Автоматизация разработки с помощью подхода DB-first
Интеграция с БД — привычно сложная и хрупкая часть большинства кодобаз, постоянно отвлекающая внимание разработчиков и раздувающая сроки. Какой бы хайпующий фреймворк вы ни пробовали, вы неизбежно обнаруживаете себя борющимся с одними и теми же симптомами, но ощущение того, что проблема могла бы решаться проще не покидает вас. Знакомо?
Оказывается, так вовсе не должно быть. В данном посте мы разберёмся в причинах и сформулируем подход, который оставляет большинство привычных проблем просто несуществующими.
Немного контекста
Если в проекте присутствует реляционная база данных, с ней необходимо интегрироваться из кода приложения. Возникает слой программного кода, который отвечает за общение с базой данных. На этом слое лежит ответственность за корректность команд и их соответствие структуре БД. Это достаточно сложности для того, чтобы изолировать этот слой от остального кода, что и является общепринятой практикой.
К такой интеграции существует три распространённых подхода:
Явно указывать запросы SQL как строковые значения и вручную прописывать кодеки.
ORM (Object-relational mapper) — фреймворки, абстрагирующиеся над реляционной моделью всецело и редуцирующие её до модели специфичной для фреймворка.
eDSL — фреймворки, абстрагирующиеся над запросами к БД и позволяющие воспользоваться помощью компилятора для их проверки при построении.
Последние два подхода по существу нацелены на автоматизацию проверок корректности интеграций за счёт абстракций, но, решая эту проблему, они привносят новые:
Завязывание интеграционного кода на специфичный для фреймворка способ выражения запросов. Умирает фреймворк — ваш проект в беде. Спецов по отдельному фреймворку по определению на рынке меньше, чем по SQL.
Переворачивание зависимостей с ног на голову: язык программирования диктует структуру БД и запросы к ней, хотя, на самом деле, это он интегрируется с БД, а никак не наоборот. Это приводит к усложнению деплоя и повышению его хрупкости, и ряду других проблем.
Практически в любом проекте, кроме демонстрационного от создателей фреймворка, пользователи сталкиваются с тупиковыми ситуациями, когда они не могут выразить корректные или эффективные запросы. Плодятся костыли.
Остаётся базовый подход: писать SQL-запросы и кодеки явно. Но остаётся и проблема автоматизации проверок на корректность. Можно ли её решить другими способами? Можно! Можно получить и гораздо больше, если опереться на подход от первых принципов. В этом посте я и опишу уже существующее решение.
Вырабатываем подход
Итак, проблема, которую мы будем решать, ясна: работа с сырым SQL муторна, требует указания множества деталей и лишена помощи от компилятора. Это ручной труд, он требует времени программиста, а человеческий фактор повышает вероятность багов в производимом коде. Чтобы снизить вероятность попадания багов в продакшн, требуется дополнительное время на покрытие тестами. Это тесты интеграционные, а значит, медленные и хрупкие.
Как по классике, приходится из времени, денег и качества выбирать только два, но это противоречие можно разрешить. На помощь приходит автоматизация.
Для начала разберёмся с тем, что это за процесс. Как правило, разработка приложения с реляционной БД проходит через следующие этапы:
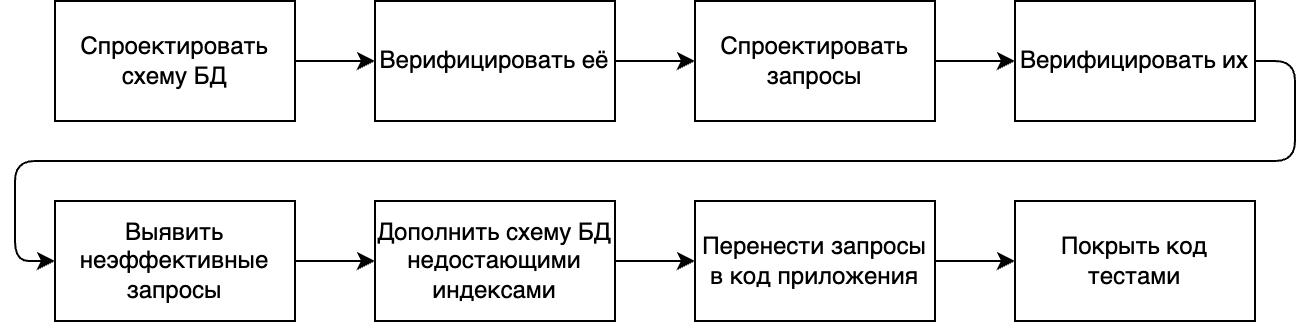
Стадии разработки
Что из этого мог бы сделать робот? Проектирование — это формулирование ваших замыслов. Никто, кроме вас, этого не сделает. А вот верификация — вполне себе рутинная задача: роботу не составит труда попытаться создать БД по вашей схеме и обработать ошибки, ровно как и попытаться исполнить против неё ваши запросы. Роботу не будет проблемой и дополнить ваши запросы командой explain и выявить seq-scan, что позволит выявить неэффективные запросы. В запросах и схеме БД содержится вся необходимая вводная информация для того, чтобы сгенерировать код приложения. Можно генерировать и тесты, но, учитывая уже проведённые верификации, кажется, в них отпадает необходимость.
Таким образом, мы выявили возможность сократить ручной труд до следующего:
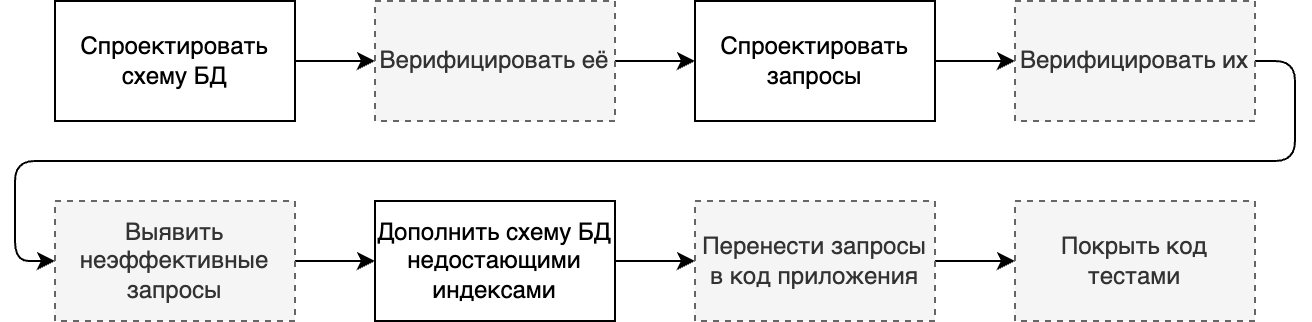
Стадии разработки при автоматизации
Получаем шаги, на выходе из которых мы должны получить какие-то артефакты, которые можно было бы передать инструменту, который осуществил бы за нас все остальные шаги. Что это за артефакты?
По схеме БД есть общепринятая практика ведения файлов-миграций. Это последовательность файлов, каждый из которых описывает набор изменений в схеме в языке SQL. Изменения в схеме — это добавления/изменения/удаления таблиц, колонок, индексов. Если последовательно исполнить каждый из этих файлов мы получим схему БД в актуальном её состоянии. Иными словами, этой информации достаточно для исчерпывающего представления о структуре БД, типах данных, связях, индексах.
По запросам артефакт — это (барабанная дробь) сами запросы в виде обычного SQL. Не нужно ничего городить: не нужен новый синтаксис, eDSL или какие-либо ещё исхищрения. Нет более универсального и полного способа передать данную информацию. В совокупности с информацией о схеме БД нам известно об этих запросах всё: типы их параметров и результатов и использование индексов.
Таким образом, мы выявили возможность создать инструмент, который бы, потребляя на вход файлы-миграции схемы и совокупность SQL-запросов к ней, проделывал бы следующее:

class MyDbConnection {
public long insertUserAndGetId(String name, Date birthday) {..}
public List selectUsersOlderThan(Date threshold) {..}
} Под точками, конечно же, подразумевается сгенерированная имплементация. Аналогичное мы могли бы получить и для Python, C++, Rust, Haskell и тд. Иными словами, пишем SQL и получаем интеграционный код для любого языка программирования, который гарантированно соответствует схеме и не может содержать багов (если багов, конечно, не содержит сам наш инструмент генерации), а тестировать больше и нечего.
Но и это не всё. Раз уж генерировать, так чего бы не сгенерировать красивую документацию? А почему бы не сгенерировать готовое приложение прокси-сервера, который будет представлять нашу БД в REST-API или gRPC? Может, ещё и дополнить код инициализации соединения с БД проверкой на совместимость, чтобы выявлять несовместимости на старте приложения, а не когда действия пользователя приведут к сбою? Такого точно никто не пишет руками, однако это позволило бы избежать многих неприятных инцидентов при ошибках деплоя.
Полагаю, уже понятно, что возможностей вскрывается масса, да и вскроются ещё, наверняка. При этом мы не изобретали велосипедов, а лишь нашли применение стандартному языку SQL.
Существующие решения
На рынке существует ряд инструментов, частично соответствующих выведенному подходу. Все зарубежные, все ограничены набором поддерживаемых языков программирования, некоторые платные.
Мы разработали собственный инструмент. Заходите на dbfirst.ru, чтобы узнать больше.
Если же вы хотите сократить t2m и:
проектируете новый сервис, то разработку качественной интеграции с PostgreSQL мы можем взять на себя.
столкнулись с накопленным техдолгом и проблемами с PostgreSQL, то мы поможем вам безопасно и надёжно привести код в порядок и прооптимизировать запросы.
хотите внедрить кодогенератор dbFirst в свою разработку, мы поможем вашей команде начать им пользоваться и будем поддерживать в дальнейшем.
По этим вопросам пишите на habr@dbfirst.ru.
