axG",@progbits,_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv,comdat
.weak _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
.type _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv, @function
_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv:
.LFB1790:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 48
movabs rax, 5485350875583313748
mov QWORD PTR [rbp-48], rax
movabs rax, -1344488152466593804
mov QWORD PTR [rbp-40], rax
movabs rax, -8102276183547423076
mov QWORD PTR [rbp-32], rax
movabs rax, 2938160962983216444
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-40]
sal rax, 17
mov QWORD PTR [rbp-8], rax
mov rdx, QWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-48]
xor rax, rdx
mov QWORD PTR [rbp-32], rax
mov rdx, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rbp-40]
xor rax, rdx
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-40]
mov rax, QWORD PTR [rbp-32]
xor rax, rdx
mov QWORD PTR [rbp-40], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
xor rax, rdx
mov QWORD PTR [rbp-48], rax
mov rax, QWORD PTR [rbp-32]
xor rax, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-32], rax
mov rax, QWORD PTR [rbp-24]
mov esi, 45
mov rdi, rax
call _Z4rotlmi
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov esi, 23
mov rdi, rax
call _Z4rotlmi
mov rdx, QWORD PTR [rbp-48]
add rax, rdx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1790:
.size _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv, .-_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
.section .text._Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv,"axG",@progbits,_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv,comdat
.weak _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
.type _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv, @function
_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv:
.LFB1794:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 48
movabs rax, -3891678030706526748
mov QWORD PTR [rbp-48], rax
movabs rax, 7653162274090525828
mov QWORD PTR [rbp-40], rax
movabs rax, 823244081203417900
mov QWORD PTR [rbp-32], rax
movabs rax, -6510995906087812148
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-40]
sal rax, 17
mov QWORD PTR [rbp-8], rax
mov rdx, QWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-48]
xor rax, rdx
mov QWORD PTR [rbp-32], rax
mov rdx, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rbp-40]
xor rax, rdx
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-40]
mov rax, QWORD PTR [rbp-32]
xor rax, rdx
mov QWORD PTR [rbp-40], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
xor rax, rdx
mov QWORD PTR [rbp-48], rax
mov rax, QWORD PTR [rbp-32]
xor rax, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-32], rax
mov rax, QWORD PTR [rbp-24]
mov esi, 45
mov rdi, rax
call _Z4rotlmi
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov esi, 23
mov rdi, rax
call _Z4rotlmi
mov rdx, QWORD PTR [rbp-48]
add rax, rdx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1794:
.size _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv, .-_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
.text
.type _Z41__static_initialization_and_destruction_0ii, @function
_Z41__static_initialization_and_destruction_0ii:
.LFB2042:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 16
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
cmp DWORD PTR [rbp-4], 1
jne .L11
cmp DWORD PTR [rbp-8], 65535
jne .L11
mov edi, OFFSET FLAT:_ZStL8__ioinit
call _ZNSt8ios_base4InitC1Ev
mov edx, OFFSET FLAT:__dso_handle
mov esi, OFFSET FLAT:_ZStL8__ioinit
mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev
call __cxa_atexit
.L11:
nop
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2042:
.size _Z41__static_initialization_and_destruction_0ii, .-_Z41__static_initialization_and_destruction_0ii
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB2043:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov esi, 65535
mov edi, 1
call _Z41__static_initialization_and_destruction_0ii
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2043:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.hidden __dso_handle
.ident "GCC: (GNU) 9.2.1 20190827 (Red Hat 9.2.1-1)"
.section .note.GNU-stack,"",@progbits
Как видно из ассемблерного кода выше, функции rotl и xorshift256_next присутствуют в коде, но на самом деле это ожидаемое поведение, так как оптимизации были отключены.
Проверим с включенными оптимизациями g++ _.cpp -S -masm=intel -O2
.file "_.cpp"
.intel_syntax noprefix
.text
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB1550:
.cfi_startproc
sub rsp, 8
.cfi_def_cfa_offset 16
mov edi, OFFSET FLAT:_ZSt4cout
movabs rsi, 6340608927850167019
call _ZNSo9_M_insertImEERSoT_
mov rdi, rax
call _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov edi, OFFSET FLAT:_ZSt4cout
movabs rsi, -1433878323375531419
call _ZNSo9_M_insertImEERSoT_
mov rdi, rax
call _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
xor eax, eax
add rsp, 8
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE1550:
.size main, .-main
.p2align 4
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB2064:
.cfi_startproc
sub rsp, 8
.cfi_def_cfa_offset 16
mov edi, OFFSET FLAT:_ZStL8__ioinit
call _ZNSt8ios_base4InitC1Ev
mov edx, OFFSET FLAT:__dso_handle
mov esi, OFFSET FLAT:_ZStL8__ioinit
mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev
add rsp, 8
.cfi_def_cfa_offset 8
jmp __cxa_atexit
.cfi_endproc
.LFE2064:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.hidden __dso_handle
.ident "GCC: (GNU) 9.2.1 20190827 (Red Hat 9.2.1-1)"
.section .note.GNU-stack,"",@progbits
Ура! получаем то, что ожидали, компилятор развернул 2 вызова макроса RND в 2 инструкции mov. Поведение компиляторов clang и MSVC в RELEASE MODE аналогичное. Можно переходить к compile time кодогенерации.
Для последующего понимания, нужно ознакомиться с универсальными логическими элементами
NOR (Стрелка пирса) NAND (Штрих Шеффера) при помощи которых можно построить абсолютно всю логику. Я не буду прилагать весь код для реализации операций & | ^ ++ — , разберём только один пример на основе случайной выборки шаблонной функции NAND, в остальных эмулируемых инструкциях принцип выборки такой же.
Давайте представим, что у нас есть 5 template имплементаций NAND выборку которых мы хотим рандомизировать.
//! (Not a) Or (Not b)
template
FORCEINLINE T Nand_1(volatile T a, volatile T b) {
return Or(Not(a), Not(b));
}
//! Not(a And b)
template
FORCEINLINE T Nand_2(volatile T a, volatile T b) {
return Not(And(a, b));
}
//! Not ((Not a) Nor (Not b))
template
FORCEINLINE T Nand_3(volatile T a, volatile T b) {
return Not(Nor(Not(a), Not(b)));
}
//! (Not a) Or (Not b)
template
FORCEINLINE T Nand_4(volatile T a, volatile T b) {
return Or(Not(a), Not(b));
}
//! ((Not a) And b) Xor (Not b)
template
FORCEINLINE T Nand_5(volatile T a, volatile T b) {
return Xor(And(Not(a), b), Not(b));
}
Для этого нам достаточно сделать следующее:
template
FORCEINLINE volatile T NandR(volatile T a, volatile T b) {
switch (n % 5) {
case 0:
return Nand_1(a, b);
case 1:
return Nand_2(a, b);
case 2:
return Nand_3(a, b);
case 3:
return Nand_4(a, b);
case 4:
return Nand_5(a, b);
default:
return Nand_1(a, b);
}
}
Вызываться в коде это может вот так:
NandR(a,b)
Компилятор оставит только 1 вызов функции, который будет выбран в соответствии с результатом от макроса RND, так как число известно на момент компиляции. RND — это макрос с использованием xorshift + fnv1 + __COUNTER__ который обсуждался выше. Так же для удобства использования был написан примитивный шаблонный класс CNNInt который в себе содержит перегрузки необходимых операторов, чтобы улучшить читаемость кода.
Рассмотрим генерируемый ассемблерный код и DIFF двух различных компиляций для следующей функции:
uint64_t diff_me(uint64_t x) {
using u64 = uint64_t;
CNNInt r(std::chrono::system_clock::now().time_since_epoch().count());
CNNInt test(x);
test++;
test--;
test|=r;
test^=r;
test&=r;
test^=r;
test = ~test;
return test.value();
}
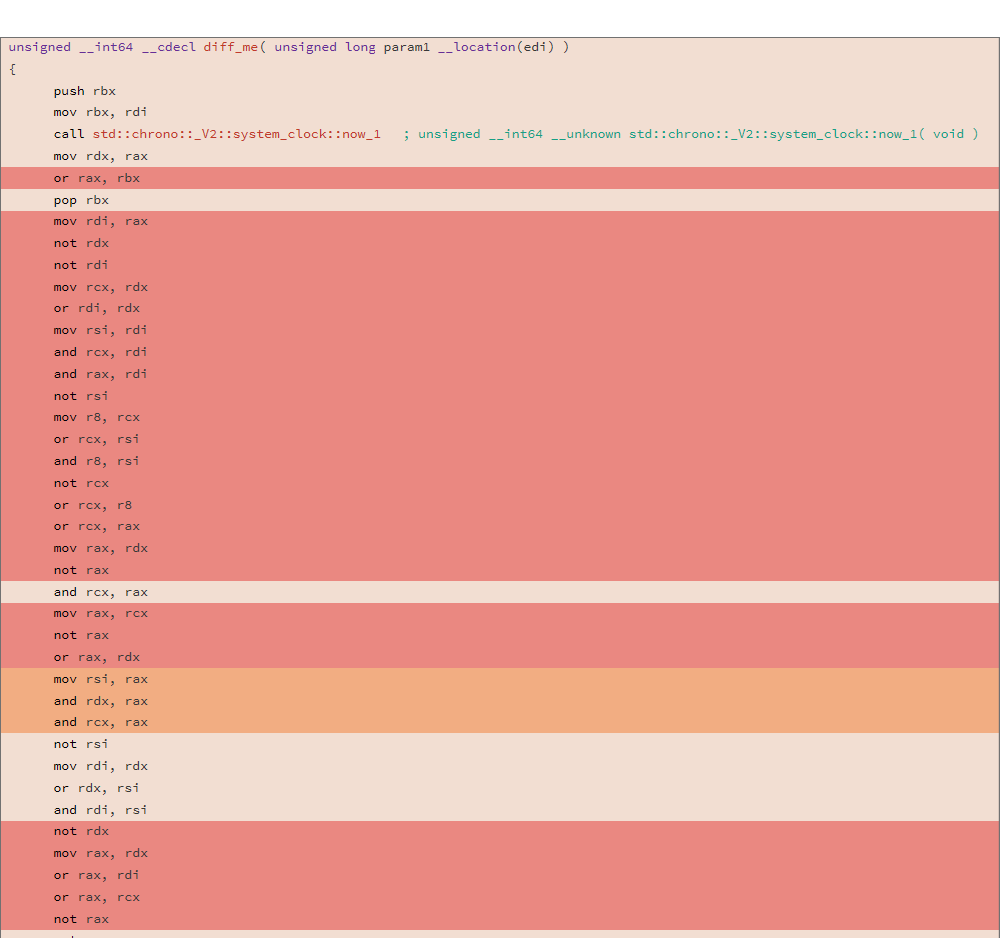
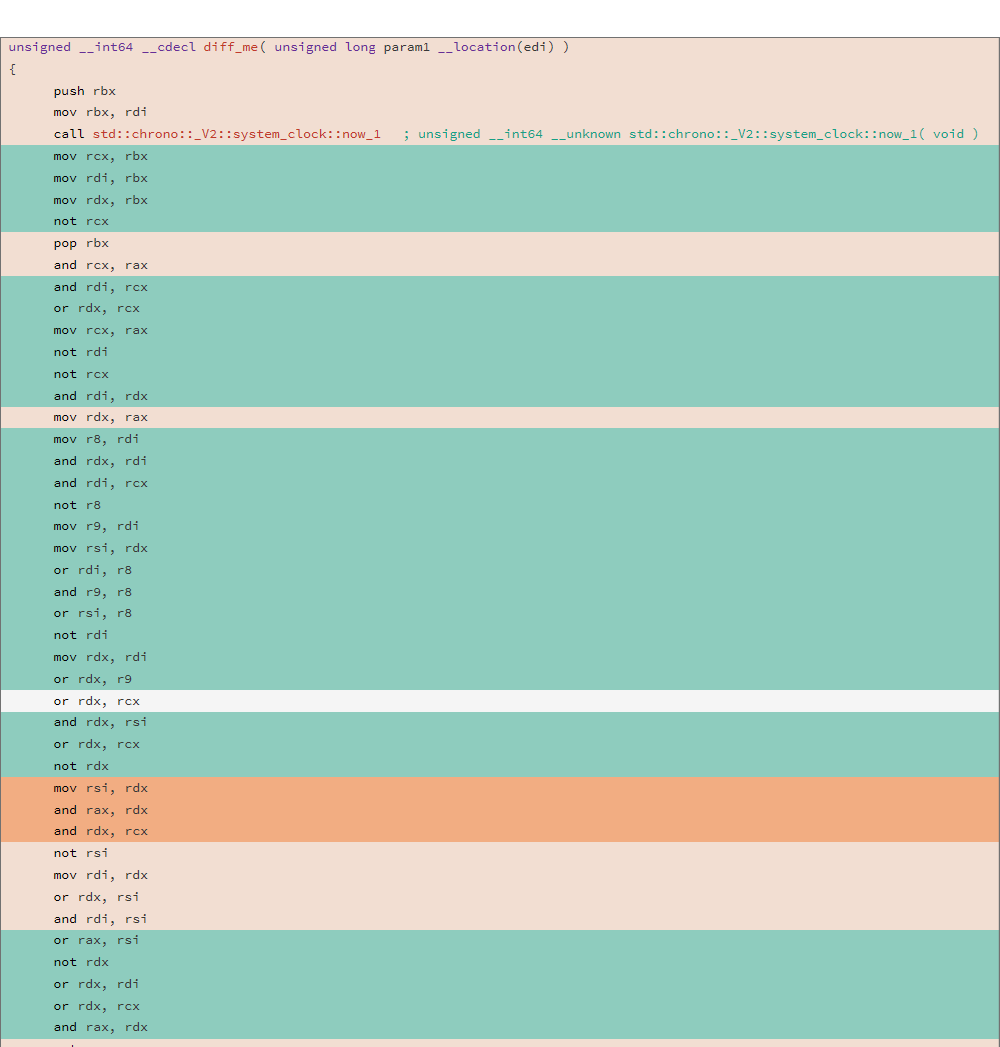
Анализ проводился используя утилиту relyze, DIFF двух бинарников показал следующий результат:
81.13% diff_me - diff_me
Посмотрим на функцию diff_me под декомпиляторами:
1. Ghidra
ulong diff_me(ulong param_1)
{
ulong uVar1;
ulong uVar2;
ulong uVar3;
ulong uVar4;
uVar1 = now();
uVar2 = ~uVar1;
uVar3 = ~(param_1 & ~param_1 & uVar1) & (param_1 | ~param_1 & uVar1);
uVar4 = ~uVar3;
uVar3 = (~(uVar3 & uVar2 | uVar4) | uVar3 & uVar2 & uVar4 | uVar2) & (uVar1 & uVar3 | uVar4) |
uVar2;
uVar4 = ~uVar3 & uVar2;
return (uVar1 & ~uVar3 | uVar3) & (~(uVar4 | uVar3) | uVar4 & uVar3 | uVar2);
}
В проекте в качестве примера есть еще одна функция execute_code, ее Ghidra декомпилировать не смогла.
2. Hopper
int _Z7diff_mem(long arg0) {
rax = std::chrono::_V2::system_clock::now();
rax = (rax & !((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) | !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax)) & (!(!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) & !rax | !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax)) | !((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) & !rax & !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) | !rax);
return rax;
}
3. RetDec
// Address range: 0x401320 - 0x4013a3
// Demangled: diff_me(unsigned long)
int64_t _Z7diff_mem(int64_t a1) {
// 0x401320
g14 = a1;
int64_t v1 = g14; // 0x401321
int64_t v2 = function_401030(); // 0x401324 _ZNSt6chrono3_V212system_clock3nowEv();
g14 = 0;
return -1 - ((v2 & -1 - v1 | v1) & v2);
}
Бонусы
1. Репозиторий проекта.
2. Вернемся к MSVC компилятору (тулчейн версии 16.4.2), компиляция примера из проекта съедает огромное количество памяти и занимает большое количество времени, я зарепортил баг компиляторной команде MSVC, буду рад если вы проголосуете за исправление данного бага.
Потребление памяти при компиляции тестового проекта:

Стоит отметить, что сборка тестового проекта используя Clang 9.0 и GCC 9.2.1 происходит практически моментально и не кушает такое количество памяти :)
