Брокер сообщений NATS: как мы решали проблему скоростной и стабильной доставки сообщений

Всем привет. Меня зовут Женя, я работаю, как это сейчас модно говорить, DevOps-инженером в компании Garage Eight.
В этой статье я бы хотел поделится опытом внедрения и эксплуатации брокера сообщений NATS в нашей инфраструктуре — настолько понравилась эта технология.
Давным-давно, когда вышел последний сезон сериала «Игра престолов», перед нами в компании Garage Eight встала задача максимально быстрой доставки сообщений из пункта A в пункт B. Условия были таковы:
перед тем как сообщение достигнет пункта назначения, оно проходит ряд сервисов;
каждый сервис выполняет определенный набор действий над этим сообщением;
время прохождения сообщений через весь путь должно быть минимальным;
брокер сообщений должен работать стабильно 24\7.
Также желательными требованиями были простота написания кода для работы с брокером сообщений и простота обслуживания брокера.
Поиски решения
Изначально в качестве шины данных хотели взять RabbitMQ, поскольку мы уже с ним работаем. Однако не раз и не два случалось так, что RabbitMQ по своим внутренним причинам (в частности, из-за переполнения очередей) переставал работать. Это сильно влияло как на сервисы, которые с ним работают, так и на людей, которые работают с этими сервисами (думаю, что все, кто работает с RabbitMQ в проде, сталкивались с подобным). Это одна из основных причин, почему мы отказались от использования «кролика». Также были сомнения относительно скорости доставки, что стало еще одним аргументом в пользу поиска другого брокера сообщений (тут должна быть статья про бенчмарки различных брокеров сообщений).
Мы смотрели в сторону брокера Kafka, и это вроде как хорошая штука, но по итогу мы отказались тащить решение, написанное на Java.
Походив по интернету, наткнулись на брокер сообщений NATS. В нем нас подкупил написанный на Go бинарный файл, который можно достаточно легко развернуть в инфраструктуре и писать сервисы для него на очень большом количестве языков (есть даже реализация для Arduino:)). Но поскольку нашим основным ЯП является Go, а NATS написан на Go, это тоже вошло в копилку аргументов за то, чтобы попробовать NATS. Более того, NATS позиционировался как высокопроизводительный брокер сообщений, и все эти факторы привели к тому, что мы решили его попробовать.
Немного про NATS
NATS — это высокопроизводительный брокер сообщений, написанный на Go. Он создан Дереком Коллисоном, за плечами которого более 20 лет работы над распределенными очередями сообщений. NATS используется широким списком крупных компаний в своей инфраструктуре.
Для работы с сообщениями в NATS используется простой текстовый протокол в стиле публикации/подписки. Клиенты подключаются и взаимодействуют с сервером через обычный сокет TCP/IP, используя небольшой набор протокольных операций, которые заканчиваются новой строкой.
Для роутинга сообщений используются Subject-ы (мы называем их «топики»). Это что-то вроде связки exchange-queue в RabbitMQ. По сути сабжект — это просто строка, которую используют и тот, кто пишет сообщения с одной стороны, и тот, кто читает сообщения с другой стороны. Сабжекты могут иметь иерархическую структуру, которая разделяется символом ».». Читатели при этом могут читать из многих сабжектов, используя символы »» или »>».
»» означает читать из всех текущих сабжектов в иерархии, а »>» — из текущего и всех последующих.
Все это отлично описано в документации.
Как мы приготовили Nats
Поскольку в то время, когда мы внедряли NATS, кластерная версия была немного сыровата, мы решили готовить standalone вариант без подтверждения доставки (в целом допускалась потеря 1–3% сообщений).
Чтобы внедрить NATS, была написана простейшая роль, которая наливает Docker-контейнер с брокером и монтирует туда конфиг.
Для написания сервисов мы пользовались примерами, которые описаны в официальной документации, и вот что у нас получилось:
Пример кода для чтения сообщений:
func StartReader(ctx context.Context) error {
var err error
bufferSize := 64
//вычитываем в нескольких горутинах
concurrentExecution := 5
//Nats name будет потом отображаться в json на страничке мониторинге
nc, err := nats.Connect("natsURI", nats.Name("natReaderConnectName"))
if err != nil {
return fmt.Errorf("could not connect to nats: %v", err)
}
natsChan := make(chan *nats.Msg, bufferSize)
defer nc.Close()
sub, err := nc.ChanSubscribe("natsReaderSubject", natsChan)
if err != nil {
return fmt.Errorf("could not subscribe to nats: %v", err)
}
defer func() {
_ = sub.Unsubscribe()
close(natsChan)
}()
errorChan := make(chan error, 1)
//Добавляем хэндлеры, которые будут отрабатывать в случае ошибки вычитки, дисконнектов, или закрытого коннекта
nc.SetErrorHandler(func(_ *nats.Conn, _ *nats.Subscription, err error) {
fmt.Printf("reader error handler %s\n", err.Error())
errorChan <- err
})
nc.SetDisconnectErrHandler(func(_ *nats.Conn, err error) {
fmt.Printf("reader disconnect error handler: %v", zap.Error(err))
})
nc.SetClosedHandler(func(_ *nats.Conn) {
fmt.Printf("reader close handler")
})
//вычитываем из созданного канала и делаем там свою логику (в этом примере просто выводим на экран)
for i := 0; i < concurrentExecution; i++ {
go func() {
for msg := range natsChan {
var data interface{}
err := json.Unmarshal(msg.Data, &data)
fmt.Println(data)
}
if err != nil {
errorChan <- err
}
}()
}
}
Пример кода, который пишет, и того проще:
func NatsWriter() error{
nc, err := nats.Connect("natsURI", nats.Name("NatsConnectName"))
var someMsg struct{
msg string
}
//топик, в который будем писать
subject := "nats_subject"
b, err := json.Marshal(someMsg)
if err != nil {
return err
}
err = nc.Publish(subject, b)
return err
}
Реализовав логику, попробовали запуститься, и у нас получилась следующая схема.
Есть сервис, который пишет в NATS, в топик awesomeService. Есть второй сервис, который читает из этого топика и делает над сообщением свою магию, затем пишет обратно в NATS, но уже в топик serviceA. Из этого топика уже вычитывают сообщения конечные потребители.
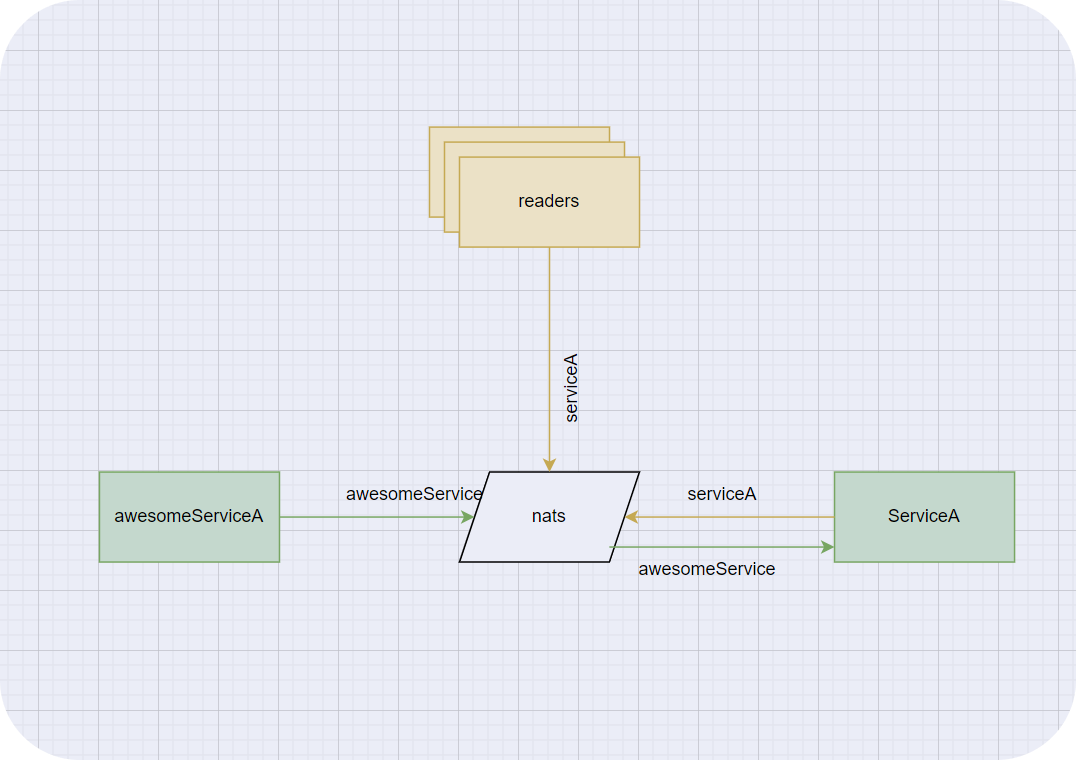
Для обеспечения отказоустойчивости мы просто запустили второй NATS и начали писать в него те же сообщения. Сейчас кластерная версия и NATS JetStream уже нормально работают, и их можно использовать в продакшене.
Запутистились, стартанули, заработало.
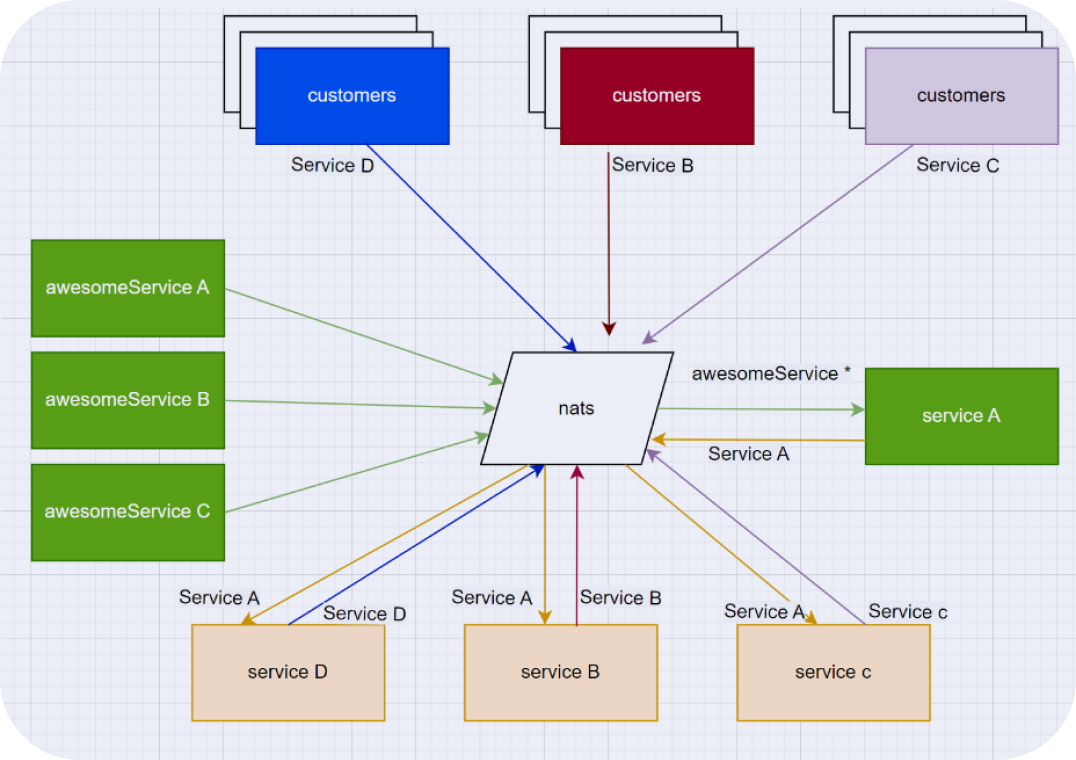
Постепенно схема разрасталась, сервисов, которые пишут и обрабатывают сообщения становилось больше, читалей, которые считывают сообщения, тоже становилось больше. При этом, помимо Go, используются C++ и иногда Python сервисы.
Сегодня схема выглядит следующим образом (фактически в нашей схеме намного больше сервисов, через которые проходят сообщения, но смысл сохраняется).
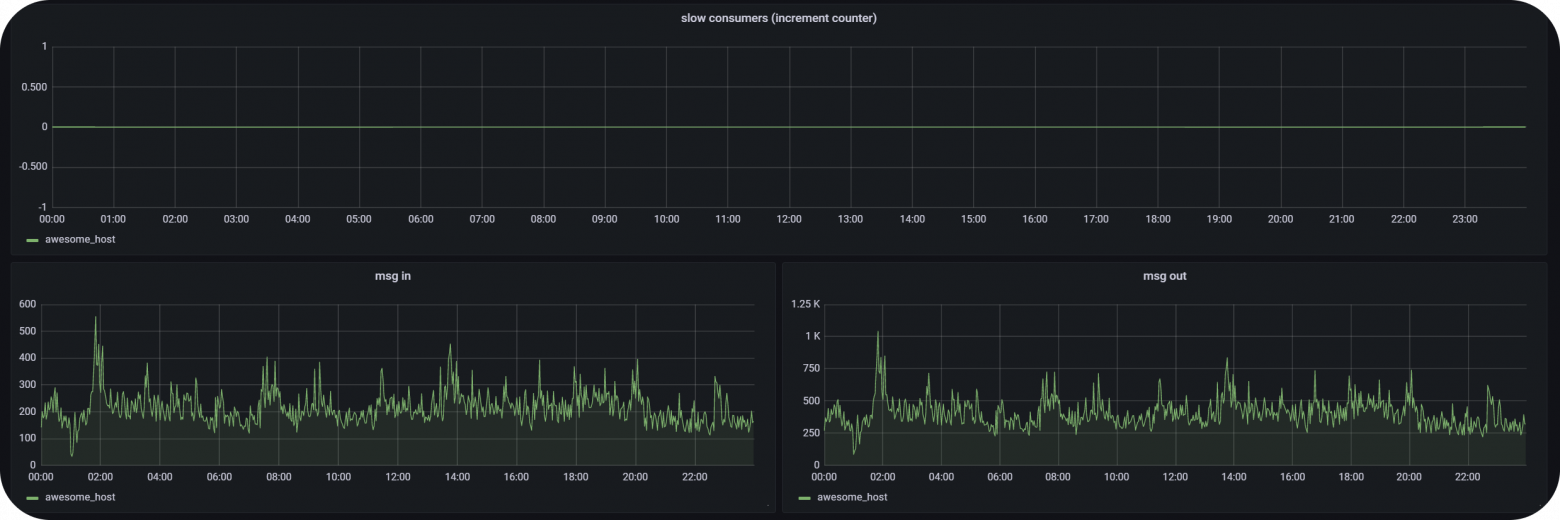
Разумеется, количество сообщений, передаваемых через NATS, тоже увеличилось
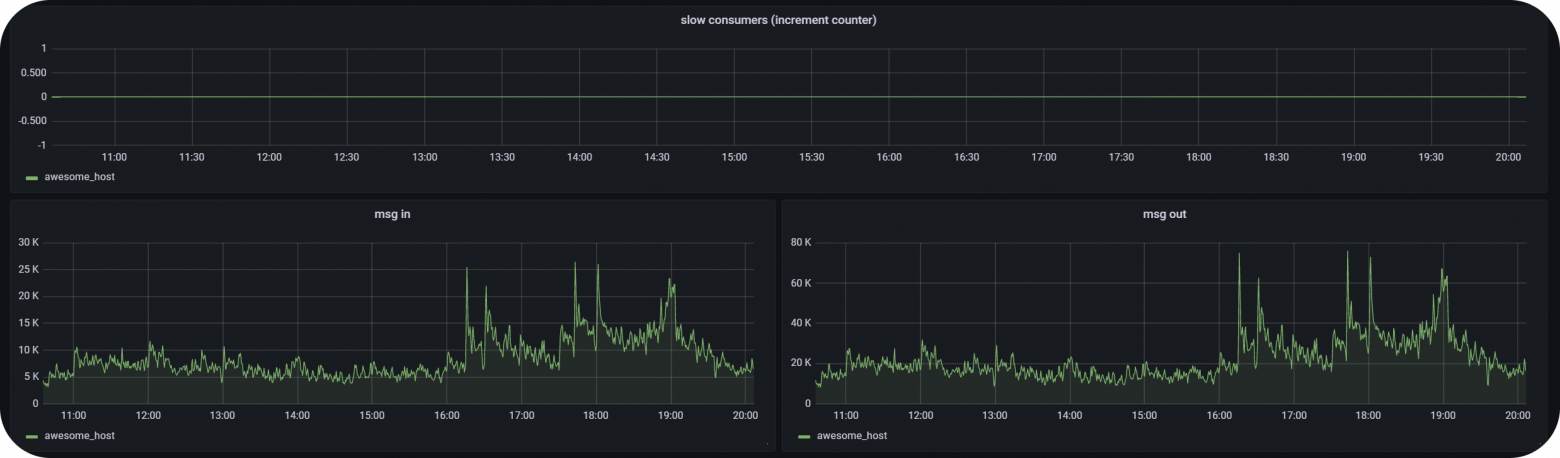
Стоит отметить, что достаточно большое количество сервисов, которые занимаются обработкой сообщений, находятся на том же сервере, где запущен сам NATS.
Время прохождения сообщений, один из наиболее критичных для нас факторов, составляет, в 99 перцентилей от 500 микросекунд до 2 миллисекунд. Весьма хороший показатель при наших потребностях.
В плане стабильности NATS тоже показал себя с хорошей стороны, но с одной, довольно болезненной проблемой, нам все-таки пришлось столкнуться. В том числе именно из-за этой проблемы у нас стала теряться некоторая часть сообщений, но об этом ниже.
Относительно потребляемых ресурсов за все время эксплуатации не было каких-то неожиданных факапов, из-за которых пришлось бы срочно что-то тюнить. Все в рамках прогнозируемых изменений.
При необходимости в NATS можно добавить авторизацию, как на уровне всего сервиса, так и на уровне отдельных топиков\пользователей. Мы в свое время это сделали, чтобы ограничить работу с топиками
Отдельным пунктом хотелось бы отметить мониторинг. По дефолту он доступен по HTTP в NATS на порту 8222.

В каждой из вкладок — статистика по выбранному пункту.
В standalone-версии, которую мы используем, чаще всего заходим во вкладку Сonnections, где показаны основные текущие коннекты, количество сообщений\байт, когда запущен и так далее.
{
"num_connections": 1,
"total": 1,
"offset": 0,
"limit": 1024,
"connections": [
{
"cid": 4,
"kind": "Client",
"type": "nats",
"ip": "192.168.1.1",
"port": 8085,
"start": "1970-01-01T06:32:17.920532298Z",
"last_activity": "1970-01-01T15:52:17.218785543Z",
"rtt": "78µs",
"uptime": "0d0h1m59s",
"idle": "0s",
"pending_bytes": 0,
"in_msgs": 146288056,
"out_msgs": 0,
"in_bytes": 14592708062,
"out_bytes": 0,
"subscriptions": 0,
"name": "some-awesome-client",
"lang": "go",
}Но все же хочется мониторинг смотреть не в отдельном веб-интерфейсе, а в системе, с плюшками в виде алертов и графиков. Поскольку для наших сервисов мы используем прометей, нашелся telegraf exporter, с помощью которого снимаем метрики. Правда, этот экспортер снимает только общую информацию касательно количества текущих коннектов, slow_consumers (об этом немного ниже) и количества входящих\исходящих сообщений\байт (основные показатели, которые доступны на вкладке general).
Ложка дегтя
Это, наверное, не столько ложка дегтя, сколько архитектурная особенность NATS, но в свое время мы с ней немного потрепались. В чем суть.
Архитектура NATS направлена, в первую очередь, на стабильность работы самого сервера, а не отдельных его клиентов. Соответственно, если кто-то из читателей по каким-то причинам начинает читать медленнее, чем в сабжект пишутся данные, то такой клиент помечается как Slow consumer, а коннект дропается. Чтобы определять, через какой период определять клиент как slow consumer, в NATS используется параметр write_deadline (подробнее в документации). Я, кстати, так и нашел возможность конфигурирования этого параметра через размер буфера, а не через время «протухания» сообщения.
Нам такая реализация и была нужна в брокере, поскольку, конечно, не очень хорошо бы было, если какой-то из читателей отвалится, но куда критичнее было бы падение всего сервера NATS.
Неприятной же особенностью при такой архитектуре стало то, что если из очереди читают несколько клиентов и один из них начинает тормозить в вычитке (из-за сети, по причине «внутренних противоречий» или из-за чего-нибудь еще), то остальные клиенты, которые читают из этого сабжекта, тоже начинают тормозить при вычитке.
Почему это происходит? Для читателей в NATS реализован цикл, по которому он последовательно проходит и пушит сообщения вместо обработки каждого читателя в отдельной горутине. Подробности этого кода можно посмотреть в исходниках.
В результате мы просто разнесли по разным Subjects стабильных и нестабильных клиентов, чтобы они не аффектили друг друга. Пока что полет нормальный :)
Выводы
Как оказалось, иметь дело с NATS достаточно приятно. Неприхотливый, быстрый, удобный, весьма стабильный, этот брокер оказался хорошим решением для нашей задачи. За все время эксплуатации NATS (± 3 года) он работает очень стабильно и предсказуемо (за исключением той ложки дегтя, которая была описана выше).
Мы, к сожалению, еще не пробовали работать с кластерной версией или с JetStream, который позволяет сохранять данные на диск. Возможно, там могут выстрелить свои баги\фичи, но это, наверное, будет уже совсем другая история.
