Автоматизируй это! Как мы улучшали интеграционное тестирование
В давние времена у нас было всего несколько сервисов, и выложить за сутки обновление более чем одного из них на production — было большой удачей работой. Потом мир ускорился, система усложнилась, а мы трансформировались в организацию с микросервисной архитектурой. Теперь у нас около сотни сервисов, и вместе с ростом их числа увеличивается и частота релизов — их более 250 в неделю.
И если новые фичи тестируют внутри продуктовых команд, то задача команды интеграционного тестирования — проверить, что изменения, включенные в релиз, не ломают функциональность компонента, системы и других фич.

Я работаю инженером по автоматизации тестирования в Яндекс.Деньгах.
В этой статье расскажу про эволюцию интеграционного тестирования web-сервисов, а также про адаптацию процесса к увеличению числа компонентов системы и повышению частоты релизов.
Про изменения в релизном цикле и развитие механизма выкладки рассказывали со стороны ops и dev в одной из прошлых статей. Я же расскажу про историю изменения процессов тестирования в ходе этой трансформации.
Сейчас у нас около 30 команд разработки. В команду обычно входят руководитель продукта, менеджер проекта, фронтенд- и бэкенд-разработчики и тестировщики. Их объединяет работа над задачами по конкретному продукту. За сервис, как правило, отвечает команда, которая чаще всего вносит в него изменения.
Приемочное end-to-end тестирование
Ещё не так давно при релизе каждого компонента прогонялись только unit- и компонентные тесты, а после этого на полноценной тестовой среде выполнялись лишь несколько самых важных end-to-end сценариев перед выкладкой сервиса в продакшен. Вместе с ростом числа компонентов стало экспоненциально увеличиваться и число связей между ними. Зачастую — совсем нетривиальных связей. Вспоминаю, как недоступность сервиса выдачи маркетинговых данных поломала регистрацию пользователей напрочь (разумеется, на короткое время).
Такой подход к проверке изменений стал давать сбои все чаще и чаще — потребовались покрытие автотестами всех критичных бизнес-сценариев и их прогон на полноценном тестовом окружении с готовой к релизу версией компонента.
Окей, автотесты на критичные сценарии появились —, но как их запускать? Возникла задача встроиться в релизный цикл, минимально повлияв на его надежность ложными падениями тестов. С другой стороны, хотелось проводить стадию интеграционного тестирования максимально быстро. Так появилась инфраструктура для проведения приемочных испытаний.
Мы постарались по максимуму использовать инструменты, уже применяемые для проведения компонента по релизному циклу и запуска задач: Jira и Jenkins соответственно.
Цикл приемочного тестирования
Для проведения приемочного тестирования определили такой цикл:
- мониторинг поступающих задач на приемочное тестирование релиза,
- запуск Jenkins job для установки релизной сборки на тестовую среду,
- проверка, что сервис поднялся,
- запуск Jenkins job с интеграционными тестами,
- анализ результатов прогона,
- повторный прогон тестов (при необходимости),
- обновление статуса задачи — пройдена или сломана, с указанием причины в комментарии.
Весь цикл каждый раз выполнялся вручную. В итоге уже на десятом релизе в день от выполнения однотипных задач хотелось ругаться, в лучшем случае, себе под нос, хвататься за голову и требовать пива валерьянки.
Бот-мониторщик
Мы поняли, что отслеживание новых задач в Jira и оповещение о них — это важные процессы, которые быстро и просто автоматизируются. Так появился бот, который этим занимается.
Данные для формирования оповещений поступают в виде пуш-уведомлений от Jira. После запуска бота мы перестали обновлять страницу дашборда с приемочными тасками, и ширина улыбки автоматизатора чуть увеличилась.
Pinger
Мы решили упростить проверку того, что во время развертывания в тестовой среде не случилось ошибок сборки или установки и что поднялась именно нужная версия компонента, а не какая-то другая. Свои версию и статус компонент отдает по протоколу HTTP. И проверка того, что сервис возвращает корректную версию, оказалась бы простой и понятной, если бы разные компоненты не были написаны на разных языках — какие-то на Node.js, какие-то на C#. Вдобавок наши самые массовые сервисы на Java тоже отдавали версию в разном формате.
Плюс хотелось в реальном времени иметь информацию и уведомления не только о смене версий, но и об изменении доступности компонентов в системе. Для решения этой задачи появился сервис Pinger, собирающий информацию о статусе и версии компонентов путем их циклического опроса.
Мы используем пуш-модель доставки сообщений — на каждом экземпляре тестовой среды развернут агент, который собирает информацию о компонентах этой среды и раз в 10 секунд сохраняет данные на центральном узле. В этот узел мы ходим за актуальным статусом — такой подход позволяет поддерживать более сотни тестовых стендов.
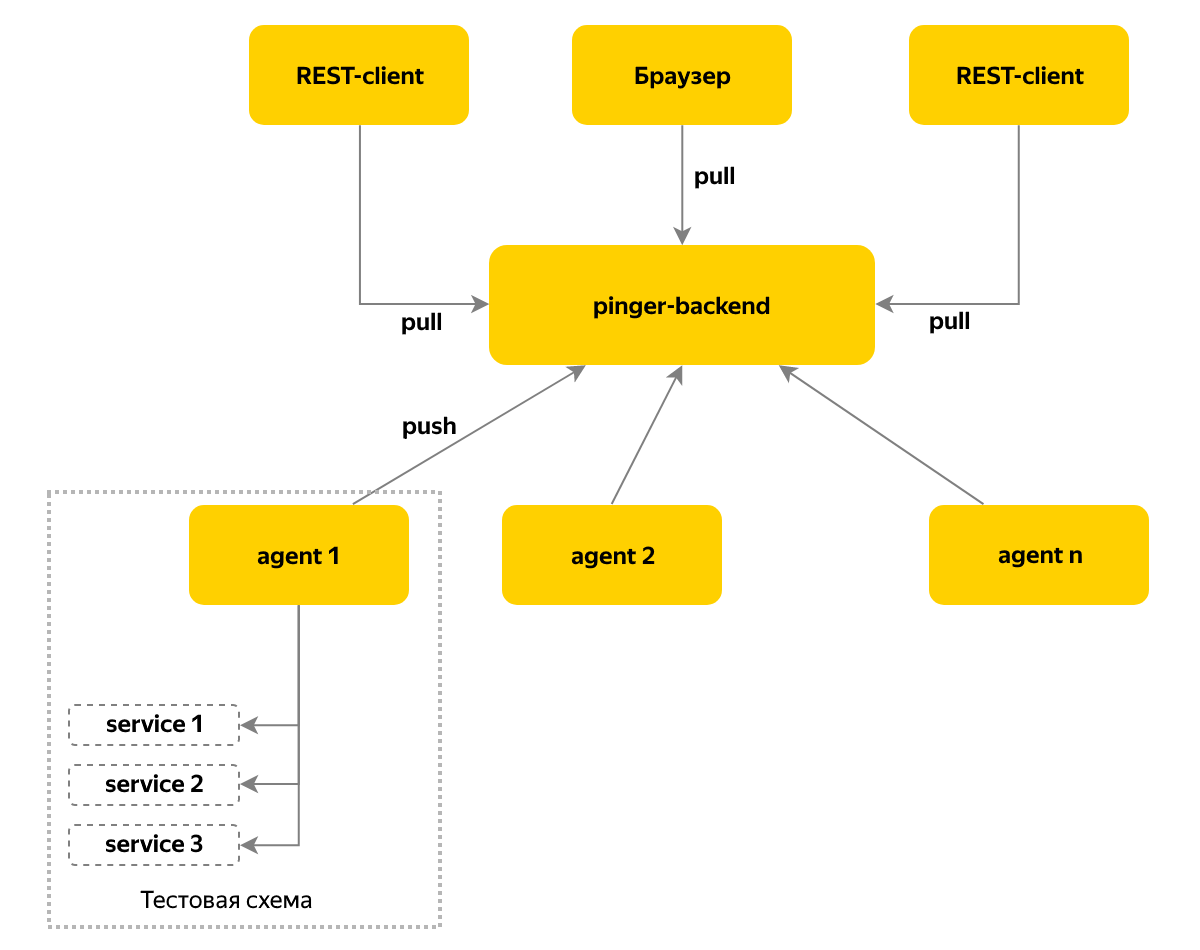
Locker
Пришло время более сложных задач — автоматического обновления компонентов и запуска тестов. На тот момент у нашей команды уже было 3 тестовых стенда в OpenStack для проведения приемочных испытаний, и сначала нужно было решить проблему управления ресурсами тестовых стендов: будет неприятно, если при прогоне тестов на систему «покатится» обновление следующего релиза. Ещё бывает, что тестовый стенд отлаживают, и тогда не стоит использовать его для приёмки.
Хотелось иметь возможность посмотреть статус занятости и при необходимости вручную заблокировать стенд на время разбора упавших тестов или до завершения других работ.
Для всего этого появился сервис Locker. Он долговременно хранит статус тестового стенда («занят»/«свободен»), позволяет задать комментарий к «занятости», чтобы было понятно, что сейчас мы отлаживаемся, пересоздаем экземпляр тестовой среды или прогоняем тесты очередного релиза. Ещё мы стали блокировать стенды на ночь — на них администраторы проводят работы по расписанию, вроде бэкапов и синхронизации баз.
При блокировании всегда выставляется время, через которое лок истекает — теперь людям не нужно участвовать в возврате стендов в пул доступных, и всё делает машина.
Дежурство
Чтобы равномерно распределить между членами команды нагрузку по разбору результатов прогонов тестов, мы придумали ежедневные дежурства. Дежурный работает с задачами на приемочное тестирование релизов, разбирает упавшие автотесты и репортит баги. Если дежурный понимает, что не справляется с потоком задач, он может попросить помощи у команды. В это время остальные члены команды занимаются задачами, не связанными с релизами.
C ростом количества релизов появилась роль второго дежурного, который подключается к основному, если возникают «завалы» или в очереди есть критичные релизы. Для предоставления информации о ходе тестирования релизов мы создали страницу с числом задач в состояниях «открыт»/«выполняется»/«ожидает реакции дежурного», статусом блокировки тестовых стендов и недоступными на стендах компонентами: 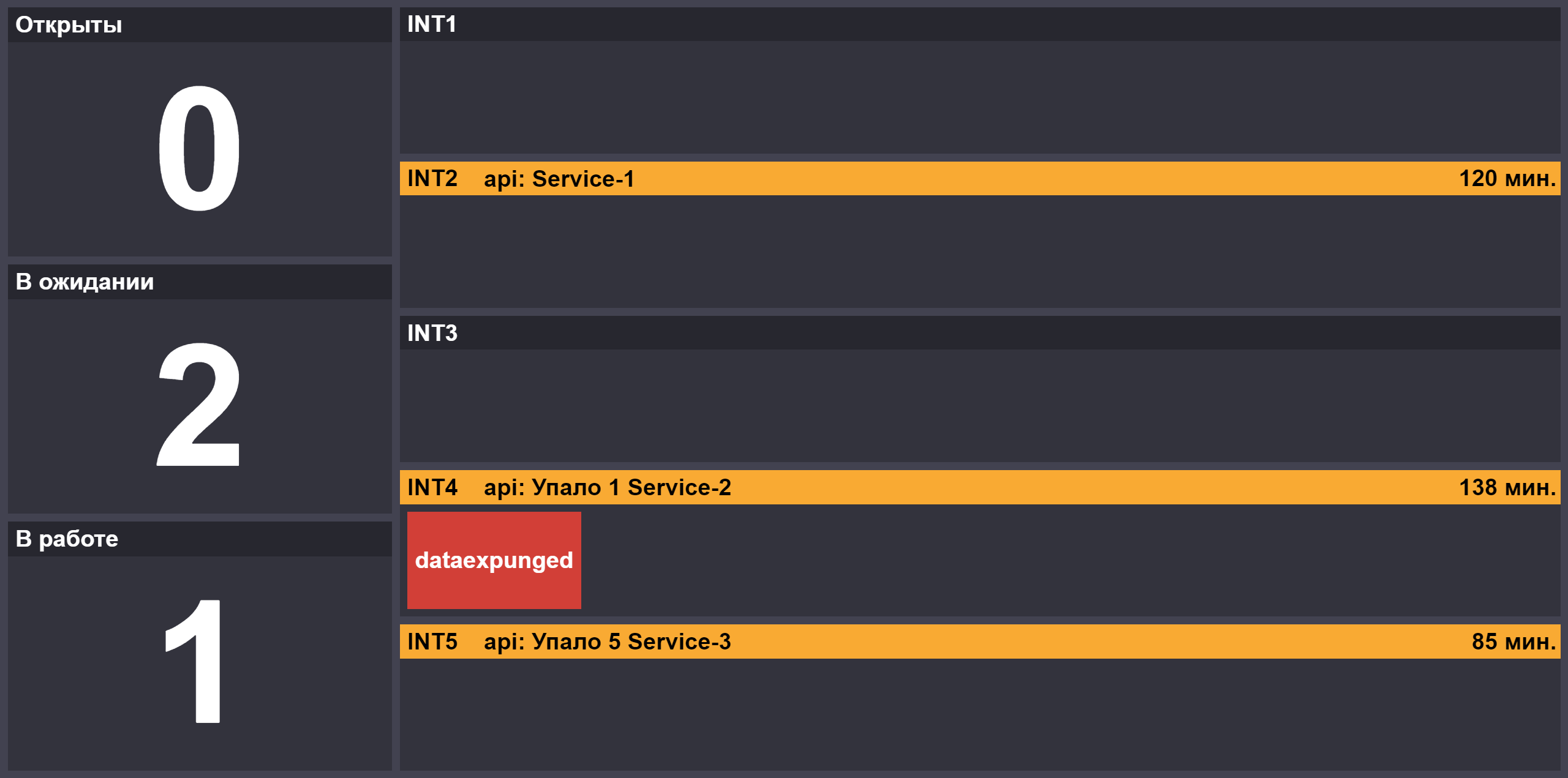
Работа дежурного требует концентрации, поэтому у него есть плюшка — в день дежурства он может выбрать место для обеда всей команды недалеко от офиса. Особенно весело выглядят подкупы дежурного в стиле: «давай я помогу разобрать задачи, а сегодня пойдем в моё любимое место» =)
Reporter
Одна из задач, с которой мы столкнулись, когда ввели дежурства, — необходимость передачи знаний от одного дежурного к другому, например, о падающих на новом релизе тестах или специфике обновления какого-то компонента.
Кроме того, у нас появились новые особенности работы.
- Возникла категория тестов, которые падают с большей или меньшей периодичностью за счет проблем с тестовыми стендами. Падения могут возникать из-за возросшего времени ответа одного из сервисов или долгой загрузки ресурсов в браузере. Выключать тесты не хочется, разумные средства повышения их надежности исчерпаны.
- У нас появился второй, экспериментальный проект с автотестами, и всплыла необходимость разбирать прогоны сразу двух проектов, просматривая отчеты Allure.
- Прогон тестов может занимать до 20 минут, а приступать к анализу результатов хочется сразу после начала первых падений. Особенно если задача критичная и члены ответственной за релиз команды стоят у тебя за спиной, приставив нож к горлу с жалобными глазами.
Так появился сервис Reporter. В него мы пушим результаты прогона тестов в реальном времени в процессе тестирования. В сервисе организована база известных проблем или багов, которые слинкованы с конкретным тестом. Также была добавлена публикация на wiki-портале компании сводного отчета по результатам прогона из репортера. Это удобно для менеджеров, которые не хотят погружаться в технические детали, которыми изобилует интерфейс Reporter или Allure.
При падении теста можно посмотреть в Reporter список связанных с ним багов или задач на исправление. Такая информация сокращает время разбора и облегчает обмен знаниями о проблемах между членами нашей команды. Записи о выполненных задачах уходят в архив, но если нужно, можно их «подсмотреть» в отдельном списке. Чтобы не грузить внутренние сервисы в рабочие часы, опрашиваем Jira по ночам и записи для issues с финальным статусом архивируем.
Бонусом от внедрения Reporter стало появление базы прогонов, на основе которой можно проанализировать частоту падений, ранжировать тесты по их уровню стабильности или «полезности» с точки зрения количества найденных багов.
Autorun
Далее мы перешли к автоматизации запуска тестов, когда в issue tracker приходит задача на приемочное тестирование релиза. Для этой цели был написан сервис Autorun, который проверяет, есть ли в Jira новые задачи на приёмку, и если да, то определяет имя компонента и его версию на основании контента задачи.
Для задачи выполняются несколько этапов:
- берем lock одного из свободных тестовых стендов в сервисе Locker,
- запускаем инсталляцию нужного компонента в Jenkins, ждем поднятия компонента с требуемой версией,
- запускаем тесты,
- ждем завершения прогона тестов, в процессе их выполнения все результаты пушатся в Reporter,
- запрашиваем у Reporter количество упавших тестов, исключая упавшие из-за известных проблем,
- если упало 0 — переводим задачу на приёмочное тестирование в «Готово» и завершаем работу с ней. Всё готово =)
- если есть «красные» тесты — переводим задачу в «Ожидание» и идем в Reporter для их разбора.
Переключения между этапами организованы по принципу конечного автомата. Каждый этап сам знает условия перехода к следующему. Результаты этапа сохраняются в task context, который является общим для стейджей одной задачи.
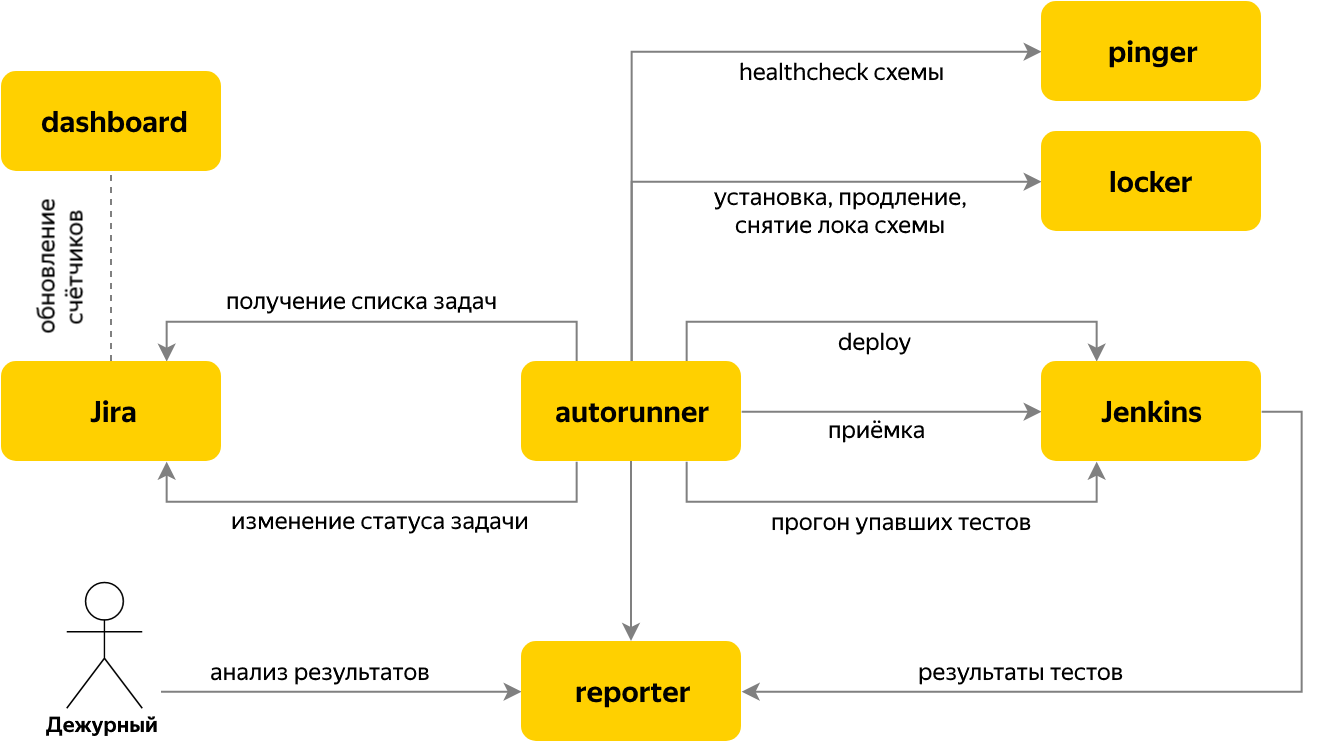
Всё это позволяет автоматически передавать дальше по конвейеру развертывания релизы, по которым 100 процентов тестов — зеленые. Но как быть с нестабильностью, вызванной не проблемами в компоненте, а «природными» особенностями UI-тестов или подросшими сетевыми задержками в тестовом стенде?
Для этого у нас реализован механизм повторных запусков (retry), которым многие пользуются, но мало кто в этом сознается. Ретраи организованы как последовательный запуск тестов в Jenkins Pipeline.
После прогона мы запрашиваем список упавших тестов у Reporter из Jenkins — и перезапускаем только провалившиеся. Кроме того — снижаем число потоков при запуске. Если число упавших тестов не уменьшилось по сравнению с предыдущим прогоном — сразу завершаем Job. В нашем случае такой подход к перезапуску позволяет повысить успешность приемочного тестирования примерно в 2 раза.
Quick-block
Получившаяся система приемочного тестирования позволила нам проводить больше 60% релизов без участия человека. Но что делать с оставшимися? При необходимости дежурный создает багрепорт на тестируемый компонент или задачу на исправление тестов в команду разработки. Иногда — оформляет баг конфигурации тестового стенда в отдел эксплуатации.
Задачи на исправление тестов часто блокируют корректное прохождение автоматического тестирования, так как неактуальные тесты будут всегда «красными». За написание новых тестов и актуализацию существующих отвечают тестировщики из команд разработки — внося изменения через pull request-ы в проект с автотестами. Эти правки проходят обязательное ревью, которое требует некоторого времени от ревьювера и от автора, и хочется временно заблокировать неактуальные тесты до перевода задачи на их исправление в финальный статус.
Сначала мы реализовали механизм отключения на основе аннотаций тестовых методов. Впоследствии оказалось, что из-за наличия обязательного код-ревью блокировка из кода оказывается не всегда удобной и может занять больше времени, чем хотелось бы.
Поэтому мы перенесли список блокирующих тесты задач в новый сервис с web-страницей — Quick-block. Так члены команды, ответственной за компонент, могут оперативно заблокировать тест. Перед прогоном мы ходим в этот сервис и получаем список тестов из карантина, которые переводим в статус skipped.
Итоги
Мы прошли путь от приемок релизов в ручном режиме до практически полностью автоматического процесса, который способен провести через приемочное тестирование более 50 релизов в день. Это помогает компании сократить время выкладки изменений, а нашей команде — находить ресурсы для экспериментов и развития инструментов тестирования.
В будущем планируем повысить надежность процесса, например, за счет распределения запросов между парой экземпляров каждого сервиса из списка выше. Это позволит обновлять инструменты без простоя и включать новые фичи только для части приемочных испытаний. Кроме того, мы уделяем внимание стабилизации самих тестов. В разработке генератор тикетов на рефакторинг тестов с самым низким success rate.
Повышение надежности тестов не только увеличит доверие к ним, но и ускорит тестирование релизов за счет отсутствия перезапусков упавших сценариев.
