Бессерверная альтернатива традиционным базам данных
Современная распределенная СУБД должна уметь поддерживать различные типы нагрузки, удовлетворяя запросы совершенно разных пользователей. СУБД Yandex Database позволяет не только хранить петабайты данных, поддерживать обработку миллионов запросов в секунду, но и предоставляет режим бессерверных вычислений. Эта платформа дает возможность обслуживать проекты с различными типами нагрузки: ключ-значение, традиционные веб-приложения на основе реляционной базы, а также документоориентированные базы данных.
Бессерверные вычисления применяются сейчас в различных сферах — от создания чат-ботов и приложений Интернета вещей до самостоятельных API доступа к сервисам по протоколу HTTP. Платформы для развертывания бессерверных вычислений имеются как у большинства поставщиков облачных решений Yandex Cloud Functions, Amazon Web Services Lambda, Google Functions), так и у Open Source сообщества.
Переход от «железных» серверов к виртуализации и контейнеризации в свое время привел к появлению культуры DevOps, рождению подходов Infrastructure as Code, предоставив возможность больше времени уделять бизнес-задачам, а не обслуживанию инфраструктуры. Кроме того, был снижен достаточно высокий «налог» на инфраструктуру, который невольно приходилось платить пользователям.
Переход к эпохе бессерверных вычислений (serverless computing) — следующий шаг в направлении дальнейшего снижения налога на инфраструктуру, исключения необходимости ее обслуживания, планирования и оптимизации использования ресурсов, решения задач масштабируемости, а также заботы о системном ПО и среде выполнения. У разработчиков появилась возможность сконцентрироваться только на бизнес-логике. При необходимости обрабатывать больше запросов сервис сам предоставляет возможности по масштабированию. Если, например, приходит рекламный трафик или одновременно происходит множество внешних событий, то облако начинает автоматически увеличивать количество одновременно запускаемых копий функций, выстраивать запросы к ним и обрабатывать ответы в соответствии с настроенными квотами, разворачивая «мини-контейнеры» с функциями. Более того, появилась возможность строить и разворачивать глобальные сервисы, выбирая в какую зону доступности и регион развернуть код для уменьшения задержки между пользователем и приложением. Как следствие, при работе в такой бессерверной среде возникает необходимость в базе данных, способной самостоятельно эластично подстраиваться под нагрузку.
Однако оказалось, что для экосистемы бессерверных вычислений почти нет баз данных, особенно реляционных. Такие системы хранения данных, как S3, не заменяют базу данных, а использование традиционных СУБД слабо совместимо с бессерверной парадигмой. Большинство решений базируются на принципе take or pay: сначала оплачиваются и выделяются ресурсы (обычно впрок), а потом оказывается, что эти ресурсы так и не использовались. Что делать, если нагрузка непредсказуема? Как автоматически менять необходимые ресурсы базы данных вместе с изменением нагрузки и при этом не переплачивать за них?
История появления Yandex Database
Предпосылки:
Интернет стал большим — появилась острая необходимость в распределенных базах данных, решающих задачу масштабирования нагрузки и объемов хранимых данных.
Аналитики утверждают, что в 2020 году интернет насчитывал 5 млрд пользователей, из которых 60% постоянно находятся в режиме онлайн.
Пользователи генерируют огромный объем данных, в течение трех последующих лет их размер станет больше чем за последние тридцать.
Масштабное распространение IoT-датчиков формирует лавинообразный рост собранных ими данных.
Нужны новые технологии распределенных баз данных, в старых классических СУБД отказоустойчивость и масштабирование реализованы поверх нераспределенной системы — это работает, но не слишком хорошо.
В 2008 году для хранения данных поисковой базы веб-робота «Яндекс» использовалось более сотни серверов: данные индексировались, выкладывались в базу поиска, по которой отрабатывались поисковые запросы. Для того чтобы система была отказоустойчивой и процессы не падали при отказах оборудования, необходимо было делать репликацию. Большинство задач выполнялось локально на конкретной машине, но когда требовалось подсчитать рейтинг страниц, для обмена данными нужно было использовать все серверы.
По мере роста объемов данных в Сети росла и поисковая база, приходилось постоянно увеличивать ресурсы, а для обеспечения надежности базы — периодически перераспределять ее по множеству узлов (пересегментировать), причем подготовка к этой операции могла занимать несколько месяцев. Чтобы увеличить парк серверов, требовалось перенести часть данных со старых серверов на новые, а также переместить данные с одних старых серверов на другие. Этот процесс был длительным и трудоемким.
В 2011 году была создана новая система, получившая название KiWi и призванная решить проблему роста объемов данных, обеспечения отказоустойчивости и балансировки нагрузки. Основа KiWi — это архитектура СУБД «ключ-значение» и решения, работающие одновременно в нескольких ЦОДах. Для распределения данных по узлам кластера использовалось консистентное хеширование. Репликация и обработка данных в KiWi выполнялись во время фонового процесса слияния изменений в основной базе. Процесс был достаточно эффективным и существенно экономил вычислительные ресурсы. Удаление данных происходило в соответствии с принятыми политиками: давно не обновлявшиеся данные удаляли в зависимости от принятого TTL (Time To Live), хранили последние несколько версий объекта. Когда систему запустили в эксплуатацию, кластер составлял более 600 серверов. Для сравнения: самая крупная публичная инсталляция на сайте Cassandra на тот момент была вдвое меньше.
Не обошлось без сложностей. При активном использовании системы начали проявляться аномалии, связанные с согласованностью в конечном счете (eventual consistency). Например, в задачах анализа данных требовался согласованный срез, что в KiWi провести было сложно: пока читается срез данных с одного набора реплик, другие реплики тех же данных могли уже измениться и возникала вероятность чтения устаревших данных другой версии.
Решать эту проблему приходилось разработчикам, которые пользовались KiWi, — в прикладном коде, работавшем с базой, они предусматривали все возможные варианты раскладки данных. Сложность инфраструктуры перешла на сторону клиентского приложения. Но разработчики хотели писать свои приложения и использовать уже готовые и привычные им инструменты, а не заниматься разработкой программ, управляющих базой данных.
Требовалась новая платформа, способная решать задачи хранения временных рядов, организации хранимых очередей, а также способная предоставить хорошо масштабируемую реляционную базу данных и поддерживать хранение «ключ-значение». Что мы хотели получить от новой платформы:
отказоустойчивость — сохранение работоспособности при выходе из строя одного из трех ЦОДов;
поддержка serializable уровня транзакционной изолированности;
ACID-транзакции между любыми ключами, строками, таблицами;
удобный язык запросов;
возможность масштабирования до объемов в сотни петабайт и по нагрузке до десятков миллионов запросов в секунду;
мультиарендность;
интерактивность — время обработки действия должно составлять не более десятков миллисекунд.
Были мысли воспользоваться готовыми продуктами с открытым исходным кодом и с широким набором функциональных возможностей. Этот подход мог бы стать успешным, если бы не было проблемы пересегментации: ни одно из существующих решений не было жизнеспособным, когда количество сегментов составляло сотни и более, а нам нужно было рассчитывать на миллионы сегментов. Требовалось вручную управлять разбивкой данных по сегментам и балансировкой данных, причем в одних узлах данных оказывалось больше, в других — меньше. Например, если в качестве ключа сегментирования выступает идентификатор пользователя, то вся информация, относящаяся к пользователю, хорошо сегментируется и помещается в одну базу, но если надо построить вторичный индекс по свойству этого пользователя, то первоначальный вариант сегментирования базы становится некорректным. Для разработчика приложения это означает необходимость самостоятельно реализовывать механизм распределенных транзакций с учетом проблем быстродействия и несогласованности. Помимо этого ни одно из существующих решений не было рассчитано на мультиарендный режи. В итоге было принято решение о создании собственной платформы Yandex Database (YDB), решающей перечисленные задачи.
YDB с точки зрения пользователя
Для пользователя YDB представляет древовидную файловую систему: каталоги в нелистовых узлах и объекты различного типа с данными в листовых узлах. Ключевой компонент базы — таблица, в которой хранятся все данные, набор строк, удовлетворяющих схеме данных. Строка — множество значений колонок определенных типов. Некоторые из колонок должны составлять первичный ключ (primary key), по которому отсортирована таблица. Таблицы сегментируются горизонтально, благодаря чему можно хранить таблицы произвольного размера.
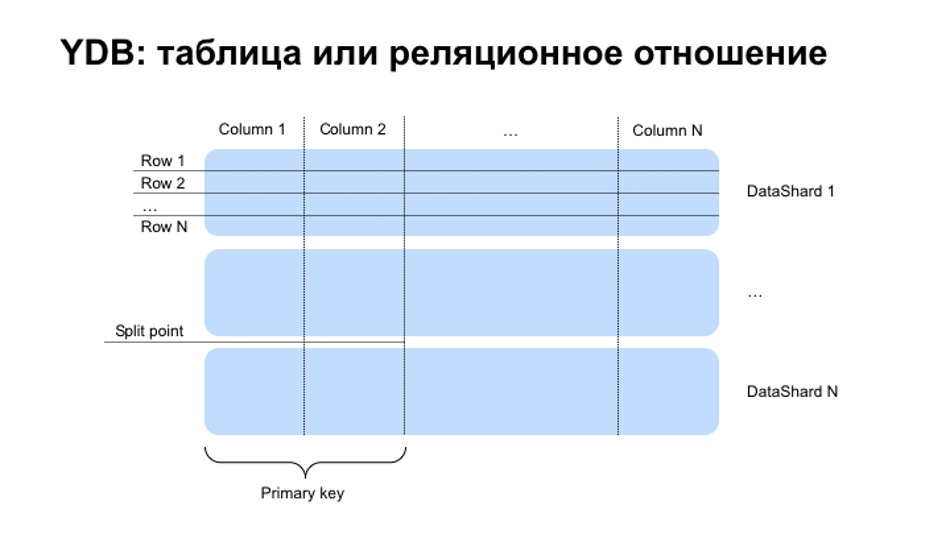
Одна из ключевых особенностей Yandex Database — поддержка двух моделей данных (реляционной и «ключ-значение»), что позволяет поддерживать различные типы нагрузки и решать разные задачи.
Для работы с реляционной моделью данных используется YQL API, позволяющий применять YDB как полноценную OLTP-СУБД с транзакциями, SQL-запросами и соединениями (join). Для работы с моделью «ключ-значение» в YDB реализован слой совместимости (Document API) с Amazon DynamoDB API — одной из самых популярных в мире бессерверных СУБД, что позволяет использовать AWS SDK и AWS CLI.
Квазиструктурированные данные обычно трудно отразить в строгой схеме, поэтому для работы с ними все чаще применяются документоориентированные СУБД, предназначенные для хранения и поиска данных, оформленных в виде документов в JSON-подобном формате. В Yandex Database реализована поддержка JsonAPI, а также специальный тип для хранения JSON — JsonDocument, позволяющий обходить документную модель с использованием JsonPath без необходимости разбора всего содержимого. Это дает возможность эффективно выполнять операции из JsonAPI, уменьшая задержки и стоимость пользовательских запросов.
Архитектура YDB
Ключевой элемент YDB — таблетка, предназначенная для хранения небольшого объема данных. Вся система состоит из таких таблеток и теоретически может расти бесконечно. Изначально таблетка маленькая и управляет единицами гигабайт данных. Множество легковесных таблеток внутри единой системы легко перемещаются между узлами кластера, так обеспечивается отказоустойчивость, адаптируемость и легкая масштабируемость — можно почти мгновенно на несколько порядков наращивать ресурсы. В противном случае, когда нагрузки незначительные, можно минимизировать стоимость сервиса.
Фактически база данных становится виртуальным ресурсом — можно сказать, что запущен «мини-контейнер» с базой данных, который находится в облаке и может перемещаться между узлами кластера. Такие микросущности выгодны с точки зрения оплаты, которая производится только за совершенные запросы, а используются лишь ресурсы, необходимые для обработки запросов.
Современная СУБД — сложный программный комплекс, отдельные части которого действуют независимо, взаимодействуют асинхронно, эффективно и прогнозируемо используют доступные ресурсы и физического сервера, и кластера из тысяч узлов. При разработке кода Yandex Database применяются концепция обмена сообщениями и модель акторов. Акторы — это однопоточные конечные автоматы, которые могут обмениваться между собой сообщениями и «живут» на различных серверах кластера. YDB — это распределенная актор-система, которая знает местоположение каждого актора, может быстро «убить» его на одном узле и поднять на другом, например, для балансировки нагрузки или в случае сбоев.
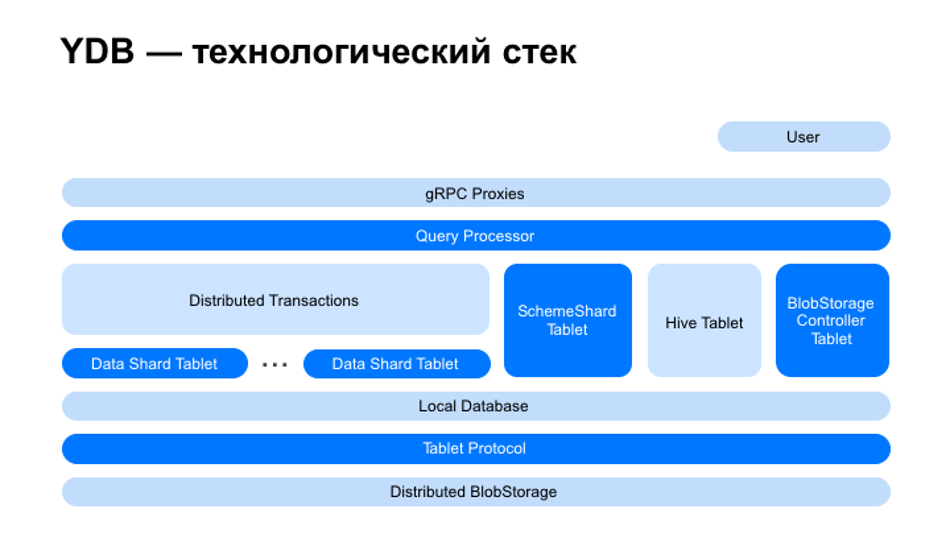
Yandex Database внутри имеет стековую архитектуру и состоит из нескольких слоев.
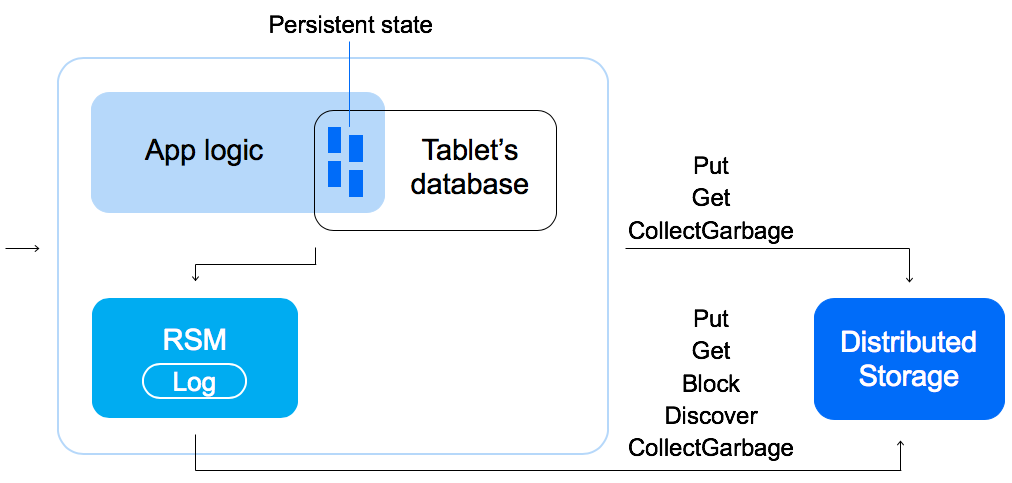
Надежность хранения состояния таблетки обеспечивает распределенная система хранения (Distributed storage), в которой хранятся все данные таблеток, включая журналы (логи) и снимки (snapshots). По своей природе Distributed storage — это специальное хранилище «блобов» (Binary Large Object — двоичный большой объект), гарантирующее надежную запись, которая успешно завершается, только когда блоб полностью реплицирован и во всех репликах записан на все необходимые диски.
Network Interconnect — слой, который обеспечивает взаимодействие всех других слоев между собой. Это собственная разработка Yandex Database поверх TCP. Интерконнект позволяет передавать сообщения между акторами, которые находятся в разных процессах операционной системы или на разных узлах.
В Yandex Database реализован механизм распределенных транзакций, полностью обеспечивающих требования ACID в запросах, которые могут затрагивать данные из нескольких таблеток (фактически сегментов одной или нескольких таблиц), расположенных на кластере.
Для того, чтобы избежать недостатков, свойственных алгоритму двухфазной фиксации (2PC), связанных с ограничениями пропускной способности и высокой вероятностью отката при конфликте, в Yandex Database реализован механизм планируемых транзакций (deterministic transactions). Они обеспечивают транзакционную изоляцию уровня serializable и основываются на подходе Calvin: когда множество участников должны договориться, как обрабатывать ту или иную транзакцию, то они делают это до того, как поставят блокировки и начнут выполнять транзакцию. Когда транзакция запланирована, она выполняется в соответствии с планом. Так как все узлы договариваются о том, какие транзакции и в каком порядке будут выполняться, то можно отказаться от протоколов распределенной фиксации, уменьшить пересечение конкурирующих транзакций и увеличить пропускную способность системы.
Пользователям Yandex Database доступен язык YQL (Yandex Query Language) — строго типизированный диалект SQL с поддержкой сложных типов: list, tuple, struct, dict. Обычно разработчики приложений для реляционных баз данных ожидают от среды наличия именно диалекта SQL.
Query Processor — это слой обработки YQL-запросов. Компилятор запросов анализирует пришедший в систему запрос на языке YQL и создает на его основе направленный ациклический граф (DAG) с информацией о типах. Оптимизатор запроса переписывает этот граф, основываясь на структуре выражений и свойствах данных. Так создается физический план выполнения запроса.
И наконец — самый верхний слой gRPC proxy. Взаимодействие с базой данных происходит по протоколу gRPC (удаленный вызов процедур с открытым исходным кодом, первоначально предложенный Google). YDB API публично открыт, что позволяет разработать собственные SDK для Yandex Database.
Бессерверный режим в YDB
В классических распределенных системах всегда есть сегменты с данными, и если все данные не умещаются на один узел, для масштабируемости добавляется второй узел, третий и т. д. Но в Yandex Database сегмент очень маленький и таблица всегда разбивается на маленькие сегменты — таблетки в среднем по 1–2 Гбайт. Как следствие удобно перемещать и управлять балансировкой маленьких сущностей — таблеток. Они могут перемещаться между узлами, активироваться за доли секунды — обработка отказа происходит быстро. Если создать таблицу в 100 Мбайт, то она поместится в одну таблетку, которую будет обслуживать несколько акторов. Если потребуется записать на порядок больше данных, то все эти таблетки автоматически поделятся, как клетки. Аналогично, если таблетка длительное время будет обрабатывать достаточно большую вычислительную нагрузку, она также поделится на несколько таблеток. Так достигается фактически бесконечная масштабируемость.
Данная архитектура позволила реализовать в Yandex Database режим бессерверных вычислений, что дает возможность применять эту базу не только в крупных сервисах компании «Яндекс», но и для решения менее масштабных задач, делая технологию доступной множеству пользователей, решающих различные бизнес-задачи.
В бессерверном режиме все запросы пользователей пересчитываются в условные единицы (request unit) — это фактически стоимость чтения по ключу нескольких килобайтов данных. Если запрос более сложный, чем просто чтение по ключу, то его стоимость пропорционально увеличивается. Для знакомства с YDB предусмотрен бесплатный режим Free Tier: пользователю предоставляется выполнение миллиона request units в месяц, чего вполне достаточно для многих сервисов. При этом пользователь, помимо бесконечной масштабируемости, получает полностью управляемую базу данных.
Благодаря режиму бессерверных вычислений менеджер проекта может точно посчитать стоимость услуги. Выполнение бизнес-процесса состоит из запуска определенного количества функций, обработки файлов в объектной системе хранения (Object Storage), использования очереди и обращения к базе данных. Стоимость каждого из этапов процесса, в том числе запроса к базе, можно оценить и получить стоимость всего бизнес-процесса для ее последующего учета в плате за обслуживание клиента.
От теории к практике, где уже работает YDB
Сервис Auto.ru планировал социальный проект «Большой экзамен ПДД». Проект предлагалось сделать в виде отдельного от основного сайта динамического сервиса. Прогнозировались пики нагрузки, обусловленные маркетинговыми активностями. Для обеспечения автоматического масштабирования выбрали бессерверный стек технологий от Yandex.Cloud — реализацию на Yandex Cloud Functions для запуска кода в безопасном, отказоустойчивом и автоматически масштабируемом окружении без создания и обслуживания виртуальных машин. При увеличении количества участников «сдачи» экзамена на знание ПДД, автоматически создаются дополнительные экземпляры функции, выполняемые параллельно. В качестве базы данных использовалась Yandex Database в режиме бессерверных вычислений. Приложение выдержало пиковые нагрузки и позволило провести тестирование более 100 тыс. участников. После завершения проекта командам Auto.ru не пришлось предпринимать каких-либо действий по его заморозке, так как плата берется только за реально обработанные вызовы.
Сегодня, кроме сервиса Auto.ru, на мультиарендных кластерах Yandex Database работают «Алиса», «Яндекс.Услуги», «Яндекс.Репетитор», «Яндекс.Коллекции», «Яндекс.Турбо», «Яндекс.Толока», «Яндекс.Директ», «Яндекс.Дзен», «Яндекс.Погода» и др.
Безграничные возможности для любых проектов
Современная распределенная СУБД должна уметь поддерживать различные типы нагрузки, удовлетворяя запросы совершенно разных пользователей.
На кластерах Yandex Database сейчас хранятся петабайты данных и выполняются миллионы запросов в секунду. На основе этой СУБД, предоставляющей режим бессерверных вычислений, основаны проекты с различными типами нагрузки: ключ-значение; традиционные веб-приложения, использующие SQL; запись логов; документоориентированные базы данных с поддержкой JSON API и базы для хранени временных рядов.
Больше подробностей можно узнать в сообществах Yandex Serverless Ecosystem и Yandex Database Chat в Telegram.
Мы планируем серию статей про внутреннее устройство Yandex Database, пишите в комментариях, какие темы наиболее интересны.
