Битва медведей: Pandas против Polars
Привет! На связи Грегори Салиба из Spectr.
Возможно, вы прочитали название статьи и подумали, что попали на программу «В мире животных». Но нет, речь пойдет о сравнении двух гигантов аналитики данных в Python: Pandas и Polars. В этой статье мы подробно рассмотрим вопрос быстродействия этих двух решений в части работы с файлами больших объемов.
В статье мы сравним скорость обработки на примере конкретной задачи одного из проектов, разработку которого ведет наша команда.

Предыстория
Мы ведем разработку большой платформы для планирования и прогнозирования спроса и продаж в ритейле. В основе платформы лежит ML-движок на базе искусственного интеллекта, который выполняет ключевые функции: прогнозирование, факторный анализ, предписывающую аналитику.
Под капотом платформы более 10 микросервисов: от серверов очередей, которые координируют взаимодействие различных частей системы, до непосредственно ML-движков, которые на основе больших входящих датасетов с историей продаж строят прогнозы на будущее.
В рамках платформы идет обработка очень больших объемов данных, при этом очень важно сохранять качественный UX и высокую производительность работы системы — нам приходится выбирать используемые решения, в том числе учитывая скорость их работы.
Одна из задач, которая встала перед нами, — это загрузка в систему данных из больших xls-файлов, выгружаемых из внешних систем.
Подробное описание задачи
Простейший кейс использования платформы. Сидит планер и занимается прогнозированием спроса с учетом промокалендаря. В процессе он экспортирует данные о продажах из какой-то ERP-системы в виде файла и пытается загрузить этот файл в нашу платформу.
Как и какими файлами осуществляется загрузка данных? Не самый лучший, однако самый популярный формат — Excel. А точнее (это важно для нас как для разработчиков) — формат .xlsx. Ух, сколько проблем с этим форматом!
Загружаемые файлы имеют разную структуру и каждый тип загружаемого файла нужно смапить на определенные модели в БД. Кстати, тут у нас используется ClickHouse и работа идет через SQLAlchemy (а точнее, через пакет clickhouse-sqlalchemy).
До того как данные из файла попадут в базу — файл должен пройти многоступенчатую валидацию, , а именно:
валидация формата: проверка файла на соответствие ожидаемому формату (перечень и порядок столбцов);
валидация данных в файле:
наличие пустых значений в обязательных полях;
консистентность загружаемых данных (корректный тип данных для всех значений каждой колонки);
проверка на отрицательность (в некоторых колонках можно было допустить отрицательные значения, в некоторых — нет).
Изначально мы присмотрелись к Pandas, поскольку это популярный инструмент и примерно каждый девятый дата-аналитик из десяти точно им пользуется в своей работе.
Как устроена валидация данных
Как ориентир валидации был выбран метод dataclasses.dataclass. Сам метод, если вы с ним незнакомы, дает возможность валидировать данные через типизацию (хоть Python и не является жестко типизированным).
Как указано выше, валидация данных проходит в четыре этапа. Берется метод dataclass и для каждой колонки устанавливается четыре флага, участвующие в валидации (про последний флаг поговорим чуть позже):
флаг для обязательности поля;
флаг для указания типа поля;
флаг для отрицательности поля;
флаг для генерации полей Excel-файла.
@dataclass
class CSVFieldValidator:
code: str
is_required: bool
dataframe_type: type | datetime | str
type: type | datetime
negative: boolОбработка данных с Pandas
Логика обработки
Прочитав всевозможные форумы, которые хоть как-то намекали на повышение скорость обработки в Pandas, мы поняли, что метод .apply — это то, что необходимо для достижения этой максимальной скорости (само собой, мы видели комментарии насчет использования .numpy, но для нашего случая оно не очень подходило).
Переходя к цифрам, бессмысленно рассматривать файлы с количеством строк меньше 5к — тут на валидацию выходит меньше секунды. Поэтому мы рассматриваем варианты с 10к строк и выше.
По умолчанию чанки начинались с 10к строк. Результаты замеров с разными чанками также представлены ниже, только наберитесь терпения.
К сожалению, могу поделиться с вами только одной строкой для каждой валидации. Но не печальтесь: конкретная реализация логики валидации не влияет на приводимые в статье замеры.
Как механизм ускорения обработки, каждый DataFrame разделялся на чанки, чтобы запускать параллельные потоки через метод:
concurrent.futures.ProcessPoolExecutor()Проверка на пустые ячейки
Show_errors: pd.Dataframe =
dataframe_for_errors[~dataframe_for_errors[field.code].apply(lambda field_ value:
VALIDATION_DICT[field.type](field_value, field.type))]dataframe_for_errors — часть нашего датасета.
Выявляем все пустые ячейки внутри каждой колонки датасета (для датасета пустые значения — это автоматически NaN).
Проверка на тип данных
Show_errors: pd.Dataframe =
dataframe_for_errors[~dataframe_for_errors[field.code].apply(lambda field_ value:
VALIDATION_DICT[field.type](field_value, field.type))]VALIDATION_DICT — простой словарь, внутри которого значения ключей — это функции проверок, которые возвращают True/False в зависимости от проверенной ячейки.
Ранее как дополнительное условие валидации упоминалась «нормализация дробных чисел»:
self.data[field.code] = self.data[field.code]. \
apply(lambda value:
float(str(value).replace(',', '.', 1)) if not isinstance(value, float)
else float(value))
Проверка на отрицательность
Show_errors: pd.DataFrame = dataframe_for_errors[~dataframe_for_errors[field.code].apply(
lambda value: False if float(value) < 0 else True
)]
Результаты замеров c Pandas
Скорость валидации файлов, Pandas
Замеры производились на файле, который содержит 21 колонку, из которых 3 относятся к строкам, а все остальные — к дробным числам.
Результаты представлены в следующей таблице:
Количество строк | Секунд на обработку |
50к | 2.5 (1) |
100к | 4.8 (1) |
4.8 (2) | |
150к | 7.1 (1) |
7.1 (2) | |
200к | 9.5 (1) |
10.2 (2) | |
9.5 (3) | |
250к | 11.7 (1) |
13.8 (2) | |
12.3 (3) | |
300к | 14 (1) |
18 (2) | |
14.6 (3) | |
350к | 16.3 (1) |
23.6 (2) | |
18.2 (3) | |
400к | 18.7 (1) |
31.4 (2) | |
20.8 (3) | |
450к | 21 (1) |
36.4 (2) | |
26 (3) | |
500к | 23.2 (1) |
45.7 (2) | |
30.5 (3) |
(1) — без чанкания
(2) — чанки из 50к строк
(3) — чанки из 100к строк
Проанализируем данные таблицы:
Скорость обработки невысокая. Если смотреть правде в глаза, то признаем: все, что выше 10 — 15 секунд — медленная работа. Пока закроем на это глаза, ведь все-таки запускается детальная валидация с кучей проверок.
Момент странности заключается в том, что чанки никаким образом не помогают Pandas в ускорение процесса работы. Как раз наоборот, они замедляют его. Скорее всего это связано с тем, что сам Pandas оптимально для себя распределяет датафрейм для обработки, а мы лишь ему мешаем при добавлении параллельных потоков.
Скорость чтения файлов, Pandas
Результаты представлены в следующей таблице:
Количество строк | Секунд на обработку |
50к | 8.5 |
100к | 16.6 |
150к | 24.8 |
200к | 33.6 |
250к | 44.1 |
300к | 51.7 |
350к | 61.6 |
400к | 73.5 |
450к | 79.4 |
500к | 85.1 |
Время полной обработки файла завязано не столько на самой обработке DataFrame, сколько на его генерации и получении.
Дам совет: работайте с excel-файлом (если это будет через Pandas) только под дулом автомата, иначе вы будете тратить больше время на чтение файла, нежели на его обработку. Например, если возьмем файл с 100к строк, то он откроется приблизительно за 16 секунды, а обработается оптимально за 4.8 секунды (разница в 3.3 раз).
Скорость чтения различных типов файлов
Для сравнения, посмотрим на скорость чтения различных типов файлов. Ниже приведены результаты чтения файлов с расширением csv и parquet:
Количество строк | Секунд на обработку (CSV) | Секунд на обработку (Parquet) | Секунд на обработку (XLSX) |
50к | 0.13 | 0.01 | 8.5 |
100к | 0.23 | 0.027 | 16.6 |
150к | 0.35 | 0.04 | 24.8 |
200к | 0.53 | 0.05 | 33.6 |
250к | 0.62 | 0.06 | 44.1 |
300к | 0.71 | 0.07 | 51.7 |
350к | 0.8 | 0.08 | 61.6 |
400к | 0.98 | 0.09 | 73.5 |
450к | 1 | 0.12 | 79.4 |
500к | 1.2 | 0.2 | 85.1 |
Результаты замеров на графике:
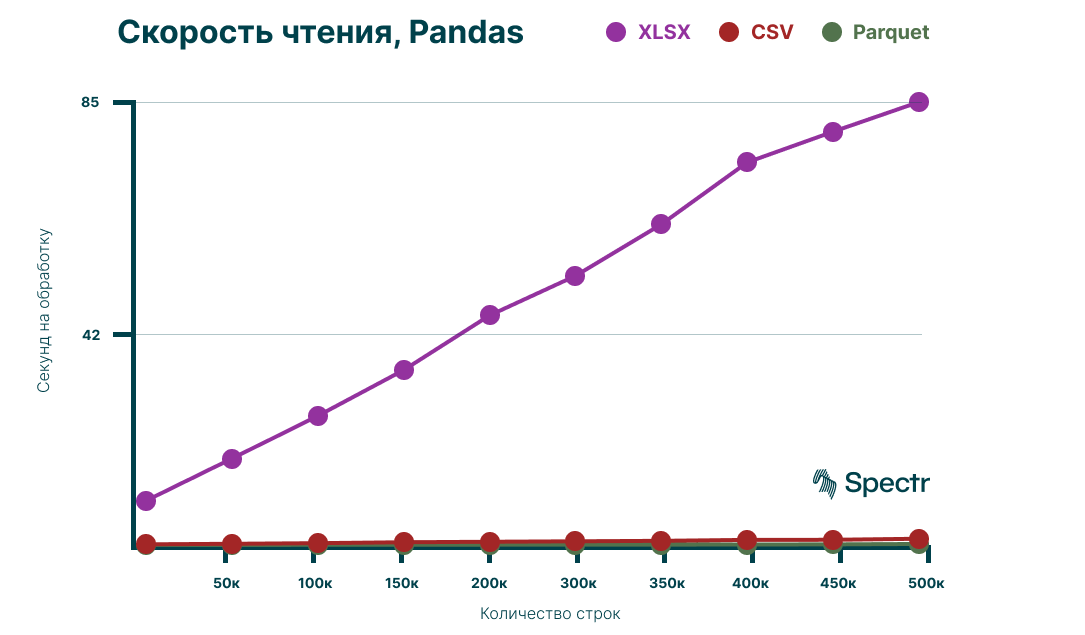
Как видим, разница колоссальная! Если взять среднее количество строк в 300к, например, и сравнить время чтения Excel-файла с CSV-файлом, то получается, что чтение CSV быстрее в 70–80 раз, чем чтение Excel-файла.
Если же сравнить с Parquet, то тут уже всё печально для Excel формата, разница в 700–800 раз.
Обработка данных с Polars
Того, что нам предлагала Pandas в части скорости, нам не хватало, и начались поиски другого инструмента.
Так на сцену вышел следующий игрок — Polars.
Polars имеет свой стиль и так же интуитивен, как и Pandas. Поэтому он и был выбран как потенциальная замена Pandas.
Логика обработки
Давайте посмотрим, что необходимо изменить в нашем коде, чтобы работать с Polars.
Сам Polars по разным причинам работает не через ProcessPoolExecuter, а только через theading.Thread. В дальнейшем мы воспользуемся этим для сравнения работы с параллелизмом и без него.
Посмотрим на основные функции валидации.
Валидация на наличии пустых ячеек в обязательных колонках:
show_errors: pl.DataFrame = dataframe_with_errors.filter(
pl.all(pl.col(field.code).is_null())
)Валидация на проверку типа данных:
show_error: pl.DataFrame = dataframe_with_errors.filter(
~pl.col(field.code).apply(lambda value: VALIDATION_DICT[field.type](value, field.type))
)Валидация на отрицательность:
show_errors: pl.DataFrame = dataframe_with_errors.filter(
pl.col(field.code).apply(lambda value: float(value) < 0))Нормализация дробных чисел:
self.data = self.data.with_columns([
pl.col(field.code).apply(lambda value:
float(str(value).replace(',', '.', 1)) if not isinstance(value, float)
else float(value))
])
Результаты замеров c Polars
Скорость валидации файлов, Polars
Для замеров использовался тот же набор файлов, что и в случае с Pandas.
Полученные результаты:
Количество строк | Секунд на обработку |
50к | 1.7 |
100к | 3.6 |
150к | 5.4 |
200к | 7.4 |
250к | 9.2 |
300к | 11.2 |
350к | 13.4 |
400к | 15.2 |
450к | 17.2 |
500к | 19.2 |
Что мы видим:
Polars впечатляет своими скоростями в сравнении с Pandas.
Для Polars также не нужны параллельные потоки, поскольку в его недрах прописан механизм, распределяющий нагрузку обработки датафреймов, что позволяет нам не думать об этом.
Скорость чтения файлов, Polars
Осталось проверить, открывает ли Polars файлы быстрее, чем Pandas, ведь этот процесс занимал у нас много времени. Посмотрим на возможности Polars через метод read_excel.
N.B. Polars еще славится тем, что можно использовать методом scan_excel, запуская фичу Lazy, и он отработает быстрее.
Результаты замеров:
Количество строк | Секунд на обработку |
50к | 6.4 |
100к | 12.6 |
150к | 19.1 |
200к | 26.4 |
250к | 33 |
300к | 40 |
350к | 45.3 |
400к | 51.2 |
450к | 57.2 |
500к | 71.8 |
Polars vs Pandas: чтение и валидация
Сопоставим полученные ранее результаты и посмотрим на них в виде графиков:
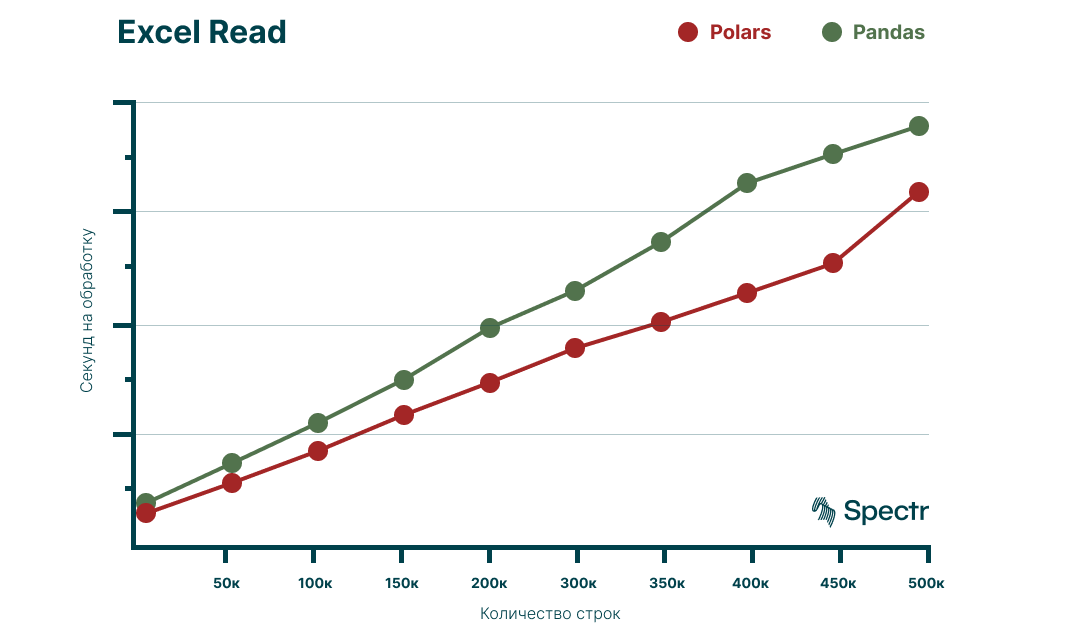
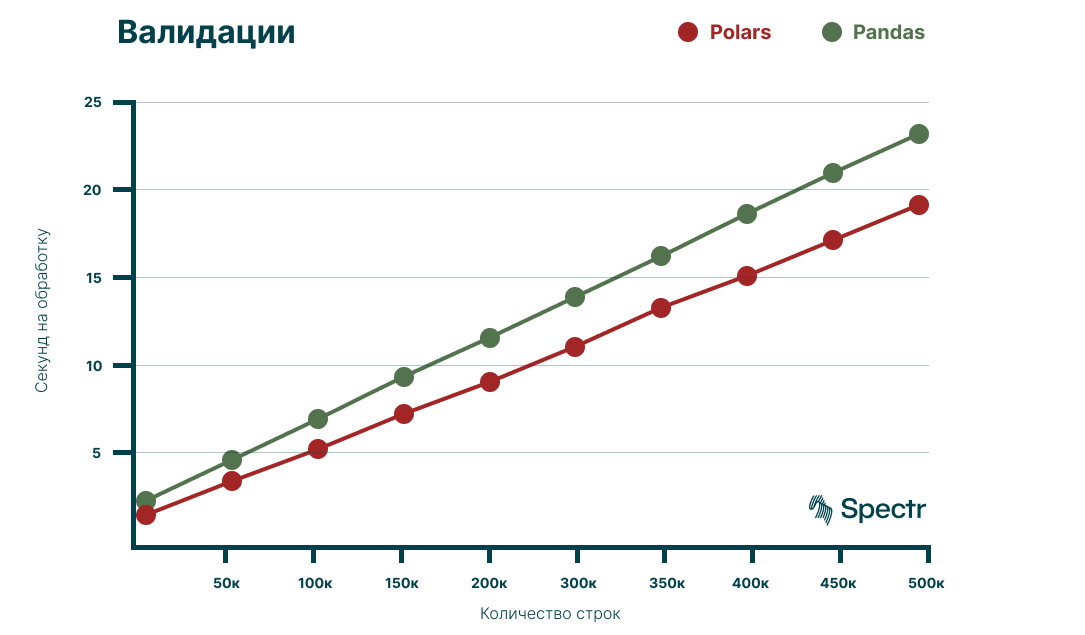
По результатам замеров Polars, в среднем, на 30 — 40% быстрее чем Pandas.
Polars vs Pandas, раунд 2: генерация файлов
Для полноты экспериментов сравним наших «медведей» в части генерации набора Excel-файлов.
Эта работа разделяется на следующие этапы:
— через Clickhouse-alchemy получаем данные;
— через метод to_excel/write_excel (Pandas, Polars) возвращаем контент в виде файлов, которые хранятся внутри переданного архива.
Что делать, если нам нужно сгенерировать и упаковать в архив одновременно 20+ файлов? Можно использовать параллельные потоки, это ускоряет работу. А помните, сколько времени занимало открытие одного файла? Думаете, что переход из DataFrame в файл Excel будет легче?
Начнем с того, что методы отличаются в одном моменте: у Pandas метод называется to_excel; у Polars — write_excel. Это кажется незначительным, но держим это в голове. Пришло время вспомнить о dataclass. Там оставался один флаг: dataframe_type. Данный флаг используется для нормализации типа данных датасета. Например, когда вы переводите данные из БД, тип float обозначается как float64. Datafarame_type помогает перейти в датасете с float64 к float32, что уменьшает затраты ресурсов на различные манипуляции, такие как запись в Excel-файл.
buffer = io.BytesIO()
df_result.to_excel(buffer)buffer = io.BytesIO()
df_result.write_excel(buffer)Получаем следующие результаты:
Количество строк | Polars (в секундах) | Pandas (в секундах) |
50к | 7.7 | 14.6 |
100к | 15.1 | 29.4 |
150к | 23 | 43.6 |
200к | 30 | 61.4 |
250к | 36.9 | 76.3 |
300к | 48.7 | 90.8 |
350к | 52.7 | 107.8 |
400к | 65.5 | 127.6 |
450к | 75.6 | 141.7 |
500к | 84.7 | 148 |
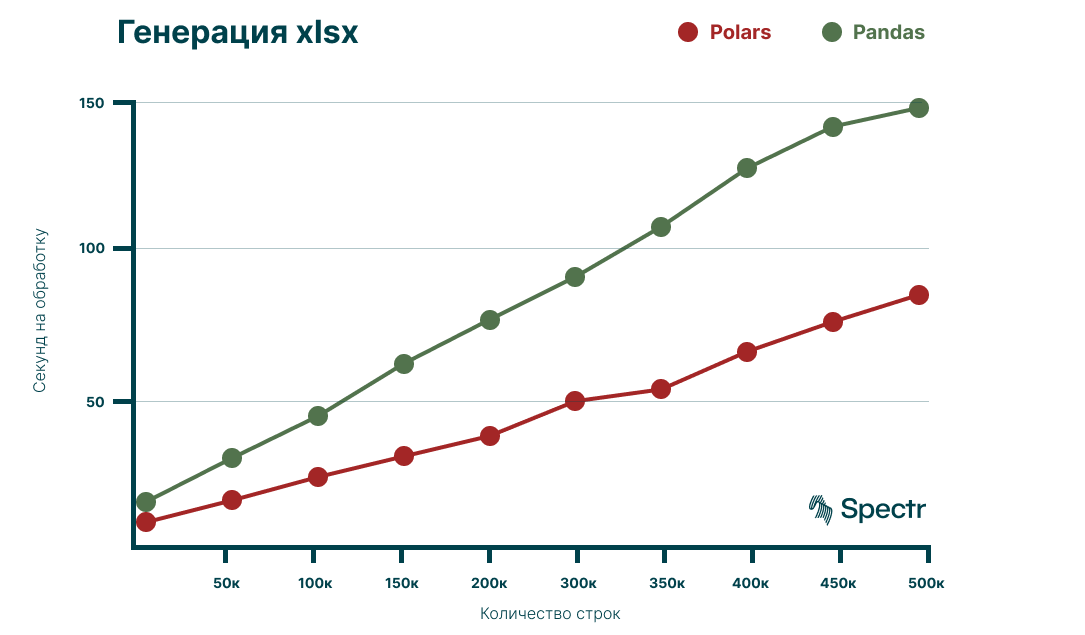
Видно, что Polars требует в 2 раза меньше времени на полную обработку.
Вдобавок к мощному языку Rust, Polars еще дополняется Apache-Pyarrow — механизмом, который решает вопросы с выделением памяти каждому типу данных.
Для наглядности оставлю таблицу генерации файлов в формат csv с помощью Polars:
Количество строк | Секунд на обработку |
50к | 0.04 |
100к | 0.08 |
150к | 0.1 |
200к | 0.18 |
250к | 0.23 |
300к | 0.25 |
350к | 0.27 |
400к | 0.33 |
450к | 0.37 |
500к | 0.46 |
Разница в генерации получается примерно в 190 раз. Тут сами делайте свои выводы.
Заключение
В рамках экспериментов были использованы следующие версии библиотек: Pandas == 2.0.2; Polars == 0.17.12.
Я не пытаюсь переманить вас на сторону «белого медведя» Polars. Это лишь наблюдение, полученное при решении конкретной задачи.
P.S. Если у вас имеются замечания или пожелания, пишите, пожалуйста, в комментарии. Я буду читать и учту их, когда продолжу делиться своими наблюдениями!
