CAT — Управление размером кэша процессора
Архитекторы процессоров архитектуры x86 исторически были против предоставления программистам возможности непосредственного управления кэшем. Один как-то сказал мне в 2009 году — «никогда мы этого не сделаем, кэш всегда должен быть прозрачным для программиста». Некоторые RISC процессоры представляют архитектурную возможность управления данными/кодом, который окажется в кэше. И вот, наконец-то, нечто подобное появилось и в архитектуре x86 (начиная с Broadwell*).
Два года назад я написал пост о том, что кэши первого и второго уровня не совсем эксклюзивно принадлежат каждому ядру, и что политика замещения кэш-линий в L3 кэше про принципу наиболее давнего использования (pseudo-LRU) — прямой путь к инверсии приоритета (priority inversion). Читатели спрашивали, не существует ли какая-нибудь аппаратная фича, которая бы позволила бы побороть priority inversion, не позволяя низкоприоритетным процессам вытеснять данные из чужих кэшей первого и второго уровня, и не давая заховать бОльшую часть кэша третьего уровня.
Такая фича теперь есть, и называется CAT — Cache Allocation Technology. Тогда я не имел права описать эту фичу на хабре, так как официально она еще не была выпущена. Ее описание появилось в Intel® 64 and IA-32 Architectures Software Developer«s Manual, том 3, глава 17 часть 15, ее показали на IDF'15 в Сан Франциско, и в lkml давно идут дискуссии, какой интерфейс к CAT войдет в ядро Linux. Скорее всего интерфейс будет реализован через cgroups. Таким образом планировщик задач будет заботится о том, чтобы пользовательские задачи с определенным приоритетом получали определенную часть кэша.
Пока поддержка CAT еще не включена в ядро, можно пользоваться напрямую. В Linux все просто — вам понадобится установить msr-tools или аналог, и потом читать и писать в два MSR (Model Specific Register), используя # rdmsr, # wrmsr — да, надо быть root. Есть и более удобный интерфейс. В Windows несколько сложнее, можно пользоваться windbg, или найти/написать драйвер для rdmsr/wrmsr.
Далее я буду объснять на примере Xeon сервера о шестнадцати ядрах, 20-way L3 кэшем, по 2.5 мегабайта на ядро. Интерфейс очень простой. Есть 2 вида MSR:
IA32_L3_MASKn: Class of Service. Это битовая маска, где каждому биту соответствует way (не set!) кэша третьего уровня. Эти MSR’ы имеют номера 0xc90, 0xc91, и т.д. Их можно писать и читать с любого ядра, они общие для всех ядер каждого процессора.
И IA32_PQR_ASSOC (0xc8f): определяет текущий активный класс для каждого ядра. Этот MSR свой для каждого ядра.
По умолчанию, все битовые маски установлены в 1 (то есть 0xfffff в моем примере) на каждом процессоре, и IA32_PQR_ASSOC для каждого ярдра равна 0, так что фича неактивна.
Как видите, если использовать CAT без поддержки операционной системы, придется также вручную следить за соответствием между IA32_PQR_ASSOC для каждого ядра, и тем какие процессы/нити на нем работают.
Также возможен интересный «хак»: можно как-бы «залочить» данные (и/или код) в кэше, если сначала включить несколько way’ев, поместить туда данные, а потом исключить эту часть кэша из всех активных битовых маск. Тогда эти данные останутся в кэше (менять их, конечно, можно), и никто их не сможет вытеснить.
Существует интересный класс LLC side channel атак. Так как эти атаки пользуются измерением, в каком way находятся данные, то разделяя кэш между виртуалками без пересечений при помощи CAT, мы полностью защищаемся от этих классов атак.
Кэш, как известно, сделан ассоциативным не зря. Используюя CAT, мы снижаем ассоциативность. Если отдать какому-то ядру 1/10 кэша, получится, что у него «свой» L3 кэш в 4 мегабайта, 2-way. 4 Мегабайта — это неплохо, но вот 2-way это очень мало. Очевидно, будет много промахов по кэшу из-за нехватки ассоциативности. Этот эффект можно измерить. Несколько лет назад я написал пост, в котором подробно описал как при помощи cache coloring разделить на непересекающиеся части L3 кэш. У этой техники есть ряд недостатков, поэтому для этой цели в распространенных ОС и гипервизорах она не используется (есть несколько специализированных гипервизоров, где она используется, но я не могу их назвать в статье.)
Итак, небольшой микробенчмарк. Одно ядро гоняет STREAM, второе измеряет время доступа к кэш линиям. При помощи CAT и Cache Coloring мы делим кэш между ними на разного размера неперескающиеся области, и во втором тесте размер области данных изменяем пропорционально.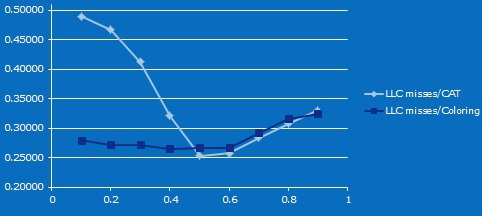
Вот результат. (По X — доля L3 второго ядра, по Y — процент промахов по кэшу на втором ядре). Признаюсь, что я точно не знаю, почему при уменьшении кэша сначала количество промахов падает (могу предположить, что это эффект, описанный в этой статье). Но начиная от 20 мегабайтов кэша 10-way, и до 4 мегабайт 2-way, очевидно, что разница в пропорции промахов по кэшу следует из уменьшения ассоциативности в случае использования CAT.
Чтобы проверить, доступна ли CAT на определенной модели процессора, есть отдельный флаг cpuid. В некоторых моделях она выключена, даже если в данном семействе CAT поддерживается. Но я предполагаю, что может найтись хакер, который обнаружит, как ее включить на любом процессоре, начиная с Haswell.
Вот и все, вкраце, что нужно знать, чтобы использовать CAT. Кроме того, CAT — часть нового семейства технологий platform quality of service, которые можно описать в отдельном посте, если интересно. Помимо CAT к ним относится CMT (Cache Monitoring Technology), которая позволяет измерять эффективность разделения общего кэша, MBM (Memory Bandwidth Monitoring), делающая то же с памятью, и CDP (Code and Data Prioritization).
