Cнова про llvm
Исследования любого приложения достаточно рутинный и длительный процесс. Без использования инструментов и автоматизации разобрать даже самые простые алгоритмы написанные на некоторых языках программирования практически невозможно. (Go рантайм без символов). Справиться с этой тяжелой задачей и предоставить набор инструментов могут следующие приложения:
Hopper
IDA Pro
Ghidra
radare2
rizin
Список включает только те, которые постоянно на слуху и известны во всём мире. Попробуем разобраться в нашей статье с тем как эти приложения могут разбирать ассемблерные листинги и строить псевдокод. Можно ли найти проект, который будет давать возможность просто создавать изменение ассемблерного листинга без написания сложных парсеров?
История про llvm
Описанные во вступительной части инструменты — интерактивные дизассемблеры. Они помогают получить низкоуровневое представление команд и приблизительную структуру кода. Дополнительной фичей, которой обладают инструменты — функция декомпиляции. Представляет собой она преобразование низкоуровневых команд в псевдокод, который очень похож на язык программирования С.
Ниже приведем пример дизассемблированного бинарного файла для ОС Linux:
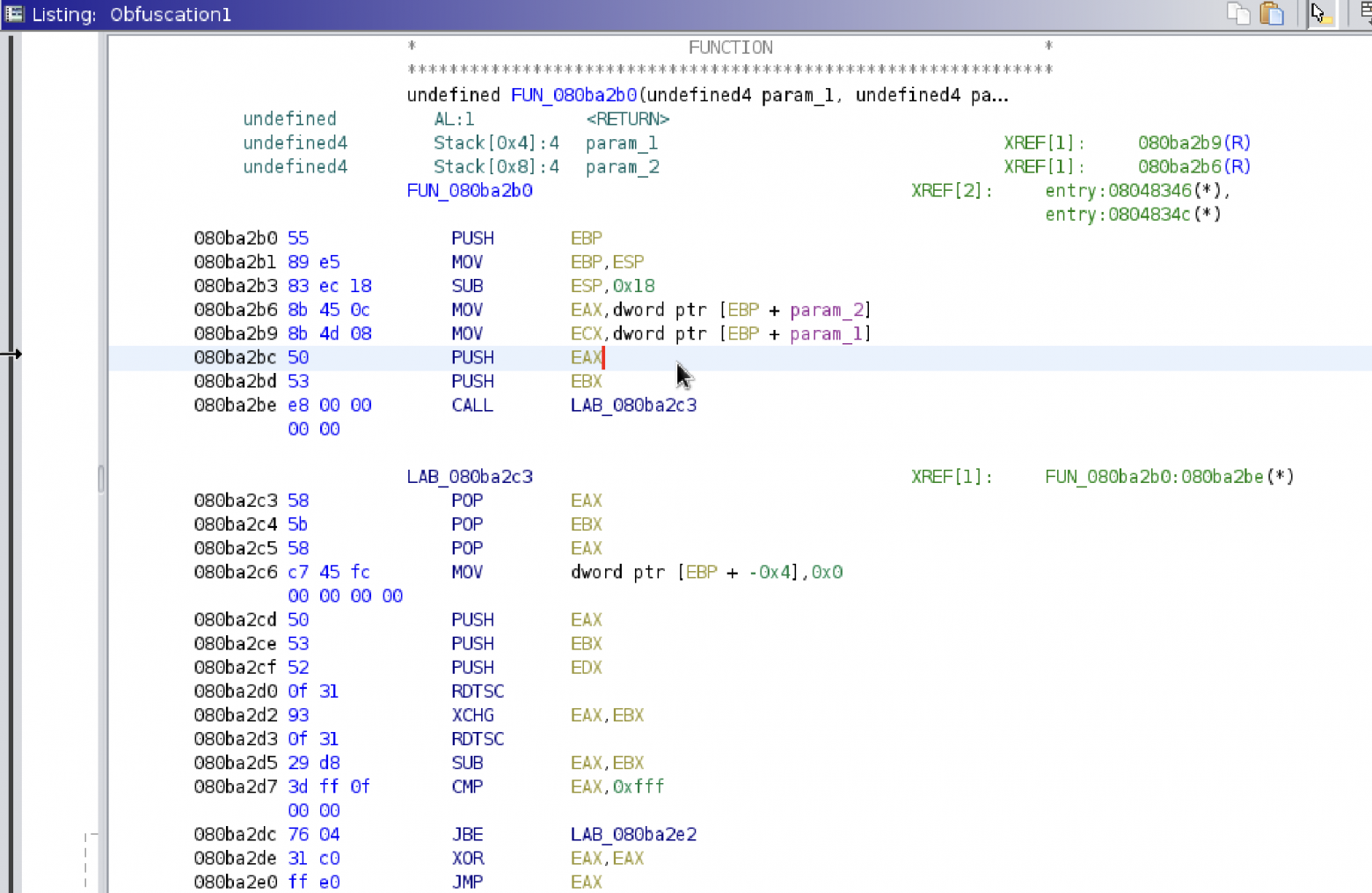
Это дизассемблированный листинг приложения, чтобы разбираться какие действия должны выполняться в алгоритме и что писал разработчик, нужно целые группы ассемблерного кода объединять в одно действие. По сути это оптимизация — десятки команд упрощаются для того чтобы в итоге получить читаемый листинг. Чтобы это было возможно делать с большим количеством вариаций ассемблерных команд используется промежуточное представление.
Промежуточное представление может быть основано на собственно разработанном языке. Так работают все существующие декомпиляторы. Иногда в приложениях можно встретить использование проекта llvm, этот проект даёт возможность создавать промежуточное представление ассемблерных команд, которые в дальнейшем можно эффективно оптимизировать.
Некоторые из интерактивных дизассемблеров создают свои собственные движки для оптимизации и представления данных в виде псевдокода. В основном это проекты с закрытым исходным кодом и их изучение без разрешения владельца охраняются законом, поэтому для обзора функций можем использовать только проекты с открытым исходным кодом. Попробуем рассмотреть особенности работы декомпилятора на примере retdec.
Что особенного с проектом retdec
Проект представляет собой обертку над llvm и позволяет производить анализ любого набора данных от проприетарных форматов операционных систем до просто наборов сырых данных, которые можно достать из памяти устройств и микроконтроллеров.
Проект содержит в себе 3 типа файлов, которые можно использовать как для интеграции инструмента в свои приложения, так и для самостоятельного использования. Список файлов:
Библиотеки для работы декомпилятора
Инструменты, которые по сути совместно могут быть использованы для компиляции
Скрипты, которые объединяют инструменты таким образом, чтобы все операции выполнялись автоматически
Все описанные файлы можно найти в любом билде, который доступен из репозитория проекта. Содержимое релиза выглядит так:

Применение проекта для исследования
Попробуем использовать проект для оптимизации кода, который достаточно плохо поддается анализу. Ниже приведен граф этого кода, чтобы можно было оценить масштаб проблемы:

Граф содержит очень много конструкций и условий, которые не могут быть добавлены для оптимизации в стандартных декомпиляторах. Попробуем оптимизировать этот граф. Для этого возьмем проект retdec и попробуем его собрать.
Полный перечень команд для каждой операционной системы есть на главной странице репозитория. Виртуальная машина справилась в компиляцией за 2 часа при параметрах в 4Гб оперативной памяти.
У retdec есть возможность работать с конкретным диапазоном внутри файла. Для этого нужно:
Локализовать адрес внутри файла (виртуальный адрес)
запустить команду —
python3 retdec.py crackme --select-ranges 0xfrom-0xto --select-decode-onlyКоманда должна оставить в директории промежуточное представление куска файла, который был обозначен в диапазоне. Попробуем передать диапазон, который входит в часть обфусцированной функции.
Для локализации данных используем Ghidra:

Файл с названием crakme.ll будет доступен в текущей директории. В этом файле располагаются команды, которые представляют собой тот самый язык промежуточного представления или IR.

Эти данные при помощи llvm можно преобразовать в любую версию ассемблерного листинга:
arm архитектура: llc -o crackme.asm -filetype=asm -march=arm crackme.ll

x86 архитектура: llc -o cracme.asm -x86-asm-syntax=intel -filetype=asm -march=x86-64 crackme.ll

mips архитектура llc -o cracme.asm -filetype=asm -march=mips crackme.ll

Так же в директории есть доступный файл для анализа с расширением .c. Это уже и есть декомпилированный листинг:

Объединим вместе, что это всё значит:
При работе с файлом retdec может выбрать любую часть данных и попытаться представить это в виде команд
Представленные команды могут быть преобразованы для любой архитектуры
Команды автоматически переводятся в псевдокод для упрощения анализа
Все перечисленные функции позволяют:
портировать софт на другие платформы. (С большими костылями, но это возможно)
решать задачи оптимизации кода и удаления мусорных команд.
По последнему вот наглядный пример как изменился кусок кода после оптимизации. Слева оригинальный код, справа оптимизированный код:
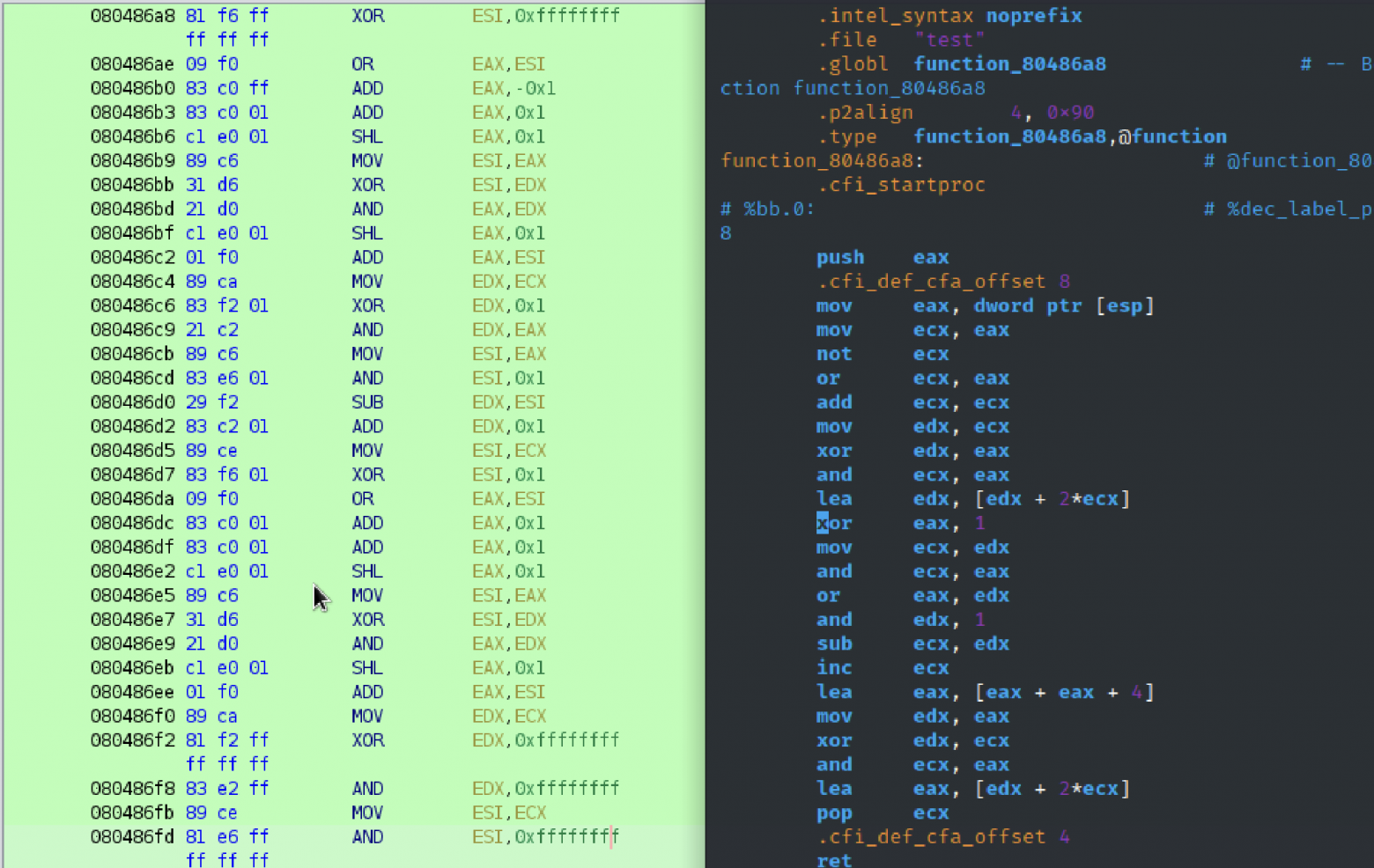
Соответственно код который расположен слева декомпилятор, который поставляется в ghidra по умолчанию, превратить в псевдокод не смог.
Таким образом retdec можно использовать и для оптимизации ассемблерного листинга и для декомпиляции.
На этом все. В преддверии старта курса Reverse Engineering приглашаю всех желающих на бесплатный демоурок в рамках которого рассмотрим типовые способы внедрения кода, которые используются вредоносными программами. А также узнаем, куда внедряется код, какие именно поля исполняемых файлов редактируются и проделаем внедрение вручную, на практике.
