Bitrix и Kafka: настраиваем интеграцию с брокером очередей
Привет! Меня зовут Саша Шутай, я тимлид в AGIMA. В прошлой статье я рассказывал, что делать, если на проекте Bitrix сожительствует с Vue.js и поисковые боты не видят контента сайта. А в этой помогу разобраться, как на Bitrix-проекте произвести интеграцию с брокером очередей Apache Kafka, почему этот вариант кажется мне более удобным, чем привычная система очередей в RabbitMQ, и как это можно подвязать на автотесты, не отправляя тестовые сообщения в продюсера.

Когда это пригодится
Но сначала давайте определимся, когда вообще может возникнуть необходимость в такой интеграции. Представьте: вы поддерживаете интернет-магазин, который является частью большой IT-инфраструктуры. В этой инфраструктуре много компонентов: сайты, складской учёт, хранилища данных, системы лояльности, офлайн-продажи и другие информационные системы. Все они могут быть разработаны на разных языках программирования, в разных фреймворках, представлять собой совсем разные продукты, которые ничего не знают про внутреннюю реализацию друг друга. И вот тут вопрос: как заставить все системы работать слаженным механизмом, иметь единый контекст и общую точку синхронизации и обмена данными? Причем взаимодействие должно быть асинхронным, чтобы нивелировать скачки нагрузки и гарантировать доставку информации.
По всей видимости, необходима централизованная система, которая позволяет связать все компоненты. Нужно, чтобы она обеспечивала прием информации, хранение и её отдачу по запросу сразу нескольким потребителям. Сообщения не должны удаляться из хранилища после их обработки и должны быть доступны для прочтения в любой момент времени разными потребителями.
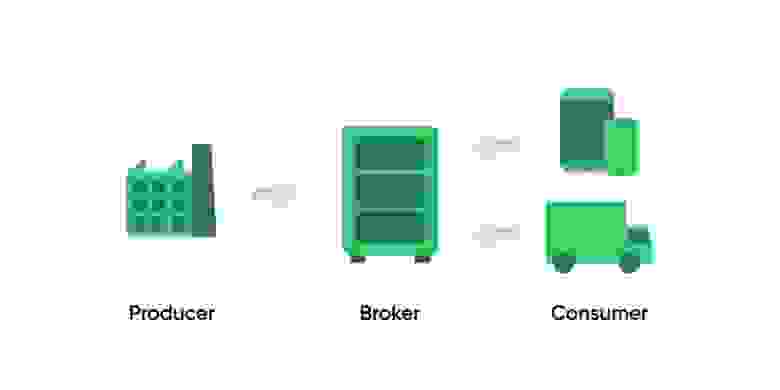 Обмен сообщениями между системами
Обмен сообщениями между системами
В этой схеме обмена сообщениями между разными системами мы видим три основные роли:
Producer — публикатор сообщений, которые должны быть считаны другими системами.
Broker — хранилище сообщений, которое отдает сообщения по запросу, ведет учет того, кто, когда и что опубликовал или прочитал.
Consumer — потребитель, считывающий сообщения.
Обратите внимание на стрелки, ведущие от Consumer к Broker. Так на схеме показано, что потребитель является инициатором запроса и сам регулирует нагрузку, с которой он хочет обрабатывать сообщения и сам их считывает по мере необходимости. В терминологии очередей такой подход называется Pull-model.
Почему Apache Kafka
Опытные читатели могут прервать меня и сказать, что в этом случае можно использовать хорошо знакомый всем механизм для временного хранения и распределения информации — систему очередей. Например, подошла бы популярная в PHP-стеке RabbitMQ. Эта концепция позволит быстро отправить информацию от поставщика сразу нескольким потребителям, каждому в собственную очередь.
Но практика показывает, что чем больше консьюмеров задействовано, чем больше очередей создано и чем больше информации передается, тем чаще не хватает производительности RabbitMQ, который, конечно, поддерживает горизонтальное масштабирование, но оно не очень адаптивное. При подключении нового потребителя создавать новую очередь и отправлять в неё старые данные для «истории» становится накладным. Поэтому для решения задач такого масштаба, по моему мнению, лучше использовать брокер Apache Kafka.
Вот преимущества, которые мы получим, используя эту стриминговую платформу:
сообщения после прочтения не удаляются в течение заданного времени; это позволяет при подключении новых консьюмеров дать им возможность прочитать уже прочитанные другими системами данные;
нет необходимости заводить поток сообщений под каждого консьюмера;
гарантия, что сообщения будут прочитаны в порядке их попадания в хранилище;
можно изменить позицию, с которой считываются сообщения; это позволяет при необходимости прочитать сообщения заново;
адаптация к горизонтальному масштабированию «из коробки»;
быстрая архитектура отдачи сообщений за счёт метода хранения информации, когда доступно последовательное считывание с физического диска;
сбор и агрегации событий из нескольких источников.
Планирование архитектуры взаимодействия
Вернемся к нашему примеру. Вы поддерживаете интернет-магазин на PHP и фреймворке Bitrix. Вы согласились со мной и решили, что для обогащения данных в БД и отправки целевой информации в другие системы необходимо интегрироваться с Apache Kafka. В этом случае сайт будет в роли как поставщика (Producer), так и потребителя (Consumer). Давайте рассмотрим их подробнее.
Роль Consumer
Когда Kafka используется как поставщик данных, для взаимодействия с ней используется Pull-model. Поэтому сайт самостоятельно должен обращаться к Broker для получения сообщений. При чтении сначала посылается запрос receive и получается тело с информаций для обработки. А когда сайт успешно обработал информацию, отправляется запрос ack. Он сообщает, что все работы произведены и можно передвинуть Offset на следующее сообщение.
Здесь можно сразу дать определение топика. Это сущность, агрегирующая в себе сообщения одной категории. Поставщики данных публикуют сообщения в топик, а потребители подписываются на топик и считывают эти сообщения из него.
Важный момент: после запроса с типом receive метка текущего сообщения в брокере не будет сдвинута, пока не будет запроса ack. И все последующие запросы receive будут возвращать одно и то же сообщение. Учитывайте это, если планируете считывать информацию из одного топика в несколько потоков. В зависимости от настроек Kafka, вам может быть доступен ключ autoAck, когда после запроса receive система автоматически перемещает метку на следующее.
Запускаем фоновый процесс, который будет с некоторым интервалом обращаться в Kafka, получать сообщения и отправлять их на выполнение. Для управления пуллом процессов мы используем Supervisord. Поэтому и в этой задаче, чтобы процесс был стабильным, запускаем его через демона. Также в нашей реализации управления процессами можно задавать для каждого инстанса delay/частоту опроса.
 Схема взаимодействия роль Consumer
Схема взаимодействия роль Consumer
Роль Producer
Здесь всё просто. Нужно отправлять сообщения send. Инициировать отправку сообщения можно на событии создания/изменения необходимой сущности Bitrix. Если важно гарантированно отправить сообщение с учётом, что сервис Kafka может быть недоступен по техническим причинам, то можно использовать такие подходы:
С двумя очередями RabbitMQ. Если планируется, что поток сообщений очень большой и нам требуется самими регулировать/ограничивать его пропускную способность (с помощью очереди и числа воркеров, с ней работающих).
С синхронным запросом и одной очередью RabbitMQ. Первый раз сообщение отправляется в момент его появления в системе. Если оно не было доставлено, то помещается в очередь и воркер будет его пытаться отправить до успешного раза.
Расскажу, как это работает в первом варианте. Создается две очереди. Каждую очередь обслуживает собственный фоновый процесс Worker. В первой очереди, «быстрой», Worker ожидает сообщение и после этого засыпает на более короткое время, чем во второй, «медленной» очереди.
Worker «быстрой» очереди пытается отправить сообщение в Kafka. Если отправка не удалась, то сообщение помещается в «медленную» очередь. Worker «медленной» очереди также пытается отправить сообщение в Kafka. В случае неудачи сообщение снова помещается в конец «медленной» очереди. Тем самым, в случае технической ошибки на стороне брокера, препятствующей получению данных, сообщения не будут потеряны и не будут с большой частотой отправляться в нерабочий сервис.
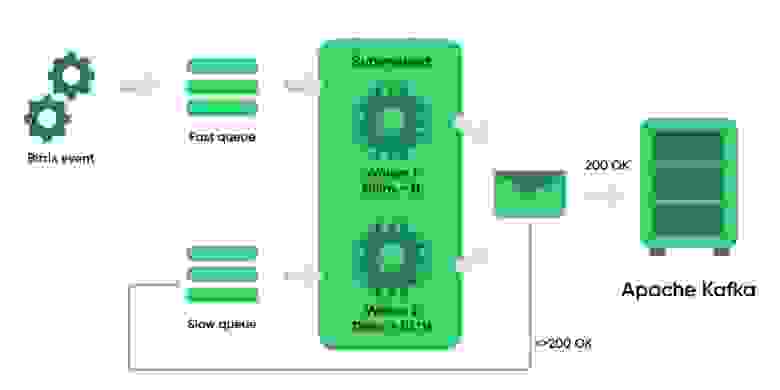 Схема взаимодействия роль Producer
Схема взаимодействия роль Producer
Построим REST клиента
Поскольку ваш стек — PHP, скорее всего, разработчики Kafka предоставят вам REST API, с помощью которого производится взаимодействия всех систем в архитектуре. Поэтому разработаем каркас нашего клиента для обмена данными. Для начала спроектируем интерфейс. Его наличие позволит в будущем реализовать несколько клиентов: основной, для тестирования и т. д. Он должен требовать реализацию основных методов работы с сообщениями: receive, ack, send. Потом добавим системный класс Topic, возвращающий наименования топиков для чтения и записи согласно необходимой внутренней логике (если такая присутствует в архитектуре).
 Структура интерфейса клиента
Структура интерфейса клиента
Добавим класс RestClient и реализуем в нем все методы взаимодействия с внешней системой, а также дополнительные вспомогательные методы, касающиеся схемы конкретного протокола взаимодействия. В нашем случае это initClient, возвращающий объект битриксового Bitrix\Main\Web\HttpClient с предустановленными авторизационными кредами и заголовками.
Получить данные из внешней системы — это, конечно, хорошо, но хочется иметь строгий механизм для работы с полученными данными в любом месте нашей системы. Приведем ответ Kafka на наш запрос к классу Result, хранящему структурированную информаций: код ответа (успешен или нет), заголовок и тело сообщений.
 Структура клиента
Структура клиента
Разработав методы обмена сообщениями, добавим в систему Actor для потребления и обработки сообщений. Реализуем чтение в абстрактном классе Consumer. Сам процесс предполагает 3 этапа:
Receive (запрос на получение сообщения);
Processe (валидация и обработка);
Ack (запрос на перемещение указателя во внешней системе).
Для поллинга в методе poll () запускаем бесконечный цикл, который производит запрос на чтение, вызывает методы валидации и обработки и перемещает указатель, если сообщение было успешно обработано. После каждой итерации вызываем «засыпание» процесса. С целью оптимизации можно добавить такую механику: если receive вернул сообщение, то следующую итерацию запускать через N времени.
Если же сообщение не вернулось (очередь пуста), то «засыпать» на 10*N. Как уже говорилось выше, за работоспособность процесса следит Supervisord.
Мы хотим, чтобы конкретные реализации Consumer описывали, как именно следуют парсить тело сообщения parseMessage () и обрабатывать полученные данные processMessage (). И имели возможность отфильтровывать заведомо бесполезные для вашей системы сообщения (если такое предполагается в архитектуре) isAllowedMessage ().
 Структура Consumer
Структура Consumer
Финальный класс, который потребуется для базовой реализации взаимодействия, это поставщик Producer. Процедура отправки одинакова для всех поставщиков, поэтому Send реализуется в абстрактном классе. А его наследники должны реализовывать createMessage (), собирающий сообщение в нужном для потребителя формате.
 Структура Producer
Структура Producer
Тестирование
Всё, мы разработали архитектуру и реализовали клиента для работы с внешней системой. Теперь предположим, что вы унаследовали своих потребителей и поставщиков от Consumer и Producer и вам нужно передать всё это в тестирование, а затем связать с системой автотестирования.
Поскольку в общей инфраструктуре с Kafka связано множество систем, то вам будет сложно организовать процесс, чтобы другие приложения публиковали новые сообщения с тестовыми данными для каждого вашего Pull Request. И если в роли Producer за корректную валидацию сообщений технически может отвечать сама Kafka, то в роли Consumer вам нужно как-то самим удостовериться, что сообщение правильно вами обработано.
Поскольку вас заинтересовала эта статья, а она посвящена PHP и Bitrix, то, скорее всего, в вашем стеке уже имеется RabbitMQ. Да и скорее всего, для интеграции с ним используется php-amqplib/php-amqplib:) Так вот что, если использовать возможность RabbitMQ работать по Pull-модели? Поскольку у нас уже имеется интерфейс для клиента IClient, то добавить RabbitClient не составит труда. Достаточно реализовать методы send, receive и ack с учётом семантики Rabbit.
Один из вариантов решения проблемы тестирования интеграции — разработка локального сервиса, который бы имитировал работу Kafka и давал интерфейсы для автоматического и ручного заведения сообщений. В процессе создания такого сервиса вы будете разрабатывать специфический программный код, который не должен уйти в prod. Мы используем подход, когда все сторонние интеграции для разработки и тестирования выносятся на отдельную виртуальную машину. Поэтому сделали mock, имитирующий работу Kafka и состоящий из двух частей: RabbitMQ для реализации системы хранения сообщений и REST-сервис (на Symfony) для реализации вышеописанного REST API. Вы можете использовать любой знакомый вам PHP-фреймворк для разработки REST-сервиса.
В дальнейшем при тестировании, в зависимости от использования среды QA, prod, автоматизированно или вручную менять используемого клиента по умолчанию.
Заключение
В итоге после всех работ, согласно вышеописанному подходу, в приложении получается такая архитектура:
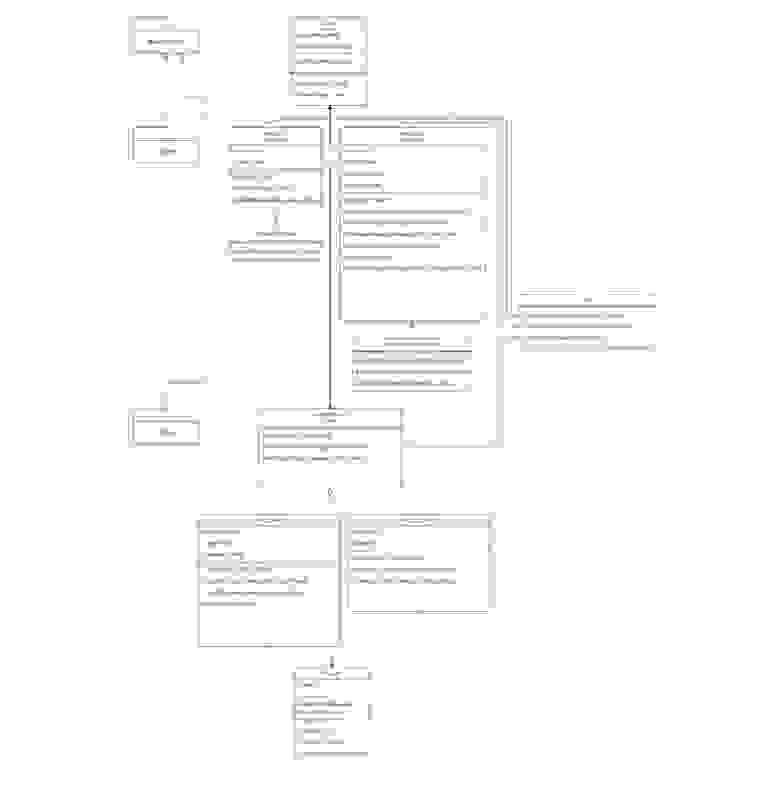 Структура приложения для интеграции с Apache Kafka
Структура приложения для интеграции с Apache Kafka
Этой архитектуры будет достаточно для базового взаимодействия с Apache Kafka. В дальнейшем, в зависимости от настроек Kafka, можно добавлять методы для оптимизации обмена. Например, читать в Batch-режиме, разбивать потоки с помощью Partition и т. д.
Надеюсь, статья была полезна. Я постарался максимально подробно рассказать об этой интеграции. В комментариях задавайте вопросы, буду рад ответить. И если считаете, что другое решение было бы более удобным, то тоже пишите — интересно обсудить.
Список использованной литературы
Apache Kafka: основы технологии
RabbitMQ Tutorial one PHP
Брокер сообщений
Apache Kafka®. Управляемые базы данных
Apache Kafka: обзор
