ChatGPT плохо отвечает на «простые вопросы». Как это починить?
Привет, Хабр! Меня зовут Антон Разжигаев, я аспирант в Сколтехе и участник научной группы Fusion Brain (AIRI), работающей над мультимодальными подходами. В этой статье я расскажу о нашей последней работе — Multilingual Triple Match — системе для поиска ответов на фактологические вопросы, которая по своей точности обходит даже ChatGPT.

Изображение сгенерировано при помощи DALLE-3
За последние несколько лет произошел взрывной рост качества языковых моделей (Language Models, LMs). Наиболее известной из них стала ChatGPT, которая приобрела популярность далеко за пределами машинного обучения. Но все языковые модели, независимо от их размера, обладают существенным недостатком — их знания фиксируются в момент обучения и из-за этого устаревают. Более того, они испытывают трудности с фактологическими вопросами из-за склонности «галлюцинировать».
Что с этим делать? Самым простым решением было бы дать этим моделям доступ в интернет и позволить «гуглить» новую и актуальную информацию —, но тогда появляется риск получить недостоверные факты. Поэтому мы решили в качестве источника актуальной информации использовать графы знаний, опирающиеся на Википедию.
Простые вопросы и графы знаний
Как я уже сказал ранее, главные ограничения языковых моделей — это галлюцинации (то есть выдумывание несуществующей информации) и фиксация знаний на дате обучения. Эти два эффекта приводят к огромным сложностям с фактологическими вопросами. От этих проблем страдают все крупные модели: ChatGPT, Llama 2, Claude и так далее (см. картинку).
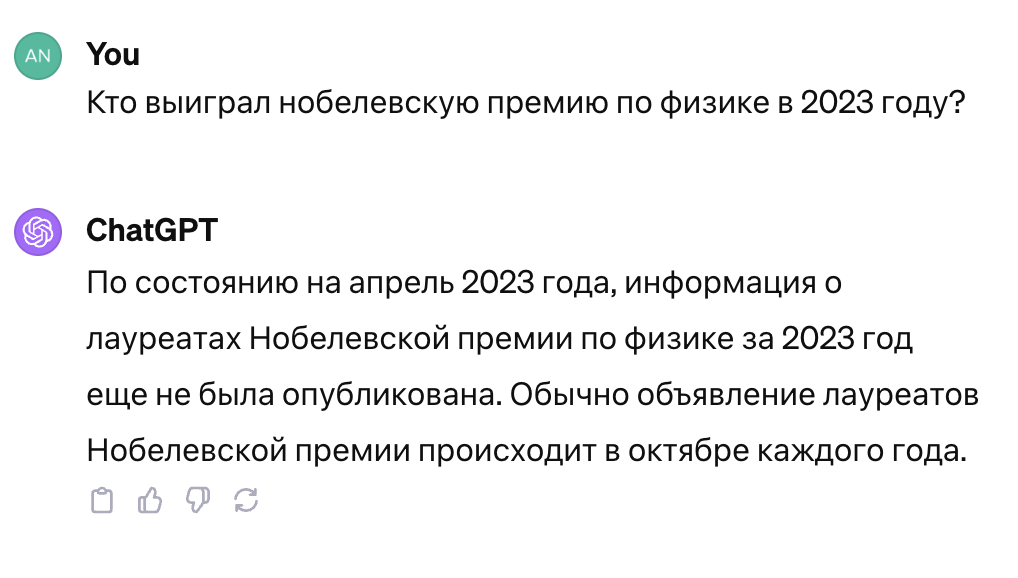
ChatGPT без доступа в интернет не отвечает на вопросы про актуальные события.

LLaMa2–70b галлюцинирует отвечая на вопросы про то чего не знает.
Вот пример ошибки из-за устаревания: Llama2–70B обучалась раньше, чем были объявлены лауреаты нобелевской премии 2023 года, поэтому она «галлюцинирует», отвечая на этот вопрос. ChatGPT вообще отказывается отвечать, так как не обладает актуальной информацией.
Ответы на фактологические вопросы всегда конкретны и не зависят от того, как мы их интерпретируем.
Особенно интересными являются простые вопросы (simple questions), где четко указывается субъект поиска. Например, «Как называется столица Франции?» — тут субъект это «Франция». Мы решили, для начала, сосредоточиться именно таких вопросах и использовать графы знаний для поиска ответов.

Граф знаний, сгенерировано при помощи DALLE-3
Графы знаний представляют собой сеть взаимосвязанных фактов, выраженных в форме триплетов [Франция, имеет столицу, Париж]. Поэтому на простые вопросы возможно отвечать с помощью поиска по таким графам. Но поиск среди миллиардов фактов — это очень сложная задача, именно ее мы и попытались решить в методе МЗМ.
Одним из самых крупных и регулярно обновляемых графов знаний является Wikidata. Она опирается на связанные друг с другом статьи из Википедии, что гарантирует определенную актуальность и верифицируемость. Более того, граф знаний Wikidata — мультиязычный, то есть факты выражены на большом количестве языков, при этом структура самого графа от языка не зависит. Мы объединили все эти преимущества для создания многоязычной KGQA-системы M3M — Multilingual Triple Match.
Архитектура модели M3M
M3M — это вопросно-ответная система, то есть на текстовый вопрос пользователя она возвращает факт из графа знаний (триплет).
Упрощённо, M3M состоит из двух частей: первая часть отображает текстовый вопрос в набор векторных репрезентаций (эмбеддингов), а вторая часть осуществляет поиск по графу знаний Wikidata через сравнение с заранее подготовленными эмбеддингами всех существующих фактов (Pytorch-Big-Graph).
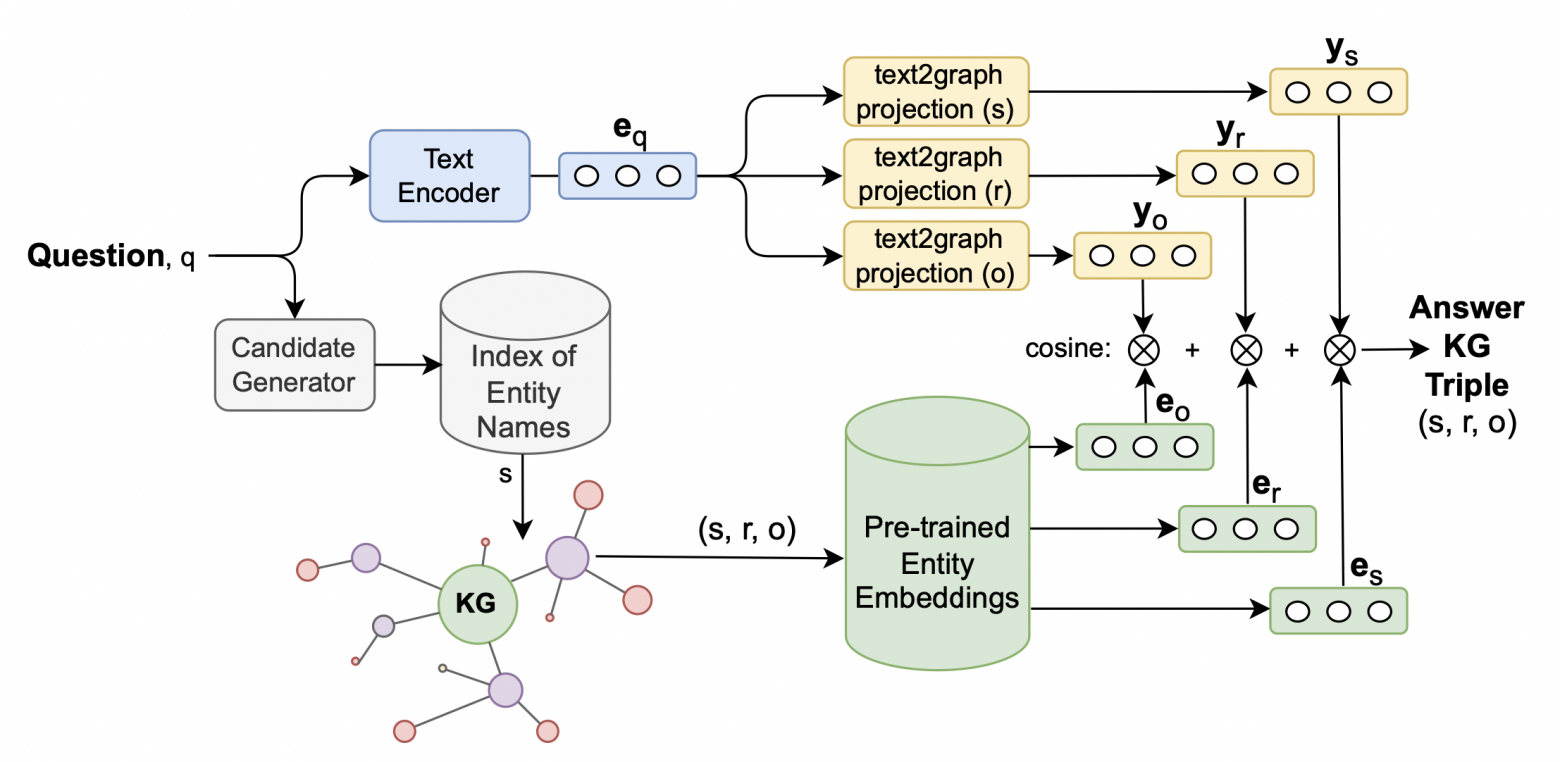
Схема работы модели M3M
Текстовый запрос кодируется при помощи mBERT (да, модель не самая свежая, но почему-то тут работает лучше других). Далее, этот текстовый эмбеддинг отображается в три отдельных вектора при помощи трёх независимых MLP. Эти три модели предсказывают эмбеддинги объекта, субъекта и предиката для триплета-ответа на данный вопрос. Таким образом, на первом этапе для каждого текстового вопроса модель M3M выдаёт три эмбеддинга описывающих ответ.
Переходя ко второму этапу, который занимается поиском ответов, стоит углубиться в особенности нашей поисковой базы данных. Мы выбрали Wikidata в качестве основы, поскольку она представляет собой огромный мультиграф, насчитывающий десятки миллиардов связей. Для этого масштабного графа существует специальный набор эмбеддингов — Pytorch Big Graph. В этом наборе каждый факт, а также все связи между ними, представлены в виде векторных репрезентаций. Эти векторы не только качественно отображают информацию, но и сохраняют расстояния в так называемом «пространстве знаний». Именно этот набор эмбеддингов служит нам поисковой базой, в которой наша система старается найти соответствия предсказанным моделью M3M эмбеддингам, сформированным на предыдущем этапе.
Поиск на втором этапе осуществляется ранжированием по косинусам между предсказанными векторами и векторами фактов из Pytorch-Big-Graph. Триплет из графа, сумма косинусов с которым самая большая — выбирается как ответ на вопрос.
Так как mBERT даёт мультиязычные эмбеддинги (близкие на всех языках), а эмбеддинги графа знаний (Pytorch-Big-Graph) вообще никак не зависит от языка — наша модель тоже получилась мультиязычной. То есть она умеет отвечать на вопросы, сформулированные на разных языках, даже если в обучении были примеры только на английском.
Подробнее об обучении и данных
M3M обучается в supervised режиме на датасете SimpleQuestionWD и эмбеддингах из Pytorch-Big-Graph (PTBG). У каждого вопроса в обучающем датасете есть триплет-ответ, для которого мы берём три эмбеддинга из PTBG и при помощи MSE-лосса обучаем M3M предсказывать их из эмбеддинга текстового энкодера.
Оценку нашего метода мы провели на нескольких датасетов (на тестовой часть):
SimpleQuestionsWD — датасет с простыми вопросами на английском языке, изначально собирался по графу знаний FreeBase, но потом, после того как Wikidata поглотила его — был повторно выровнен на неё.
RuBQ 2.0 — датасет простых вопросов (и не только) на русском языке + их переводы на английский язык. Датасет изначально завязан на граф знаний Wikidata.
Mintaka — мультиязычный датасет вопросов различных типов. Мы взяли сабсет именно простых вопросов, для которых существовал ответ в графе знаний Wikidata.
Сравнение M3M с другими моделями
Мы сравнили точность нашего подхода с GPT-3, ChatGPT, T5 и некоторыми KGQA-моделями. В качестве метрики использовали Accuracy@1, которая оценивает как часто правильный ответ возвращается первым в ранжированной выдаче систем.
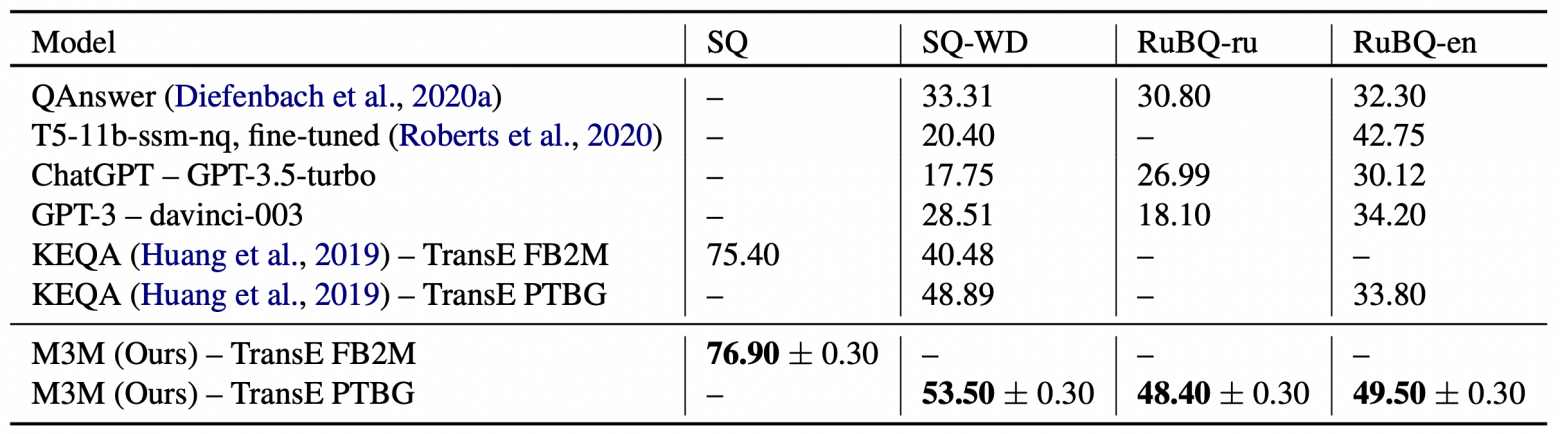
Результаты на KGQA бенчмарках
Как видно из таблицы — M3M отвечает на простые вопросы точнее, чем другие подходы, в том числе различные версии T5, GPT-3, ChatGPT, KEQA и QAnswer.

Результаты на датасете Mintaka-simple
В сравнении с T5 на датасете Mintaka, M3M показывает превосходство только на некоторых языках, достигая сопоставимой точности на остальных.
Заключение
До сих пор остаются задачи, которые простым увеличением размеров языковых моделей решить нельзя, одна из таких задач — актуализация знаний, ведь «интеллект» языковых моделей застревает на дате составления их обучающих датасетов. Самым простым решением было бы дать этим моделям доступ в интернет и позволить «гуглить» новую и актуальную информацию —, но тогда появляется риск получить недостоверные ответы. Думаю, что самый надёжный способ обойти это ограничение — опираться на верифицируемые и постоянно обновляемые графы знаний. Именно такую систему мы попробовали сделать в нашей работе — Multilingual Triple Match.
Наш проект открыт для всех на Github, подробности — в статье ACL-2023. Больше о глубоком обучении — в моем блоге @AbstractDL в Telegram.
