Code style как стандарт разработки
Давайте сразу, это не про скобочки. Здесь речь пойдет о том, как работает наш мозг и почему code style помогает обеспечивать линейное развитие проекта, значительно ускоряет адаптацию новых сотрудников и, в целом, формирует и воспитывает культуру разработки. Я постарался собрать в одной статье несколько исследований и принципов, посвященных работе мозга разработчика, и тому, как программисты читают код, а также поделился результатами личного эксперимента.
Интересно? Добро пожаловать под кат.

Привет! Меня зовут Антон, я пишу backend в ManyChat. Недавно у нас прошел митап, посвященный PHP-разработке, где я рассказал доклад про code style как один из стандартов разработки. По фидбеку, он отлично зашел гостям мероприятия, и мы решили сделать расшифровку доклада на Хабр. Для тех, кто особенно ценит эффект личного присутствия и больше любит смотреть видеозапись, чем читать тексты, у нас велась трансляция, которая доступна и сейчас. Найти ее можно по ссылке. Тем, кто любит лонгриды, добро пожаловать дальше.
Наш мозг — нейронная сеть
Начать стоит с описания, как вообще это работает и зачем вообще нужно всё то, о чем я расскажу позже. Многие из вас знакомы с понятием нейронной сети, или как минимум, слышали это словосочетание, которое несколько лет было чуть ли символом хайпа в IT-пространстве и маркетинге. Даже сейчас многие компании добавляют «AI based» на свои продукты, как наклейку «Без ГМО» на пельмени. Нейронная сеть работает по принципу распознавания образов и крайне эффективна при работе с однородными данными. Это изображения, видео, звук и т.д. Основной момент, который имеет отношение к стилизации кода — это принцип, на котором они были построены. Перцептроны, ячейки сети, были описаны как процессы работы мозга и заложены задолго до того, как они смогли быть реализованы в функциональную, работоспособную и эффективную сеть из-за слабых вычислительных мощностей. Наш мозг, хоть и значительно мощнее, работает схожим образом. Как следствие, человек использует мощности обученной нейронной сети от рождения и до самой смерти, а обучение идёт практически бесшовно.
Итак, мы воспринимаем только образы. Для мозга не существует текстов, звуков и прочего — все это мы воспринимаем только после декомпозиции. Грубо говоря, мы разделяем образы «попиксельно», складываем в память и потом при помощи ассоциативного мышления узнаем различные объекты. Благодаря этому мы можем понять, бежать ли нам от змеи или садиться на велосипед и нажимать на его педали. Перед вами схема стандартного перцептрона, которая иллюстрирует, как происходит классификация объектов. Для тех, кто не знаком с принципом работы перцептрона, может выглядеть немного хаотично. Но именно благодаря такой схеме балансировки и взвешивания нейронная сеть распознает образы, быстро и эффективно.

Из программирования можно вспомнить принцип DuckType, когда считается, что если объект плавает как утка, летает как утка и крякает как утка — это утка. Своеобразная аппроксимация детектирования объектов. И для нашего мозга распознавание объектов происходит моментально. Обучение же значительно более длительный процесс. Поэтому можно представить этот процесс также, как и обучение еще маленького ребенка, который только учит слова. Вы берете яблоко, показываете и говорите: «Это яблоко». Берете другое и снова повторяете: «Это яблоко».

И так до закрепления результата. Зеленые, желтые, красные, шарообразные, вытянутые, с черенками и без, черно-белые. Год за годом, ребенок наращивает свою базу на основе эмпирических знаний. Я думаю, принцип понятен. Тоже самое мы делаем когда обучаем нейронную сеть. От объекта к объекту или, если более точно, от образа к образу.
Как программист читает код
То же самое происходит, когда мы работаем с кодом. Мы открываем страницу, изучаем ее, декомпозируем на блоки, идентифицируем разные части — легко отделяем свойства от функций, уровни изоляции методов и свойств, находим константы и так далее. Мы идентифицируем все это по блокам, и поэтому важным аспектом стилизации кода является приведение всего кода к одинаковому виду. Это ключевой фактор, который характеризует читабельность кода.
Почему это важно? Потому что большую часть своего рабочего времени программист читает код. Какой-то прямой корреляции не обнаружено, по большей части это зависит от квалификации, языка (например, Python построен на отступах, и неправильно структурированный код просто не будет работать), качества кода и т.д. Но от 50% времени уходит на чтение своего и чужого кода. Если код сложный, то показатель может достигать 75%, а если код совсем плох, то 95% времени может уходить на чтение и попытку понять, куда нужно добавить одну строчку, чтобы поправить какой-то недочет. А теперь вопрос. Что вы сделаете, если увидите, что ваш код тратит 75% времени на чтение диска или на выделение памяти двусвязным спискам? Программист постарается оптимизировать этот процесс, попробует поменять алгоритм, применить более эффективную структуру хранения и т.д. Соответственно, когда потраченное время стало критичным, я начал инспектировать этот процесс. И можно было бы сказать мол, ну это же мозг, он значительно мощнее любого компьютера и может хранить около петабайта данных. Но, в процессе разработки своего ментального фреймворка по работе с кодом (скрытый процесс формирования привычек чтения кода), я набрел на исследования, в которых датчики следили за движениями глаз начинающего и опытного программистов. Выглядит все это вот так:
Начинающий 
Опытный
Обратите внимание, чем занимается опытный программист. Он выделяет блоки кода, декомпозирует их и читает поблочно, выделяя ключевые части и анализируя их работу. Начинающий же мечется построчно, просто пытается понять, что тут вообще происходит. Львиная доля времени уходит на то, чтобы сложить общую картину и чтение кода происходит с постоянным перекрестным инспектированием.
Видео довольно старое, от 2012 года, и запись была направлена на исследование процессов мозга программиста. Чуть подробнее можно почитать тут и тут.
Вот сейчас самое время вернуться к описанию работы перцептронов. Это наглядная демонстрация работы обученной и не обученной нейронной сети. Исходя из своей базы знаний опытный программист идет по коду подобно интерпретатору, часто даже не осознавая это. Можно подойти к решению этой проблемы также, как мы подходим к проблемам обучения нейронных сетей.
Есть 2 способа ускорить чтение кода:
- Постоянно наращивать базу знаний разработчика по тому, как может выглядеть код. Это значит непрерывное обучение, которое постоянно наращивает мощность сети.
- Привести весь код к одному стандарту, задать тот самый code style
Разумеется, довольно очевидно, что первый способ — очень трудозатратный. В этом случае программисту нужно постоянно читать репозитории. А учитывая текучку кадров, появление новых технологий и практик, это становится практически невозможно. Методом исключения, остается стилизация кода, которая снизит аффект на декомпозицию и оставит только аффект на бизнес логику.
Количество настройщиков пианино
Представьте, что команда из 5 человек пишет, как хочет, во все модули и компоненты системы, постоянно получая пересекающиеся задания, корректируя код друг друга. Какое возможное количество всех вариантов написания условия в if, если учесть, что каждый пишет по своему? 5. А сколько у нас допустимых блоков? Все конструкции, вызовы одноаргументных и множественноаргументых функций, неймспейсов, классов, трейтов, интерфейсов, позиционирование блоков, статики, зоны видимости и т.д. Это при условии, что каждый использует только 1 стиль написания, который отличается от стилей всех остальных. А если человек 10? А 50? Понятно, что с возрастанием количества человек будет снижаться дисперсия из-за ограниченного количества способов написать один и тот же блок. И это первый уровень, в который мы не вкладываем одну из основных проблем программирования — нейминг переменных. Эффект мультипликатора и всех возможных комбинаций даже не учтен. Накиньте сверху стилистику разделения, отступы на пробелах и табуляции, любовь к if лапше и т.д. и т.п. А еще постоянно поступают новые специалисты и уходят старые. На выходе вы получаете огромный нечитаемый код, к которому невозможно привыкнуть и невозможно выработать хорошо обученную нейронную сеть у программистов в компании.
Наш мозг ленив донельзя
Еще один интересный эффект работы нашего центрального процессора в черепной коробке заключается в крайне негативном восприятии новой информации. Наш мозг ленив донельзя. С массой около 1,5—2% от общей массы тела, мозг потребляет 25% всей энергии организма. Одной из самых ресурсоемких операция для мозга была, есть и остается концентрация внимания. 20–25 минут можно удерживать максимальную концентрацию (привет техника Pomodoro), и за это время мозг сожрет столько глюкозы, сколько он сожрал бы за целый день субъективного покоя. Обработка новых данных это крайне ресурсоемкий процесс. А одна из главных целей мозга — эти самые ресурсы экономить. Это связано с работой нашей ментальной модели. Своеобразный психологический блокер. Выглядит это примерно так. Вы начинаете учить что-то новое. Что-то новое сложно даётся и из-за отсутствия ощутимой динамики прогресса у Вас начинает снижаться самооценка из-за витающей бэкграундом мысли «I«m stupid!». Наша психика устроена таким образом, что от самооценки зависит всё мироощущение, а от мироощущения, в свою очередь, зависит наш успех в социуме. И для того, чтобы не ломать базовые социальные лифты на адаптационных зависимостях, наш мозг начинает сопротивляться занятиям, снижающим самооценку. Как следствие, вам хочется посмотреть сериальчик, почитать хабр, пойти выпить кофе, посидеть в соц. сетях и т.д. Что угодно, лишь бы не учить ту самую теорию поля Ландау. Или фиксить трудновоспроизводимый баг. Или… читать некачественный код, в котором трудно разобраться. Отличный пример того, как мозг себя ведет по ограничению в этой области — люди лет 70–80, которые в упор не желают осваивать смартфон или 2 кнопки на роботе-пылесосе. Ресурсы на исходе. Мозг отчаянно блокирует процесс обучения и действует по накатанной. Этих ресурсов очень много, пока вы молоды. С течением времени и взрослением их становится всё меньше и меньше. Работает вполне линейно. Благо это компенсируется возрастающей мощностью наших нейройнных сетей. Если мы не говорим о прямой целенаправленной деградации, конечно.
Немного стереотипов
Распространенное заблуждение, которое вы могли слышать «Да ну, я профи, я могу читать любой код. Я быстро и круто пишу, решая проблемы компании. И не важно, как выглядит мой код, если он решает проблему. Остальные просто не могут быстро разобраться, у меня с этим проблем нет.». Если в вашем окружении есть такой кодер, можете сказать ему: «Чувак, у меня для тебя плохие новости. Ты афектишь всю команду, и такой подход является причиной, почему остальные пишут медленнее, когда супер эффективный программист быстро форсит код».
Суперэффективный программист, который пишет без оформления и стандартизации, на самом деле суперэффективен в 2-х вещах:
- Суперэффективно закрывать задачи, не вдаваясь в дизайн и стилистику.
- Суперэффективно тормозить всех остальных, потому что после его дополнений люди долго пытаются понять, что тут вообще произошло.
Зачем нужен code style
Хоть это уже и должно быть очевидно, но нужно как-то подчеркнуть основные моменты.
Code style:
1. Обеспечивает линейное развитие проекта и не влияет на объем кодовой базы. Если вы обеспечили историческое написание понятного кода, то, сколько бы не приходило и не уходило разработчиков, вы всегда имеете равное качество кода, что позволяет проекту динамично расти вне зависимости от его объема.
2. Значительно ускоряет процесс адаптации новых программистов. Если ваш код написан понятно, новый специалист очень быстро обучит свою нейросеть на определение блоков и начнет приносить пользу. Есть такое понятие, как точка самоокупаемости сотрудника. Это точка, с которой сотрудник начинает приносить только пользу. А если код написан понятно, новым сотрудникам не нужно разбираться в бизнес-логике, ему достаточно научится читать ваш код. И чем быстрее он это сделает, тем быстрее перестанет задавать тонны вопросов остальным специалистам, отнимая у них время. А время специалистов, которые прошли точку самоокупаемости, значительно дороже для команды и компании с точки зрения потенциальной ценности приносимой продукту.
3. Убирает зависимость от частностей. Не нужно будет постоянно спотыкаться о чью-то оригинальность и специфическое оформление.
4. Минимизирует эффект ментального блокера при изучении нового кода. Ваш мозг меньше сопротивляется, т.к. не нужно вникать в чужую стилистику. Ментальных ресурсов на чтение понятного кода нужно намного меньше.
5. Минимизирует репутационные потери. Очень скоро, после прибытия в новую компанию, программист начнет делиться впечатлениями с бывшими коллегами и друзьями. И он либо скажет, что тут все круто, либо выделит негативные моменты в работе с кодом. В каком-то смысле тут получается HR-бонус: если вы хотите, чтобы с вами работали крутые программисты, делайте хороший проект. Хоть это не всегда важно, и в ряде компаний на качество кода не смотрят в принципе, а смотрят лишь на доставку фич до прода, это приятный бонус. Не секрет, что частой причиной ухода становится усталость от постоянного перепиливания некачественной кодовой базы.
6. Формирует и воспитывает культуру разработки. Задача программиста лежит на более низком уровне, чем будущее всей компании, но важно донести понимание, что понятность и читаемость кода сейчас влияет на динамику дальнейшей разработки. Если код трудночитаем и не стандартизирован, с болью и страданиями поддается рефакторингу и масштабированию, то с ростом кодовой базы проекта, будет падать скорость разработки. Чем больше некачественного кода, тем сложнее писать новый, тем медленнее развивается продукт, тем сложнее компании наращивать обороты и тем сложнее ей платить вам больше денюжек, потому что много денюжек уходит на то, чтобы обеспечивать жизненный цикл проекта все новыми и новыми сотрудниками, который основное время онбоардинга тратят не на то, чтобы приносить пользу компании, а на классификацию наркотиков, под которыми этот код был написан.
Идеальный код
Все мы понимаем, что его не существует. С точки зрения каноничного code style — это понятие об оформлении кода. И всё бы хорошо, если бы это было правдой. В разработке на длинной дистанции code style более емкое понятие, которое включает в себя принципы разработки. Разбиение кода на логически изолированные блоки в классах или файлах также относится к оформлению. Нейминг, уровни изоляции, наследование. Все это инструменты не только взаимодействия, но и оформления вашего сложного механизма, где каждый кирпичик играет свою роль.
Концепции меняются от языка к языку. Частности выходят на передний план. Но фундамент остается неизменным. Качественный код определяется всего двумя критериями:
- Код обезличен
- Код читается как книга
Обезличенный код
То идеальное состояние, к которому нужно прийти в этом процессе, называется обезличенным кодом. Я уверен, что многие из вас, открыв рабочий проект и случайный компонент, могут навскидку сказать, кто из коллег это писал. У каждого часто присутствует стилистика. Кто-то любит лапшу из if, кто-то по поводу и без сует лямбды, кто-то любит сокращать переменные так, чтобы сэкономить один символ. В обезличенном коде вы этого сделать не сможете. В идеальном обезличенном коде невозможно определить автора. И этот тот случай, когда вы пришли к финальной точке своего codestyle.
Читабельность на уровне книги
Вспомним 2 главные проблемы программирования? Инвалидация кеша и нейминг переменных. Обойдём стороной тёмное прошлое процессов кеширования и перейдем сразу к нашей боли. Нейминг переменных, классов, объектов, файлов, методов, констант и так далее. Эта проблема имеет 2 крайности. Слишком краткие названия и слишком длинные. Здравый смысл подсказывает, что логика где-то рядом, рядом с серединой. Тут к нам в дверь постучатся суперэффективные программисты и расскажут, что им всё равно. Но зачем нам теоретизировать об этом? Расскажите мне что делает это код? 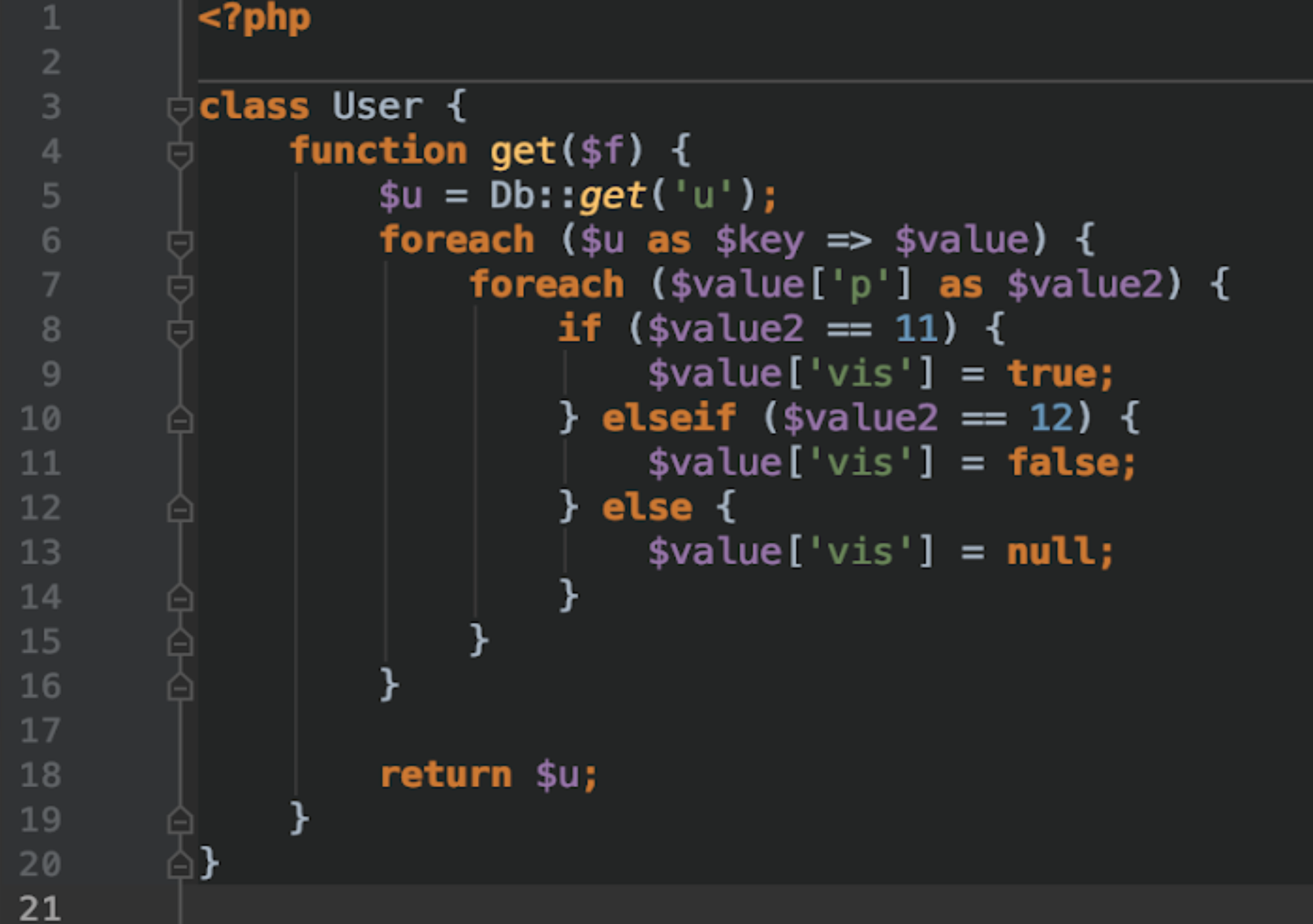
А этот?

Второй код читается напрямую и легко. Не нужно особо разбираться в бизнес логике, чтобы понять функциональную нагрузку при таком нейминге. В этом примере мы просто берем весь репозиторий, потом используем builder, чтобы создать коллекцию, потом применяем фильтр. Не нужно даже вникать внутрь кода, чтобы понять, что происходит. Как чтение книги по заголовкам. Но нейминг это еще не всё.
Паттерны проектирования
О паттернах проектирования вас спрашивают чуть ли не на каждом собеседовании. Их публичная цель — повторяемое архитектурное решение. Их побочный эффект — предсказуемость и системность. Тот момент, когда вы переходите на архитектуру, построенную на паттернах проектирования, вы формируете довольно предсказуемую систему. Т.е. исходя из названия вы легко понимаете назначение класса или объекта. Что делает паттерн Repository? Это представление хранилища с методами получения данных. Что делает паттерн Builder? Собирает сложный объект или структуру. И так по всем фронтам.
Существует такой паттерн как Command. Что с ним можно сделать? Конечно, только execute! Вам не нужно изучать, что же в нем внутри. Понятно, что его можно выполнить. Шаблоны проектирования помогают понять, как устроен ваш проект. Если вы написали все хорошо, то не будете задаваться вопросом: «Что у меня лежит в этих директориях?». По названиям вы легко определите, что и где находится.
Скажем так. Все решения на паттернах проектирования были сформированы, неся в своей основе боль разработчика по той или иной проблеме. Эта боль уже была кем-то пережита, оформлена и получила свое решение в виде одной из существующих архитектурных моделей. Более того, всё это было сформировано поверх небезызвестного SOLID.
SOLID
SOLID — акроним из пяти принципов объектно-ориентированного программирования. Заметьте: 5 принципов. Объектно-ориентированного. Программирования. Это не практика. Это не рекомендация. Это не желание какого-то старого программиста поучить молодежь. И много где вы сможете услышать, что SOLID — это принципы. Но если вы посмотрите на манифест SOLID, в котором были описаны 6 признаков плохого проекта, то обнаружите, что SOLID — это не просто принципы. Это условия, при соблюдении которых ваш проект будет обладать гибкостью, расширяемостью и предсказуемым для разработчика поведением. И несоблюдение любого из принципов — это нарушение условий контракта с кодовой базой при котором вы потеряете одно из качеств. Будь то простота восприятия, гибкость, или зависимость на абстракциях: чтобы вы не потеряли, это начало формирования проекта или компонента, который вы будете переписывать. С нуля. Потому что правильно сделать в получившейся реализации гораздо сложнее, чем быстро внести очередные некорректные вкрапления.
Сколько вы видели переписываний проектов? В скольких таких участвовали сами? Не один и не два. В каждой компании вы найдете компонент или целую систему, которая была спроектирована без культуры разработки. Без хорошего code style, без паттернов проектирования, без учета условий SOLID. Отделы разработки каждый день занимаются переписыванием кода. Двойной работой. Зачастую переписывая в такие же трудночитаемые компоненты. И единственный плюс таких переписываний — знакомство специалиста с бизнес-логикой. Т.е. вы переписали код, думаете, что разбираетесь, но вы разбираетесь не потому, что он стал проще, легче, лучше оформлен. В большинстве случаев в нем теперь разбираются просто потому, что сами же его и переписали.
Из этого стоит вынести, что code style это форма социального контракта внутри вашего community в компании. Вы договариваетесь о том, как писать код, с учетом специфики бизнеса, самого кода, архитектуры и планов по изменению кодовой базы. Эта договоренность означает, что соблюдают ее все. Командная работа подразумевает не столько работу вместе, сколько работу в интересах команды. Это не коворкинг, это общая цель к которой идут все. Как следствие, одной из целей обозначается чистота кода как инструмент дальнейшего развития.
Какой выбрать code style? Не важно! Это не обсуждение вкусовщины. Мы же обучаем нейронную сеть, а значит не имеет значения что именно будет в тренировочном сете. Важно, чтобы это были одинаковые блоки. А как они будут выглядеть значения не имеет. Но лучше взять что-то из open-source based стилей. Просто исходя из того, что PSR знает большее количество людей, нежели какой-то свой кастомный. Не говоря уже о крайне распространенном symfony2 code style, который фактически является улучшением и расширением PSR. Это, разумеется, про PHP. В них встроена качественная блочная модель, которая легко читается, легко дополняется и легко поддерживается.
К чему всё это?
Вам, вероятно, хочется узнать к чему это приведет? Я приведу пример с одного из предыдущих мест работы — там получился чистый эксперимент, учитывая, что вопросы CodeStyle не волновали команду до того, как я поднял этот вопрос. Когда я пришел к команде и сказал, что с завтрашнего дня в вашем PHPStorm заведется такой забавный зверь, как phpcs и codestyle протокол — все немного приуныли. Не в моих правилах заниматься нововведениями через репрессии, я попытался донести это через демонстрацию той кучи исследований по распознаванию образов программистом. И все равно поддержка нашлась только у пары человек, которые, как и я, сильно страдали от чтения некачественного кода.
Я пожал плечами и начал писать чистые, хорошо спроектированные (субъективно), изолированные компоненты. Я ведь могу ошибаться, верно? Конечно могу. А потом стал раздавать одним и тем же людям задачи идентичной сложности в новые чистые компоненты и в старые. Постепенно, аккуратно собирая статистику. Спустя 2 месяца я поднял свою табличку в Google Sheets и показал ее команде. На чистом коде эффективность программистов оказалась на 23% выше. Поразмыслив, что 7 человек это не репрезентативно, я продолжил эту практику довольно тихо в параллельном проекте, где работало около 20 фриланс программистов. Результаты оказались несколько хуже. Но да, небольшой состав программистов из более чем 20 человек писал довольно чистый и хорошо спроектированный код. И поверх их кода идентичные задачи другими решались на 21% быстрее. Хотел двинуться дальше, но этого было достаточно, чтобы получить поддержку со стороны команды.
Медленно, но уверенно, мы очищали рабочий проект от плохого дизайна, и в один момент пришли к состоянию, когда 90% кода было выполнено по всем канонам разработки, которые мы определили. К чему это привело? Мы взяли очередного Middle PHP Developer в команду. И его onboarding прошел за месяц, вместо обычных 3-х. А потом еще один такой же… Комплексная бизнес-логика и асинхронное взаимодействие всегда сложно даются. Но не в этом случае. Наш onboarding приобрел характер быстрого обучения бизнес-логике, а не классификации наркотиков, под которыми написан каждый кусок кода. Мы пришли к состоянию, когда достаточно всего 1-го месяца перед выдачей большой и серьезной задачи даже Junior PHP Developer. Коммуникации в стиле «как это работает» были сведены к минимуму. И эта была действительно success story.
Вот так, просто не нарушая правила, которые были написаны задолго до сегодняшнего дня, нам удалось на ровном месте увеличить производительность команд почти на 25%, а тайминг onboarding«а уронить на ⅔. При этом совершенно исключено появление «грязного кода» внутри чистого, потому что никто не позволит вносить непонятно что в отлаженную и работающую систему. А если качество кода изначально низкое, никто не заметит появления новых никуда не годных фрагментов. К тому же сегодня есть достаточно инструментов, которые позволяют следить за качеством и чистотой кода в автоматическом режиме, например, таким плагином phpstorm как Sonar Light.
Во многих компаниях некачественный код — это причина, по которой нужно держать огромный штат Senior разработчиков, основная ценность которых заключается в том, что они знают проект и могут разобраться в любой каше. Вдумайтесь, ресурсы высококлассных специалистов используются для борьбы с последствиями отсутствия культуры разработки, а не для реализации технически сложных систем. Для решения этой проблемы дополнительные деньги уходят на огромный штат Senior QA Engineer со всеми вытекающими дополнительными расходами.
Мне иногда не верят, что эффективность может быть повышена на 21–27%. Окей, предположим, что у нас получился какой-то невероятный результат. Но если даже предположить, что экономия составляет 5%, то при реальном рабочем времени в 5 часов в день (исключая перекусы, перекуры и прочее), то для команды из 5 человек будет сэкономлено 69 минут в день. Простым умножением понимаем, что получается 14 840 минут в год –, а это 40 человеко/дней. Почему бы не потратить один из них на установку phpcs и phpstorm? Я уже не говорю о том, каковы будут результаты при оптимизации работы 50 разработчиков.
P.S.: Если будет интерес к данной теме, то в следующей статье я обязательно поделюсь с вами историей того, как мы настроили этот процесс в ManyChat, с чего лучше начинать и как действовать.
