Bug policy. Что делать когда работа с дефектами — это хаос и ужас
Сегодня хотим рассказать о том, как нам в YouTravel.me удалось снизить количество дефектов в 30 раз — с 400 до 13 — менее чем за полгода. Для наглядности — вот как выглядит это на графике:
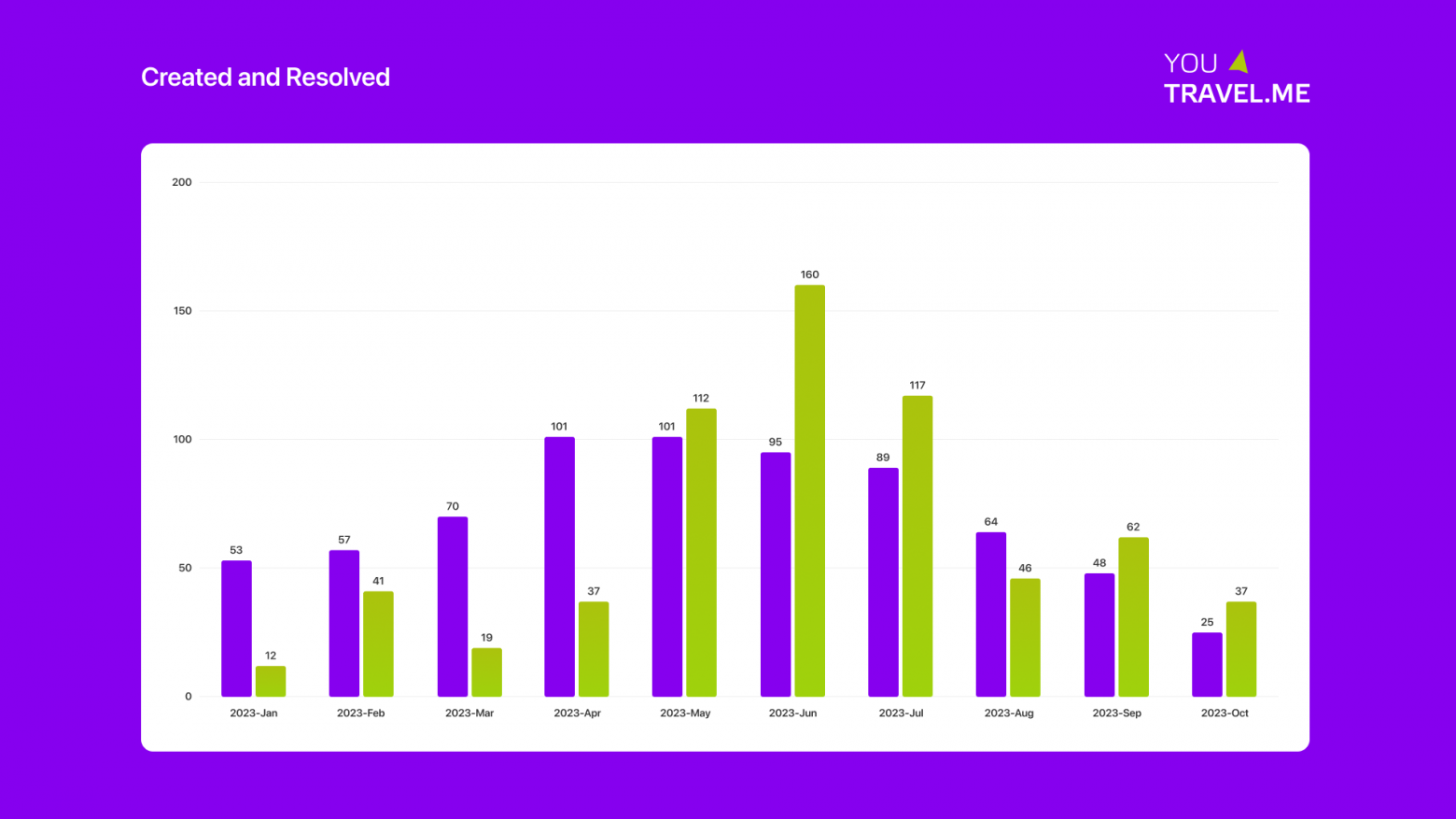
Немного истории: в начале 2023 года мы столкнулись с тем, что количество дефектов становится всё больше, а ресурса на их своевременное устранение у нас все меньше. Проанализировав ситуацию, мы решили кардинально поменять подход к этой проблеме. Так начались наши поиски идеального решения.
Почему выделенный ресурс на работу с дефектами — плохое решение?
Прежде всего мы проанализировали масштаб дефектов и поняли, что в массе своей мы имеем дело с достаточно мелкими ошибками, не влияющими на критические функции сервиса и потому находящимися в нескончаемой очереди на исправление. В приоритете бэклога команд закономерно стояла разработка фичей и устранение дефектов, напрямую влияющих на бизнесовые показатели и продуктовые метрики. В итоге из мелких исправлений начал копиться внушительный беклог.
На тот момент самым логичным решением нам показалось создание отдельного канала, специалист которого будет заниматься обрабатыванием входящих запросов и исправлением дефектов. Однако такой подход выявил значительное количество проблем.
Специалист Force Support принимал запросы, воспроизводил дефект и приступал к его исправлению, при этом отсутствовала приоритезация — степень критичности дефекта, а также дефект ли это вообще, определял сам специалист. У сотрудника зачастую не было перед глазами полной картины, достаточного знания процесса разработки, он не обладал достаточной информацией о логике работы продукта, и в итоге количество дефектов только росло, а в работу могли быть взяты задачи, по факту дефектом не являющиеся. Система, которая должна была уменьшить беклог, в итоге только способствовала его увеличению.
В итоге мы приняли решение вернуть процесс исправления дефектов обратно в ведение команд, но при этом полностью поменять подход к их взятию в работу. На том этапе мы понимали, что, так как команда уже достаточно загружена, то работа на входящих запросах без какой-либо системы будет малоэффективна. Поэтому мы решили внимательно изучить запросы, посмотреть, какие из них наиболее часто повторяются или следуют друг из друга, и разработать систему приоритетов, благодаря которой команда сможет адекватно рассчитывать свое время и загрузку.
Анализ запросов позволил нам разделить дефекты на следующие категории:
1) Очень редкие и некритические ошибки, когда мы больше времени тратим на поиск пути, по которому прошел пользователь столкнувшийся с ними
2) Визуальные дефекты — съехавшие шрифты, верстка, и т.д.
3) Функциональные дефекты, при которых можно использовать сервис
4) Критические инциденты — когда все силы направляются на скорейшее решение проблемы

На основе полученных знаний мы вместе с QA-инженерами создали Bug Policy — документ, в котором подробно описали все типы багов и процесс приоритезации по работе с ними. В документе мы описали подход, основанный на severity и priority, разработав систему критериев для определения серьезности и приоритета каждого конкретного дефекта. Таким образом каждый член команды, получив входящий запрос, мог самостоятельно планировать его решение без ущерба для текущих процессов.

Для того, чтобы на исправление дефектов и подчистку «хвостов» беклога, всегда было время, мы предложили ввести «баго-недели» с периодичностью раз в месяц. На протяжении месяца мы собираем все мелкие запросы и ошибки через специальный канал dev-support, который позволяет самостоятельно ставить задачи, а не писать специалистам «в личку» с просьбой взять решение вопроса в работу. Все собранные дефекты мы «оптом» исправляем в течении выделенной недели.
Наши «баго-недели» существенно повысили качество нашего продукта. Кроме того, выросла лояльность сотрудников к IT команде — теперь все знают, что их запросы не потеряются, а будут решены в специально-выделенное для этого время.
Недостаточная осведомлённость многих сотрудников о специфике процесса разработки, кстати, стала одной из проблем на пути к сокращению количества дефектов — мы столкнулись с тем, что не все сотрудники компании адекватно понимают разницу между багами и фичами. Это мы смогли исправить только через образовательные материалы и повышение прозрачности продуктового процесса. И мы все еще находимся в процессе оптимального решения.
Что всё это нам дало?
Внедрение Bug Policy значительно улучшило наш подход к управлению дефектами, что привело к более эффективной работе по их устранению. Мы успешно систематизировали процесс и стали более гибкими в отношении дефектов, быстро и объективно оценивая их приоритеты и устраняя гораздо быстрее, чем раньше.
Новый метод также дал нам возможность лучше управлять беклогом и не снижать темпы разработки, даже в ситуациях, когда необходимо уделить больше внимания качеству продукта. Наш подход стал более прозрачным и понятным для всех участников процесса, что позволяет нам более точно прогнозировать разработку и управлять ожиданиями пользователей через техническую поддержку.
Важно, что теперь мы не делаем сложный выбор между добавлением новых функций и исправлением дефектов. Мы имеем четкую систему приоритизации, которая позволяет нам определять, какие задачи требуют немедленного внимания, а какие можно отложить без угрызений совести, не отвлекаясь от главных целей и не растрачивая ресурсы команды.
