Быстрый ENUM
tl; dr
github.com/QratorLabs/fastenum
pip install fast-enumЗачем нужно перечисление (enum)
(если вы все знаете — опуститесь до секции «Перечисления в стандартной библиотеке»)
Представьте, что вам нужно описать набор всех возможных состояний сущностей в собственной модели базы данных. Скорее всего, вы возьмёте пачку констант, определенных прямо в пространстве имен модуля:
# /path/to/package/static.py:
INITIAL = 0
PROCESSING = 1
PROCESSED = 2
DECLINED = 3
RETURNED = 4
...
… или как статические атрибуты класса:
class MyModelStates:
INITIAL = 0
PROCESSING = 1
PROCESSED = 2
DECLINED = 3
RETURNED = 4
Такой подход поможет сослаться на эти состояния по мнемоническим именам, в то время как в вашем хранилище они будут представлять собой обычные целые числа. Таким образом вы одновременно избавляетесь от магических чисел, разбросанных по разным участкам кода, заодно делая его более читабельным и информативным.
Однако, и константа модуля, и класс со статическими атрибутами страдают от внутренней природы объектов Python: все они изменяемы (мутабельны). Можно случайно присвоить значение своей константе во время выполнения, а отладка и откат сломанных объектов — отдельное приключение. Так что вы можете захотеть сделать пачку констант неизменяемыми в том смысле, что количество объявленных констант и их значения, на которые они отображаются, не будут изменяться во время выполнения программы.
Для этого вы можете попробовать организовать их в именованные кортежи с помощью namedtuple(), как в примере:
MyModelStates = namedtuple('MyModelStates', ('INITIAL', 'PROCESSING', 'PROCESSED', 'DECLINED', 'RETURNED'))
EntityStates = MyModelStates(0, 1, 2, 3, 4)
Но выглядит такое не очень опрятно и читаемо, а объекты namedtuple, в свою очередь, не очень то расширяемы. Допустим у вас есть UI, отображающий все эти состояния. Вы можете использовать свои константы в модулях, класс с атрибутами или именованные кортежи для их рендеринга (последние два рендерить легче, раз уж об этом зашла речь). Но такой код не дает возможности предоставить пользователю адекватное описание для каждого определенного вами состояния. Помимо этого, если вы планируете внедрить поддержку мультиязычности и i18n в своем UI, вы придете к осознанию, как быстро заполнение всех переводов для этих описаний становятся невероятно утомительной задачей. Совпадение имен состояний не обязательно будет означать совпадение описания, что означает, что вы не сможете просто отобразить все свои INITIAL состояния в одно и то же описание в gettext. Вместо этого ваша константа принимает следующий вид:
INITIAL = (0, 'My_MODEL_INITIAL_STATE')
Или же ваш класс становится таким:
class MyModelStates:
INITIAL = (0, 'MY_MODEL_INITIAL_STATE')
Наконец, именованный кортеж превращается в:
EntityStates = MyModelStates((0, 'MY_MODEL_INITIAL_STATE'), ...)
Уже неплохо — теперь он гарантирует, что и значение состояния и заглушка перевода отображаются на языки поддерживаемые UI. Но вы можете заметить, что код, использующий эти отображения, превратился в бардак. Каждый раз, пытаясь присвоить значение сущности, приходится извлекать значение с индексом 0 из используемого вами отображения:
my_entity.state = INITIAL[0]или
my_entity.state = MyModelStates.INITIAL[0]или
my_entity.state = EntityStates.INITIAL[0]
И так далее. Помните, что первые два подхода, использующие константы и атрибуты класса, соответственно, страдают от изменяемости.
И вот перечисления приходят к нам на помощь
class MyEntityStates(Enum):
def __init__(self, val, description):
self.val = val
self.description = description
INITIAL = (0, 'MY_MODEL_INITIAL_STATE')
PROCESSING = (1, 'MY_MODEL_BEING_PROCESSED_STATE')
PROCESSED = (2, 'MY_MODEL_PROCESSED_STATE')
DECLINED = (3, 'MY_MODEL_DECLINED_STATE')
RETURNED = (4, 'MY_MODEL_RETURNED_STATE')
Вот и все. Теперь вы можете легко перебирать перечисление в вашем рендере (синтаксис Jinja2):
{% for state in MyEntityState %}
{% endfor %}
Перечисление является неизменяемым как для набора элементов — нельзя определить новый член перечисления во время выполнения и нельзя удалить уже определенный член, так и для тех значений элементов, которые он хранит — нельзя [пере]назначать любые значения атрибута или удалять атрибут.
В вашем коде вы просто присваиваете значения вашим сущностям, вот так:
my_entity.state = MyEntityStates.INITIAL.val
Все достаточно понятно, информативно и расширяемо. Вот для чего мы используем перечисления.
Как мы смогли сделать его быстрее?
Перечисление из стандартной библиотеки довольно медленное, поэтому мы спросили себя — можем ли мы ускорить его? Как оказалось — можем, а именно, реализация нашего перечисления:
- В три раза быстрее по доступу к члену перечисления;
- В ~8,5 быстрее при доступе к атрибуту (
name,value) члена; - В 3 раза быстрее при доступе к члену по значению (вызов конструктора перечисления
MyEnum(value)); - В 1.5 раза быстрее при доступе к члену по имени (как в словаре
MyEnum[name]).
Типы и объекты в Python являются динамическими. Но существуют и инструменты для ограничения такой динамической природы объектов. Можно получить существенное повышение производительности с помощью __slots__. Также существует потенциал выигрыша в скорости, если избегать использования дескрипторов данных там, где это возможно —, но необходимо учитывать возможность значительного роста сложности приложения.
Slots
К примеру, можно использовать объявление класса с помощью __slots__ — в этом случае все экземпляры классов будут иметь только ограниченный набор свойств, объявленных в __slots__ и всех __slots__ родительских классов.
Descriptors
По умолчанию интерпретатор Python возвращает значение атрибута объекта напрямую (при этом оговоримся, что в данном случае значение — это тоже объект Python, а не, например, unsigned long long в терминах языка Си): value = my_obj.attribute # это прямой доступ к значению атрибута по указателю, который объект хранит для этого атрибута.
Согласно модели данных Python, если значение атрибута является объектом, реализующим протокол дескрипторов, то при попытке получить значение этого атрибута интерпретатор сначала разыщет ссылку на объект, на который ссылается свойство, а затем вызовет у него специальный метод __get__, которому передаст наш исходный объект в качестве аргумента:
obj_attribute = my_obj.attribute
obj_attribute_value = obj_attribute.__get__(my_obj)Перечисления в стандартной библиотеке
По меньшей мере свойства name и value членов стандартной реализации перечислений объявлены как types.DynamicClassAttribute. Это значит что когда вы попытаетесь получить значения name и value произойдет следующее:
one_value = StdEnum.ONE.value # это то что вы пишете в коде
# а это то, что произойдет вкратце в действительности
one_value_attribute = StdEnum.ONE.value
one_value = one_value_attribute.__get__(StdEnum.ONE)# и это то, что __get__ делает на самом деле (в реализации python3.7):
def __get__(self, instance, ownerclass=None):
if instance is None:
if self.__isabstractmethod__:
return self
raise AttributeError()
elif self.fget is None:
raise AttributeError("unreadable attribute")
return self.fget(instance)# так как DynamicClassAttribute является декоратором над методами `name` и `value` стек вызовов __get__() заканчивается на:
@DynamicClassAttribute
def name(self):
"""The name of the Enum member."""
return self._name_
@DynamicClassAttribute
def value(self):
"""The value of the Enum member."""
return self._value_
Таким образом, вся последовательность вызовов может быть представлена следующими псевдокодом:
def get_func(enum_member, attrname):
# тут на самом деле идет поиск в __dict__, таким образом вычисления хеша и поиск в хеш-таблице тоже имеют место быть
return getattr(enum_member, f'_{attrnme}_')
def get_name_value(enum_member):
name_descriptor = get_descriptor(enum_member, 'name')
if enum_member is None:
if name_descriptor.__isabstractmethod__:
return name_descriptor
raise AttributeError()
elif name_descriptor.fget is None:
raise AttributeError("unreadable attribute")
return get_func(enum_member, 'name')
Мы написали простой скрипт демонстрирующий вывод, описанный выше:
from enum import Enum
class StdEnum(Enum):
def __init__(self, value, description):
self.v = value
self.description = description
A = 1, 'One'
B = 2, 'Two'
def get_name():
return StdEnum.A.name
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
graphviz = GraphvizOutput(output_file='stdenum.png')
with PyCallGraph(output=graphviz):
v = get_name()
И после выполнения скрипт выдал нам следующую картинку: 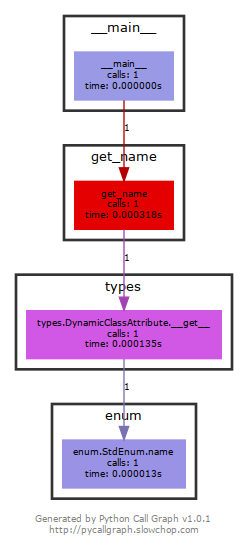
Это показывает, что каждый раз, когда вы обращаетесь к атрибутам name и value членов перечислений из стандартной библиотеки, вызывается дескриптор. Этот дескриптор, в свою очередь, завершается вызовом из класса Enum из стандартной библиотеки метода def name(self), декорированного дескриптором.
Сравните с нашим FastEnum:
from fast_enum import FastEnum
class MyNewEnum(metaclass=FastEnum):
A = 1
B = 2
def get_name():
return MyNewEnum.A.name
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
graphviz = GraphvizOutput(output_file='fastenum.png')
with PyCallGraph(output=graphviz):
v = get_name()
Что видно на следующем изображении: 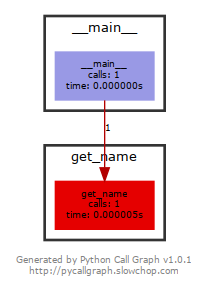
Все это действительно происходит внутри стандартной реализации перечислений каждый раз, когда вы обращаетесь к свойствам name и value их членов. Это же и причина, по которой наша реализация быстрее.
Реализация перечислений в стандартной библиотеке Python использует множество обращений к объектам, реализующим протокол дескрипторов данных. Когда мы попытались использовать стандартную реализацию перечислений в наших проектах, мы сразу же заметили, сколько было вызвано дескрипторов данных у name и value.
А поскольку перечисления использовались довольно обширно по всему коду, результирующая производительность была низкой.
Кроме того, стандартный класс Enum содержит несколько вспомогательных «защищенных» атрибутов:
_member_names_— список, содержащий все имена членов перечисления;_member_map_—OrderedDict, который отображает имя члена перечисления на его значение;_value2member_map_— словарь, содержащий сопоставление в обратную сторону: значения членов перечисления в соответствующие члены перечисления.
Поиск по словарю медленный, поскольку каждое обращение приводит к вычислению хеш-функции (если, конечно, не кешировать результат отдельно, что для неуправляемого кода не всегда возможно) и поиску в хеш-таблице, что делает эти словари не оптимальной основой для перечислений. Даже сам поиск членов перечислений (как в StdEnum.MEMBER) является поиском по словарю.
Наш подход
Свою реализацию перечислений мы создавали с оглядкой на элегантные перечисления в C и прекрасные расширяемые перечисления в Java. Основные функции, которые мы хотели реализовать у себя, были следующими:
- перечисление должно быть как можно более статическим; под «статическим» здесь подразумевается следующее — если что-то может быть вычислено только один раз и во время объявления, то оно должно быть вычислено в этот (и только в этот) момент;
- от перечисления нельзя наследоваться (оно должно быть «конечным» классом), если наследующий класс определяет новые члены перечисления — это верно для реализации в стандартной библиотеке, за тем исключением, что там наследование запрещено, даже если наследующий класс не определяет новых членов;
- перечисление должно иметь широкие возможности для расширения (дополнительные атрибуты, методы и т.д.)
Мы используем поиск по словарю в единственном случае — это обратное отображение значения value на член перечисления. Все остальные вычисления выполняются только один раз во время объявления класса (где используются метаклассы для настройки создания типов).
В отличие от стандартной библиотеки, мы обрабатываем только первое значение после знака = в объявлении класса в качестве значения члена: A = 1, 'One' в стандартной библиотеке весь кортеж 1, "One" рассматривается как значение value; A: 'MyEnum' = 1, 'One' в нашей реализации только 1 рассматривается как значение value.
Дальнейшее ускорение достигается за счет использования __slots__ где это возможно. В классах Python, объявленных с использованием __slots__ у экземпляров не создается атрибут __dict__, который содержит отображение имен атрибутов на их значения (поэтому вы не можете объявить какое-либо свойство экземпляра, которое не упомянуто в __slots__). Кроме того, доступ к значениям атрибутов, определенных в __slots__, осуществляется по константному смещению в указателе экземпляра объекта. Это высокоскоростной доступ к свойствам, поскольку он позволяет избежать вычислений хеша и сканирования хеш-таблиц.
Каковы дополнительные фишки?
FastEnum не совместим ни с какой версией Python до 3.6, поскольку повсеместно использует аннотации типов, внедренные в Python 3.6. Можно предположить, что установка модуля typing из PyPi поможет. Краткий ответ — нет. Реализация использует PEP-484 для аргументов некоторых функций, методов и указателей на тип возвращаемого значения, поэтому любая версия до Python 3.5 не поддерживается из-за несовместимости синтаксиса. Но, опять же, самая первая строка кода в __new__ метакласса использует синтаксис PEP-526 для указания типа переменной. Так что Python 3.5 тоже не подойдет. Можно перенести реализацию на более старые версии, хотя мы в Qrator Labs, как правило, используем аннотации типов когда это возможно, так как это сильно помогает в разработке сложных проектов. Ну и в конце-концов! Вы же не хотите застрять в Python до версии 3.6, поскольку в более новых версиях нет обратной несовместимости с вашим существующим кодом (при условии, что вы не используете Python 2), а ведь в реализации asyncio была проделана большая работа по сравнению с 3.5, на наш взгляд, стоящая незамедлительного обновления.
Именно это в свою очередь делает ненужным специальный импорт auto, в отличие от стандартной библиотеки. Вы просто даете указание, что член перечисления будет экземпляром этого перечисления, не предоставляя значение вообще — и значение будет сгенерировано для вас автоматически. Хотя Python 3.6 достаточен для работы с FastEnum, имейте в виду, что сохранение порядка следования ключей в словарях было представлено только в Python 3.7 (а мы не стали отдельно для случая 3.6 использовать OrderedDict). Мы не знаем каких-либо примеров, где сгенерированный автоматически порядок значений важен, поскольку мы предполагаем, что, если разработчик предоставил окружению задачу генерации и назначения значения члену перечисления, значит, само по себе значение ему не так уж важно. Тем не менее, если вы все еще не перешли на Python 3.7, мы вас предупредили.
Те, кому необходимо, чтобы их перечисления начинались с 0 (нуля) вместо значения по умолчанию (1), могут сделать это с помощью специального атрибута при объявлении перечисления _ZERO_VALUED, который не будет сохранен в полученном классе.
Однако, существуют некоторые ограничения: все имена членов перечисления должны быть написаны ЗАГЛАВНЫМИ буквами, иначе они не будут обработаны метаклассом.
Наконец, вы можете объявить базовый класс для ваших перечислений (имейте в виду, что базовый класс может сам использовать метакласс, поэтому вам не нужно предоставлять метакласс всем подклассам) — достаточно определить общую логику (атрибуты и методы) в этом классе и не определять членов перечисления (так что класс не будет «финализирован»). После можно объявить столько наследующих классов этого класса, сколько захотите, а сами наследники при этом будут иметь общую логику.
Псевдонимы и как они могут помочь
Предположим, что у вас есть код, использующий:
package_a.some_lib_enum.MyEnum
И что класс MyEnum объявлен следующим образом:
class MyEnum(metaclass=FastEnum):
ONE: 'MyEnum'
TWO: 'MyEnum'
Теперь, вы решили что хотите сделать кое-какой рефакторинг и перенести перечисление в другой пакет. Вы создаете что-то вроде этого:
package_b.some_lib_enum.MyMovedEnum
Где MyMovedEnum объявлен так:
class MyMovedEnum(MyEnum):
pass
Теперь вы готовы к этапу, на котором перечисление, расположенное по старому адресу, считается устаревшим. Вы переписываете импорты и вызовы этого перечисления так, что теперь используется новое название этого перечисления (его псевдоним) — при этом можно быть уверенными, что все члены этого перечисления-псевдонима на самом деле объявлены в классе со старым названием. В вашей документации о проекте вы объявляете, что MyEnum устарел и будет удален из кода в будущем. Например, в следующем релизе. Предположим, ваш код сохраняет ваши объекты с атрибутами, содержащими члены перечислений с помощью pickle. На этом этапе вы используете MyMovedEnum в своем коде, но внутренне все члены перечислений по-прежнему являются экземплярами MyEnum. Ваш следующий шаг — поменять местами объявления MyEnum и MyMovedEnum, чтобы MyMovedEnum не был подклассом MyEnum и объявлял все свои члены сам; MyEnum, с другой стороны, теперь не объявляет никаких членов, а становится просто псевдонимом (подклассом) MyMovedEnum.
Вот и все. При перезапуске ваших приложений на этапе unpickle все члены перечисления будут переобъявлены как экземпляры MyMovedEnum и станут связаны с этим новым классом. В тот момент, когда вы будете уверены, что все ваши хранимые, например, в базе данных, объекты были повторно десериализованы (и, возможно, сериализованы опять и сохранены в хранилище) — вы можете выпустить новый релиз, в котором ранее помеченный как устаревший класс MyEnum может быть объявлен более ненужным и удаленным из кодовой базы.
Попробуйте сами: github.com/QratorLabs/fastenum, pypi.org/project/fast-enum.
Плюсы в карму идут автору FastEnum — santjagocorkez.
