Безопасность алгоритмов машинного обучения. Атаки с использованием Python

Машинное обучение активно применяется во многих областях нашей жизни. Алгоритмы помогают распознавать знаки дорожного движения, фильтровать спам, распознавать лица наших друзей на facebook, даже помогают торговать на фондовых биржах. Алгоритм принимает важные решения, поэтому необходимо быть уверенным, что его нельзя обмануть.
В этой статье, которая является первой из цикла, мы познакомим вас с проблемой безопасности алгоритмов машинного обучения. Это не требует от читателя высокого уровня знаний машинного обучения, достаточно иметь общее представление о данной области.
Сначала приведем термины, использующиеся в тематике безопасности алгоритмов машинного обучения:
Adversarial пример — вектор, подающийся на вход алгоритму, на котором алгоритм выдает некорректный выход.
Adverasial атака — алгоритм действий, целью которого является получение Adversarial примера.
Чтобы понять проблему Adversarial примеров, давайте вспомним одну из задач машинного обучения — обучение с учителем при классификации. В данной задаче у нас есть пары «объект-метка», и мы должны научиться предсказывать значение для новых объектов.
Если рассмотреть эту задачу с геометрической точки зрения, то необходимо разделить пространство таким образом, чтобы на новом объекте предсказать «правильный» класс. Более того, если бы мы имели генеральную совокупность данных (например, для набора рукописных цифр MNIST иметь всевозможные изображения всех цифр), то данную гиперплоскость можно было бы провести идеально при условии разделимости классов. Но так как генеральной совокупности чаще всего не бывает, то для этого мы и используем алгоритмы машинного обучения —, чтобы максимально точно приблизить «идеальную» гиперплоскость с помощью тех данных, что у нас есть.
Любое отклонение гиперплоскости от идеальной, порождает некоторый «зазор», попадая в который, объекты классифицируются некорректно. Именно поэтому и появляются такие примеры, как панда, классифицированная как гиббон. А задача атакующего сводится к изменению вектора параметров объекта таким образом, чтобы он попал в этот «зазор».
Примеры Adversarial атак
Имеется нейронная сеть, детектирующая лицо на фотографии. Она успешно справляется с поставленной задачей (1 рисунок). Но после добавления к этой фотографии незначительного шума (3 рисунок), алгоритм на полученном adversarial примере (2 рисунок) больше не детектирует лицо на изображении.

Данный пример, продемонстрированный в статье «Adversarial Attacks on Face Detectors using Neural Net based Constrained Optimization», интересен тем, что множество реальных системы распознавания лиц используют для детектирования лиц именно нейросетевые подходы.Человек же не заметит разницы при взгляде на оба изображения.
Следующий пример был взят из automotive, а именно распознавание дорожных знаков. Этот пример интересен тем, что adversarial example не обязательно должен быть объектом хоть сколько-то близким к объектам, на которых обучалась сеть. Например, в работе «Rogue Signs: Deceiving Traffic Sign Recognition with Malicious Ads and Logos» было показано, что полученный adversarial пример знака KFC будет распознан исходной нейронной сетью как знак СТОП с вероятностью 100%.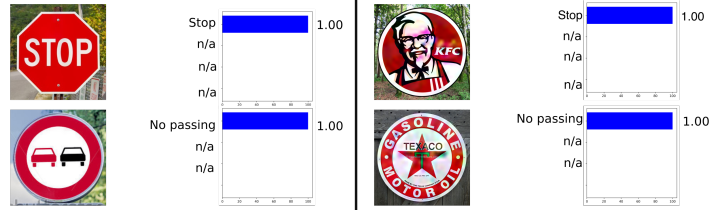
Многие могли усомниться в использовании adversarial examples в реальном мире, так как предыдущие примеры были протестированы на компьютере, тогда как в реальной жизни такой объект вряд ли возможно получить. Но это не так. В работе «Synthesizing Robust Adversarial Examples» было показано, что сделанный на компьютере adversarial пример может быть успешно распечатан на 3D принтере, и алгоритм будет допускать такие же ошибки, как и при компьютерной симуляции.
Здесь вы видите черепаху, распечатанную на 3D принтере, которая не была распознана как черепаха ни под одним углом.
Следующий же пример показывает, что можно сделать, если пойти дальше обычного понимания adversarial атаки. А именно перепрограммировать исходную сеть для использования своей собственной полезной нагрузки. Иначе говоря, мы обучаемся использовать чужую нейронную сеть для решения задачи, поставленной атакующим. Например, в работе «Adversrial Reprogramming of Neural Network» было продемонстрировано, как сеть, обученная на ImageNet, отлично посчитала количество квадратов на изображении и распознало цифры из набора MNIST.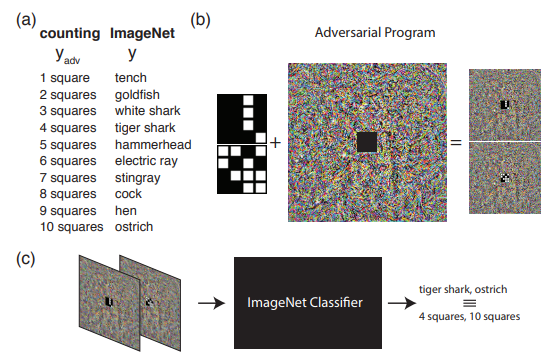
В данной статье хотелось бы поговорить именно о способах генерации Adversarial примеров, а во второй статье мы перейдем к способам защиты и тестирования алгоритмов машинного обучения.
Классификация атак
Все атаки можно разделить на 2 класса: WhiteBox (WB) и BlackBox (BB). В случае с WB нам известна вся информация об обученной модели алгоритма, тогда как в случае с BB у нас есть доступ только к входу и выходу модели. Честно говоря, еще возможен GrayBox вариант, когда нам не известна информация об обученной модели, но имеется информация о типе алгоритма и его гиперпараметрах.
Далее стоит классифицировать атаки на Targeted и Non Targeted. Targeted атаки подразумевают, что атака совершается в определенном направлении. Например, на наборе данных MNIST мы обучим нейронную сеть и возьмем изображение 0 из тестового набора. Обученная нейронная сеть выдает вероятность класса 0 в этом объекте равную 1.00. Если мы хотим, чтобы после применения adversarial атаки, adversarial пример был распознан как класс 1, тогда мы применим Targeted атаку, иначе, если нам не особо важно к какому классу отнесет нейронная сеть полученное изображение (главное, что это больше не класс 0), тогда такая атака будет Non Targeted.
Кроме того, атаки делятся на метрику, по которой 2 объекта считаются схожими —  нормы.
нормы.  норма — количество измененных параметров.
норма — количество измененных параметров.  евклидово расстояние между двумя векторами.
евклидово расстояние между двумя векторами.  максимальная поэлементная разница между двумя векторами.
максимальная поэлементная разница между двумя векторами.
Библиотеки на Python
Данные Python библиотеки позволяют работать с Adversarial примерами. Это FoolBox, CleverHans и ART-IBM.
| Foolbox | CleverHans | ART-IBM | |
|---|---|---|---|
| Поддерживаемые фреймворки | TensorFlow, Keras, Theano, PyTorch, Lasagne, MXNet | TensorFlow, Keras | TensorFlow, Keras, общеают MXNet, PyTorch |
Теперь давайте немного подробнее разберем атаки, и начнем с WhiteBox атак.
L-BFGS атака
Постановку метода L-BFGS можно записать следующей формулой.
Из нее следует, что мы хотим минимизировать функцию потерь в направлении target класса с ограничением, что вносимые изменения были минимальными. При этом решать такую задачу в исходной статье предлагалось именно с помощью L-BFGS метода, отсюда и название данной атаки.
Исходная статья — «Intriguing properties of neural networks»
Данная атака представлена в 2 из 3 ранее озвученных библиотек — FoolBox и CleverHans.
А применение данной атаки на FoolBox занимает 3 строчки кода на Python:
from foolbox.attacks import LBFGSAttack
attack = LBFGSAttack(fmodel)
adversarial = attack(image, label)
Использование L-BFGS поможет вам найти оптимальные adversarial-примеры, исходя из ваших ограничений, но, во-первых, поиск такого примера может занять длительное время, а, во-вторых, вполне возможно, что метод просто не сойдется.
FGSM атака
Следующим этапом развития стал метод FGSM (Fast Sign Gradient Method), который можно показать с помощью формулы:

Данный метод работает намного быстрее L-BFGS. Здесь мы просто берем знаки от функции градиента исходной функции потерь, умножая знак на некоторый  , прибавляем к исходному изображению.
, прибавляем к исходному изображению.
Вот пример работы данного метода. К фотографии панды добавляется шумовая карта с равной 0.007, и получается, что фотография панды теперь распознается как Гиббон с вероятностью 99.3%
Данный метод отличается простотой имплементации, но при этом, результат работы данного метода является сильно зашумленным.
Исходная статья — Explaining and Harnessing Adversarial Examples
Найти реализацию этого метода можно в библиотеках, а применение на foolbox так же не займет много времени
from foolbox.attacks import FGSM
attack = FGSM(fmodel)
adversarial = attack(image, label)
DeepFool атака
DeepFool является Non Targeted методом. Его основное отличие от предыдущих методов том, что он старается сделать минимальную шумовую карту, которая обманет алгоритм. Метод не позволяет сделать из одного класса какой- то конкретный класс, а делает любой другой, который ближе всего к исходному изображению.
На примере видна исходная картинка, на 3 строке — FGSM метод, а по середине — как раз DeepFool атака. Видно, что шумовая карта сильно меньше, чем при FGSM.
Исходная статья — DeepFool: a simple and accurate method to fool deep neural networks
Такую атаку можно провести с использованием любой из перечисленных библиотек, а реализация на ART-IBM занимает всего 3 строчки кода:
from art.attacks import DeepFool
attack = DeepFool(model)
img_adv = attack.generate(img)
Jacobian saliency map атака
В JSMA методе считается прямая производная, на основании чего строится карта градиентов. На карте каждому параметру объекта по факту соответствует вклад данного параметра в изменение конечного результата работы алгоритма. Тем самым метод позволяет изменить как можно меньше параметров в атакуемом объекте. И, соответственно, работает по норме.
Исходная статья — The Limitations of Deep Learning in Adversarial Settings
Данную атаку можно провести, используя CleverHans или ART-IBM.И на CleverHans это выглядит следующим образом:
from cleverhans.attacks import SaliencyMapMethod
jsma = SaliencyMapMethod(model, sees=sees)
jsma_params = { 'theta' : 1., 'gamma' : 0.1,
'clip_min' : 0., 'clip_max' : 1.,
'y_target' : None}
adv_x = jsma.generate_np(img, **jsma_params)
One pixel атака
Логичным будет вопрос, а какое минимальное количество пикселей необходимо изменить, для того чтобы провести атаку на алгоритм, и как многие уже догадались по названию атаки, достаточно 1 пикселя.
Например, изображение лошади всего лишь с одним измененным пикселем становиться лягушкой с вероятностью 99.9%
Исходная статья — One pixel attack for fooling deep neural networks
Данная атака поддерживается только в FoolBox, и ее проведение выглядит следующим образом:
from foolbox.attacks import SinglePixelAttack
attack = SinglePixelAttack(fmodel)
adversarial = attack(image,max_pixel=1)
Здесь стоит оговориться и сказать, что реализация в Foolbox хоть и имеет общую цель (изменить конкретное кол-во пикселей в изображении), но реализация отличается от той, что приведена в исходной статье
Методы основанные на обобщение BlackBox модели
Для большинства методов требуется понимание того, как устроена архитектура модели, знание точных значений ее параметров, но на практике такое возможно достаточно редко. И именно поэтому появляется отдельное направление атак — BlacBox/GrayBox атаки. Для таких атак достаточно иметь доступ к входу и выходу модели.
Один из методов, позволяющих реализовать атаку на BlackBox модель — это обобщение данной модели в Student (на картинке Substitute) модели.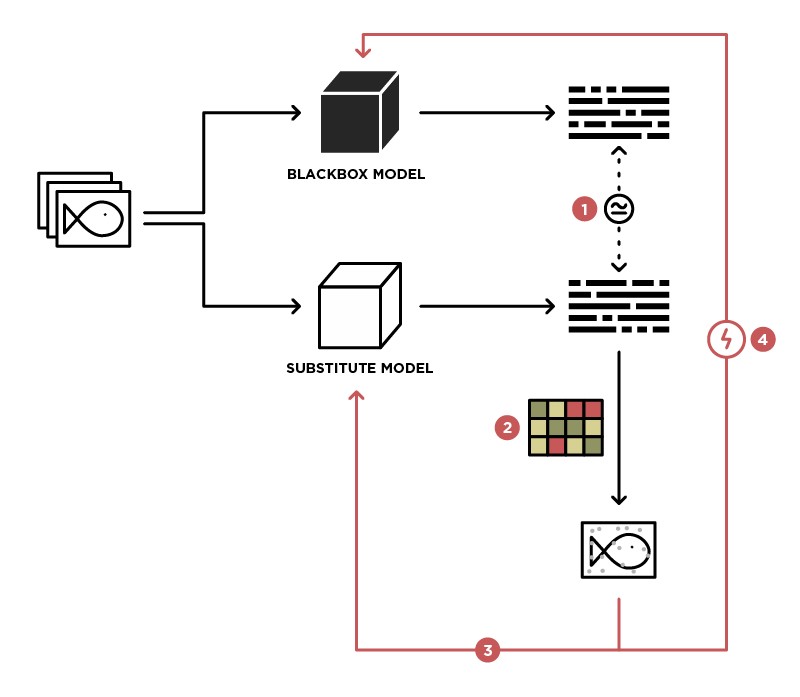
Имея доступ к отправке данных в BlackBox модели (Teacher) и доступ к выходу данной модели, мы можем сформировать датасет, на котором возможно обучить собственную модель (Student), тем самым обобщив Teacher модель. После этого можно применить WhiteBox атаку на Student модель, и с большой долей вероятности данная атака пройдет и на Teacher модели. Вероятность такой атаки тем выше, чем больше знаний о Teacher модели мы имеем. Например, мы знаем, что Teacher модель обрабатывает изображения, чаще всего для обработки изображений используются пред-обученные архитектуры (ResNet, Inception) с весами ImageNet. Взяв за основу Student модель с той же архитектурой, вероятность успешной атаки будет максимальна.
Исходная статья — Practical Black-Box Attacks against Machine Learning
Данный метод не представлен ни в одной из библиотек и требует самостоятельной имплементации Student модели, а атаки на нее можно проводить, руководствуясь описанными выше методами.
GAN-based методы
Следующим этапом развития BlackBox атак стали атаки, основанные на встраивание BlackBox модели в архитектуру генеративной сети.
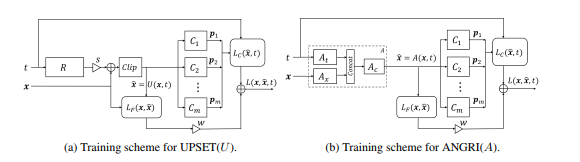
Данный метод позволил сгенерировать adversarial примеры практически для любой архитектуры. Для его работы также требуется доступ к входу и выходу атакуемой модели.
Почитать подробнее об этом методе можно в исходной статье — UPSET and ANGRI: Breaking High Performance Image Classifiers
Как вы могли догадаться, данные методы не представлены ни в одной из библиотек.
Заключение
На самом деле, существует большое количество атак, здесь рассмотрены только некоторые из них. Мы надеемся, что данный материал помог вам понять базовые концепции adversarial примеров и алгоритмов их генерации. Для более подробного ознакомления советуем почитать оригинальные статьи и познакомиться с материалами из списка литературы.
До встречи в следующей статье, где речь пойдет о методах защиты и тестирования алгоритмов машинного обучения.
Список литературы
- Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey — большой обзор методов нападения на алгоритмы глубокого обучения в задаче Computer Vision
- Attacking Machine Learning with Adversarial Examples — блог компании OpenAI посвященный adversarial examples
- Awesome Adversarial Machine Learning — гитхаб с ссылками на множество полезных материалов по Adversarial тематике
- Презентация на тему Adversarial Machine Learning — Презентация с конференции MoscowPythonConf2018 по тематике Adversarial Machine Learning
