Browser Fingerprint – анонимная идентификация браузеров

Валентин Васильев (Machinio.com)
Что же такое Browser Fingerprint? Или идентификация браузеров. Очень простая формулировка — это присвоение идентификатора браузеру. Формулировка простая, но идея очень сложная и интересная. Для чего она используется? Для чего мы хотим присвоить браузеру идентификатор?
- Мы хотим учитывать наших пользователей. Мы хотим знать, пришел ли пользователь к нам первый раз, пришел он во второй раз или в третий. Если пользователь пришел во второй раз, мы хотим знать, на какие страницы он заходил, что он до этого делал. С анонимными пользователями это невозможно. Если у вас есть система учета записей, пользователь логинится, мы все про него знаем — мы знаем его учетную запись, его персональные данные, мы можем привязать любые действия к этому пользователю. Здесь все просто. В случае с анонимными пользователями все становится гораздо сложнее.
- Второй сценарий — персональная реклама. Это сейчас везде. Мы заходим, и вдруг нам показывают рекламу каких-нибудь пирожков, которые мы хотели купить еще вчера. Как это делается? Это делается через идентификацию пользователей.
- Третий сценарий — внутренняя аналитика. Если вы используете, помимо Google Analytics или Яндекс, собственную самописную систему аналитики, Fingerprint JS и Browser Fingerprint, в целом, может вам помочь в достижении почти полной идентификации анонимных пользователей. Вы сможете увидеть, что пользователь делал на вашем сайте, на какие страницы заходил, какие ссылки он щелкал и т.д. И построить на основе этого целую картину, карту действий пользователя. Все это достигается при помощи этой техники — Browser Fingerprinting.

Почему бы для этой цели не использовать просто http cookie? Ведь это очень просто, и все это умеют делать. Работает это, вы все знаете как.
Пользователь приходит на ваш сайт, мы читаем его cookie, если там есть какой-то идентификатор, значит, он у нас уже был, и мы знаем, кто он такой. Мы выполняем всю нашу аналитику, трекинг и т.д. в привязке к этому пользователю.
Если там идентификатора нет, значит, пользователь пришел к нам впервые. Мы генерируем идентификатор уникальный, GUI, бинарную строку какую-то, записываем это в cookie, и потом, когда пользователь придет в следующий раз, мы этот cookie прочитаем и поймем, что этот пользователь к нам пришел во второй, третий и последующий разы.
У сookie есть один большой недостаток — его можно очистить. Любой, даже технически неподкованный пользователь знает, как очищать cookie. Он нажимает «Настройки», заходит и очищает. Все, пользователь становится опять для вас анонимным, вы не знаете, кто он такой.
Все современные браузеры, даже Internet Explorer, кажется, предлагают режим инкогнито. Это такой режим, когда ничего не сохраняется, и когда пользователь посетил ваш сайт в этом режиме, он не оставляет никаких следов. Следующий раз, когда он зайдет в режиме инкогнито, вы опять же не узнаете, кто он такой и был ли он у вас до этого. Т.е. в режиме инкогнито http cookie работать не будут.
В настоящее время в связи с популярностью таких персонажей как Сноуден и т.д. многие предпочитают разные режимы приватности, анонимности в Интернете, режимы, плагины и что угодно. Все это препятствует трекингу и идентификации в Интернете. Многие пользователи этим пользуются, даже не понимая, зачем. Просто устанавливают, просто потому, что это модно. И они становятся для вас опять же анонимными. Http cookie в этом случае работать не будут.
Как программисты пытались и пытаются решить эту проблему?
Наиболее успешным проектом в сфере сохранения информации в cookie так, чтобы невозможно было ее удалить, на мой взгляд, является проект evercookie, или persistent cookie — неудаляемый cookie, трудно удаляемый cookie. Суть его заключается в том, что evercookie не просто хранит информацию в одном хранилище, таком как http cookie, он использует все доступные хранилища современных браузеров. И хранит вашу информацию, например, идентификатор. Начинает он использовать http cookies, записывает идентификатор туда, затем, если в браузере доступен Flash, он использует local shared objects для записи информации в т.н. Flash cookies.

Flash cookies до недавнего времени не очищались, когда вы очищали cookie. Лишь последние версии Google Chrome умеют очищать Flash cookie, когда вы очищаете обычные cookie. Т.е. до недавнего времени Flash cookies были практически неудаляемыми. Существовала специальная страница на сайте macromedia, куда нужно было зайти, нажать кнопку: «Да, я хочу очистить Flash cookies», и тогда они очищаются, т.е. без этой страницы было очистить невозможно.

Далее, evercookie использует Silverlight Cookies. По-другому они называются Isolated Storage. Это специальное выделенное место на жестком диске компьютера пользователя, куда пишется cookie информация. Найти это место невозможно, если вы не знаете точный путь. Оно прячется где-то в документах, Setting«ах, если на Windows, глубоко в недрах компьютера. И эти данные удалить, при помощи очистки cookie невозможно.

Далее. Evercookie использует такую инновационную технику как PNG Cookies. Суть заключается в том, что браузер отдает картинку, в которой в байты этой картинки закодирована информация, которую вы сохранили, например, идентификатор. Эта картинка отдается с директивой кэширования навсегда, допустим, на следующие 50 лет. Браузер кэширует эту картинку, а затем при последующем посещении пользователем при помощи Canvas API считываются байты из этой картинки, и восстанавливается та информация, которую вы хотели сохранить в cookie. Т.о. даже если пользователь очистил cookie, эта картинка с закодированным cookie в PNG по-прежнему будет находиться в кэше браузера, и Canvas API сможет ее считать при последующем посещении.

Evercookie использует все доступные хранилища браузера — современный HTML 5 стандарт, Session Storage, Local Storage, Indexed DB и другие.

Также используется ETag header — это http заголовок, очень короткий, но в нем можно закодировать какую-то информацию, и если установлен Java, то используется java presistence API.

Evercookie — очень умный плагин, который может сохранять ваши данные практически везде. Для обычного пользователя, который не знает всего этого, удалить эти cookies просто невозможно. Нужно посетить 6–8 мест на жестком диске, проделать ряд манипуляций для того, чтобы только их очистить. Поэтому обычный пользователь, когда посещает сайт, который использует evercookie, наверняка не будет анонимным.
Несмотря на все это, evercookie не работает в инкогнито режиме. Как только вы зашли в инкогнито режим, никакие данные не сохраняются на диске, потому что это основополагающая суть инкогнито режима — вы должны быть анонимными. А еvercookie использует хранение на жестком диске, которое в этом режиме не работает.

FingerprintJS — это маленькая библиотечка, которую я написал, и которая пытается решить эти проблемы. Я расскажу, как она это делает, и что из этого получилось.
Написал я ее в 2012 году. Я тогда работал в «КупиКупон» Ruby разработчиком. И у меня была задача сделать такую систему аналитики, чтобы учитывать не просто залогиненных пользователей, т.е. тех пользователей, которые есть у нас в системе, а также анонимных пользователей. Конкретно на сайте «КупиКупон» было много анонимных пользователей, потому что люди часто приходили извне посмотреть на какие-то купоны, скидки, предложения, у них ни у кого не было учетной записи, и поэтому система трекинга, система отслеживания посещаемых страниц, нажатия на кнопки — все это не работало, потому что пользователи были анонимными.
FingerprintJS, вообще, не использует cookie. Никакая информация не сохраняется на жестком диске компьютера, где установлен браузер. Работает в инкогнито режиме, потому что в принципе не использует хранение на жестком диске. Не имеет зависимостей, работает даже без jQuery, и размер — 1,2 Кб gzipped.

На данный момент используется в таких компаниях как Baidu, это Google в Китае, MasterCard, сайт президента США, AddThis — сайт размещениz виджетов и т.д.
Эта библиотека быстро стала очень популярной. Она используется примерно на 6–7% всех самых посещаемых сайтов в Интернете на данный момент.
Как она работает, расскажу детально. Суть ее в том, что код этой библиотеки опрашивает браузер пользователя на предмет всех специфичных и уникальных настроек и данных для этого браузера и для этой системы, для компьютера. Эти данные объединяются в огромную строку, затем они подаются на вход функции хэширования. Функция хэширования берет эти данные и превращает их в компактные красивые идентификаторы. Как детально это работает, я расскажу.
Сначала считывается userAgent navigator. Допустим, тут он обрезан, это присоединяется к итоговой строке отпечатка.

Считывается язык браузера — какой у вас язык — английский, русский, португальский и т.д. Тоже присоединяется к строке отпечатка.
Считывается часовой пояс, это количество минут от UTC:
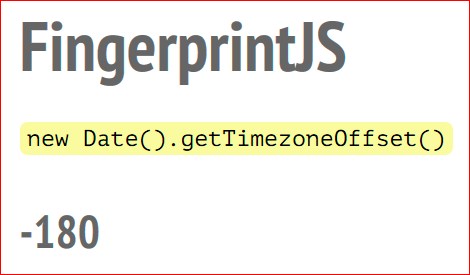
–180.
Это –6, получается Москва.

Далее получается размер экрана, массив, глубина цвета экрана.

Затем происходит получение всех поддерживаемых HTML5 технологий, т.е. у каждого браузера поддержка отличается. FingerprintJS пытается определить, какие поддерживаются, какие — нет, и для каждой технологии результат опроса наличия этой технологии и степень ее поддержки прибавляется к итоговой функции отпечатка.

SessionStorage, LocalStorage, IndexedDB, OpenDatabase и другие всевозможные.
Опрашиваются данные, специфичные для пользователя и для платформы, такие как настройка doNotTrack (очень иронично, что настройка doNotTrack используется как раз для трекинга), cpuClass процессора, platform и другие данные.

Здесь у вас может возникнуть закономерный вопрос — ведь у очень многих пользователей эти данные они одинаковые? Допустим, пользователь живет в Москве, у него будет одинаковый язык, последний Chrome, у него будет все практически одинаково, и все эти строки, которые были получены на данном этапе, будут одинаковые. Как это поможет идентифицировать пользователя?
Есть еще 2 способа, которые добавляют уникальности.
- Первый — это информация о плагинах. Код опрашивает наличие всех установленных плагинов в системе. Для каждого плагина получается его описание и название.А также, что очень важно, список всех мультимедиа типов или main типов, которые поддерживают этот плагин. Вся эта информация объединяется в огромный массив строк, и этот массив тоже конкатенируется и прибавляется к строке отпечатка. Как вы понимаете, на каждом компьютере список плагинов свой, достаточно уникальный, и версии плагинов могут быть свои, и список поддерживаемых main типов тоже будет свой.

- Следующее — к строке отпечатка прибавляется т.н. Сanvas Fingerprint. Это еще одна техника, которая позволяет повысить точность. Суть ее заключается в том, что на скрытом Сanvas элементе рисуется определенный текст с определенными наложенными на него эффектами. И затем полученное изображение сериализуется в байтовый массив и преобразовывается в base64 при помощи вызова canvas.toDataULR ().
У вас тут возникает вопрос: как это тоже помогает идентифицировать? Неожиданное для меня было исследование, которое я нашел. Оно говорит о том, что прорисовка шрифтов, в частности, в Canvas API, очень платформозависима. Внешне идентичные одинаковые изображения, нарисованные в разных браузерах, будут преобразованы в разный байтовый массив. Почему? Это зависит от процессора, видеокарты, драйверов видеокарты, системных библиотек, таких как direct X, систем отрисовки шрифтов, теней — все это на каждом компьютере может быть свое, поэтому результирующий байтовый массив будет отличаться практически на каждом компьютере, где будет разная аппаратная и программная начинка. И эта длинная строка, полученная при сериализации Сanvas будет присоединена к итоговому отпечатку, и мы получим огромную строку.
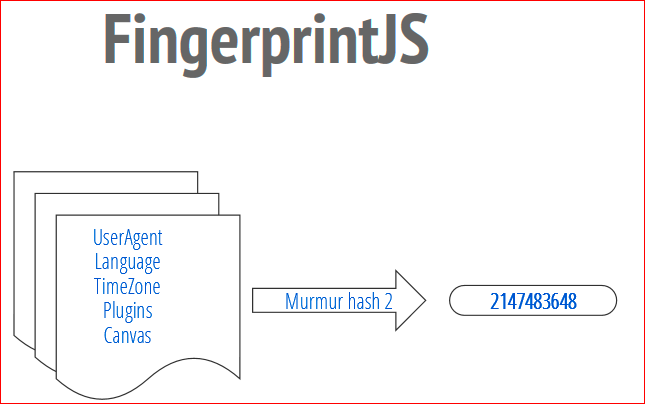
Тут показано, как это работает. Мы получаем все эти данные. Потом мы передаем их в функцию хэширования, в FingerprintJS используется nomo hash2, и на выходе мы получаем 32-х битное число. Это и есть ваш идентификатор. Т.о., когда пользователь заходит на наш сайт, ему присваивается номер. Этот номер вы считываете и используете, как хотите, — вы базируете на нем свою аналитику и т.д.
Тут вопрос: насколько уникально и точно определение? Исследование, за основу которого было взято, было сделано компанией Electronic Frontier Foundation, у них был проект Panopticlick. Оно говорит, что уникальность составляет порядка 94%, но на реальных данных, которые были у меня, уникальность составляла около 90%-91%.
Библиотеку стало использовать много людей и компаний, и с течением времени выявился ряд недостатков. Т.е. она неидеальна, у нее есть недостатки. Самый главный недостаток — то, что точность идентификации только 90%, но есть и другие недостатки.

- UserAgent. У современных браузеров UserAgent меняется очень часто, каждые два месяца выходит новая версия Google Chrome. UserAgent будет меняться, потому что та версия Google Chrome, которая защита в UserAgent будет отличаться. А это означает, что UserAgent будет влиять на итоговый отпечаток. Если выходит новый браузер, итоговый отпечаток изменится, потому что с точки зрения FingerprintJS это будет новый пользователь.
- IPhone, IPad и другие продукты Apple. Дело в том, что они очень униформенные, одинаковые с точки зрения аппаратной реализации. У них у всех одинаковые процессоры. Если мы возьмем, конечно, отдельно взятую модель, допустим IPhone 5S, у всех IPhone 5S будет одинаковый процессор, одинаковый графический ускоритель и одинаковые системные библиотеки, и плагины там будут одинаковые, но на самом деле их там нет. Это означает, что тот байтовый массив, полученный с Сanvas Fingerprint, будет одинаков для всех версий IPhone 5S, а это значит, что точность идентификации для продуктов Apple будет ниже.
- Internet Explorer и Китай. Не подозревал о существовании этой проблемы, но потом я узнал, что используется в Китае очень много старых версий IE, и для того, чтобы получить список плагинов, нужно иметь названия всех плагинов заранее. Потому что для того, чтобы проверить, есть плагин или нет, в IE просто невозможно вызвать, например, navigator.plugins. Это не будет работать. Нужно взять и каждый плагин попытаться инстанциировать как active ex объект. Если он создался, то значит все хорошо. Если выброшена ошибка, значит, что плагины в IE не установлены. Список плагинов для IE у меня был, но он был коротким — порядка десяти плагинов. У меня не было определения тех плагинов, которые популярны в Китае, таких как QQ, baidu и др. Там очень много плагинов, которые используются только там. Эти плагины я не проверял, и список плагинов для Китая конкретно был меньше.
- Другой недостаток первой версии — это отсутствие интеграции с Flash и Silverlight, а интеграция с этими плагинами позволяет улучшить качество Fingerprint.
- И последняя, но достаточно серьезная вещь, которая недавно обрушилась на FingerprintJS, — это то что, начиная с версии 42, Google Chrome просто перестал активировать все те плагины, которые работают через NPAPI. NPAPI — это очень старый API для инстанциирования плагинов, он был разработан еще компанией «Nextkey». Он так и назывется — «Nextkey plugin API». Все плагины, которые работают и опираются на этот протокол, на этот API, перестали загружаться, и поэтому ни Silverlight, ни Java, а эти два плагина наиболее популярны, которые работают через NPAPI, не отображаются в FingerprintJS — они ни коем образом не определяются, и список их main типов тоже не отображается. Это значит, что в Chrome 42 и старше точность FingerprintJS снижена за счет этой проблемы.
Поэтому, проанализировав все это, а сейчас я тоже использую FingerprintJS, я пришел к выводу, что пора разрабатывать новую библиотеку, которая будет практически лишена всех существующих недостатков.
Я ее начал делать совсем недавно, разработка ведется на github.
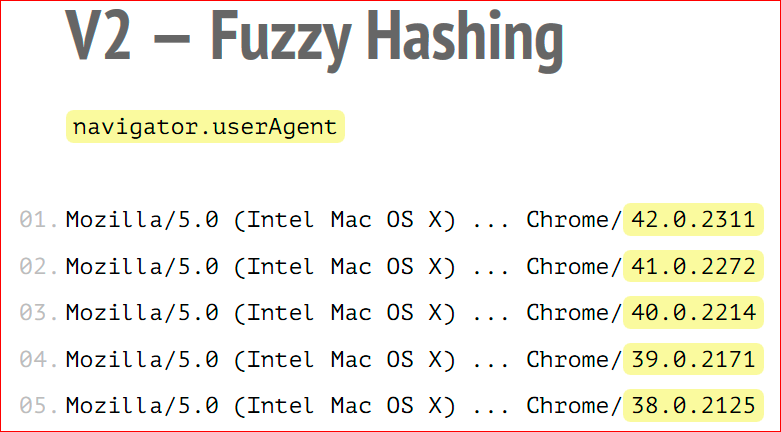
Как она решает существующие проблемы? Самое главное — используется фазихэширование или localsensitivehash, или нечеткое хэширование. Такое хэширование, которое не меняется, даже если в обычном хэшировании, если вы измените хотя бы один байт входящей информации, выходящая строка тоже изменится, причем кардинальным образом. В фазихэшировании этого не происходит, тут есть порог чувствительности, когда определенный процент входящих данных может измениться, что не повлияет на исходящий отпечаток. Допустим, если поменялась в UserAgent только версия браузера, это случается очень часто, допустим, в Chrome, то результирующий отпечаток будет одинаковым, потому что версия составляет 3 или 5% от общей длины от UserAgent.

Второе — в FingerprintJS 2 используется определение установленных шрифтов, всех шрифтов, которые установлены в системе. Чем это полезно? Если вы поставили программу, допустим, adobe pdf, то вы добавляете в систему шрифты.
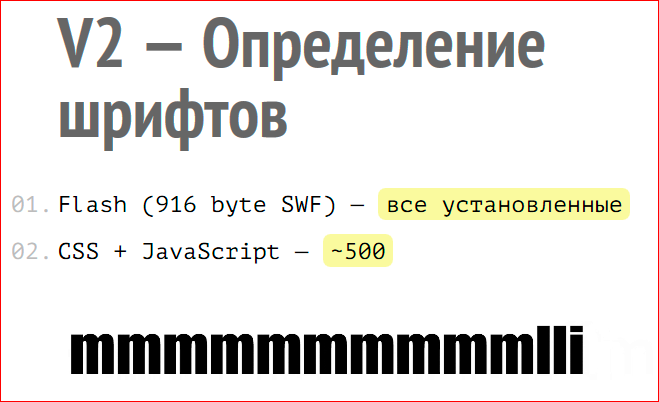
Если вы поставили Microsoft Office, вы добавляете в систему шрифты; если вы поставили какой-нибудь Quick office, который имеет собственные шрифты, вы опять же добавляете в систему шрифты. И поэтому у вас может быть два абсолютно одинаковых компьютера, но на одном установлен Office, а на другом — нет. Это значит, что на первом, где нет Office, будет 320 доступных шрифтов, а, где есть Office — 1700 шрифтов. И значит, что вы сможете получить все шрифты, которые есть на этом компьютере, опять же, для итогового отпечатка. Это будет два разных отпечатка, потому что шрифты разные.
По умолчанию используется Flash, маленький swf файл размером 916 байт. Он получает список всех установленных шрифтов, причем в платформозависимом порядке, т.к. они доступны в системе, так они и будут возвращены. Если Flash не установлен, используется такая техника, она называется site chanel technic. Она впервые была опубликована на сайте lalit.org. Это определение наличия шрифта с помощью javascript only. Как это делается? Для каждого референтного шрифта, который задан по умолчанию в браузере или в системе, измеряется его ширина и высота, и этот массив ширины и высоты сохраняется. Затем к скрытому тексту (текст, кстати, огромный, допустим, 72 пикселя) применяется другой шрифт. Если этот шрифт есть в системе, текст изменит свои габариты правильно, и код, который изменяет высоту и ширину, получит новый массив, с высотой и шириной. Если он отличается от референтного, от того, который был получен при запросе дефолтного шрифта, значит, этот шрифт установлен. Если не отличается, значит, этого шрифта нет.
Очень простая идея, но она работает. На данный момент этот код может достоверно определить около 500 шрифтов без использования Flash. И, соответственно, тот компьютер, где есть Microsoft Office, и тот, где его нет, будут по-разному определены в FingerprintJS 2 за счет этой техники.

Третье отличие — WebGL Fingerprint. Это развитие идеи Сanvas Fingerprint. Суть его заключается в том, что рисуются 3D треугольники (на слайде не очень хорошо видно, но это 3D). На него накладываются эффекты, градиент, разная анизотропная фильтрация и т.д. И затем он преобразуется в байтовый массив. Результирующий байтовый массив, как и в случае с Canvas Fingerprint, будет разный на многих компьютерах. Потом к этому байтовому массиву еще добавляется информация о платформозависимых константах, которые определены в WebGL.Т. е. в WebGL есть набор констант, которые должны быть обязательно в реализации. Это глубина цвета, максимальный размер текстур… Этих констант очень много, их десятки. Код опрашивает все эти константы и, понятное дело, что на android-девайсах эти константы будут отличаться, там глубина цвета может быть другой, чем на Windows или чем на linux«е. Он опрашивает все эти константы, все это опять же складывается в огромный массив, и все это добавляется к сериализованному изображению 3D треугольника, который нарисован при помощи аппаратных эффектов.
Тут тоже такой вопрос: как это помогает идентифцировать? 3D графика очень платформозависима, версия драйверов, версия видеокарты, стандарт OpenGL в системе, версия шейдерного языка, — все это будет влиять на то, как внутри будет нарисовано это изображение. И когда оно будет преобразовано в байтовый массив, оно будет разное на многих компьютерах.
Почему WebGl Fingerprint важен? Потому что IOS 8.1 поддерживает WebGL, а это помогает идентифицировать IOS девайсы, о проблеме идентификации которых я упоминал. Поэтому WebGL повышает точность Fingerprint.

Что еще предстоит реализовать?
Как я говорил, библиотека находится в разработке и не все вещи, которые я бы хотел в ней сделать, сделаны. Вокруг нее уже есть небольшое сообщество разработчиков. Я, кстати, приглашаю всех желающих участвовать в разработке — она очень интересная, мы очень неформальны, каждый предлагает идеи, там достаточно интересно.
Что предстоит еще реализовать? WebRTC Fingerprinting.
WebRTC — это стандарт peer-to-peer коммуникаций через аудиопотоки, или это стандарт аудиокоммуникаций в современных браузерах. Он позволяет делать аудиозвонки и т.д., он поддерживается в FireFox и будет скоро поддерживаться в других браузерах.
Реализация WebRTC стандарта тоже платформозависима, она будет зависеть от той видеокарты, которая установлена в системе, от драйверов на звук и т.д. Поэтому, измеряя разные уровни латентности, разные уровни поддержки WebRTC и констант, которые зашиты в этом формате, можно получить разные итоговые отпечатки для разных компьютеров.
Будет использоваться больше плагинов для IE. Будут использованы те плагины, которые популярны в разных странах — Китае, Индии и т.д., т.е. растущие информационные рынки. В первой версии недостаточно внимания было уделено этой проблеме, а во второй версии это будет решено.
Больше информации будет собираться об ОС. Как мы это будем делать? Будет использоваться интеграция с Flash и Silverlight. Flash позволяет получать информацию о системе, такую как версия ядра, патч левел ядра. Silverlight, если на Windows, позволяет получить версию Windows, bild, номер Windows, все это доступно через Silverlight.
Пару слов о Silverlight, почему интеграция с sliverlight тоже достаточно важна? Может быть, в России Silverlight плагин не очень популярен, но в США, например, есть сервис стримингового видео Netflix, который транслирует видео, и я знаю точно, что они используют Silverlight. Ввиду того, что он поддерживает DRM (это система ограничения цифровых прав на контент), т.к. Netflix часто показывают разные свежие голливудские фильмы, они используют Silverlight для того, чтобы это видео не расходилось по Интернету. Поэтому в США у многих десктопных пользователей Интернета установлен Silverlight плагин, который, кстати, доступен и на Mac«е тоже, помимо Windows.
Будет реализовано определение наличия нескольких мониторов. Если мы запросим размеры через javascript, то получим просто два числа — это ширина и высота экрана. Если мы сделаем то же самое через Flash API, Actionscript API, мы получим массив массивов. Это значит, что если установлено несколько мониторов, где каждый подмассив — это будет размер экрана каждого монитора. Если разработчик сидит за пятью мониторами, он получит массив массивов из пяти элементов, т. о., мы узнаем, что человек сидит за пятью мониторами, а не за основным монитором, который вернул бы javascript.
Все эти данные в совокупности позволяют на данный момент получить точность определения порядка 94–95%. Но, как вы понимаете, это недостаточная точность идентификации. Тут встает вопрос: каким образом это можно улучшить, и можно ли это улучшить? Я считаю, что можно. Цель этого проекта — достичь 100% идентификации так, чтобы можно было опираться на Fingerprint в 100% случаях и гарантированно сказать: «Да, этот пользователь к нам приходил; да, я все о нем знаю, несмотря на то, что он использует инкогнито mode, tor сеть…». Не важно, все это будет определено.

Контакты
» github
» Machinio.com
Этот доклад — расшифровка одного из лучших выступлений на конференции фронтенд-разработчиков FrontendConf.Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая FrontendConf.
