БДСЛ-2017: Таня Бибикова о визуализации данных
Этим летом Лаборатория данных совершила вылазку на Байкал, где кроме прочего я провела мастер-класс по визуализации данных в Байкальском дизайнерском спецлагере. К слову, на Байкале — ошеломительно!

Видео мастер-класса обещано, но появится нескоро. Тем временем, один из участников лагеря расшифровал запись моего выступления. Я привожу здесь первую часть расшифровки лекции с минимальными косметическими правками и конспект второй части, посвящёной алгоритму Δλ, который мы изучаем на курсе по визуализации данных.
Мастер-класс по визуализации данных, 22 июля 2017 года, БДСЛ
Вела Таня Бибикова из Лаборатории данных
Расшифровал Миша Новиков
Мы с вами сегодня поговорим о том, как создавать классные визуализации — визуализации, которые раскрывают природу данных и проявляют скрытые в них закономерности. Но чтобы понять как создавать хорошие визуализации давайте сначала разберёмся, какие визуализации мы будем считать хорошими. Покажу вам несколько примеров.
История землетрясений
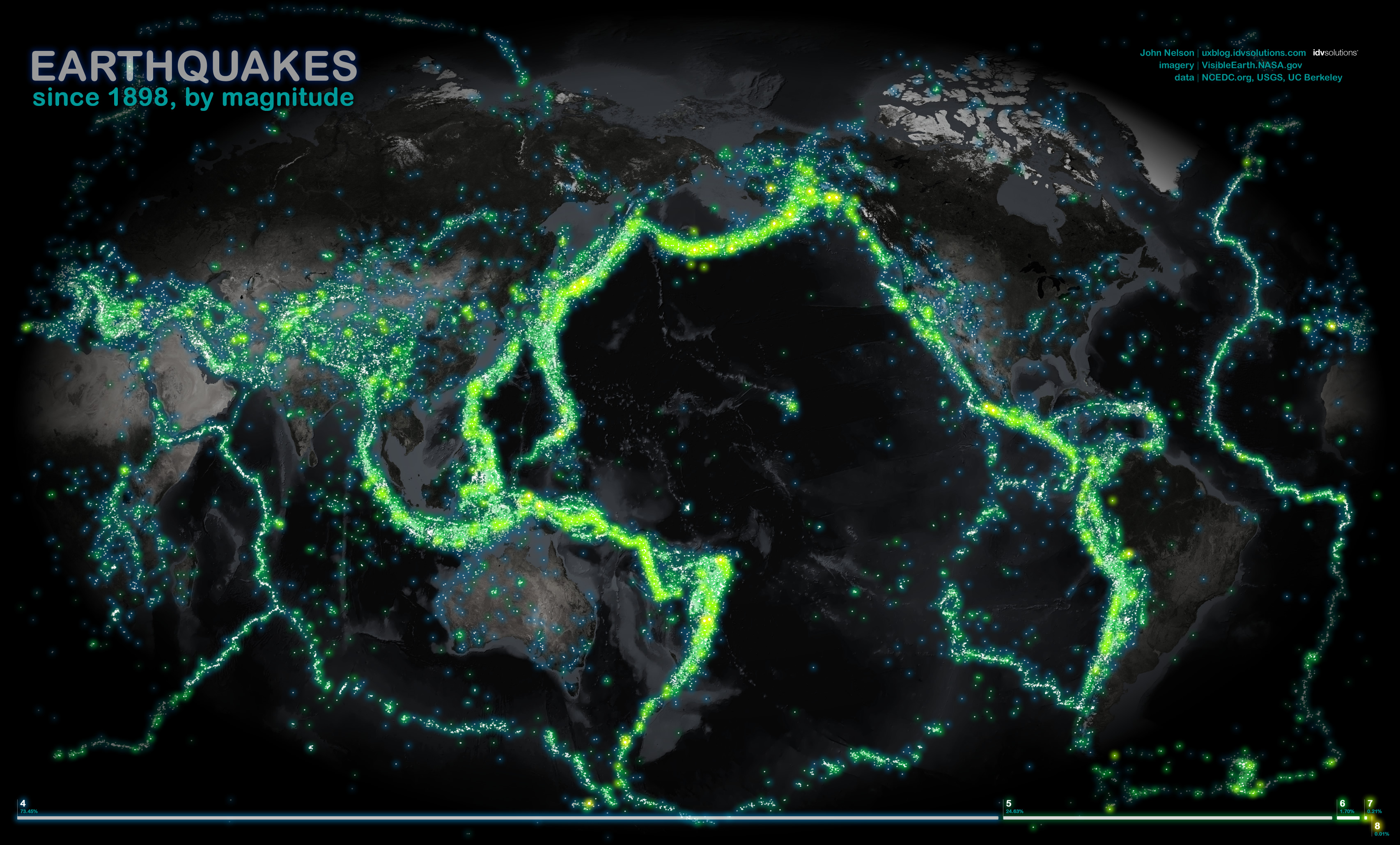
Все землетрясения с 1898 года, показанные на карте. Мы взяли обычную таблицу с сухими данными, где есть год, дата землетрясения, место и сила. Просто поместив эту таблицу на карту, мы проявили картину, которую ни один человек не видел и не может увидеть своими глазами: за историей землятрясений проступают очертания тектонических плит
Результаты Московского марафона
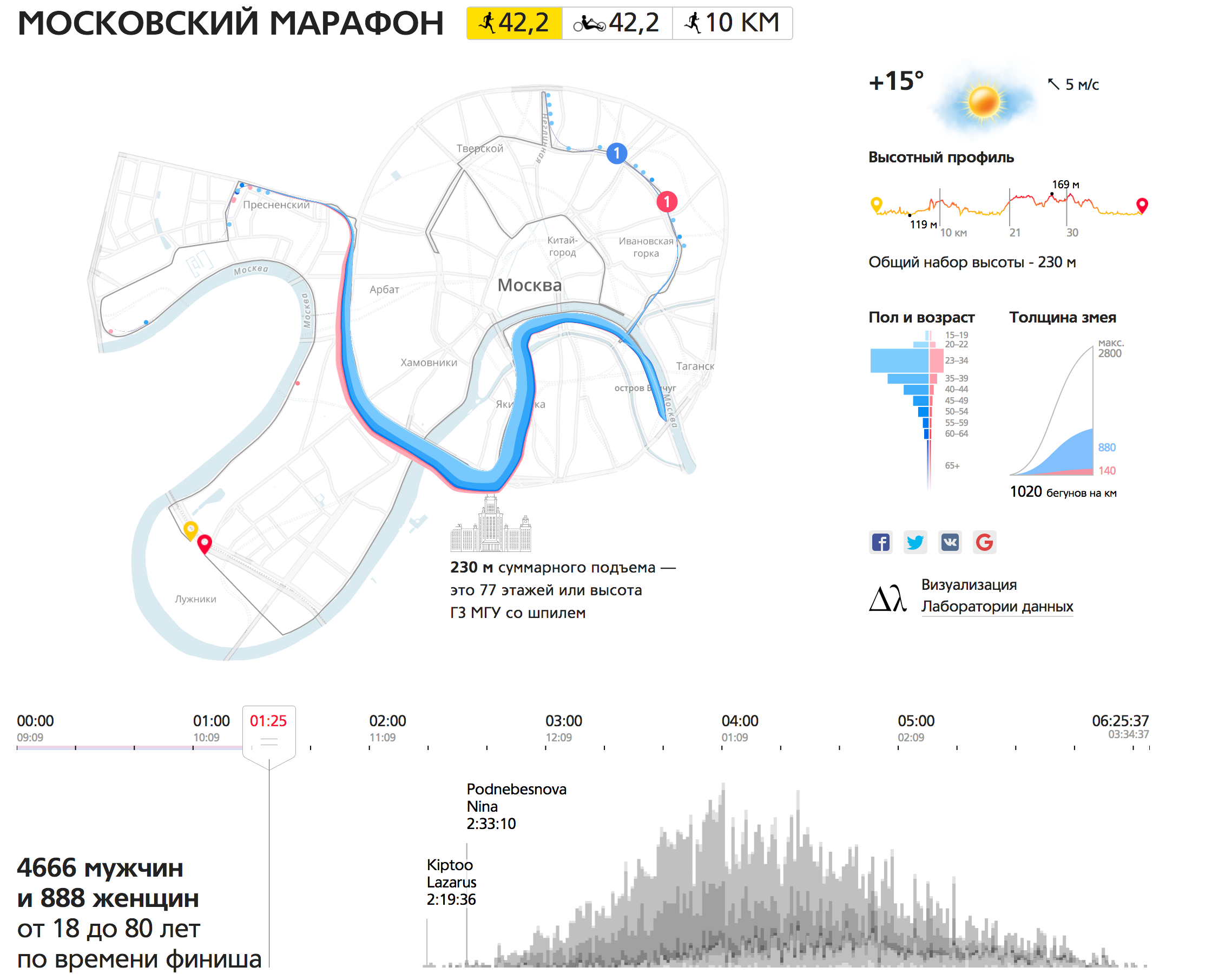
Следующая работа — наша гордость, нам дали за нее бронзу на Malofiej (престижный конкурс по интерактивной графике).
Дано: результаты марафона, которые выглядят как таблица с полями — фамилия, имя, возраст, страна.
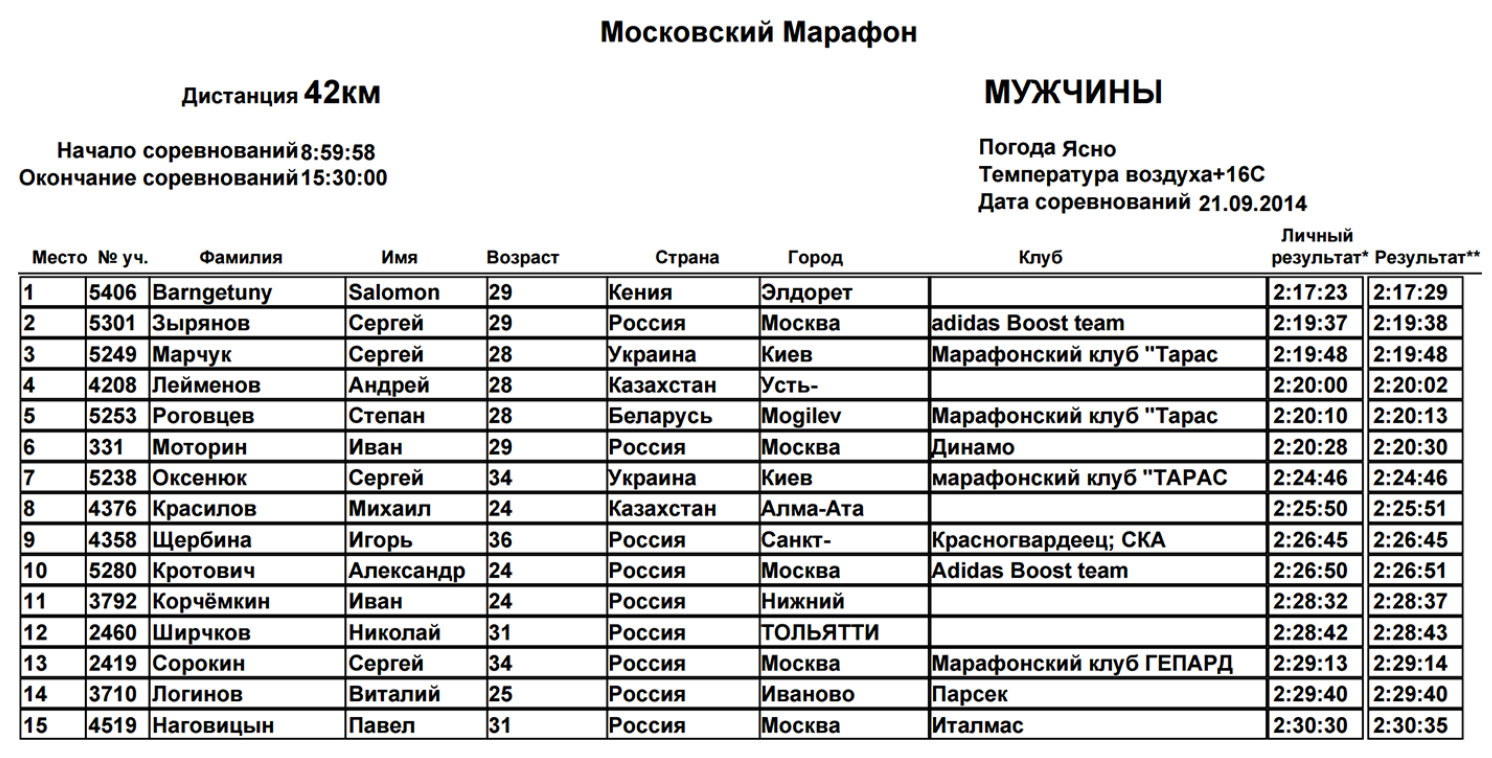
Почему с этими данным захотелось что-то сделать? В 2013 году я сама готовилась к марафону и участвовала в промежуточных забегах. Мой первый забег очень сильно меня вдохновил, потому что это огромная толпа бегунов, разных возрастов, беговых сообществ, команд. Самое интересное происходит в процессе забега, потому что это огромная толпа, которая бежит по маршруту, образует группы. Кто-то очень старается, выкладывается по полной, кто-то делает это для себя, в расслабленном темпе. Когда после моего первого официального забега нам выдали сухую таблицу, не отражающую всего того, что происходило, мне захотелось сделать визуализацию.
У нас есть толпа бегунов, которая бежит по интереснейшему маршруту через весь центр Москвы. В начале толпа большая и толстая, со временем она сильно растягивается вдоль трассы. Когда бегуны уже почти на финише, хвост только-только выбегает из садового кольца.
На этой визуализации много измерений данных. Толпа разделена по цветам — мужчины и женщины, и по возрасту, который показан оттенком цвета, — чем темнее тем взрослее. Из такой визуализации можно извлечь интересные мини-истории. Например, обратите внимание на победителя. Вот здесь, когда выбегает на набережную, он где-то на 7–8 месте, уже на набережной он делает рывок, обогоняет всех и финиширует первым.
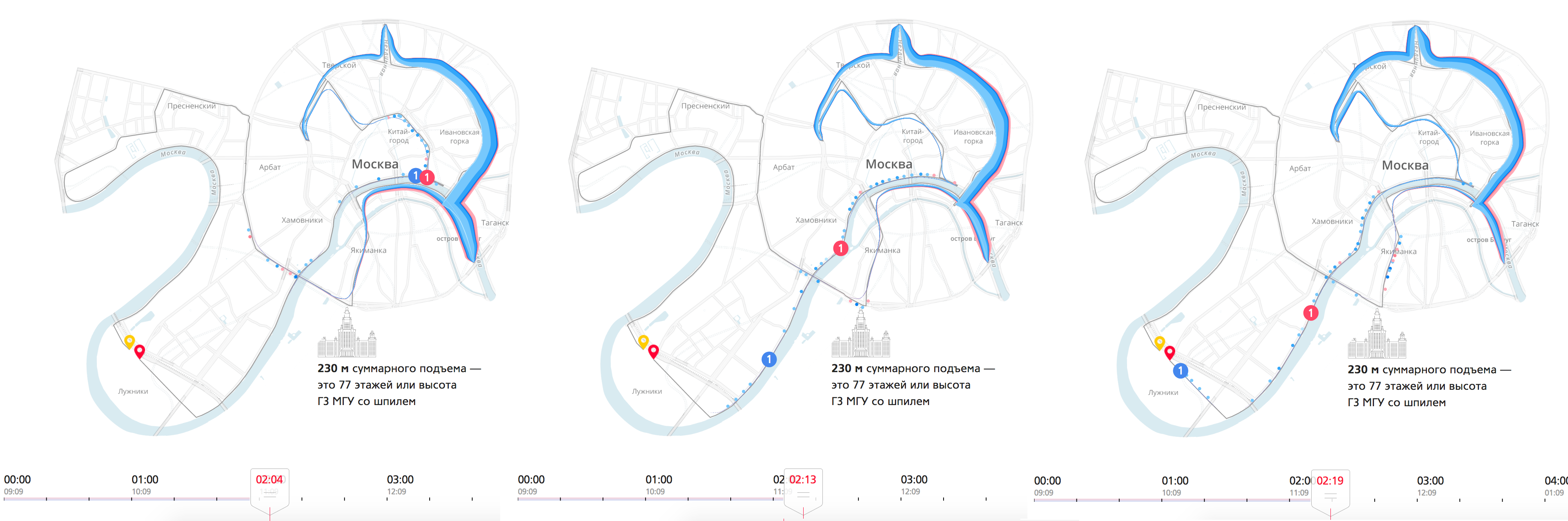
Смотрите: мы взяли сухую таблицу, добавили промежуточные результаты (10, 15, 21 км, 30 и 35 км) и получили огромный пласт новой информации, которую нам было бы сложно извлечь из таблицы. Мы получили полную и целостную картину того, что происходило.
Кроме отражения позиций бегунов мы добавили маленькие диаграммы, распределили бегунов по полу и возрасту. На гистограмме финишей можно увидеть как распределились участники по времени финиша, найти тех, с кем вы бежали вместе. Еще есть список участников с возможностью фильтрации (фильтры влияют и на основную визуализацию). И динамика погоды на протяжение всей гонки, погода для марафонцев — это очень важно, напрямую влияет на результат.
Вопрос в зал: Почему эта визуализация классная?
Ответы:
— Можно в динамике смотреть
— Становится видна новая информация, которой не было в таблице. Например, рывок на набережной
— Карта и питон за счет наглядности создают ощущение простоты и целостности истории, того, что произошло на самом деле. Это не разрозненный набор графиков, а целостное отображение реальности.
Сравнение танков World Of Tanks
Есть игроки, они переходят с уровня на уровень. На каждом новом уровне свойства танков улучшаются, они становятся более бронированными и мощными. Основные характеристики танка — это атака, защита и скорость.
Вот такую диаграмму, посвящённую свойствам танков, мне прислал на разбор один из любителей игры: 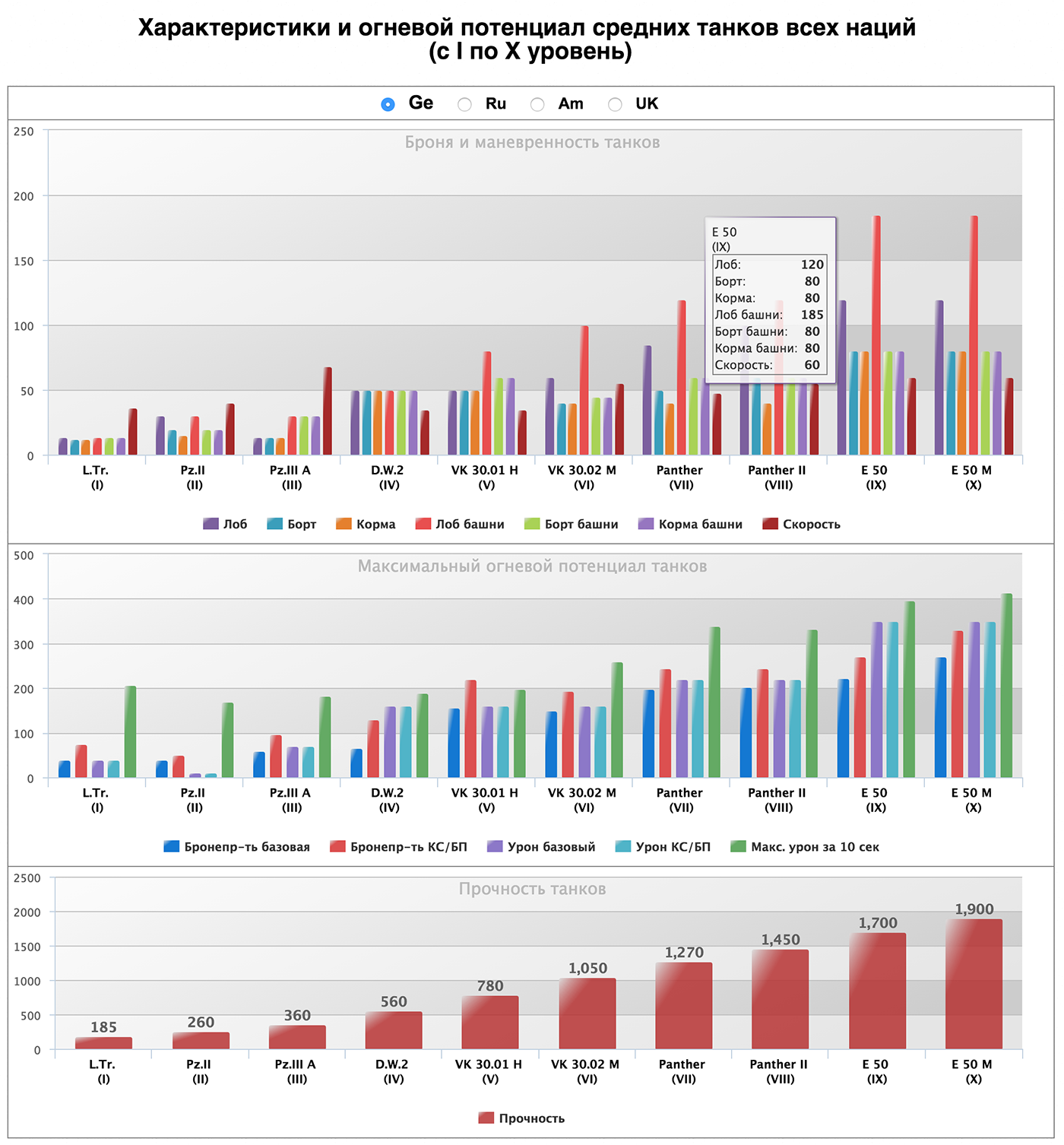
А вот визуализация, которую мы сделали в лаборатории: 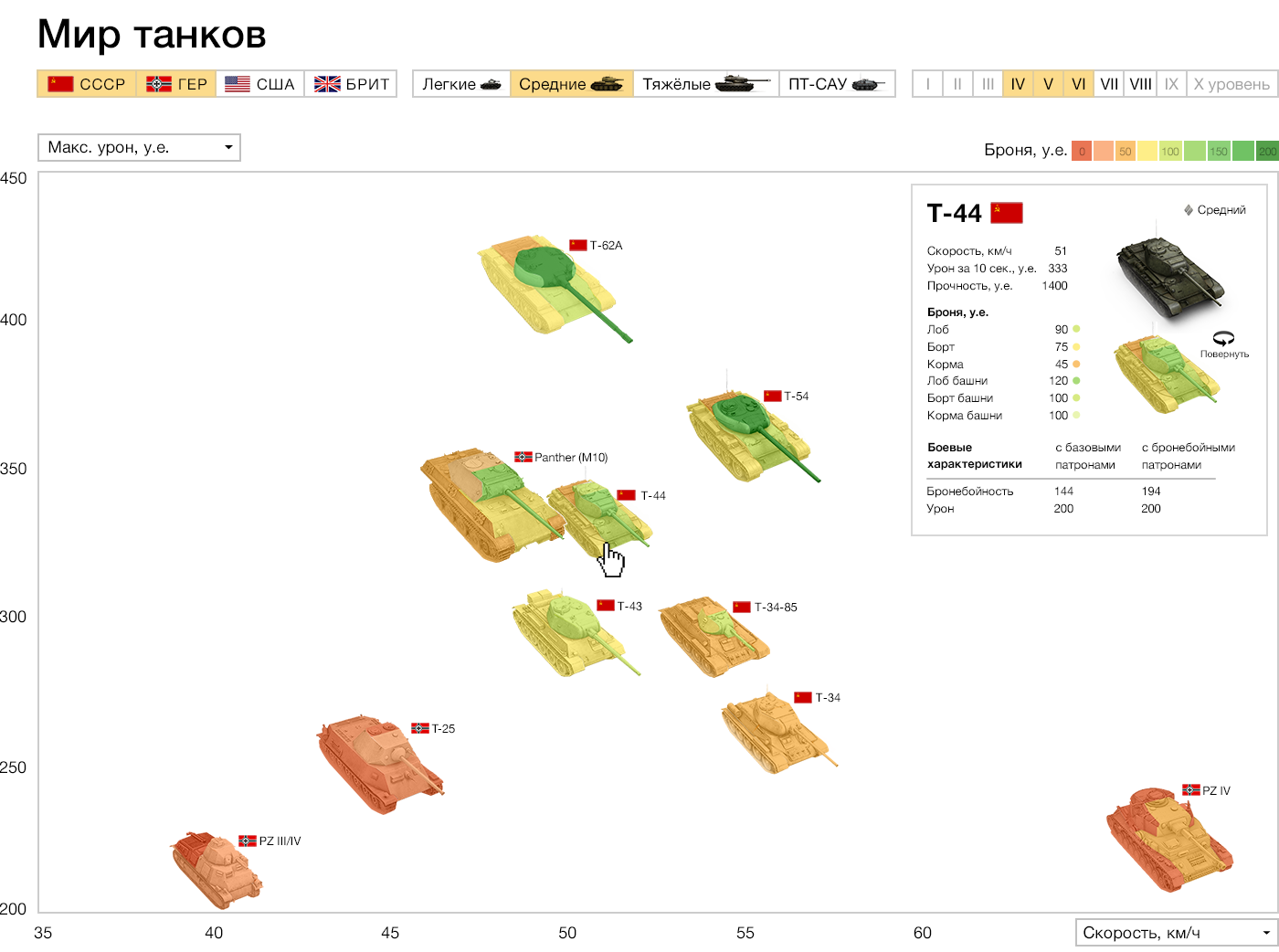
Скорость по горизонтали, атака за 10 секунд вертикали, броня показана цветами прямо на изображении танка. Более детальные характеристики и реальное изображение по клику. Сверху фильтры по странам и классам танков. Вместо сухих диаграмм мы смотрим на размер, форму танков.
Вопрос из зала: Но при этом не все параметры видны всегда. На вашей версии в отличии от первой нельзя узнать какой танк круче с первого взгляда
При желании можно включить все танки всех уровней. Но мы специально урезали стандартный вид, чтобы не забивать экран, и не ухудшать восприятие. На исходном варианте, кстати, тоже не все, а всего десять каким-то неизвестным образом выбранных танков — по одному на каждый уровень. Главный вывод, который там можно сделать — с нарастанием уровня, показатели растут, самое заметное отклонение — у какого-то из танков один из показателей не вырос. На нашей же визуализации можно сравнивать танки одного и соседних уровней.
Комментарий Ильи Рудермана, игрока WOT:
— На прокачку первых трех уровней уходит три-четыре дня. Но чтобы прокачаться от четвертого по десятый надо потратить очень много времени. Ты своим временем дорожишь, поэтому тебе надо знать как можно больше про следующий в дереве развития танк. У игры большая аудитория, и малейшие изменения параметров и характеристик танков сильно влияют на игровой процесс. Поэтому игроки уделяют характеристикам много внимания. Работа крутая. Потенциал у нее большой, но не хватает нескольких критически важных параметров.
Вопрос в зал: Чем хороша эта визуализация?
Ответы:
— Фильтры и параметры не наваливаются огромной кучей переключателей, а аккуратно разнесены и встроены в визуализацию. Мало визуального шума, и каждый элемент помогает восприятию, а не мешает
— На первом графике про танки мы сравнивали все мощности всех танков. Это не очень полезно, т.к. если танк слабый, какой смысл его сравнивать с сильными? В вашей версии, можно их легко отфильтровать и получать только важную информацию.
— Мотивированный игрок будет изучать и первый график, но ваша визуализация обладает потенциалом привлечь и обычного игрока, которому просто интересно.
Ритм жизни больших городов, Jawbone
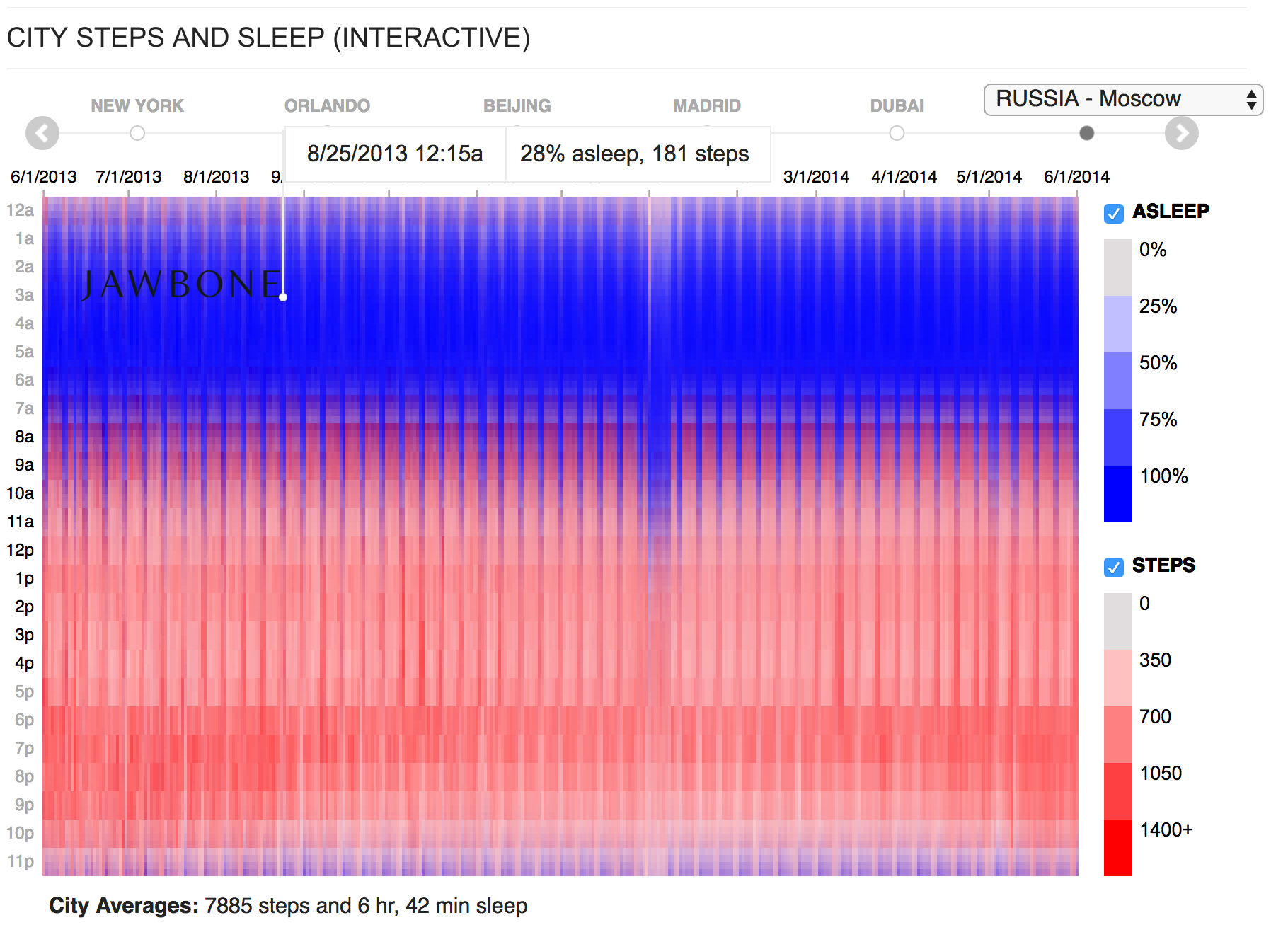
На диаграмме показана активность пользователей в разных городах. По горизонтали — 365 дней года, по вертикали — сутки с разбивкой по 15 минут. Это… 365×24 х 4 = ~35 тысяч ячеек данных х 2 параметра: сон и шаги. Получается ~70 тысяч чисел, которые отражены на одной картинке, 45 таких картинок для 45 городов. Это усредненные числа по всем пользователям, представьте, какое количество данных было на входе!
Что бросается в глаза? Палочки — выходные, все отсыпаются. Заметное проседание 1 января — отмечают Новый год. На оригинальной визуализации каждый год подгружается несколько секунд, от этого пропадает возможность быстрого сравнения. Мы взяли исходную графику и сделали так, что данные загружены сразу и их удобно сравнивать.
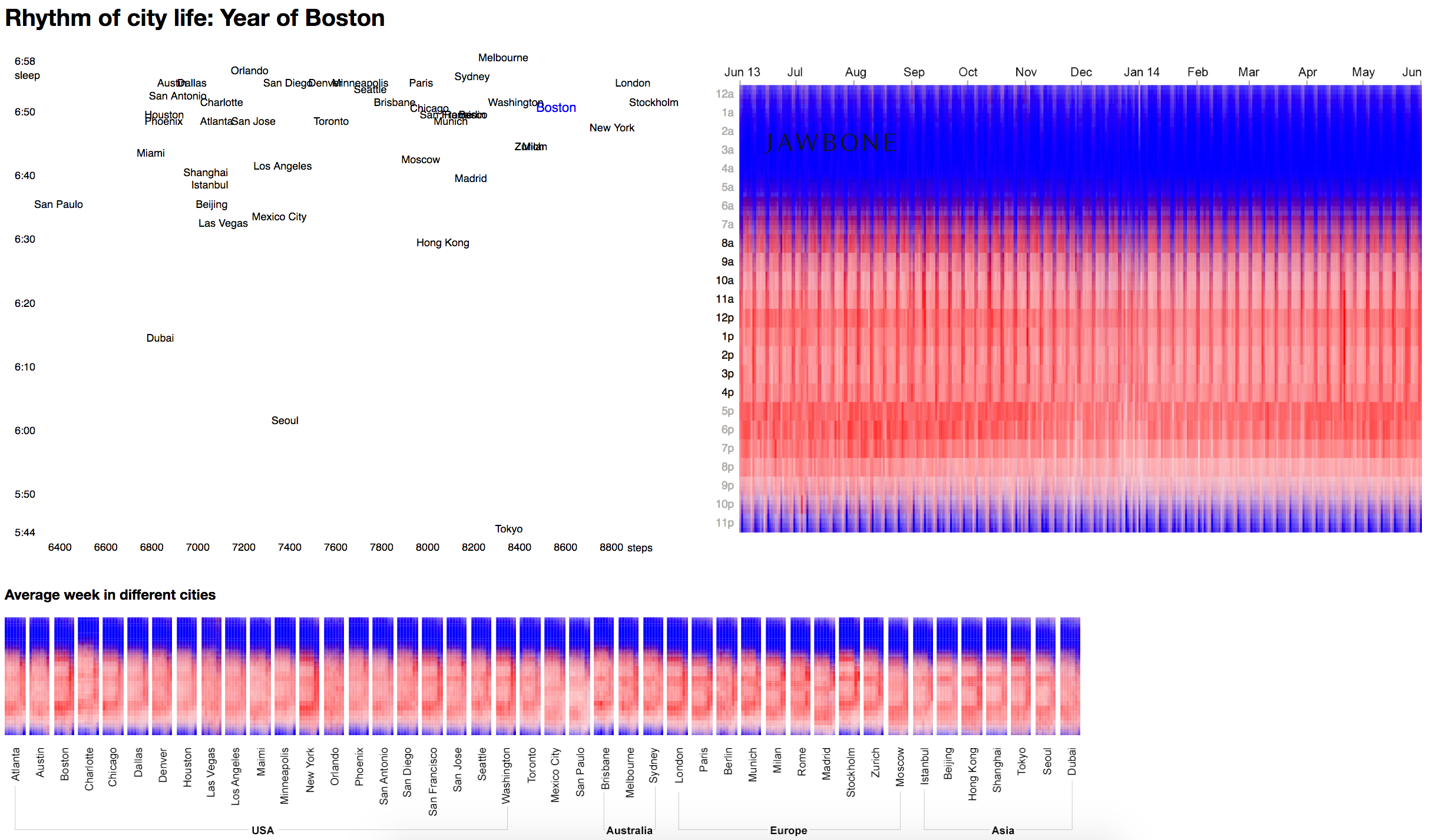
Попробуйте нашу версию. Посмотрите что происходит летом в Стокгольме и Лондоне, насколько Лондон более регулярный. У них изменения только на Новый год. А теперь сравним Лондон и Нью-Йорк: в Нью-Йорке бывают длинные выходные, уикенды. А теперь посмотрите на Мадрид, как у них сиеста после часа дня изменяет всю картину. И теперь Майами или Феникс, где все очень равномерно и нет большой разницы между выходными и рабочими днями. В Дубае почему-то все спят в июне. Возможно это влияние какого-то религиозного поста.
Полоска внизу — усредненная неделя одного города. По ней видно, например, что Шарлотта в США сильно выбивается по времени начала дня. А вечер в Токио плавно переходит в ночь.
Можно разглядеть, что у Нью-Йорка, Вашингтона, Бостона активно выраженная неделя и выходные с большим количеством активности, а в рабочие дни все довольно вяло.
Дополнительный уровень моментального сравнения хорошо работает со способностью нашего зрения замечать перемены в похожих картинках (об этом пишет Тафти). Визуализации классные сами по себе, можно комбинировать с другими каркасами, связывать интерактивом и получать более мощный коммуникативный эффект
Визуализация NYT про Баскетбол
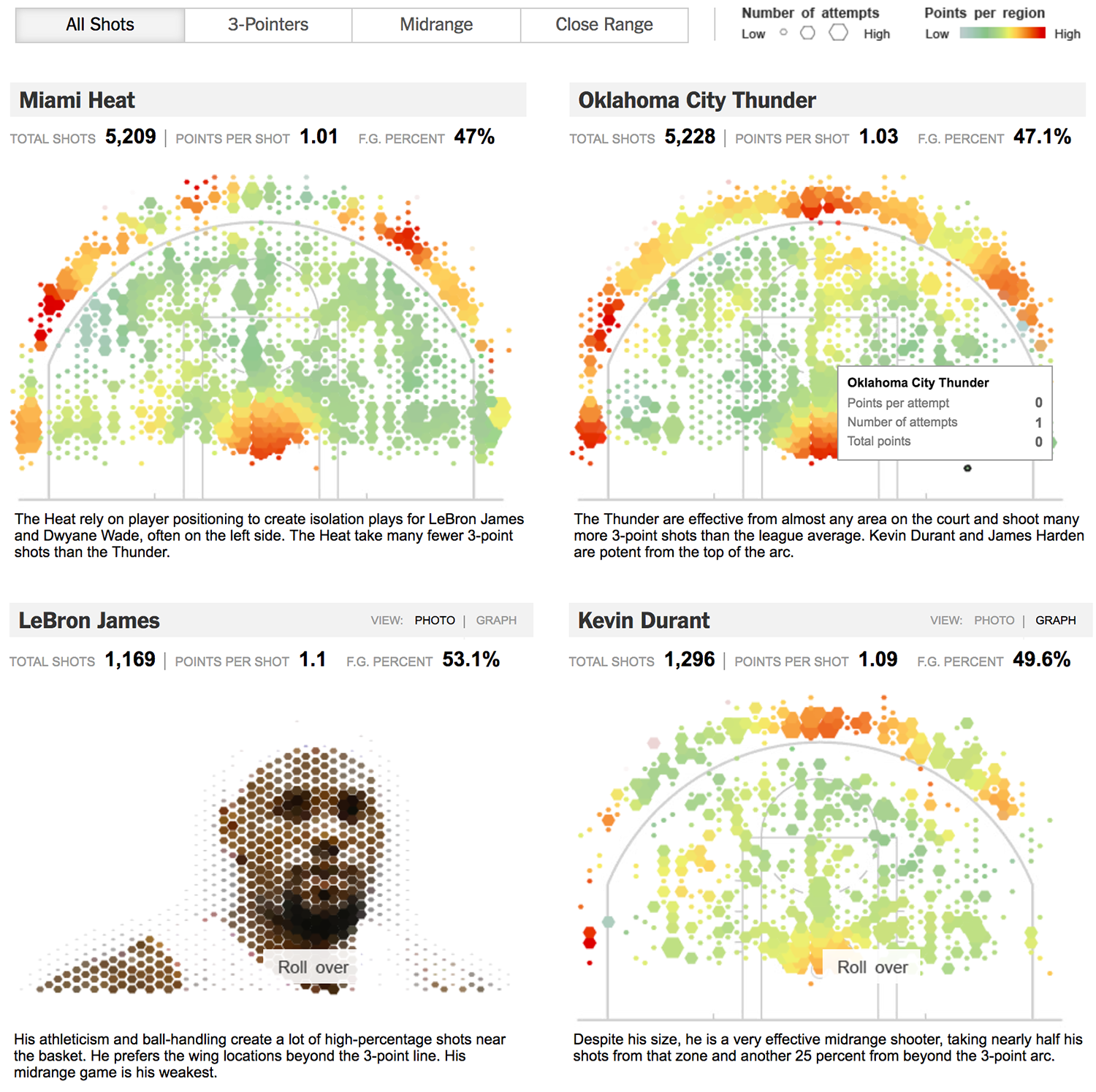
Здесь показана баскетбольная площадка и кольцо, и поверх — количество бросков из разных точек площадки и результативность бросков. Размер шестиугольника — количество бросков с позиции, цвет — чем краснее, тем больше отсюда попаданий. Статистика собрана по двум разным командам, тут есть и сводные данные: общее количество бросков, очков за бросок, процент попадания.
Когда две картинки рядом мы достаточно легко можем сравнивать две команды. Можем заметить кое-какие закономерности: Oklahoma City Thunder бросают трехочковые из центра, а Miami Heat — нет. У них там результативность очень низкая. Но самое интересное начинается когда переходим к статистике по игрокам. [При наведении на изображения игроков они разлетаются и превращаются в диаграммы, из зала восторженные вздохи.]
Сравнение по игрокам более интересно, тут вау-эффект не мешает восприятию и очень органично вписывается в графику. Kevin Durant — спец по трехочковым, а LeBron James кидает из-под кольца. Можно сравнить и посмотреть технику разных игроков и получить понимание о стиле игры. Можно еще увидеть кто левша, а кто правша
Вопрос из зала: А как они все это записывают?
Сейчас все больше спортивные аналитики и телеканалы начинают понимать силу визуализации и тратят ресурсы на сбор и агрегацию таких данных. В крайнем случае, можно найти записи всех голов, и создать датасет вручную.
Визуализация оборота наличности
Дальше скучная таблица, финансы: 
На таблице субъекты РФ и их оборот наличности по физическим / юридическим лицам, резидентам / нерезидентам, выдаче / внесении наличности и сумме оборота. Аналитиков Центробанка не интересуют операции в каждый конкретный момент времени, а интересуют аномалии и выбросы. Например резкий скачек снятия наличных в каком-то субъекте —это повод для подозрения в мошеннических схемах.

Цветовое кодирование мы сделали по аномальности. Внутренний алгоритм вычисляет процент аномальности и в соответствии с индексом раскрашивает область.
В Новгородской области некоторые значения отклоняются от средних, и эту аномальность мы видим на карте. Когда мы увидели аномалию, мы можем попробовать разобраться и провалиться глубже. Аномалия тут оказалась в выдаче. Это были большие изъятия у резидентов в марте, мае и январе. Данная визуализация не позволяет копнуть еще глубже, но уже тут мы можем смотреть временную динамику по сезону. Вряд ли это туристическая активность, девять миллиардов рублей туристы не выгребут. Возможно, это повод для разбирательства. Это не настоящие данные, институт сгенерировал условный сет для тестовой работы.
Здесь классический пример комбинация форматов. Когда мы работаем с картой, оживает график в динамике. А когда работаем с графиком, изменяется карта, мы можем видеть, что в апреле 2013 года была аномалия в Томской области.
У заказчика вся эта информация хранится на 30 листах в экселе, и чтобы увидеть такую картину они путешествуют по этим 30 листам. Там есть специальный человек, который в этом экселе ориентируется и откапывает нужную информацию. Плюс визуализации в том, что можно огромный объем данных упаковать в лаконичную форму.
Карта Венеции
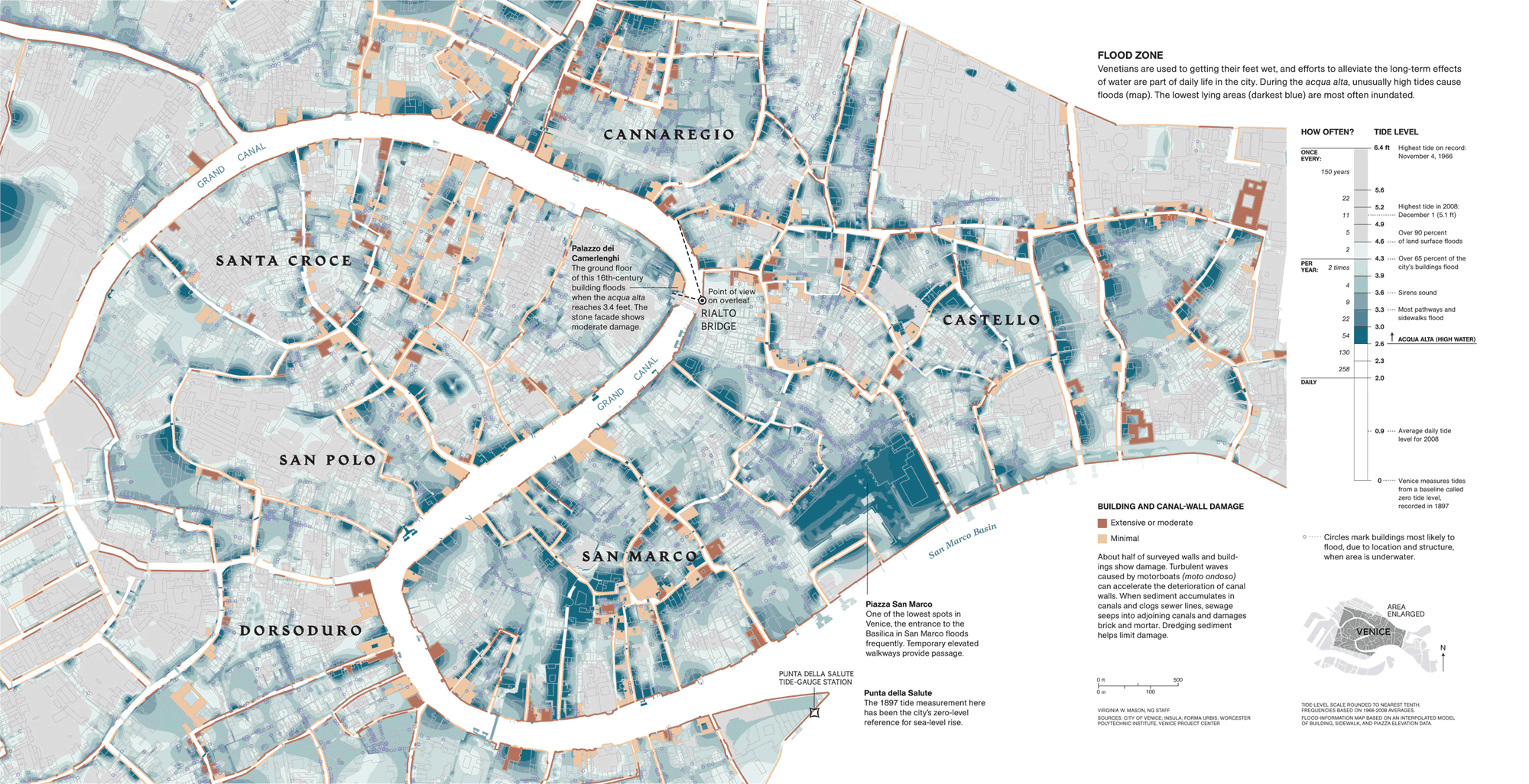
Прекрасный пример связи данных и цвета на карте. Цветовая заливка областей — это районы, которые затопляются с разной частотой. Какие-то районы затапливаются чаще. Интересное совмещение двух типов данных. С одной стороны — это уровень воды, а с другой, на этой же шкале, частота затопления. Помимо заливки областей, тут есть еще одна смысловая единица — дома. Светлым показаны строения, которые слабо страдают от подтопления, темным, которые разрушаются очень сильно
Кто на ком женится
Решётка на фоне составлена из разных профессий. Слева — более мужские профессии, справа — более женские. При наведении на профессию мы видим линии-связи разной толщины, которые показывают как часто люди из этой профессии женятся на людях из другой профессии. Круги означают что люди женятся внутри одной профессии. Цвет градиента показывает пол внутри пары.
Пожарные женятся на воспитателях детских садов. Дизайнеры выходят замуж за менеджеров по продажам.
Такая графика совсем никак не привязана к классическим форматам представлениям информации. Но она максимально учитывает особенности данных, которые лежат в основе визуализации, и делает супер-наглядным то что мы хотим показать — частоту брачного союза. Получается очень минималистично. И эту шутку реально интересно изучать.
Вопрос из зала: А каким способом раскиданы профессии по горизонтали от более мужских к более женским?
Скорее всего какой-то хитрый алгоритм, распределяющий в зависимости от близости профессий, чтобы итоговая картинка выглядела хорошо.
Классная визуализация, выводы
Вопрос в зал: Все примеры очень разные. Что их объединяет и делает визуализацию классной?
Ответы из зала:
— Данные не перестают быть неинтересными и живыми от того, что тема является сухой и неинтересной.
— Когда визуализация сделана хорошо, хочется её исследовать и задавать вопросы.
— Когда связаны многомерные данные, рождается новый смысл от их сопоставления.
…
Вот моё понимание.
В интересной визуализации, в той в которой есть ощущение «магии», всегда много измерений на плоском экране. Мы используем разные выразительные средства и способы и приемы, чтобы сделать восприятие удобным.
При этом, когда мы показываем все эти измерения, мы сохраняем наглядность. Это не должно быть механическое кодирование «ага, у меня есть свойство высота, я его закодирую цветом, у меня есть свойство длина, я его закодирую штриховкой». Старайтесь думать, какие реальные вещи стоят за данными. Если это броня танка рисуйте прямо на танке, где она расположена. Выбирайте способы кодирования как можно ближе к реальности, ближе к интуитивным представлениям о цветах (мальчики — голубой, девочки — розовый). Чем больше интуитивно понятного кодирования вы используете, тем легче будет воспринимать работу, даже если в ней зашито много измерений данных. Не нужно будет делать подписи и гайды «Как читать график», не нужны будут огромные легенды. Возможно минималистичная легенда сама станет диаграммой. При этом график хорошо живет без легенды.
Это не всегда получается. Иногда лучше подходит новый тип визуализации, который сразу не понятен, но очень хорошо решает задачу. Так можно так делать. Но в идеале надо стремиться к наглядности и интуитивности.
Когда эти принципы соблюдены, рождается некая общая картина, мы можем бросить взгляд на данные в целом, не переключаясь по тридцати вкладкам, не переключая города страны, мы можем увидеть целостную картину, что называется, big picture. На большой картине видим закономерности, аномалии, связи. На ней легко проводить сравнения. Если у нас нет общей картины, а всего-лишь пять разрозненных графиков — польза и эффект от визуализации будет совсем другой. После того как мы увидели закономерность, мы можем провалиться глубже и начать исследовать (оборот наличности, города jawbone). Увидеть картину в целом, заметить закономерности и уйти вглубь и отвечать вопросы об этой закономерности. В этом сила, и залог классной визуализации.
Алгоритм Δλ
Мы посмотрели классные примеры визуализаций, теперь поговорим о том, как устроен наш процесс внутри лаборатории. Большинство результатов работы с данными совсем не похожи на примеры, которые мы посмотрели. При слове «визуализация» обычно сразу представляются дашборды, разрозненные графики, круговые, столбиковые диаграммы, иногда санкей.
У меня есть гипотеза почему так происходит. Аналитика, работа с данными и визуализация часто воспринимается, как скучное и муторне дело, потому что данные хранятся в таблицах или базах данных. И эти простыни данных и таблицы выглядят одинаково. Та же проблема со стандартными видами визуализации.
Все данные уникальны. Они живые, внутри у них всегда что-то происходит — взаимодействуют объекты, у них меняются свойства. Если мы заносим эту жизнь в таблицу, мы фиксируем её мёртвым срезом. Когда мы пытаемся визуализировать этот срез, то получаем умеренно информативные, но достаточно скучные, неживые дашборды. Такой прямолинейный подход хоть и самый логичный, но приводит к сухим и примитивным результатам.
Хотя он не всегда такой простой, как кажется. Там есть куча нюансов, и аналитики получают большие деньги, чтобы корректно работать с отражением данных.
Чтобы создать «ощущение магии», о котором мы говорили в первой части, нужно включить воображение и выйти за рамки таблиц. Нужно представить что стоит за этими таблицами, что порождает эти данные.
Реальность данных — это совокупность процессов, которые происходят в физическом пространстве и порождают данные
Здесь Кэти Ледеки бьёт рекорд и завоёвывает олимпийское золото в заплыве вольным стилем на 800 метров:

Это прекрасный пример того, как подключив реальность данных, можно визуализировать то, что происходило на самом деле. Как скучная таблица превращается в штуку, от которой трудно оторвать глаз.
И еще один пример, но из другой области. Карта специалитетов Италии Антуана Корбино: 
Это сложно назвать визуализацией данных, но это хороший пример того, что не нужно бояться брать реальные объекты, как в примере с танками или баскетбольной площадкой. Не нужно бояться размещать всё на карте, привязывать какому-то реальному физическому пространству.
Мы стараемся использовать реальный «ландшафт» и перенести элементы из нашей физической реальности в визуализацию. Это сильно повышает наглядность и приближает нас к общей картине.
Определяя реальность данных, включая воображение и представляя что стоит за сухими таблицами, увидев эту картину, мы делаем шаг к тому, чтобы показать суть явления, а не мертвый и сухой срез. Реальность данных помогает увидеть природу данных за однообразными таблицами.
Частица данных — это заход с микроуровня, это элементарный кирпичик данных, который позволяет распутать клубок данных любой сложности. Их может быть несколько, но чаще всего одна. Это аналитическая работа, найти сущность, единицу, которая позволит максимально гибко работать с данными.
Представить реальность данных и вычленить частицу данных — первый шаг нашего алгоритма Δλ. Представить картину в целом, и найти мельчайший кирпичик. Данные превращаются в совокупность частиц, которые мы можем любым удобным способом группировать.
Дальше мы переходим в двумерную плоскость экрана и начинаем на ней раскладывать частицы как угодно. Это второй шаг алгоритма — подбор каркаса и визуального атома.
Каркас — это способ организации двух измерений экрана, который передаёт свойства частицы данных за счёт её положения на экране и изменения этого положения. Каркас распределяет частицы данных на плоскости, чтобы их можно было сравнивать между собой.
Визуальный атом — визуальное воплощение частицы данных на экране. Визуальные атомы показывают параметры данных с помощью цветового кодирования, размера, формы объектов и других визуальных атрибутов.
Зачем эти сложности с каркасами и атомами? Возможность разделить пространственные измерения и визуальные, как бы собственные свойства частицы значительно увеличивает гибкость нашего подхода к отображению данных. Любой визуальный атом может оказаться на любом каркасе. Даже если рассмотреть небольшой набор базовых каркасов, знакомых всем, в сочетании с графическими примитивами (точка, фигура, линия…), получится внушительная таблица возможных форматов визуализации:

Почему я не начинаю лекцию с этой чудесной таблицы? Мне кажется, что эта таблица подталкивает пойти по стандартному пути и выбирать визуализацию из большого набора графиков, чтобы наши данные в неё запихнуть. А когда мы пытаемся запихнуть данные в заранее предопределённую форму, мы не учитываем их суть, их особенности, и многое теряем. Мне хочется, чтобы мы плясали от данных и поэтому я уделяю столько внимания первой части. Данные сложнее и интереснее всех стандартных форматов. У меня вообще есть ощущение, что у данных свое представление о том, в каком виде им лучше быть :) Что для каждого набора данных, с учётом их внутренних особенностей, есть свой самый подходящий способ представления. Я не хочу чтобы вы воспринимали эту таблицу, как инструмент, чтобы запихивать данные в какой-то формат.
Третий шаг алгоритма, после того как мы вывалили данные на каркас. Мы начинаем добавлять элементы интерфейса, инструменты фильтрации. Возможно у нас получилось слишком много точек и они рябят, то мы можем сливать точки между собой в фигуры. После того как мы распределили данные на каркасе, мы можем добавлять элементы управления, исходя из сценариев, как мы хотим работать с данными.
Очень круто алгоритм раскладывается на примере визуализации потерь Второй мировой войны:
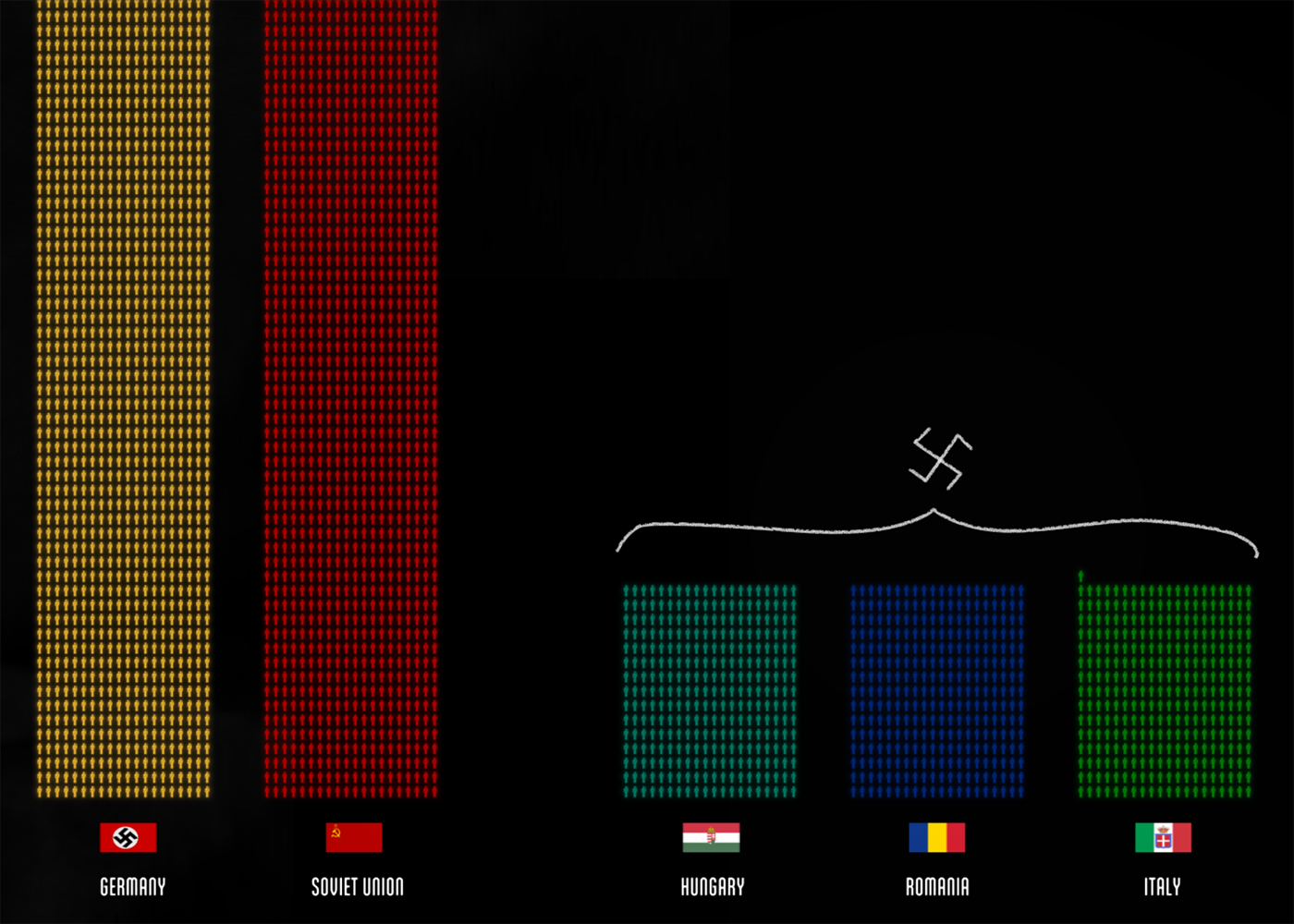
Действие алгоритма сейчас будет как будто происходить на наших глазах, в режиме реального времени (включите видео).
Видео начинается с вводного слово — это реальность данных. Теперь они выбрали частицу данных — мирный житель и солдат. Первый шаг алгоритма пройден. Визуальный атом — фигурка человека, в котором закодировано 1000 жизней. Причём две разные фигурки — солдат с ружьём и безоружный мирный житель. Из отдельных человечков получается масса данных. В какой-то момент все данные располагаются на временной оси. Мы видим как растет число потерь со временем и как оно распределено в разных сражениях. Это второй шаг, мы раскидываем визуальный атом по разным каркасам, видим разные картины.
К этой же частице применяется другой метод группировки — по цветам, которые означают другие осмысленные части. Получается что между собой частицы данных одинаковы, но мы их можем легко сравнивать между собой и делать выводы. Обратите внимание на сценарный ход — повторяется мысль, что все это живые люди, а не точки на графике.
После этого точки превратились в столбики (третий шаг), потому что слишком крупный масштаб. На этом примере, как и на знаменитой карте Минара, проявляется сила целостной картины, на которой мы видим каждую точку, каждую смерть. Это намного сильнее резонирует, чем сухая цифра 87 миллионов, или столбики.
***
Подробнее об алгоритме читайте «Алгоритм визуализации сложных данных».
Всех, кто дочитал заметку до конца, приглашаю на курс по визуализации данных. На курсе мы ещё глубже разбираем понятия реальности и частицы данных, ещё ближе знакомимся с каркасами, визуальными атомами и принципами работы с ними. Кроме того, участники курса изучают инструменты визуализации — Табло и библиотеку d3.js, а в последний день курса самостоятельно создают визуализацию под руководством преподавателей. Чтобы активировать скидку 5 тыс. руб., при записи в комментарии сделайте пометку «с хабра».
