Boson — разработка СУБД «с нуля» (часть I)
 © Анимация компании Seagate
© Анимация компании Seagate
1. Введение
После разработки виртуальной машины и компилятора в рамках хобби прошел год и захотелось попробовать реализовать ёмкий по алгоритмам проект по системному программированию.
Каждый разработчик «кровавого» enterprise в своей работе использует СУБД (SQL/NoSQL) и меня всегда искренне интересовало как они устроены в самом сердце, на самом низком уровне. Почитав документацию и исходный код SQLite и MongoDB, про используемые в индексах и интерпретаторах запросов алгоритмы, осознал, что несмотря на широкую распространенность и некую привычность, системы управления базами данных (СУБД) — это сложные программные продукты, реализация которых не всем под силу. Отлично — как раз то, что мне надо. С мотивацией разобрались, перейдем к делу.
Итак, для начала хорошо бы сформулировать высокоуровневую спецификацию требований. Boson — это легкая, встраиваемая документоориентированная база данных на С/С++:
Простой и понятный API для работы с базой данных.
Быстрый поиск документов по ID на основе B+ Tree индексов.
Хранилище коллекций документов формата ключ/значение (JSON).
Поддержка LRU-cache для ускорения файловых операций ввода/вывода.
Хранение данных в одном файле, без временных файлов и настроек.
Кроссплатформенный «чистый» C/C++ и отсутствие внешних зависимостей.
Предварительная упрощенная архитектура будет поделена на четыре основных программных слоя, каждый из которых даёт очередной уровень абстракции для следующего уровня. Выглядеть это будет вот так:
 Архитектура слоёв базы данных Boson
Архитектура слоёв базы данных Boson
Начну поэтапную реализацию проекта снизу вверх. Первое — кэширование ввода/вывода.
2. Кэширование файлового ввода/вывода (CachedFileIO)
Все мы знаем, что скорость I/O накопителя (HDD/SSD) в сотни раз медленнее, чем работа с оперативной памятью (RAM), а RAM в сотни раз медленнее I/O кэш вашего процессора (CPU). При этом достоверно известно, что практически все приложения в «реальном мире» имеют некую степень локальности обращения к данным.
В ряде исследований есть статистика, что кэш размером 10–15% от размера базы данных даёт в среднем более 95% попаданий в кэш (cache hits), а соотношение операций чтения/записи примерно соотносятся как 70%/30% Поэтому, для производительности кэширование (многоуровневая организация памяти) — это оправданная стратегия. Производительность CachedFileIO будем оценивать в сравнении со стандартными функциями STDIO (fread, fwrite) — прирост более 50% будем считать успехом.
Будем считать атомарным блоком чтения/записи при работе с физическим накопителем (storage device) и кэшем в оперативной памяти (memory cache) массив байт фиксированного размера (8Кб). Назовем его Страница (Page). Предполагается, что операции чтения/записи выровненные по границам физических секторов диска (HDD) или блокам (SSD) выполняются значительно быстрее. Аналогичная ситуация и с оперативной памятью. Кэшем (cache) будем считать загруженные в оперативную память, наиболее часто/недавно использовавшиеся страницы файла.
Итак, как неоднократно говорилось выше класс CachedFileIO нам необходим для кэширования файловых операций ввода/вывода. Основные требования к нему заключаются в следующем:
Хранить в кэше наиболее используемые страницы и удалять самые старые. То есть использовать алгоритм кэширования Least Recent Used (LRU), но таким образом, чтобы размер кэша не влиял на его производительность, он может иметь как сотни, так и сотни тысяч страниц, а именно, отвечать следующим требованиям:
Сложность поиска необходимой страницы в кэше — O (1).
Сложность вставки страницы в кэш — O (1).
Сложность удаления страницы из кэша — O (1).
При записи использовать стратегию Fetch-Before-Write (FBW). Если запись осуществляется в страницу, которая не была ранее загружена, нужно предварительно загрузить её в кэш. Это необходимо, чтобы при изменении части страницы, мы не затерли то, что было в остальной части.
Реализация должна быть максимально «cache-friendly» для CPU. Желательно использовать непрерывные обычные массивы, чтобы при попадании в кэш, она вероятнее всего уже была в одном из уровней кэша CPU (находилась рядом).
Выравнивать запросы операций ввода/вывода на границы файловой страницы (8192 байта). Операции чтения/записи в файл выровненные по границам страниц (сектора на HDD или блока на SSD) выполняются значительно быстрее.
Реализация должна быть 64-битной (не иметь ограничений на файлы более 4Гб).
Иметь очень простой API, инкапсулирующий детали реализации.
Примечание: на текущем этапе, для упрощения, мы осознанно не включаем в требования по блокировке файлов (file lock), так как без специфичных для ОС API этого не сделать. Механизмы для безопасного многопоточного использования (thread safe) также сделаем позже.
Как некогда говорил А. Привалов, на когда-то независимом канале РБК,»вещи не такие сложные, как кажутся на первый взгляд. И не такие простые как на второй….». Поэтому начнем со структур данных, которые необходимы для реализации стратегии кэша LRU/FBW.
Чтобы поиск, вставка, удаление из/в кэш по сложности была O (1), нам нужно объединить свойства таких структур данных как хэш-таблица и связанный список. Первый нам даёт нужную скорость поиска, а второй вставки и удаления. Если в Java есть стандартный шаблон LinkedHashMap, то в стандартной библиотеке C++ такого нет. И прекрасно — реализуем сами.
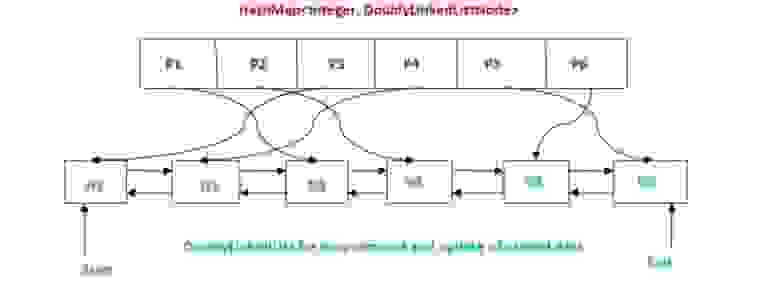 Вот иллюстрация необходимой нам структуры данных: хэш-таблица и связанный список
Вот иллюстрация необходимой нам структуры данных: хэш-таблица и связанный список
Логика работы алгоритма LRU Cache при чтении будет следующая:
Пользователь CachedFileIO делает вызов метода чтения данных (read, readPage). Мы считаем какие страницы файла затрагивает операция, пробегаемся по списку запрошенных страниц.
Для каждой запрошенной страницы проверяем, есть ли она в кэше — ищем номер файловой страницы в хэш-таблице. Если страница нашлась в хэш-таблице — это попадание кэш, перемещаем её в начало списка как наиболее «свежую», копируем запрошенные данные в буфер пользователя.
Если не находим номер страницы в хэш-таблице, то берем свободную страницу кэша. Если свободных страниц кэша нет, то выгружаем (если была изменена — помечена DIRTY) на диск наиболее «старую» (последнюю в списке) страницу в кэше, удаляем из списка и хэш-таблицы. В конце, загружаем запрошенную страницу с диска, вставляя её номер в начало списка (List) и добавляя ссылку на узел списка в хэш-таблицу. Помечаем страницу как CLEAN («чистая»), обозначая, что в неё после загрузки с диска изменения не вносились.
Копируем запрошенный участок данных файла из кэша в пользовательский буфер.
Логика алгоритма при записи будет следующая (Fetch-Before-Write):
Пользователь CachedFileIO делает вызов метода записи данных (write, writePage). Мы считаем какие страницы файла затрагивает операция, пробегаемся по списку запрошенных страниц.
Для каждой изменяемой страницы проверяем, есть ли она в кэше — ищем номер файловой страницы в хэш-таблице. Если страница нашлась в хэш-таблице — это попадание кэш, перемещаем её в начало списка как наиболее «свежую», записываем пользовательские данные в страницы кэша. Помечаем их как DIRTY (измененные).
Если не находим номер страницы в кэше, аналогично алгоритму чтения выгружаем наиболее старую страницу, загружаем с диска изменяемую и потом записываем данные в кэш, помечая страницу как DIRTY.
Все страницы которые были загружены и в них не вносились изменения помечаются как CLEAN («чистые»), а в те которые что-то записывали, помечаем как DIRTY («грязные»). При удалении из кэша, все грязные страницы сохраняются на накопитель, остальные просто выгружаются из оперативной памяти. При сбрасывании (flush) на накопитель всего кэша, страницы сортируются в памяти в порядке возрастания номера страницы в файле, только после чего записываются. Предполагается, что последовательная запись выполняется быстрее.
 Иллюстрация алгоритма: показаны состояния кэша слева направо, сверху указан запрашиваемый элемент.
Иллюстрация алгоритма: показаны состояния кэша слева направо, сверху указан запрашиваемый элемент.
Класс CachedFileIO будет иметь следующее объявление:
#pragma once
#define _ITERATOR_DEBUG_LEVEL 0 // MSVC debug performance fix
#include
#include
#include
#include
namespace Boson {
//-------------------------------------------------------------------------
constexpr uint64_t PAGE_SIZE = 8192; // 8192 bytes page size
constexpr uint64_t MINIMAL_CACHE = 256 * 1024; // 256Kb minimal cache
constexpr uint64_t DEFAULT_CACHE = 1*1024*1024; // 1Mb default cache
constexpr uint64_t NOT_FOUND = -1; // "Not found" signature
//-------------------------------------------------------------------------
typedef enum { // Cache Page State
CLEAN = 0, // Page has not been changed
DIRTY = 1 // Cache page is rewritten
} PageState;
typedef struct {
uint8_t data[PAGE_SIZE];
} CachePageData;
class alignas(64) CachePage { // Align to CPU cache line
public:
uint64_t filePageNo; // Page number in file
PageState state; // Current page state
uint64_t availableDataLength; // Available amount of data
uint8_t* data; // Pointer to data (payload)
std::list::iterator it; // Cache list node iterator
};
//-------------------------------------------------------------------------
typedef // Double linked list
std::list // of cached pages pointers
CacheLinkedList;
typedef // Hashmap of cached pages
std::unordered_map // File page No. -> CachePage*
CachedPagesMap;
//-------------------------------------------------------------------------
typedef enum { // CachedFileIO stats types
TOTAL_REQUESTS, // Total requests to cache
TOTAL_CACHE_MISSES, // Total number of cache misses
TOTAL_CACHE_HITS, // Total number of cache hits
TOTAL_BYTES_WRITTEN, // Total bytes written
TOTAL_BYTES_READ, // Total bytes read
TOTAL_WRITE_TIME_NS, // Total write time (ns)
TOTAL_READ_TIME_NS, // Total read time (ns)
CACHE_HITS_RATE, // Cache hits rate (0-100%)
CACHE_MISSES_RATE, // Cache misses rate (0-100%)
WRITE_THROUGHPUT, // Write throughput Mb/sec
READ_THROUGHPUT // Read throughput Mb/sec
} CachedFileStats;
//-------------------------------------------------------------------------
// Binary random access LRU cached file IO
//-------------------------------------------------------------------------
class CachedFileIO {
public:
CachedFileIO();
~CachedFileIO();
bool open(const char* path, size_t cache = DEFAULT_CACHE, bool readOnly = false);
bool close();
bool isOpen();
size_t read(size_t position, void* dataBuffer, size_t length);
size_t write(size_t position, const void* dataBuffer, size_t length);
size_t readPage(size_t pageNo, void* userPageBuffer);
size_t writePage(size_t pageNo, const void* userPageBuffer);
size_t flush();
void resetStats();
double getStats(CachedFileStats type);
size_t getFileSize();
size_t getCacheSize();
size_t setCacheSize(size_t cacheSize);
private:
void allocatePool(size_t pagesCount);
void releasePool();
CachePage* allocatePage();
CachePage* getFreeCachePage();
CachePage* searchPageInCache(size_t filePageNo);
CachePage* loadPageToCache(size_t filePageNo);
bool persistCachePage(CachePage* pageInfo);
bool clearCachePage(CachePage* pageInfo);
uint64_t maxPagesCount; // Maximum cache capacity (pages)
uint64_t pageCounter; // Allocated pages counter
uint64_t totalBytesRead; // Total bytes read
uint64_t totalBytesWritten; // Total bytes written
uint64_t totalReadDuration; // Time of read operations (ns)
uint64_t totalWriteDuration; // Time of write operations (ns)
uint64_t cacheRequests; // Cache requests counter
uint64_t cacheMisses; // Cache misses counter
std::FILE* fileHandler; // OS file handler
bool readOnly; // Read only flag
CachedPagesMap cacheMap; // Cached pages map
CacheLinkedList cacheList; // Cached pages double linked list
CachePage* cachePageInfoPool; // Cache pages info memory pool
CachePageData* cachePageDataPool; // Cache pages data memory pool
};
} Реализацию класса можно посмотреть тут CachedFileIO.cpp.
3. Тестирование CachedFileIO
Так как у меня на компе стоит только SSD для тестирования также купил HDD подключаемый через USB, чтобы сравнивать на разных типах устройств. По настоящему я удивился, когда увидел что скорость их работы одинаковая (!). Но потом понял в чем дело.

Интересно, что тестирование может оказаться более сложным занятием чем сама разработка. Например, потому что в операционной системе эффективно работает кэш файловой системы, плюс операции ввода/вывода ОС выполняются не синхронно (не немедленно), а добавляются в очередь. Это означает, что на относительно небольших объемах ввода/вывода, может показаться, что ввод/вывод осуществляется быстрее, чем реальная пропускная способность устройств. Замерять время в лоб — так себе идея. Поэтому для бенчмарков нужны достаточно большие объемы данных, которые превышают и объем кэша, и объем очередей ввода/вывода операционных систем. Также ранее упоминалось, что:
В ряде исследований есть статистика, что кэш размером 10–15% от размера базы данных даёт в среднем более 95% попаданий в кэш (cache hits), а соотношение операций чтения/записи примерно соотносятся как 70%/30%
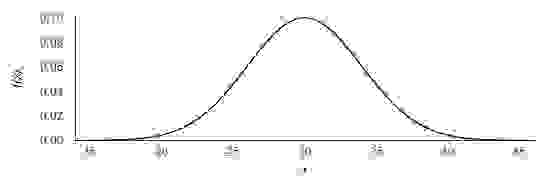
Для тестирования предположим, что запросы данных будут нормально распределены: σ =4% от размера базы и локализованы в каком то одном месте — для CachedFileIO без разницы даже если в нескольких, лишь бы локализованы. Примерно вот так:
Далее методом Box Muller`а будем генерировать нормально распределенные псевдослучайны числа, чтобы запрашивать разные участки файла (но нормально распределенные):
/**
*
* @brief Box Muller Method
* @return normal distributed random number
*
*/
double CachedFileIOTest::randNormal(double mean, double stddev)
{
static double n2 = 0.0;
static int n2_cached = 0;
if (!n2_cached) {
double x, y, r;
do {
x = 2.0 * rand() / RAND_MAX - 1.0;
y = 2.0 * rand() / RAND_MAX - 1.0;
r = x * x + y * y;
} while (r == 0.0 || r > 1.0);
double d = sqrt(-2.0 * log(r) / r);
double n1 = x * d;
n2 = y * d;
double result = n1 * stddev + mean;
n2_cached = 1;
return result;
}
else {
n2_cached = 0;
return n2 * stddev + mean;
}
}
Будем делать тестирование с миллионом итераций для каждого теста, мелкими порциями данных сравнивая результаты производительности работы CachedFileIO (read, write, readPage, writePage) и STDIO (fread, fwrite). Вот тут сам бенчмарк на коленках без использования каких либо фреймворков. И вот что получилось:
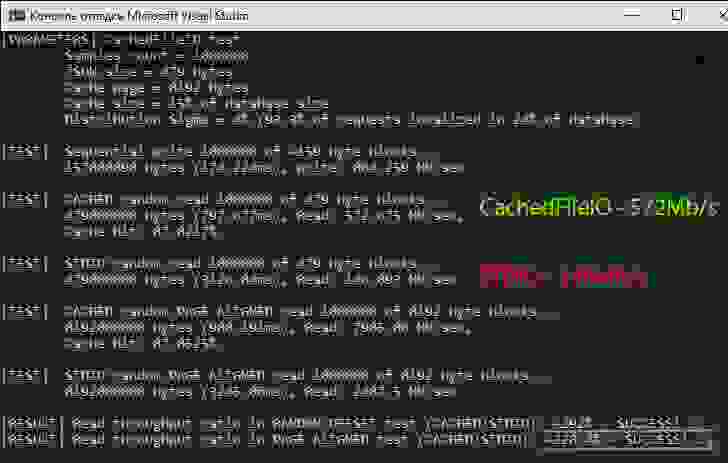
В release сборке сравнение производительности CachedFileIO и STDIO при многократных запусках с разными параметрами дало следующие результаты:
50%-97% попадания в кэш даёт от 50%-600% прироста производительности.
35%-49% попадания в кэш даёт от 12%-36% прироста производительности
1%-25% попаданий в кэш дают падение производительности от 5%-20%
Значит всё сработало как надо или, точнее, как ожидалось.
Наблюдение: почему-то в компиляторе MSVC в режиме debug очень «тормозят» итераторы и мешают измерениям. В 20–30 раз в сравнении с release. Приходилось отключать их отладку _ITERATOR_DEBUG_LEVEL.
Итак, конечно можно еще много что сделать в CachedFileIO, но на текущий момент его возможностей достаточно, чтобы переходить к разработке следующего слоя базы данных Boson — StorageIO.
До встречи!
