C++ против C#

Всем известно, что нет ничего глупее споров «какой язык лучше». Например, лучше для чего? Разные языки успешны в разных нишах — и бессмысленно делать категоричные выводы, не учитывая это.
Но что получится, если обратиться к опытным специалистам, которые сами всё это понимают, и попросить их всё-таки устроить холивар «C++ vs C#»? Оказывается, можно узнать много любопытных деталей. Слово «кроссплатформенный» можно по-своему применить к обоим языкам, но что это значит на практике? Активно ли сейчас развивается С++? Ломал ли C# когда-либо обратную совместимость? Ответы могут быть очевидны для тех, кто уже глубоко погружён в оба языка сразу, но таких людей немного —, а все остальные узнают что-то новое.
Со стороны C++ поучаствовал Сергей sermp Платонов — председатель программного комитета конференции C++ Russia. Сторону C# представлял Анатолий Кулаков — он входит и в ПК конференции DotNext, и в число лидеров DotNetRu. А ведущим дискуссии, в жизни которого сосуществуют оба этих мира, стал Дмитрий mezastel Нестерук.

Дмитрий: Добрый день, коллеги. Добро пожаловать на неформальные посиделки на тему языков программирования. В интернете нам постоянно напоминают, что сравнивать языки нельзя. И сегодня мы займёмся именно тем, что делать нельзя: сравним С++ с C# и .NET, их плюсы и минусы. Представьтесь, пожалуйста.
Анатолий: Меня зовут Анатолий, и я сегодня буду топить за C#, потому что я занимаюсь этим языком с первых его версий и, кажется, знаю о нём всё.
Сергей: Привет, меня зовут Сергей, я сегодня буду топить за C++. Дима правильно сказал, что сравним плюсы и минусы. «Плюсами» все называют известно что, получается, что C# в данной дискуссии будет минусом. Правильно, Анатолий?
Анатолий: У C# на два плюса больше! Поэтому я думаю, что это эволюционное развитие плюсов, которые уже морально устарели и не способны конкурировать практически нигде.

Образование
Дмитрий: У меня первый топик для нашей дискуссии. Представьте, что в университет приходят новые студенты, им нужен первый язык. Как вы считаете, каким должен быть первый язык, который люди получают на первом курсе: C++, C# или вообще ассемблер?
Сергей: Я какое-то время преподавал, поэтому у меня есть устоявшееся мнение. Понимаю, что мы здесь собрались дискутировать, какой язык лучше, и я выступаю за C++… Но для обучения C++ нужно понимать архитектуру компьютера. И с этим большая проблема преподавания у студентов (по крайней мере, в том вузе, где я преподавал). А чтобы преподавать алгоритмы и прочее, наверное, надо что-то, что не не акцентирует внимание на инфраструктуре, на самом языке. Вот Eiffel был попыткой сделать такое, но там тоже много магии. Поэтому я бы сказал, что из двух наших языков ни тот, ни другой не подходят.
Программирование — оно разное, и преподают не «программирование», а алгоритмы, структуры данных и так далее. Возможно, что имеет смысл на каждом предмете выбирать свой инструмент. По какому-нибудь Lisp разбираться со структурами данных. А C++, соответственно, давать уже после того, как студенты поймут что-то про архитектуру. И тогда можно будет понять, зачем вся эта боль и страдание. Я даже не стану спорить с тем, что плюсы — это про боль.
Анатолий: Да, я полностью согласен, что нужно разделять предметы, а не ставить это в «программирование» и одним языком всё забивать. Но если вы дойдёте до уровня, когда изучили базисы, основы, алгоритмы, и начинаете выбирать какой-то промышленный язык, то здесь, безусловно, C# будет намного лучше. Потому что он вас не заставляет учить всю эту муть на уровне архитектур, байтов памяти и прочих «закатов солнца вручную». Он даёт сразу понятный язык, простой синтаксис, и на этом языке уже с первого-второго курса можно зарабатывать вполне осязаемые деньги.
Дмитрий: Тут есть аргумент, что не давать начинающим студентам некоторые вещи вроде указателей — это какое-то кощунство. У них будет огромная дыра, если человек не понимает, что, допустим, ссылка — это на самом деле всего лишь адрес переменной в памяти. Что вы думаете по этому поводу?
Анатолий: 20 лет назад это было актуально, когда у компьютеров было недостаточно памяти, не хватало дисков и прочего. А сейчас посмотри на этих джаваскриптеров, они на каждый «hello world» притаскивают по 500 мегабайт библиотек. Сколько они занимают в памяти? Какая у них производительность? Какие там ссылки? Да никого это не волнует. Главное — это быстренько набацать и выпустить что-то в продакшн. Я не утверждаю, что это хороший или правильный путь, я утверждаю, что нужно меняться вместе с реалиями. Может быть, сейчас уже не настолько важно, сколько у тебя занимает ссылка.
Сергей: Наверное, смотря где. Дмитрий, насколько понимаю, интересовался алгоритмическим трейдингом — живо представляю, как он подтягивает библиотеки на JS, чтобы отправить заказ на биржу.
Дмитрий: Ну да, естественно, на практике там никто не использует языки такого типа. Хотя теоретически это, может, и возможно: не будем забывать, что в инфраструктуру JS вбрасываются неслабые деньги. Движки, которые делают компиляцию JS во всё и вся. Многие рассматривают этот язык как first-class language для всего вообще.
Естественно, что алготрейдинг — это сейчас удалённая от подобного дисциплина, но алготрейдинг и в целом финансовая математика — это вообще специфичная область. В ней как раз преобладает C++. И преобладает он отчасти из-за инертности, просто из-за исторических причин: в начале все были на С++, а область эта консервативная.
Сергей: Не соглашусь. Я сейчас работаю в финтехе, и коллеги, которые тут с самого начала алготрейдинга, рассказывают про крупные компании, которые сначала писали на Java. Поначалу Java справлялась с алготрейдингом, но, когда рынок стал расти и появились конкуренты с C++, они в какой-то момент просто не справились, не успели всё сделать эффективно… Так что не все в алготрейдинге начинали с C++. Просто те, кто не писал на нём, умерли. Такой естественный отбор.
Дмитрий: На самом деле можно брать шире. Известно очень много примеров, когда даже крупные банки держат свои алгоритмы в экселевском документе. Они потом используют Excel ещё и как сервер, чтобы всё это обсчитывать. Там адские тормоза, но всё зависит от того, делаешь ли ты high-frequency trading (или вообще что-то высокочастотное). Если ты market maker — естественно, что тебе нужна высокая производительность, и там дело даже не ограничивается С++, там мы уходим в железо и HDL-языки.
Но наша дискуссия не только вокруг алготрейдинга, а вокруг простых вещей тоже. Вот я приведу такой пример. Мне нужно было в связи со строительством написать несколько маленьких приложений, рассчитывающих разные вещи: например, как класть кирпичи вокруг контура дома. И я практически не представляю себе, как делать такие вещи на C++, потому что всё, что связано с UI, там слабее. Есть всего один фреймворк, Qt, и даже на нём писать очень тяжело. А если я сажусь за C#, за WinForms, то просто моментально делаю приложение.
Анатолий: Ну, визуальная часть всегда являлась сильной стороной C#. Microsoft много вкладывался и в формочки, и даже в кроссплатформенные формочки, и в целом в визуализацию. Поэтому, если мы говорим о визуальных десктопных приложениях, то мне кажется, плюсы вообще далеко-далеко позади.
Сергей: Ну, it depends, как всегда. Я UI очень не люблю, но на плюсах мне постоянно приходится его делать. Казалось бы, притащи JS и просто взаимодействуй с плюсами. Но я работал с embedded, и там это тяжело. Люди покупали какой-то быстрый дорогой движок, но он всё равно не справлялся с нормальным рендерингом UI, написанного на JS. А переписав всё это на Qt, получалось разогнать. Обыкновенная история.

Кроссплатформенность vs кроссплатформенность
Сергей: Я тут хотел уточнить. Я про C# мало знаю, сам трогал его очень давно, в самых первых версиях (мне тогда ещё обратную совместимость сломали). Поэтому вопрос:, а его до сих пор развивает только Microsoft?
Анатолий: Нет, сейчас он кроссплатформенный, открыт и заверифицирован под ISO (ECMA-334 и ISO/IEC 23270). Кстати, насколько знаю, у С++ до сих пор нет открытой ISO-спецификации, только платная. А C#, в отличие от этого, полностью открытый. Развивается многими компаниями (в их числе Google, Amazon и Samsung), у нас есть .NET Foundation. Я даже не знаю сейчас более открытого языка, чем С# и платформа его .NET.
Сергей: Ну, Haskell.
Анатолий: Кстати, автор Haskell работает в Microsoft Research и приложил немало усилий, чтобы в C# появились всякие клёвые штуки — например, статическая проверка, какая-нибудь рефлексия, о чём плюсы, вероятно, и мечтать не могут.
Сергей: Мечтать-то могут, и даже идёт работа в эту сторону. Но понятно, что у всего есть своя цена. В C++ просто отказываются платить эту цену.
Анатолий: Какую? Они компилируются по два часа, какая ещё может быть цена?
Сергей: В C++ принцип zero cost abstraction. Ну то есть виртуальная машина — это не zero cost abstraction, правильно? Приходится с этим мириться.
Дмитрий: Ну, зато виртуальная машина может, например, затюнить код для той или иной архитектуры. В то время как на С++, если использую AVX-инструкцию на компьютере без AVX, у меня процесс просто накрывается. Я бы сказал, что этот аргумент не совсем корректен, потому что теоретически — я подчеркну, теоретически — JIT может делать то, что C++ недоступно. А именно оптимизацию в момент запуска.
Сергей: Но в C++ во время компиляции ты можешь полностью контролировать, какие инструкции тебе нужны. В данном случае не руками управляешь, а инструменту (компилятору) отдаёшь на откуп. Вот смотри, какие инструкции есть на этой архитектуре, какой набор инструкций…
Дмитрий: Это понятно. Но можно сформулировать так: поскольку платформ миллион, мы никогда не получим какой-то идеал, потому что мы не можем релизить миллион версий с разными компиляционными флагами. Правильно? Мы выпускаем обычно x86 и x64, а не разбиваем всё это на какие-то подгруппы.
Сергей: Почему не можем? XXI век. Держи Docker с разными параметрами, и всё.
Дмитрий: Когда у нас есть конечный клиент, который скачивает наше приложение, он хочет скачать конкретный бинарник. И в этом бинарнике лучшее, что мы можем сделать — это натыкать везде if. Типа «if cpuid такой-то и поддержка avx такая-то, тогда используем версию алгоритма 25». В результате нам нужно 25 разных версий одного и того же алгоритма, потому что ускорение зависит от платформ, оно platform-dependent.
Сергей: Наверное, согласен. Просто я, если честно, ни разу не создавал не-внутренний продукт. Я в основном в компаниях, которые сами используют свой продукт.
Дмитрий: Ну, конечно, самый лучший вариант, когда ты предсказуемо знаешь архитектуру. В этом случае, строго говоря, вообще никто не заставляет тебя использовать x86-инструкции. Можешь брать конкретную карточку (например, Nvidia Tesla) и делать всё, что хочешь. Это и мой подход тоже, я контролирую свою архитектуру. Но когда ты делаешь mass-market решения для пользователя… Если взять какой-нибудь условный ReSharper, он не может просто взять и использовать GPU-ускорение для каких-нибудь произвольных индексов. Потому что GPU-ускорение — это не портативная штука.
Сергей: На самом деле есть подходы (сейчас в детали, наверное, вдаваться не нужно), есть интересные ребята (автор подхода, кажется, сейчас тоже в Microsoft перешёл). Вот у нас на конференции в позапрошлом году был доклад про то, как бы написать такую программу, которая сама будет разбираться, что где (относительно легко, опять же zero cost abstractions). Чтобы на лету можно было выбирать, и если что, грамотно перестраивать код в CUDA-стиль…
Дмитрий: На самом деле CUDA сама пытается решить эту проблему, потому что в CUDA есть некий промежуточный слой PTX, который этим занимается. Но это пока всё очень тяжело, потому что железо кардинально меняется эволюционно, и очень сложно за этим вообще поспевать. И если мы посмотрим на использование GPU-ускорения, например, в продуктах Adobe, то они используют очень узкий срез имеющихся технологий. Если у тебя карточка правильная — то да, всё будет. Но если она чуть-чуть экзотическая — в этом плане уже не гарантировано ничего.
Анатолий: В этой дискуссии мы затронули довольно важную тему, такой миф: C++ декларировался много лет назад как такой кроссплатформенный язык, но на данный момент кроссплатформенности куда больше в C#. Один-единственный бинарник, работает везде, где поддерживается .NET, а это практически везде.
Сергей: Ну, это тоже достаточно голословно. Я как человек, большую часть жизни проведший в embedded, редко видел, чтобы .NET поддерживался тулчейном производителя железа. Компании, которые производят железо, берут тот же G++ или Clang или делают так, чтобы он начинал генерировать код для их платформы.
Дмитрий: Да, но проблема в том, что каждый раз, когда они это делают, они теряют что-то из С++. Например, Nokia использовала вариацию C++, но их C++ был с безумными наворотами и безумным API, которое всех бесило. То есть это не просто С++, а С++ под ту или иную платформу. И тогда начинаются проблемы. Например, взять ту же CUDA. Она как бы должна плюсы просто через себя пропускать, она вообще не компилятор, а просто драйвер. Но несмотря на это, у неё бывают затыки с тем, что она всё-таки использует какой-то фреймворк для раздирания CUDA-файлов на GPU- и CPU-части. И иногда у неё это не получается.
Сергей: Я немножко не это имел в виду. Просто, когда я слышу, что ».NET везде запускается», большая часть моей рабочей биографии взбрыкивается. Когда ты покупаешь железку с кастомным процессором, она просто идёт в комплекте с поставкой G++. И там обыкновенный C++, который G++ из тулчейна умеет преобразовывать в машинный код, поддерживаемый именно этим процессором.
Дмитрий: Но это опять надо пересобирать…
Сергей: Конечно.
Дмитрий: И идея, что мы берём уже существующий плюсовый код и втаскиваем его на железку — эта идея тоже не работает, потому что внезапно ты втащил свой обычный x86 куда-то, где у тебя 8 гигабайт памяти на всё про всё, и уже не развернуться: например, нет свопа на диск, потому что нет диска и доступа к нему. Это если мы про портативность. Зависит от целей, естественно.
Анатолий: Плюсы работают на большем количестве устройств, и, безусловно, embedded — это одна из сильнейших частей. Но обычно придётся как-то под платформу свой код адаптировать. Вот это плохо. Я могу одним кодом накрыть огромное число платформ, архитектур, моделей. На плюсах мне приходилось думать о каждой отдельной платформе:, а где он там запустится, а при каких условиях. И это очень плохо, это очень сдерживает.

Стабильность, совместимость, развитие языка
Дмитрий: Ещё были упомянуты zero cost abstractions, но проблема в том, что у этого огромная цена. Например, в .NET есть понятие перечисляемого типа и интерфейс IEnumerable. И у каждого типа, например, массива, можно взять и проходить по итератору. А в C++ такой идеи нет. Из-за zero cost abstraction, чтобы обойти коллекцию, есть пара begin () и end (), есть правила их работы, и всё это намного сложнее (особенно для тех, кто начинает программировать). Это прямо проблема: как обойти какой-нибудь массив «от А до Я».
Сергей: Если я правильно понимаю, о чём вы говорите… Если просто нужно обойти какой-то контейнер от начала до конца, то сейчас просто пишешь, как в каком-нибудь Питоне.
Дмитрий: Это всё прекрасно. Но у тебя, например, нет использования полиморфизма для этого. Ты не можешь сказать, что вот у меня функция, которая получает некое значение, которое является перечисляемым априори. Ты не можешь сказать, что вот у меня есть значение, которое реализует интерфейс, и вот в этом интерфейсе есть итератор, например.
Сергей: Мы говорим про какой C++? Про C++ вообще, C++ будущего, С++, который сейчас принимают в стандарт?
Дмитрий: Ну, если в плюсах будущего это будет…
Сергей: В C++20 это уже есть. Уже можно сказать, уже можно самому даже объявлять. Это не интерфейсы, но, как правильно сказать… В общем, можешь объявить, что у тебя тип должен удовлетворять таким-то условиям. Например, у него begin и end, которые возвращают итератор. А итератор — это в стандартной библиотеке такой подготовленный концепт. Он говорит, что это такое, описывает. Итераторы тоже разные бывают. В общем, стараемся, делаем так, чтобы людям было удобнее.
Дмитрий: Мне кажется, это выросло из того, что люди просто поняли, что без концепций итерируемости объекта жить тяжело. Потому что непонятно, как писать обобщённые вещи. Да, zero cost abstraction означает, что у нас нет затрат на хождение по v-table при поиске… В .NET есть просто конкретный метод, например. И нам, чтобы его найти, естественно, приходится затратить усилия, от которых плюсы отказываются. Но с точки зрения юзабельности всё-таки конечный результат не такой хороший, я бы сказал.
Сергей: Естественно, должен быть баланс. Нельзя иметь всё и сразу.
Анатолий: Это заставляет задуматься: сколько лет прошло. Альтернативные языки развиваются, и в них такие базовые вещи появляются с самого начала. Сейчас они догоняют что-то более существенное и интересное. А плюсовики сидят по десять лет с одним и тем же непонятным синтаксисом, непонятными абстракциями, непонятными костылями и слабо развиваются. Можно это поставить как один из минусов.
Сергей: Ну come on! Что значит «слабо развивается»?
Ты упоминал комитет — у C++ тоже есть комитет ISO, который его развивает. Там есть представители в том числе Microsoft, которые сильно топят за то, что «нельзя такое делать, потому что у нас куча легаси, которое нам надо поддерживать». Просто C++ — это язык уже состоявшийся. И, естественно, очень аккуратно шагает. Одна из главных задач (что было декларировано ещё Страуструпом при создании) — это совместимость с C. Но сейчас C уже даже развился достаточно далеко, приходится обозначать, с каким именно C совместимость.
И на мой взгляд, сейчас C++ развивается огромными темпами. По поводу концептов и так далее — на самом деле всё растёт, конечно, не из итерируемости. На самом деле развитие идёт по тому, что описал ещё Александр Степанов — один из авторов того, что мы сейчас называем «обобщённое программирование», тот человек, который фактически втащил в C++ шаблоны, дженерики и так далее. Если честно, не знаю, насколько именно комитет вдохновляется этими идеями, но мне кажется, что какое-то пересечение с ними точно есть.
Анатолий: Кажется, что все эти метаклассы, итераторы — это реально вдохновение, которое было уже много десятков лет назад. Даже если метапрограммирование взять, шаблоны, макросы — это же всё люди давно пережили, перемололи, и существуют намного более простые, очевидные, понятные концепции. В других языках это всё сделано в миллион раз лучше и быстрее, с типобезопасностью, проверкой в compile time и так далее.
Сергей: Подожди, ты уже говоришь про то, за что не все готовы платить. Я не хочу, чтобы моя программа что-то проверяла в compile time без моего ведома. Понимаешь?
Анатолий: Я думаю, это всё флажочками можно настроить. Уровень оптимизации ставишь, и она тебе или проверяет, или нет. Это не проблема.
Сергей: Часто нужно контролировать всё руками. Точно знать, что происходит. Потому что инструменты — ну такое.
Дмитрий: Тут даже не про инструменты. Тут тот факт, что языки вроде D и Rust, допустим, говорят: ну вот да, есть такая фишка, что когда доступ к элементу массива, можно его проверять, а можно не проверять. И они просто отдают это на откуп пользователя, то есть ты можешь сказать «а давайте отключим проверки массивов», «а давайте включим». То есть контроль какой-то в этом плане.
Сергей: Непонятно тогда, когда у тебя Unsafe и Safe есть, как в Rust, я не вижу разницы с C, например, в таком случае.
Анатолий: Разница в том, что ты можешь писать безопасно, а можешь писать быстро. А в C ты вынужден писать опасно. Ну, да, может быть, быстро. Иногда намного важнее стабильность продукта, чем быстрота.
Дмитрий: На самом деле, если уж мы начнём копать вот тему с новыми языками, в С++ есть такие вещи, которые вообще очень тяжело донести до людей. Простой вопрос: какого размера int? В большинстве языков ты знаешь ответ на этот вопрос. Ты говоришь: int — это 32 бита. А в плюсах не знаешь. Ты знаешь размер на своём конкретном компьютере, потому что запомнил, но, строго говоря, даже базовые типы не хочется использовать, потому что они недетерминированные. И вот меня бесят такие вещи, когда есть набор легаси-подходов вроде того, что int будет разным на разных платформах. И сейчас-то мы уже понимаем, что так делать нельзя. Почему бы не шагнуть дальше этого и как-то решить эту проблему?
Сергей: Ну, это решено. Есть STD, нужные типы с фиксированной длиной. Сейчас представитель России в комитете втаскивает int переменной длины (ну опять же, с zero cost abstraction).
Анатолий: А я правильно помню, что там даже недетерминированный размер указателя на метод? То есть под разные компиляторы и разные платформы указатели разные?
Сергей: Естественно, это архитектура. Когда ты близко к железу, как ты можешь гарантировать размер указателя, если ты то на 8-битной, то на 64-битной?
Анатолий: И как можно после этого какую-то арифметику на указателях делать? Это же с ума сойти.
Сергей: В смысле? Ну, аккуратно.
Анатолий: Понятно. Подход везде понятен, аккуратно, ручками контролируя всё.
Сергей: Ну да. Опять же, в современных стандартах C++ развиты подходы… Если говорить о выборе, то в современных плюсах, по сути, есть выбор, использовать ли сборщик мусора. Просто GC там построен на reference counter-ах.
Вообще, по вашим словам, коллеги, я, простите, чувствую, что вы давно не обновляли знания про современные плюсы.
Сейчас от людей вроде Страуструпа, входящих в пантеон плюсовых богов, исходит много призывов разобраться с тем, как преподавать современный C++. Проблема в том, что люди думают в категориях C++ 2003 года, и преподают в этих же категориях. И в связи с этим есть интересные новые проекты и подходы, есть современные курсы — скажем, ребята из Яндекса сделали прекрасный курс. И сейчас в плюсах считается моветоном, например, использовать чистые new и delete.
Дмитрий: Насчёт твоего комментария про обновление знаний… Нюанс в том, что мой подход, например — использовать маленькую дельту C++, которая у меня гарантированно работает и с которой я «дружу». Понимаешь, C++ обширен. Есть шаблонное метапрограммирование, и всё бы хорошо, там много магии, но, к сожалению, эта магия нечитабельная. Это код, в котором не-автору без каких-то особых знаний не разобраться, в каком-то смысле чёрный ящик. И вот таких чёрных ящиков в плюсах много, таких областей тьмы, которые не переварить… Хочется, чтобы, не знаю, твой опцион обсчитывался предсказуемо, хорошо и без каких-либо ухищрений.
Самый простой пример — разговор про ranges (range-v3 и вся эта тема). С одной стороны, всё это здорово: появляются вещи, которые в C# уже были несколько лет, позволяющие, например, построить календарик путём всяких преобразований стандартной коллекции. С другой стороны, то, как это реализовано в С++, просто неприятно по сравнению с C#: оно тяжело, неудобочитаемо.
Сергей: Это вкусовщина. Мне, наоборот, нравится. Я так понимаю, ты к докладу Ниблера и его представлению…
Дмитрий: Понимаешь, когда для фильтрации коллекции используется оператор «или», у меня сразу к этому вопросы. И C#, и Java всё сделали через точку, через обычные методы.
Сергей: А мне кажется, это вдохновлено Bash’ем. То есть это просто pipe.
Дмитрий: Ну, да, наверное, это объясняет что-то в этом подходе.
Сергей: Многое объясняет! Давайте вот про PowerShell поговорим, раз заговорили про Bash. Кто видел PowerShell?
Анатолий: Я пишу на PowerShell, шикарный язык. Но опять же, pipe нужно вставлять там, где он к месту, там, где вся архитектура им пронизана. Не там, где тебе нужно сделать какое-то одно действие, и оно здесь идиоматически плохой синтаксис.
Сергей: В range’ах pipe как раз очень…
Дмитрий: В range они используются, по-моему, по следующей причине… Скажу так: если бы в C++ были extension-методы или extension-функции, использовали бы их, конечно. Потому что самое естественное, если вам нужно отсортировать коллекцию — это написать «коллекция.фильтр ()». А не «коллекция | view: фильтр ()».
Анатолий: У меня тоже сложилось такое впечатление, что тебе 20 лет стреляли в ноги, били по лицу, стучали головой о стену, а потом в конце концов говорят: «Ну вот мы теперь всё сделали красиво в 20-м стандарте, давайте теперь учить плюсы правильно». Да уже никто не хочет их учить правильно! То есть это боль многолетняя.
Сергей: Пожалуйста, не учите. В чём проблема? Пишите на C# — торгуйте на нём, пишите embedded. Я не против.
Анатолий: Ну, есть узкие ниши, где плюсы всё ещё остались.
Сергей: Embedded — «узкая ниша»… Я прямо сейчас, глядя у себя на кухне по сторонам, вижу кучу компьютеров.
Дмитрий: Я каждый раз, когда лечу на самолёте, думаю: «Блин, надеюсь, эти плюсовики хорошо всё там написали».
Сергей: Ну, кстати, там в основном Ada, насколько я помню.
Дмитрий: Ada там доминирует, да.
Анатолий: Мне, кстати, недавно попалась отличная статейка, где автор на разных языках (около 10) написал низкоуровневый драйвер — network driver для 10-гигабитной карточки Intel. От C до Swift, JS, Python и, естественно, C#. Если мы посмотрим на эти графики, которые у него получились, то C# на больших батчах (когда нивелируются расходы на запуск) идёт вровень с C и Rust.
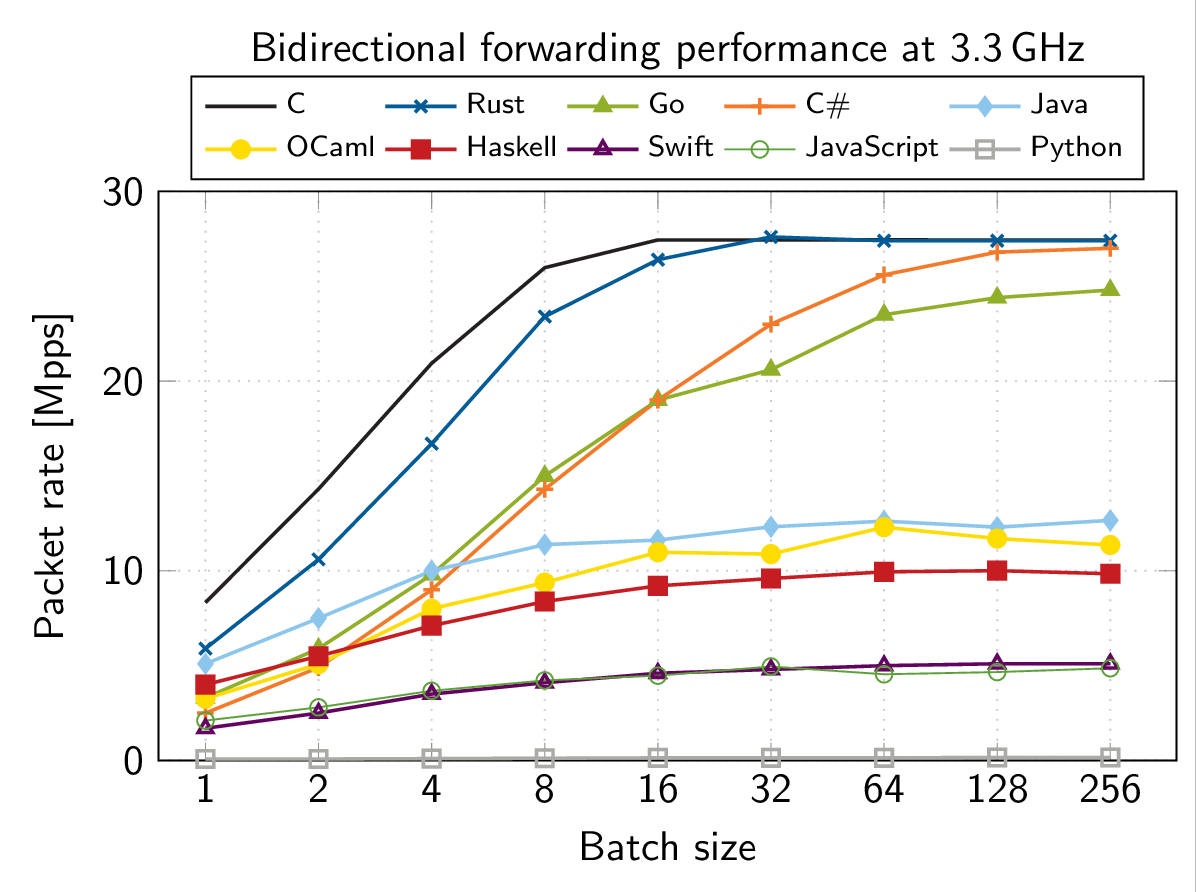
То есть, если мы говорим о производительности, может быть заблуждением, что C# очень сильно где-то уступает. Есть ещё обалденный доклад Федерико Луиса Scratched Metal, где он показывал, как оптимизировал C#-код под процессорные профайлеры.
Сергей: Ну это опять начинается. Штука в том, что когда ты начинаешь оптимизировать что Java, что C#, становится непонятно, почему не писать на плюсах. Потому что тебе нужны специфичные знания. И, как мне кажется, нивелируется преимущество языков вроде C# и Java — не очень высокий порог входа. Насколько понимаю, как раз то, про что Дмитрий говорил: про читаемость кода, что учить много, тяжело объяснять какие-то концепции и так далее.
Анатолий: Я на работе 99% времени пишу на «нормальном» С# — безопасном, стабильном и всё время работающем. А 1% времени я хочу написать какой-то быстрый низкоуровневый код. И это C# мне тоже позволяет. Но основной мой инструмент — это всё-таки стабильный, читабельный, без ошибок…
Дмитрий: Толя, давай я приведу тебе простой пример: векторизация. С векторизацией в .NET всё очень плохо, несмотря на то, что медленно пилится System.Numerics.Vectors. И к чему это приводит, с моей стороны, например? К тому, что если суёшься на рынок и покупаешь математическую библиотечку для .NET, она написана на плюсах (с дотнетной обёрточкой). Потому что в .NET нет практически никакого доступа к аппаратному ускорению (AVX и прочее), это сейчас на каком-то зачаточном этапе.
Анатолий: В .NET Core 3 вышли интринсики, где можно напрямую обращаться к AVX. Они там действительно в зачаточном состоянии, но базовые вещи есть, а остальное вполне двигается.
Дмитрий: Ты понимаешь, у нас 2019 год на дворе. Я как пользователь всего этого математического ускоренного добра не дождался этого. И в результате для меня, если хочу что-то быстро считать, C# уже не кандидат. Потому что библиотеки на C++ уже есть. Может, уже время упущено для этого.
Анатолий: Мне кажется, что C# движется в сторону плюсов, он пытается отвоевать их рынок. А вот плюсы уже не движутся никуда.
Сергей: Откуда это? Что значит «плюсы не движутся никуда»?
Анатолий: Когда мне в 2019 году рассказывают, что в будут стандарте будут итераторы, будут какие-то подвижки насчёт лямбд, мне кажется, что…
Сергей: Я не знаю, зачем ты разговариваешь про итераторы и лямбды, не понял, в чью сторону был камень…
Анатолий: Не про итераторы, я неправильно выразился, я имел в виду enumerable’ные контейнеры, которые мы до этого обсуждали. А у нас тем временем появился pattern matching.
Сергей: Всё зависит от того, надо это или нет. У нас pattern matching обсуждают. Но пока нет всех аргументов, нужен ли он именно в плюсах.
Дмитрий: Я слышу много подобных комментариев от плюсовиков, которые говорят, что «хотя уже есть очевидное присутствие того или иного подхода в других языках, он уже отработан, люди его любят и строят на нём решения, мы всё равно не хотим это в плюсах, потому что это не идиоматично плюсам». И мне кажется, что Java попала в ту же дыру. Java сказала «нет, ребята, у нас делегатов не будет». И в Java до сих пор нет понятия делегатов, а в .NET всё это прекрасно работает.
Сергей: Смотри, в плюсах всё очень просто. Опять же, возвращаемся к комитету. Там есть верхушка — это люди, которые занимаются разработкой компиляторов. И для них слова «zero cost abstraction» — это как раз то, чем они должны руководствоваться. И словом «legacy», к сожалению.
Дмитрий: Ну, zero cost abstraction — это ассемблер. Если мы хотим вообще zero cost abstraction, надо писать всё на ассемблере.
Сергей: Там нет abstraction.
Дмитрий: Ассемблер — это абстракция над бинарным кодом. Просто это второе поколение, а не третье.
Сергей: Так вот, про всякие «удобные штуки» оказывается, что непонятно, как заставить их быстро работать.
Дмитрий: Пускай они работают медленнее. Идея с асинхронными итераторами, корутины, всё вот это — в .NET с C# ключевое слово yield уже не знаю сколько релизов прекрасно работает. Да, за кулисами строятся огромные стейт-машины, прям магия. Но и в async/await строится магия, и в итераторах. Но все этим пользуются, и это реально удобно.
Сергей: Корутины и в плюсы добавляют, здравствуйте.
Дмитрий: Ну да, прогресс идёт. Но корутины появляются сейчас, а не 10 лет назад.
Сергей: Ещё раз. Плюсы старше, и на мой взгляд, скорость развития падает с накоплением кодовой базы. Понятно, всё зависит от того, есть ли желание сохранять поддержку легаси. Для плюсов это принципиальная позиция. То есть код, который ты написал в 80-х, сейчас скомпилируешь современным компилятором.
Дмитрий: Да, но код, который ты написал на C# 1.0, ты тоже скомпилируешь современным компилятором.
Сергей: Это неправда. Я в самом начале дискуссии сказал, что у меня на ранних версиях .NET прилетело обновление, и внезапно все программы перестали работать.
Дмитрий: Возможно, просто поменялось API, которые ты использовал. Тут нужно разделять библиотеки и язык программирования.
Сергей: У меня ничего не было, просто C#. Я был молодой, это были первые годы.
Дмитрий: Я помню только один breaking change, в C# 4 — изменение поведения foreach чуть-чуть. Конечно, в версиях 1.x всё могло быть более турбулентно, но сейчас мы точно не в такой фазе, когда кто-то что-то внезапно ломает.
Анатолий: Ну и официально Microsoft придерживается позиции, что строго следит за обратной совместимостью, они тестируют новые версии на огромном количестве машин и кодовых баз. Возможно, у тебя был баг или что-то в этом духе.
Дмитрий: В общем, в .NET тоже следят за обратной совместимостью, но скорость прогресса обскакала и C++, и Java.
Сергей: Мне кажется, сыграло большую роль, что вначале всё это драйвила одна компания. Потому что C++ изначально в комитете —, а это политика, каждый пытается протащить своё решение, и это как заседание Сената в «Звёздных войнах».
Дмитрий: То есть твой аргумент в том, что мы все заложники комитетов, которыми движет не инновация?
Сергей: Проблема в том, что не выбрать решение, которое удовлетворит всех. Инструмент настолько широко разошёлся, что его использует очень много компаний. Ты те же корутины вспомнил: почему их приняли поздно? Потому что Microsoft, кажется, с Google не мог договориться. Были две имплементации — я не помню, кто был за stackful, а кто за stackless, но не могли договориться. Потому что обе компании большие, у них огромные кодовые базы, которые уже содержат решение, и они отказываются это переписывать.
Дмитрий: С точки зрения читателя создастся ощущение, что на него плевали с высокой колокольни, потому что есть corporate interests, они занимаются там междусобойчиками, а вас всё это как бы и не касается — идите, холопы, «let them eat cake».
Сергей: Всё как раз наоборот. Комитет пытается выбрать так, чтобы обыкновенному человеку не пришлось страдать. И часто это тяжело.
Дмитрий: Ну, я за себя могу сказать, что не буду страдать, если где-то пропадёт прям zero cost, зато появится какая-нибудь гибкая возможность ходить по бинарному дереву и делать итерирование разными способами без временных переменных. Если внезапно появилось ключевое слово yield, которое за собой тащит стейт-машину или ещё что-то — я готов на это, потому что знаю, что выигрыш от этого будет больше, чем то, чт
