Автоматизация Для Самых Маленьких. Часть первая (которая после нулевой). Виртуализация сети
В предыдущем выпуске я описал фреймворк сетевой автоматизации. По отзывам у некоторых людей даже этот первый подход к проблеме уже разложил некоторые вопросы по полочкам. И это очень меня радует, потому что наша цель в цикле — не обмазать питоновскими скриптами анзибль, а выстроить систему.
Этот же фреймворк задаёт порядок, в котором мы будем разбираться с вопросом.
И виртуализация сети, которой посвящён этот выпуск, не особо укладывается в тематику АДСМ, где мы разбираем автоматику.
Но давайте взглянем на неё под другим углом.
Уже давно одной сетью пользуются многие сервисы. В случае оператора связи это 2G, 3G, LTE, ШПД и B2B, например. В случае ДЦ: связность для разных клиентов, Интернет, блочное хранилище, объектное хранилище.
И все сервисы требуют изоляции друг от друга. Так появились оверлейные сети.
И все сервисы не хотят ждать, когда человек настроит их вручную. Так появились оркестраторы и SDN.
Первый подход к систематической автоматизации сети, точнее её части, давно предпринят и много где внедрён в жизнь: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Вот с ним сегодня и поразбираемся.

- Причины
- Терминология
- Underlay — физическая сеть
- Overlay — виртуальная сеть
- Overlay с ToR’a
- Overlay с хоста
- На примере Tungsten Fabric
- Коммуникация внутри одной физической машины
- Коммуникация между ВМ, расположенными на разных физических машинах
- Выход во внешний мир
- FAQ
- Заключение
- Полезные ссылки
И раз уж мы об этом заговорили, то стоит упомянуть предпосылки к виртуализации сети. На самом деле этот процесс начался не вчера.
Наверно, вы не раз слышали, что сеть всегда была самой инертной частью любой системы. И это правда во всех смыслах. Сеть — это базис, на который опирается всё, и производить изменения на ней довольно сложно — сервисы не терпят, когда сеть лежит. Зачастую вывод из эксплуатации одного узла может сложить большую часть приложений и повлиять на много клиентов. Отчасти поэтому сетевая команда может сопротивляться любым изменениям — потому что сейчас оно как-то работает (мы, возможно, даже не знаем как), а тут надо что-то новое настроить, и неизвестно как оно повлияет на сеть.
Чтобы не ждать, когда сетевики прокинут VLAN и любые сервисы не прописывать на каждом узле сети, люди придумали использовать оверлеи — наложенные сети — коих великое многообразие: GRE, IPinIP, MPLS, MPLS L2/L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE итд.
Их привлекательность заключается в двух простых вещах:
— Настраиваются только конечные узлы — транзитные трогать не приходится. Это значительно ускоряет процесс, а иногда вообще позволяет исключить отдел сетевой инфраструктуры из процесса ввода новых сервисов.
— Нагрузка сокрыта глубоко внутри заголовков — транзитным узлам не нужно ничего знать о ней, об адресации на хостах, маршрутах наложенной сети. А это значит, нужно хранить меньше информации в таблицах, значит взять попроще/подешевле устройство.
В этом не совсем полноценном выпуске я не планирую разбирать все возможные технологии, а скорее описать фреймворк работы оверлейных сетей в ДЦ.
Вся серия будет описывать датацентр, состоящий из рядов однотипных стоек, в которых установлено одинаковое серверное оборудование.
На этом оборудовании запускаются виртуальные машины/контейнеры/серверлесс, реализующие сервисы.

В цикле сервером я буду называть программу, которая реализует серверную сторону клиент-серверной коммуникации.
Физические машины в стойках называть серверами не будем.
Физическая машина — x86-компьютер, установленный в стойке. Наиболее часто употребим термин хост. Так и будем называть её »машина» или хост.
Гипервизор — приложение, запущенное на физической машине, эмулирующее физические ресурсы, на которых запускаются Виртуальные Машины. Иногда в литературе и сети слово «гипервизор» используют как синоним «хост».
Виртуальная машина — операционная система, запущенная на физической машине поверх гипервизора. Для нас в рамках данного цикла не так уж важно, на самом ли деле это виртуальная машина или просто контейнер. Будем называть это »ВМ»
Тенант — широкое понятие, которое я в этой статье определю как отдельный сервис или отдельный клиент.
Мульти-тенантность или мультиарендность — использование одного и того же приложения разными клиентами/сервисами. При этом изоляция клиентов друг от друга достигается благодаря архитектуре приложения, а не отдельно-запущенным экземплярам.
ToR — Top of the Rack switch — коммутатор, установленный в стойке, к которому подключены все физические машины.
Кроме топологии ToR, разные провайдеры практикуют End of Row (EoR) или Middle of Row (хотя последнее — пренебрежительная редкость и аббревиатуры MoR я не встречал).
Underlay network или подлежащая сеть или андэрлей — физическая сетевая инфраструктура: коммутаторы, маршрутизаторы, кабели.
Overlay network или наложенная сеть или оверлей — виртуальная сеть туннелей, работающая поверх физической.
L3-фабрика или IP-фабрика — потрясающее изобретение человечества, позволяющее к собеседованиям не повторять STP и не учить TRILL. Концепция, в которой вся сеть вплоть до уровня доступа исключительно L3, без VLAN и соответственно огромных растянутых широковещательных доменов. Откуда тут слово «фабрика» разберёмся в следующей части.
SDN — Software Defined Network. Едва ли нуждается в представлении. Подход к управлению сетью, когда изменения на сети выполняются не человеком, а программой. Обычно означает вынесение Control Plane за пределы конечных сетевых устройств на контроллер.
NFV — Network Function Virtualization — виртуализация сетевых устройств, предполагающая, что часть функций сети можно запускать в виде виртуальных машин или контейнеров для ускорения внедрения новых сервисов, организации Service Chaining и более простой горизонтальной масштабируемости.
VNF — Virtual Network Function. Конкретное виртуальное устройство: маршрутизатор, коммутатор, файрвол, NAT, IPS/IDS итд.
Я сейчас намеренно упрощаю описание до конкретной реализации, чтобы сильно не запутывать читателя. Для более вдумчивого чтения отсылаю его к секции Ссылки. Кроме того, Рома Горге, критикующий данную статью за неточности, обещает написать отдельный выпуск о технологиях виртуализации серверов и сетей, более глубокую и внимательную к деталям.
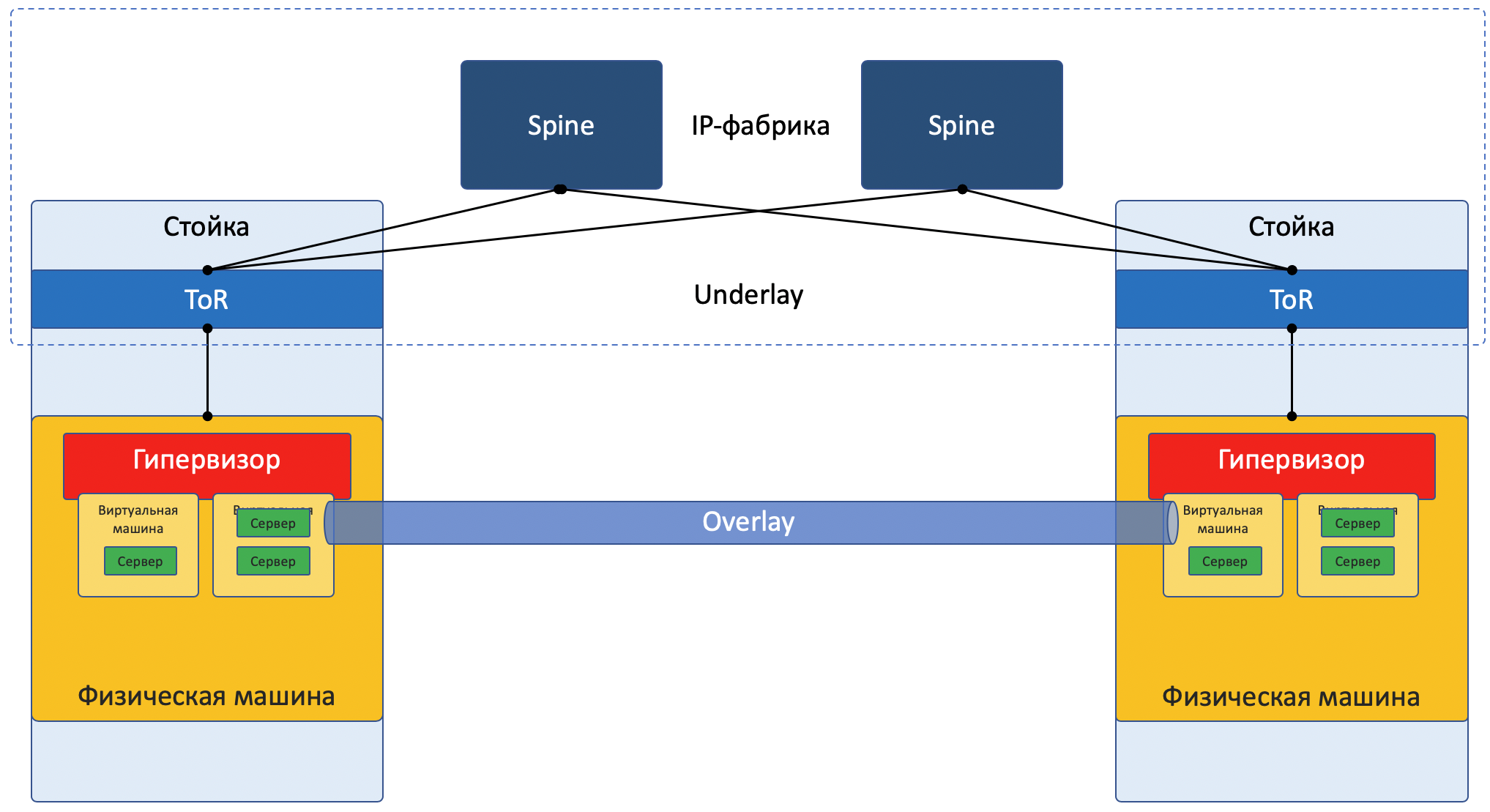
Большинство сетей сегодня можно явно разбить на две части:
Underlay — физическая сеть со стабильной конфигурацией.
Overlay — абстракция над Underlay для изоляции тенантов.
Это верно, как для случая ДЦ (который мы разберём в этой статьей), так и для ISP (который мы разбирать не будем, потому что уже было в СДСМ). С энтерпрайзными сетями, конечно, ситуация несколько иная.
Картинка с фокусом на сеть:

Underlay — это физическая сеть: аппаратные коммутаторы и кабели. Устройства в андерлее знают, как добраться до физических машин.
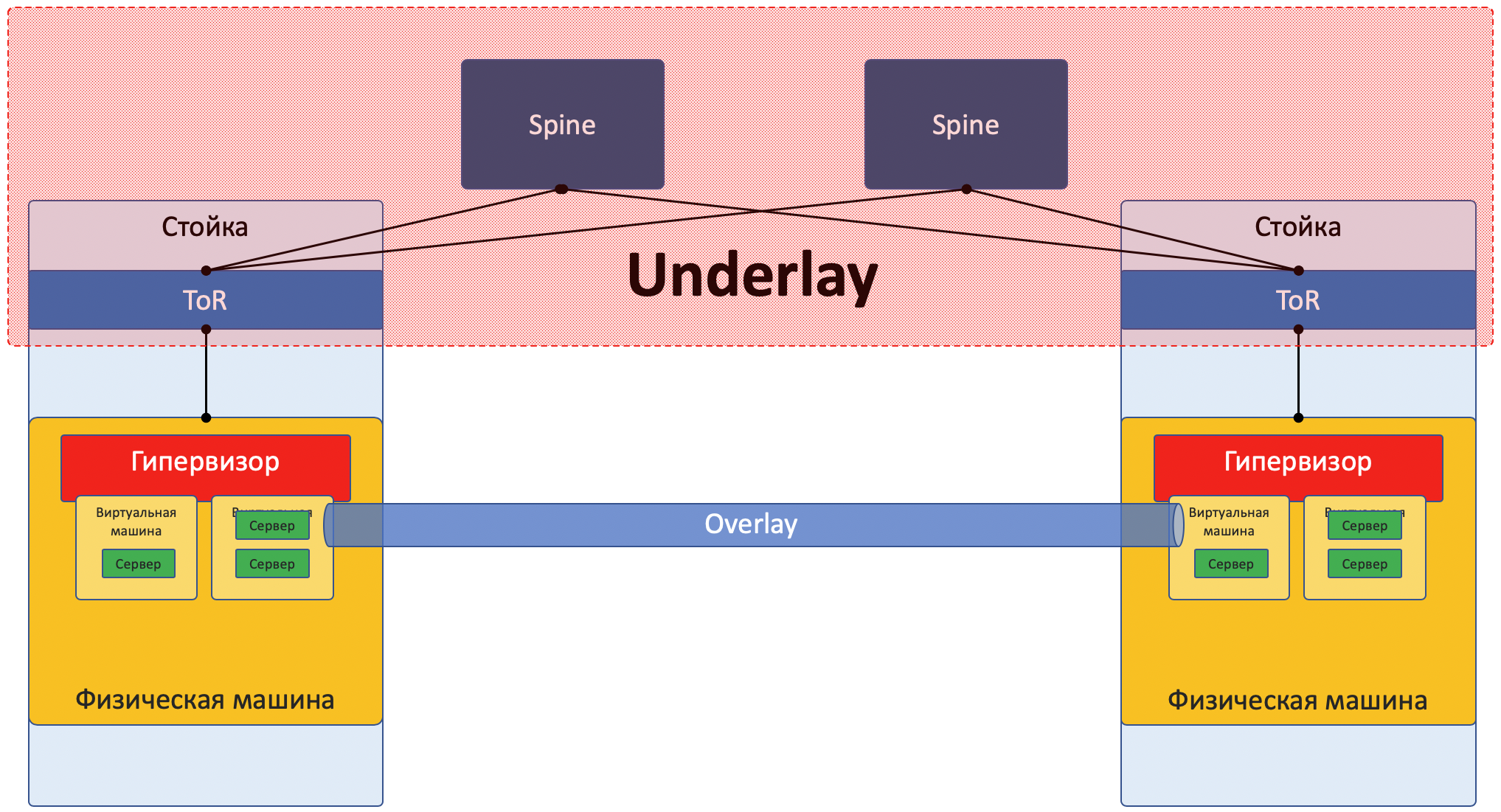
Опирается он на стандартные протоколы и технологии. Не в последнюю очередь потому, что аппаратные устройства по сей день работают на проприетарном ПО, не допускающем ни программирование чипа, ни реализацию своих протоколов, соответственно, нужна совместимость с другими вендорами и стандартизация.
А вот кто-нибудь вроде Гугла может себе позволить разработку собственных коммутаторов и отказ от общепринятых протоколов. Но LAN_DC не Гугл.
Underlay сравнительно редко меняется, потому что его задача — базовая IP-связность между физическими машинами. Underlay ничего не знает о запущенных поверх него сервисах, клиентах, тенантах — ему нужно только доставить пакет от одной машины до другой.
Underlay может быть например таким:
- IPv4+OSPF
- IPv6+ISIS+BGP+L3VPN
- L2+TRILL
- L2+STP
Настраивается Underlay’ная сеть классическим образом: CLI/GUI/NETCONF.
Вручную, скриптами, проприетарными утилитами.
Более подробно андерлею будет посвящена следующая статья цикла.
Overlay — виртуальная сеть туннелей, натянутая поверх Underlay, она позволяет ВМ одного клиента общаться друг с другом, при этом обеспечивая изоляцию от других клиентов.
Данные клиента инкапсулируются в какие-либо туннелирующие заголовки для передачи через общую сеть.

Так ВМ одного клиента (одного сервиса) могут общаться друг с другом через Overlay, даже не подозревая какой на самом деле путь проходит пакет.
Overlay может быть например таким, как уже я упоминал выше:
- GRE-туннель
- VXLAN
- EVPN
- L3VPN
- GENEVE
Overlay’ная сеть обычно настраивается и поддерживается через центральный контроллер. С него конфигурация, Control Plane и Data Plane доставляются на устройства, которые занимаются маршрутизацией и инкапсуляцией клиентского трафика. Чуть ниже разберём это на примерах.
Да, это SDN в чистом виде.
Существует два принципиально различающихся подхода к организации Overlay-сети:
- Overlay с ToR’a
- Overlay с хоста
Overlay с ToR’a
Overlay может начинаться на коммутаторе доступа (ToR), стоящем в стойке, как это происходит, например, в случае VXLAN-фабрики.
Это проверенный временем на сетях ISP механизм и все вендоры сетевого оборудования его поддерживают.
Однако в этом случае ToR-коммутатор должен уметь разделять различные сервисы, соответственно, а сетевой администратор должен в известной степени сотрудничать с администраторами виртуальных машин и вносить изменения (пусть и автоматически) в конфигурацию устройств.
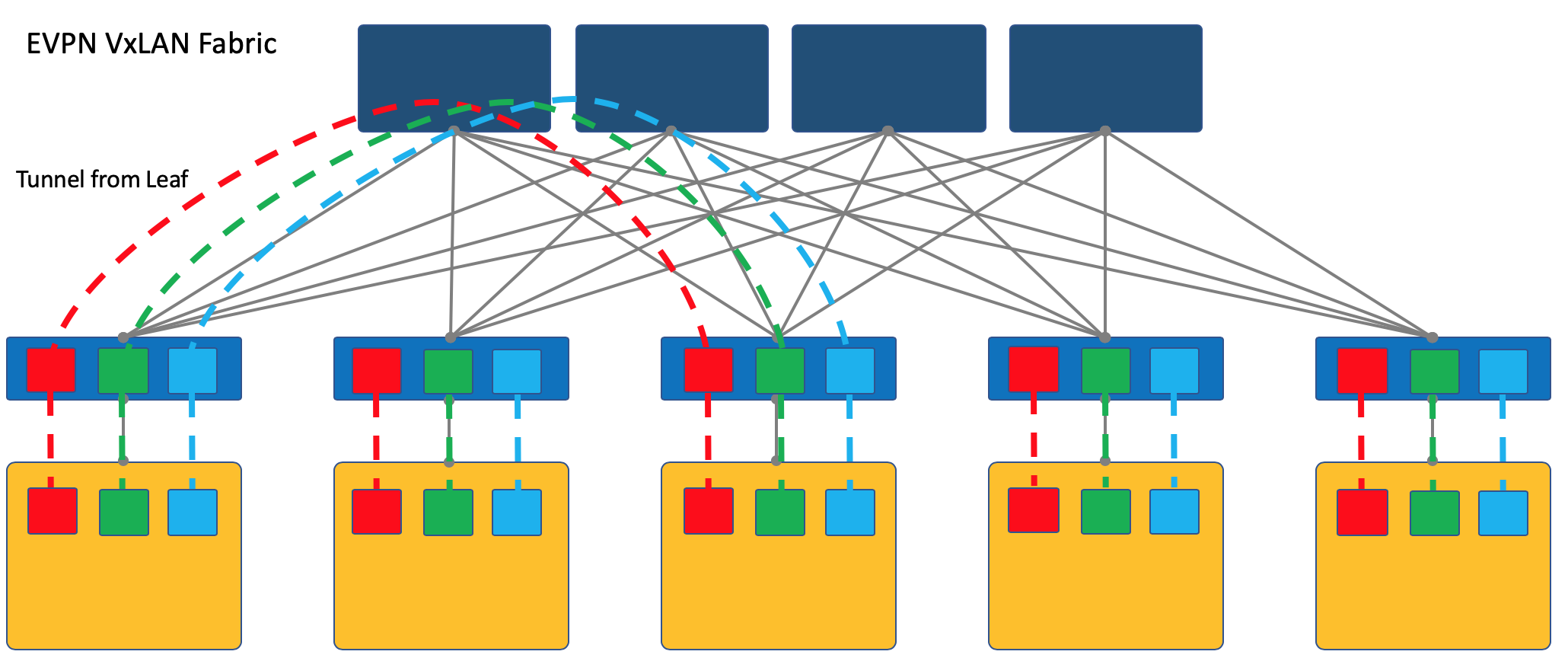
Тут я отошлю читателя к статье о VxLAN на хабре нашего старого друга @bormoglotx.
В этой презентации с ENOG подробно описаны подходы к строительству сети ДЦ с EVPN VXLAN-фабрикой.
А для более полного погружения в реалии, можно почитать цискину книгу A Modern, Open, and Scalable Fabric: VXLAN EVPN.
Замечу, что VXLAN — это только метод инкапсуляции и терминация туннелей может происходить не на ToR’е, а на хосте, как это происходит в случае OpenStack’а, например.
Однако, VXLAN-фабрика, где overlay начинается на ToR’е является одним из устоявшихся дизайнов оверлейной сети.
Overlay с хоста
Другой подход — начинать и терминировать туннели на конечных хостах.
В этом случае сеть (Underlay) остаётся максимально простой и статичной.
А хост сам делает все необходимые инкапсуляции.
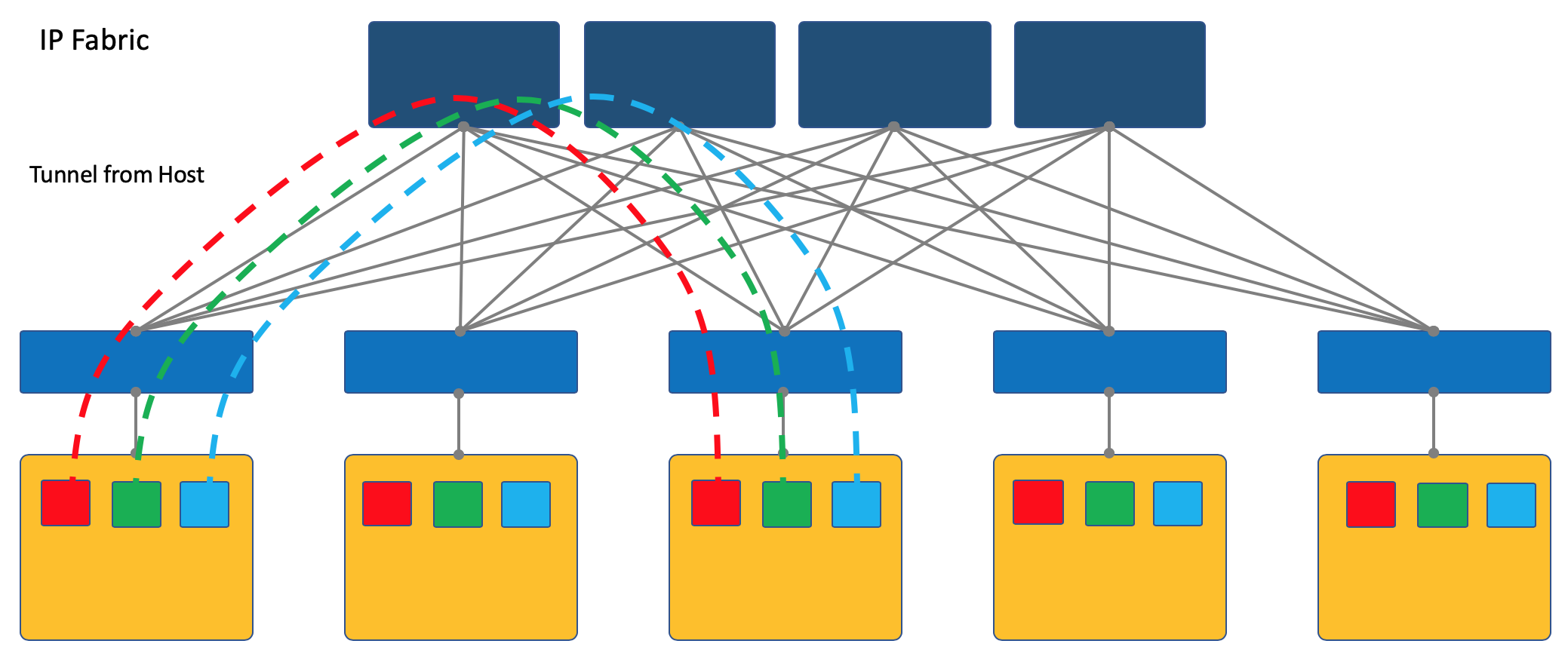
Для этого потребуется, безусловно, запускать специальное приложение на хостах, но оно того стоит.
Во-первых, запустить клиент на linux-машине проще или, скажем так, — вообще возможно — в то время как на коммутаторе, скорее всего, придётся пока обращаться к проприетарным SDN-решениям, что убивает идею мультивендорности.
Во-вторых, ToR-коммутатор в этом случае можно оставить максимально простым, как с точки зрения Control Plane’а, так и Data Plane’а. Действительно — с SDN-контроллером ему тогда общаться не нужно, и хранить сети/ARP’ы всех подключенных клиентов — тоже — достаточно знать IP-адрес физической машины, что кратно облегчает таблицы коммутации/маршрутизации.
В серии АДСМ я выбираю подход оверлея с хоста — далее мы говорим только о нём и возвращаться к VXLAN-фабрике мы уже не будем.
Проще всего рассмотреть на примерах. И в качестве подопытного мы возьмём OpenSource’ную SDN платформу OpenContrail, ныне известную как Tungsten Fabric.
В конце статьи я приведу некоторые размышления на тему аналогии с OpenFlow и OpenvSwitch.
На примере Tungsten Fabric
На каждой физической машине есть vRouter — виртуальный маршрутизатор, который знает о подключенных к нему сетях и каким клиентам они принадлежат — по сути — PE-маршрутизатор. Для каждого клиента он поддерживает изолированную таблицу маршрутизации (читай VRF). И собственно vRouter делает Overlay’ное туннелирование.
Чуть подробнее про vRouter — в конце статьи.
Каждая ВМ, расположенная на гипервизоре, соединяется с vRouter’ом этой машины через TAP-интерфейс.
TAP — Terminal Access Point — виртуальный интерфейс в ядре linux, которые позволяет осуществлять сетевое взаимодействие.

Если за vRouter’ом находится несколько сетей, то для каждой из них создаётся виртуальный интерфейс, на который назначается IP-адрес — он будет адресом шлюза по умолчанию.
Все сети одного клиента помещаются в один VRF (одну таблицу), разных — в разные.
Сделаю тут оговорку, что не всё так просто, и отправлю любознательного читателя в конец статьи.
Чтобы vRouter’ы могли общаться друг с другом, а соответственно и ВМ, находящиеся за ними, они обмениваются маршрутной информацией через SDN-контроллер.
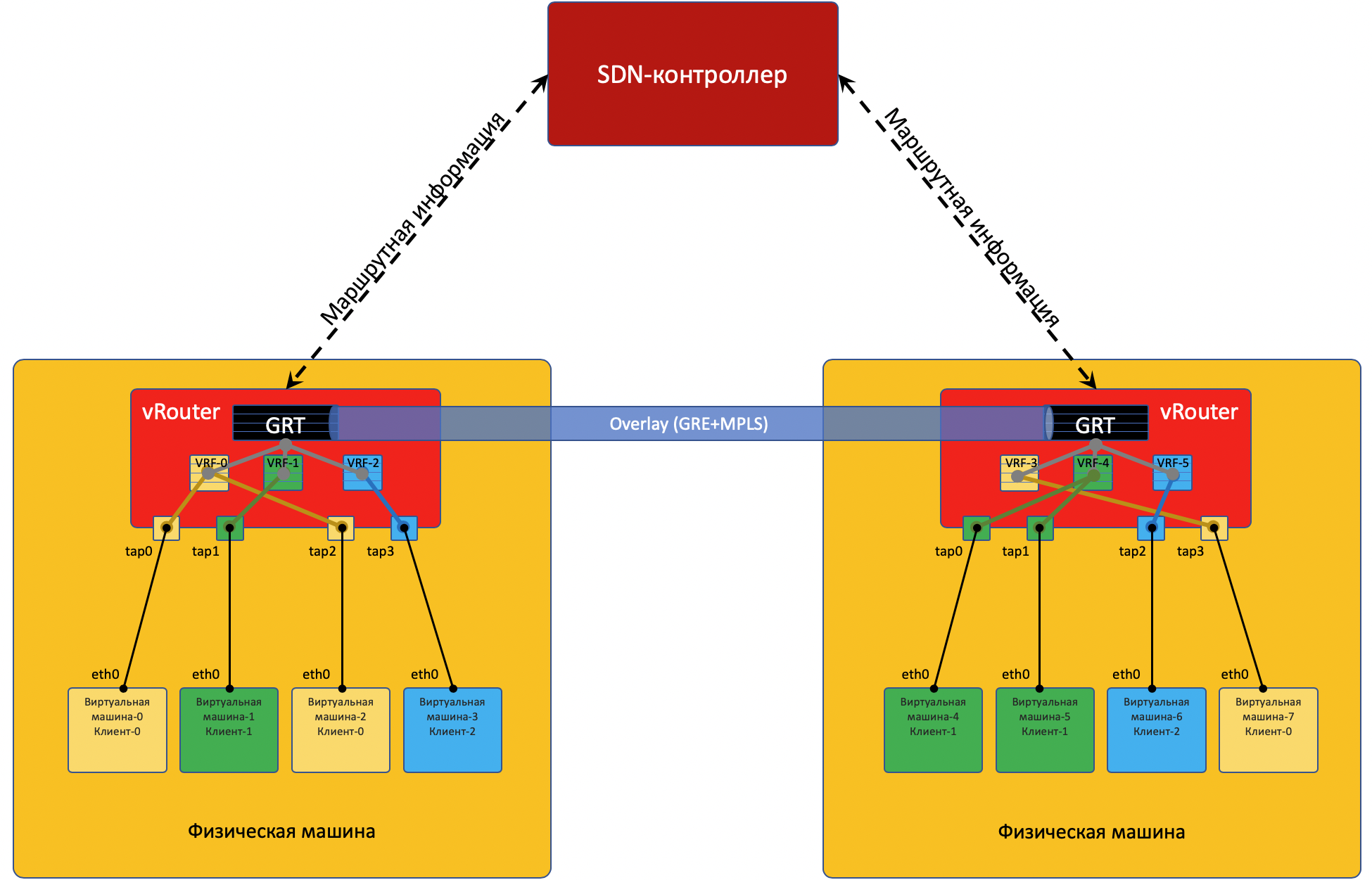
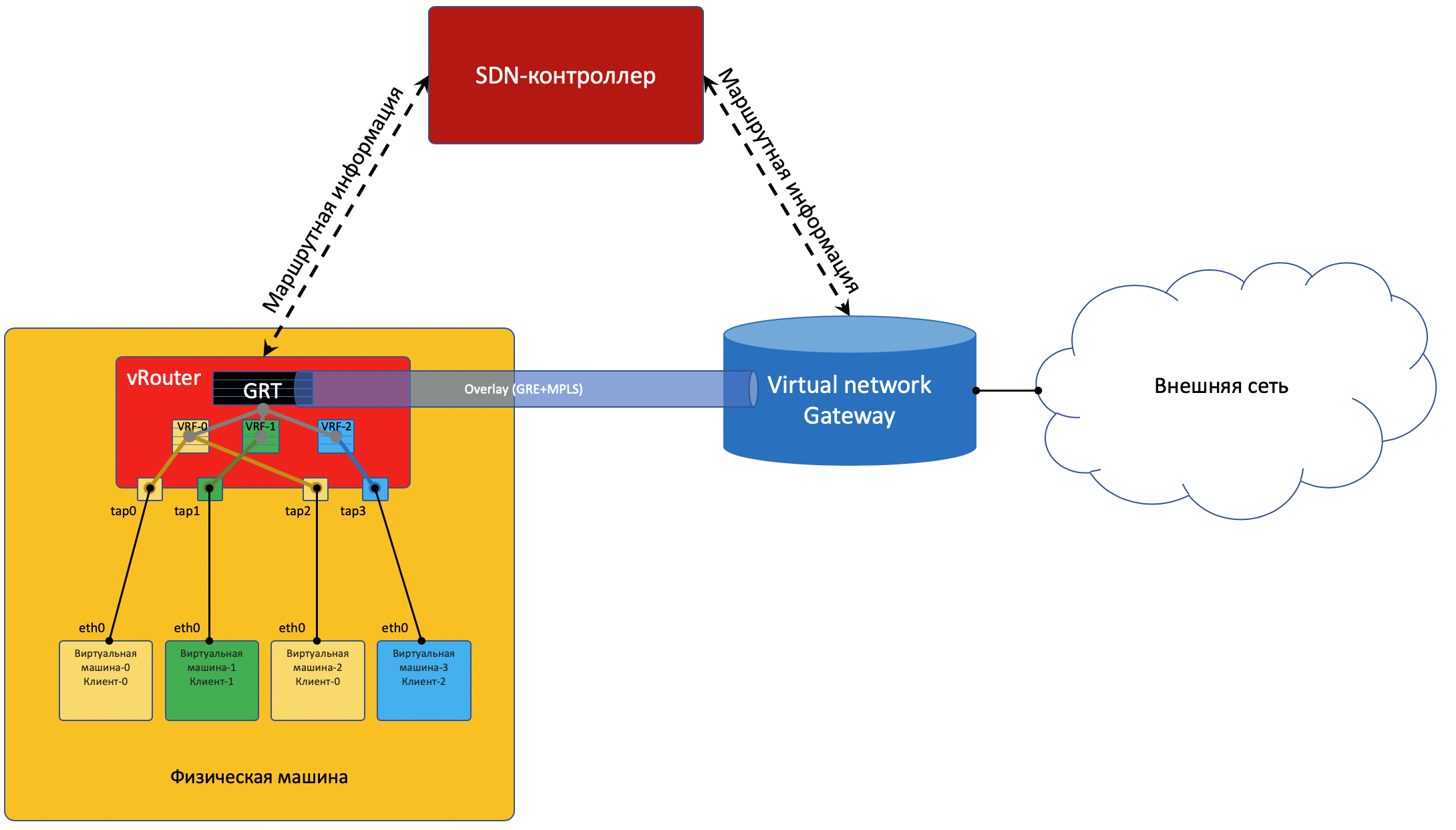
Чтобы выбраться во внешний мир, существует точка выхода из матрицы — шлюз виртуальной сети VNGW — Virtual Network GateWay (термин мой).
Теперь рассмотрим примеры коммуникаций — и будет ясность.
Коммуникация внутри одной физической машины
VM0 хочет отправить пакет на VM2. Предположим пока, что это ВМ одного клиента.
Data Plane
- У VM-0 есть маршрут по умолчанию в его интерфейс eth0. Пакет отправляется туда.
Этот интерфейс eth0 на самом деле виртуально соединён с виртуальным маршрутизатором vRouter через TAP-интерфейс tap0. - vRouter анализирует на какой интерфейс пришёл пакет, то есть к какому клиенту (VRF) он относится, сверяет адрес получателя с таблицей маршрутизации этого клиента.
- Обнаружив, что получатель на этой же машине за другим портом, vRouter просто отправляет пакет в него без каких-либо дополнительных заголовков — на этот случай на vRouter’е уже есть ARP-запись.
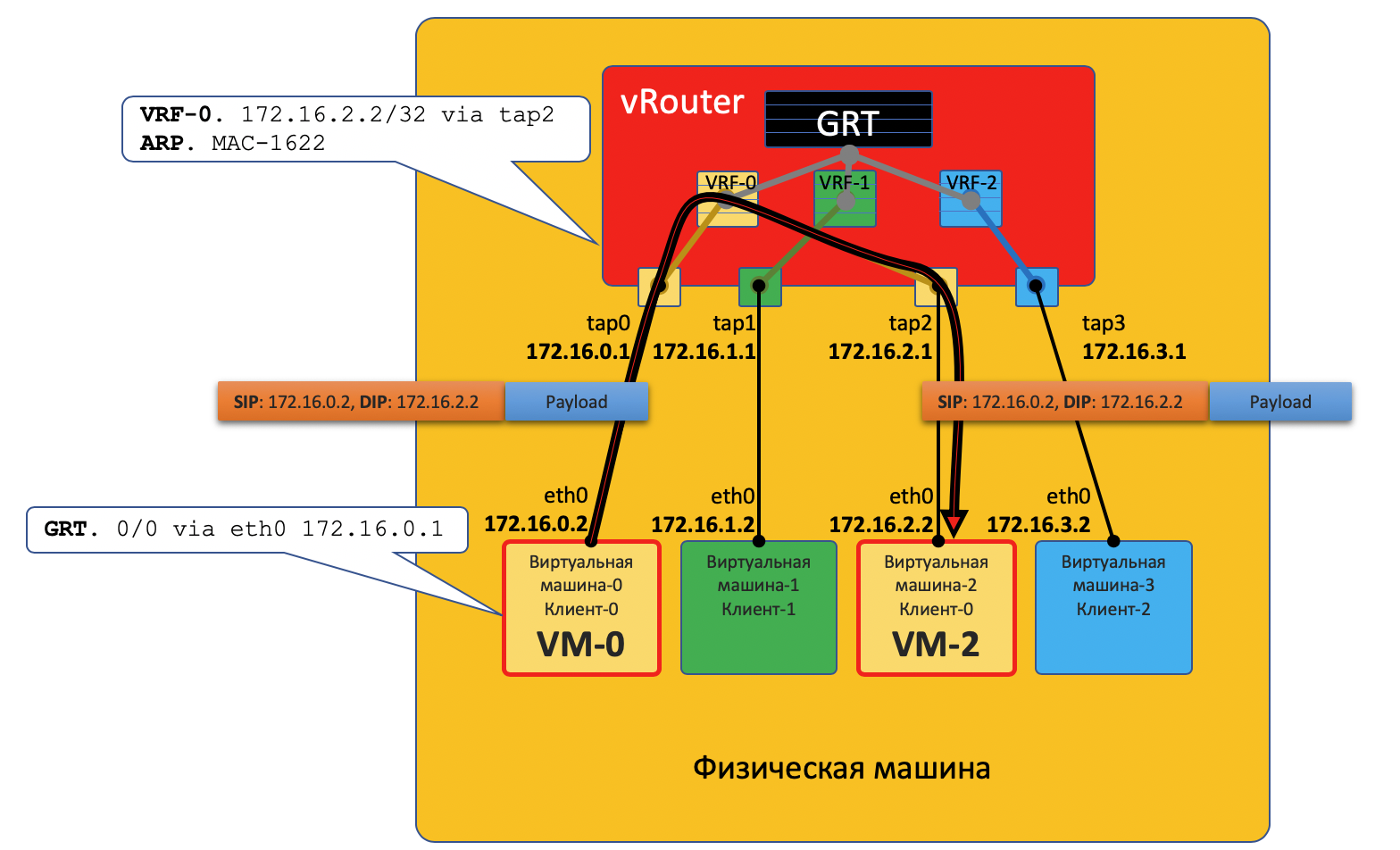
Пакет в этом случае не попадает в физическую сеть — он смаршрутизировался внутри vRouter’а.
Control Plane
Гипервизор при запуске виртуальной машины сообщает ей:
- Её собственный IP-адрес.
- Маршрут по умолчанию — через IP-адрес vRouter’а в этой сети.
vRouter’у через специальный API гипервизор сообщает:
- Что нужно создать виртуальный интерфейс.
- Какой ей (ВМ) нужно создать Virtual Network.
- К какому VRF его (VN) привязать.
- Статическую ARP-запись для этой VM — за каким интерфейсом находится её IP-адрес и к какому MAC-адресу он привязан.
И снова, реальная процедура взаимодействия упрощена в угоду понимания концепции.

Таким образом все ВМ одного клиента на данной машине vRouter видит как непосредственно подключенные сети и может сам между ними маршрутизировать.
А вот VM0 и VM1 принадлежат разным клиентам, соответственно, находятся в разных таблицах vRouter’а.
Смогут ли они друг с другом общаться напрямую, зависит от настроек vRouter и дизайна сети.
Например, если ВМ обоих клиентов используют публичные адреса, или NAT происходит на самом vRouter’е, то можно сделать и прямую маршрутизацию на vRouter.
В противной же ситуации возможно пересечение адресных пространств — нужно ходить через NAT-сервер, чтобы получить публичный адрес — это похоже на выход во внешние сети, о которых ниже.
Коммуникация между ВМ, расположенными на разных физических машинах
Data Plane
- Начало точно такое же: VM-0 посылает пакет с адресатом VM-7 (172.17.3.2) по своему дефолту.
- vRouter его получает и на этот раз видит, что адресат находится на другой машине и доступен через туннель Tunnel0.
- Сначала он вешает метку MPLS, идентифицирующую удалённый интерфейс, чтобы на обратной стороне vRouter мог определить куда этот пакет поместить причём без дополнительных лукапов.

- У Tunnel0 источник 10.0.0.2, получатель: 10.0.1.2.
vRouter добавляет заголовки GRE (или UDP) и новый IP к исходному пакету. - В таблице маршрутизации vRouter есть маршрут по умолчанию через адрес ToR1 10.0.0.1. Туда и отправляет.
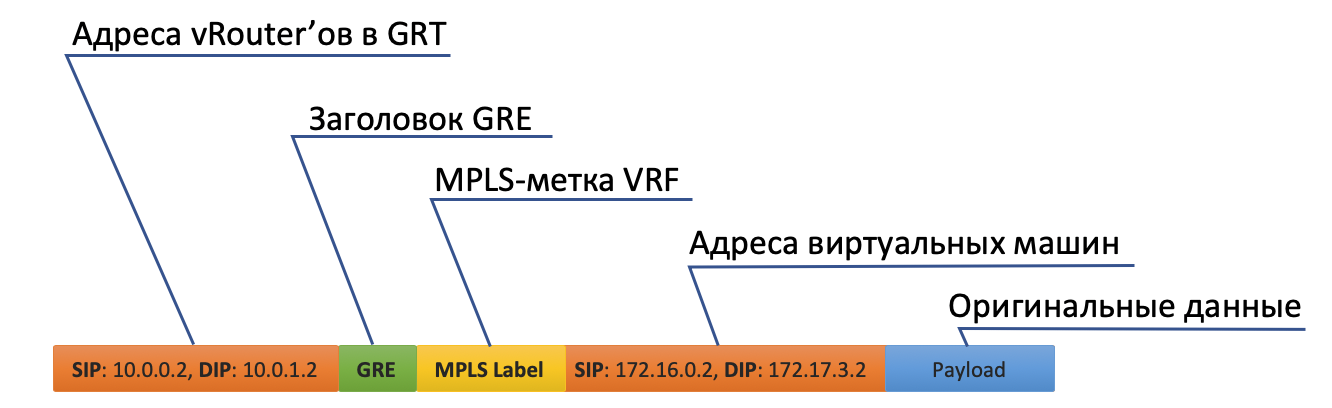
- ToR1 как участник Underlay сети знает (например, по OSPF), как добраться до 10.0.1.2, и отправляет пакет по маршруту. Обратите внимание, что здесь включается ECMP. На иллюстрации два некстхопа, и разные потоки будут раскладываться в них по хэшу. В случае настоящей фабрики тут будет скорее 4 некстхопа.
При этом знать, что находится под внешним заголовком IP ему не нужно. То есть фактически под IP может быть бутерброд из IPv6 over MPLS over Ethernet over MPLS over GRE over over over Грека. - Соответственно на принимающей стороне vRouter снимает GRE и по MPLS-метке понимает, в какой интерфейс этот пакет надо передать, раздевает его и отправляет в первоначальном виде получателю.
Control Plane
При запуске машины происходит всё то же, что было описано выше.
И плюс ещё следующее:
- Для каждого клиента vRouter выделяет MPLS-метку. Это сервисная метка L3VPN, по которой клиенты будут разделяться в пределах одной физической машины.
На самом деле MPLS-метка выделяется vRouter’ом безусловно всегда — ведь неизвестно заранее, что машина будет взаимодействовать только с другими машинам за тем же vRouter’ом и это скорее всего даже не так.
- vRouter устанавливает соединение с SDN-контроллером по протоколу BGP (или похожему на него — в случае TF -это XMPP 0_o).
- Через эту сессию vRouter сообщает SDN-контроллеру маршруты до подключенных сетей:
- Адрес сети
- Метод инкапсуляции (MPLSoGRE, MPLSoUDP, VXLAN)
- MPLS-метку клиента
- Свой IP-адрес в качестве nexthop
- SDN-контроллер получает такие маршруты ото всех подключенных vRouter’ов, и отражает их другим. То есть он выступает Route Reflector’ом.
То же самое происходит и в обратную сторону.

Overlay может меняться хоть каждую минуту. Примерно так это и происходит в публичных облаках, когда клиенты регулярно запускают и выключают свои виртуальные машины.
Центральный контроллер берёт на себя все сложности с поддержанием конфигурации и контролем таблиц коммутации/маршрутизации на vRouter.
Если говорить грубо, то контроллер запиривается со всеми vRouter’ами по BGP (или похожему на него протоколу) и просто передаёт маршрутную информацию. BGP, например, уже имеет Address-Family для передачи метода инкапсуляции MPLS-in-GRE или MPLS-in-UDP.
При этом не меняется никоим образом конфигурация Underlay-сети, которую кстати, автоматизировать на порядок сложнее, а сломать неловким движением проще.
Выход во внешний мир
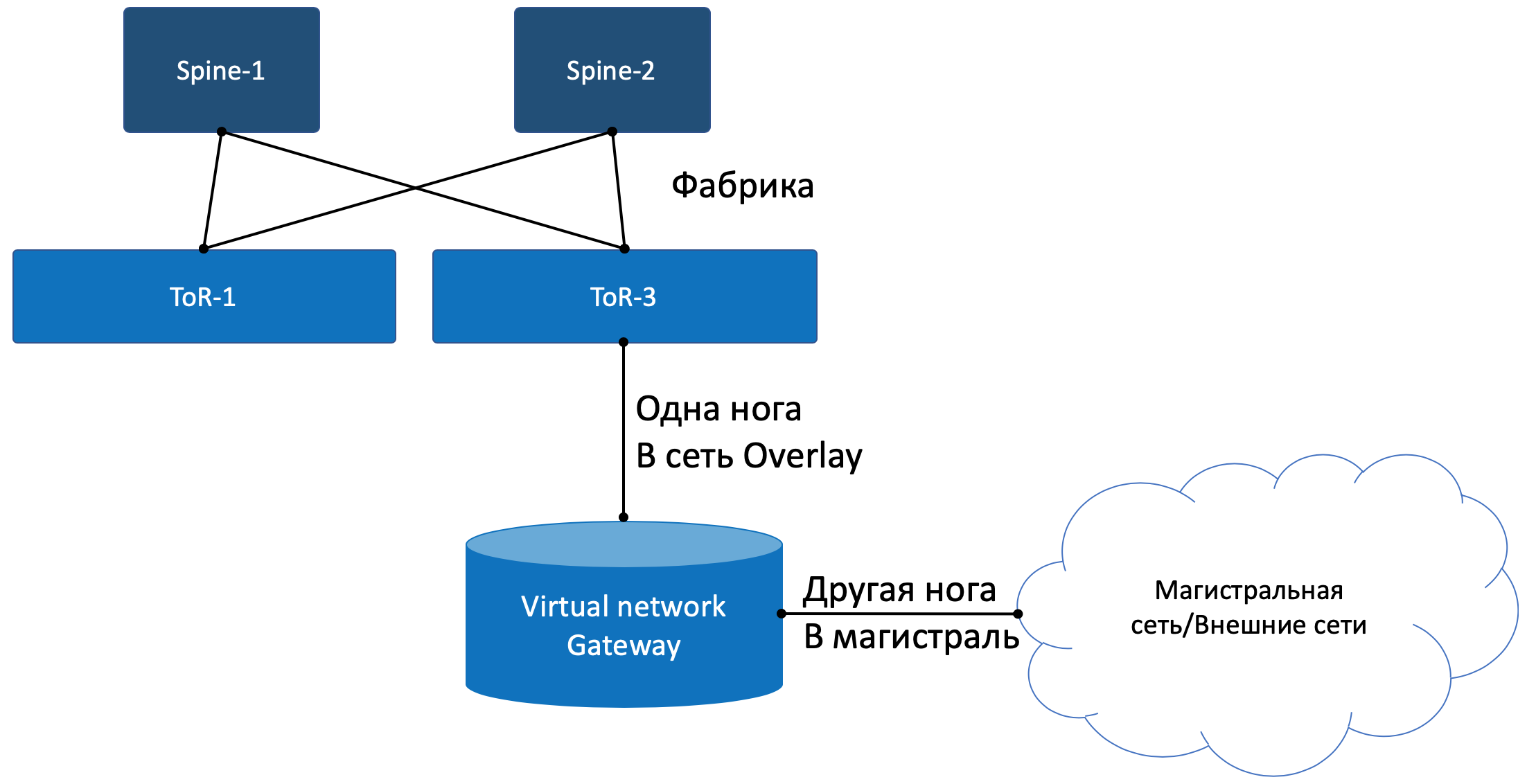
Где-то симуляция должна закончиться, и из виртуального мира нужно выйти в реальный. И нужен таксофон шлюз.
Практикуют два подхода:
- Ставится аппаратный маршрутизатор.
- Запускается какой-либо appliance, реализующий функции маршрутизатора (да-да, вслед за SDN мы и с VNF столкнулись). Назовём его виртуальный шлюз.
Преимущество второго подхода в дешёвой горизонтальной масштабируемости — не хватает мощности — запустили ещё одну виртуалку со шлюзом. На любой физической машине, без необходимости искать свободные стойки, юниты, вывода питания, покупать саму железку, везти её, устанавливать, коммутировать, настраивать, а потом ещё и менять в ней сбойные компоненты.
Минусы же у виртуального шлюза в том, что единица физического маршрутизатора всё же на порядки мощнее многоядерной виртуалки, а его софт, подогнанный под его же аппаратную основу, работает значительно стабильнее (нет). Сложно отрицать и тот факт, что программно-аппаратный комплекс просто работает, требуя только настройки, в то время как запуск и обслуживание виртуального шлюза — занятие для сильных инженеров.
Одной своей ногой шлюз смотрит в виртуальную сеть Overlay, как обычная Виртуальная Машина, и может взаимодействовать со всеми другими ВМ. При этом она может терминировать на себе сети всех клиентов и, соответственно, осуществлять и маршрутизацию между ними.
Другой ногой шлюз смотрит уже в магистральную сеть и знает о том, как выбраться в Интернет.
Data Plane
То есть процесс выглядит так:
- VM-0, имея дефолт всё в тот же vRouter, отправляет пакет с адресатом во внешнем мире (185.147.83.177) в интерфейс eth0.
- vRouter получает этот пакет и делает лукап адреса назначения в таблице маршрутизации — находит маршрут по умолчанию через шлюз VNGW1 через Tunnel 1.
Также он видит, что это туннель GRE с SIP 10.0.0.2 и DIP 10.0.255.2, а ещё нужно сначала повесить MPLS-метку данного клиента, которую ожидает VNGW1. - vRouter упаковывает первоначальный пакет в заголовки MPLS, GRE и новый IP и отправляет на адрес ToR1 10.0.0.1 по дефолту.
- Андерлейная сеть доставляет пакет до шлюза VNGW1.
- Шлюз VNGW1 снимает туннелирующие заголовки GRE и MPLS, видит адрес назначения, консультируется со своей таблицей маршрутизации и понимает, что он направлен в Интернет — значит через Full View или Default. При необходимости производит NAT-трансляцию.
- От VNGW до бордера может быть обычная IP-сеть, что вряд ли.
Может быть классическая MPLS сеть (IGP+LDP/RSVP TE), может быть обратно фабрика с BGP LU или GRE-туннель от VNGW до бордера через IP-сеть.
Как бы то ни было VNGW1 совершает необходимые инкапсуляции и отправляет первоначальный пакет в сторону бордера.
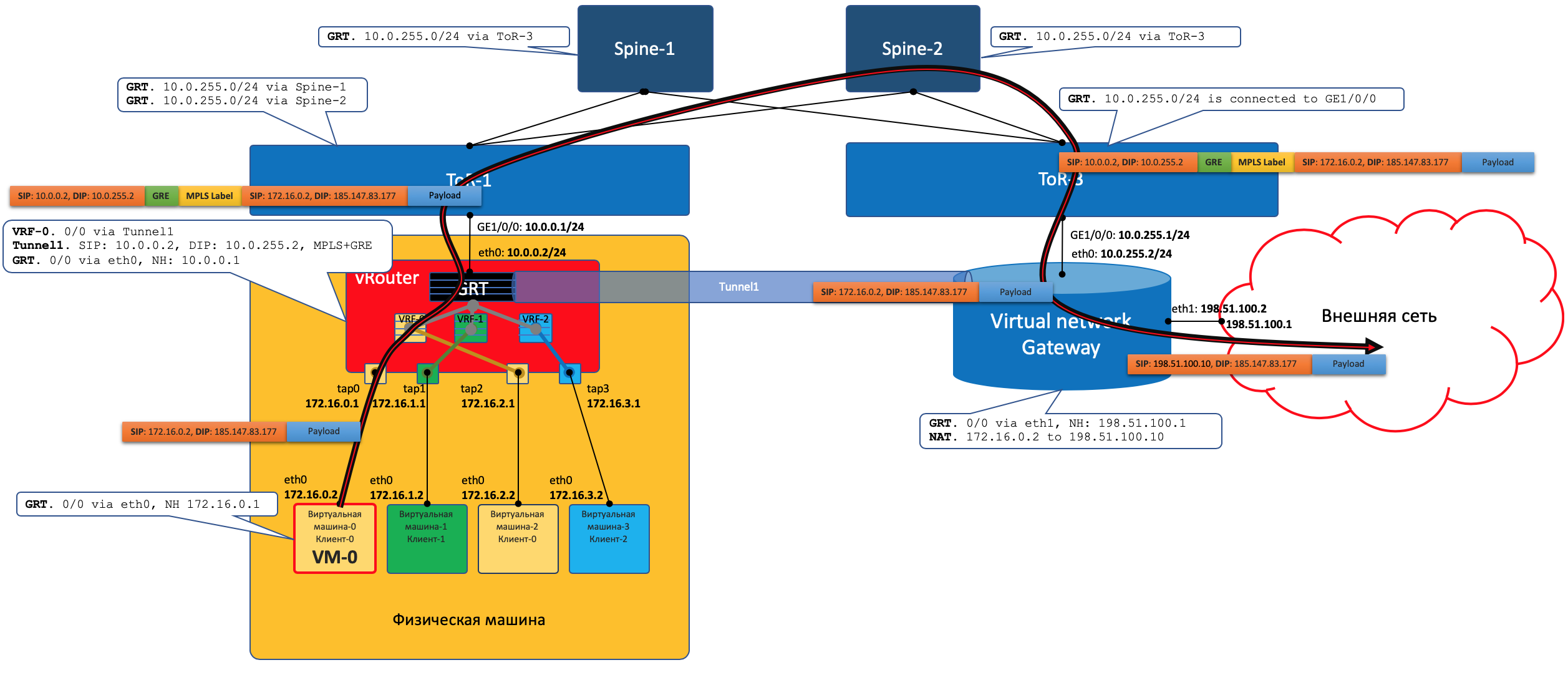
Трафик в обратную сторону проходит те же шаги в противоположном порядке.
- Бордер добрасывает пакет до VNGW1
- Тот его раздевает, смотрит на адрес получателя и видит, что тот доступен через туннель Tunnel1 (MPLSoGRE или MPLSoUDP).
- Соответственно, вешает метку MPLS, заголовок GRE/UDP и новый IP и отправляет на свой ToR3 10.0.255.1.
Адрес назначения туннеля — IP-адрес vRouter’а, за которым стоит целевая ВМ — 10.0.0.2. - Андерлейная сеть доставляет пакет до нужного vRouter’а.
- Целевой vRouter снимает GRE/UDP, по MPLS-метке определяет интерфейс и шлёт голый IP-пакет в свой TAP-интерфейс, связанный с eth0 ВМ.

Control Plane
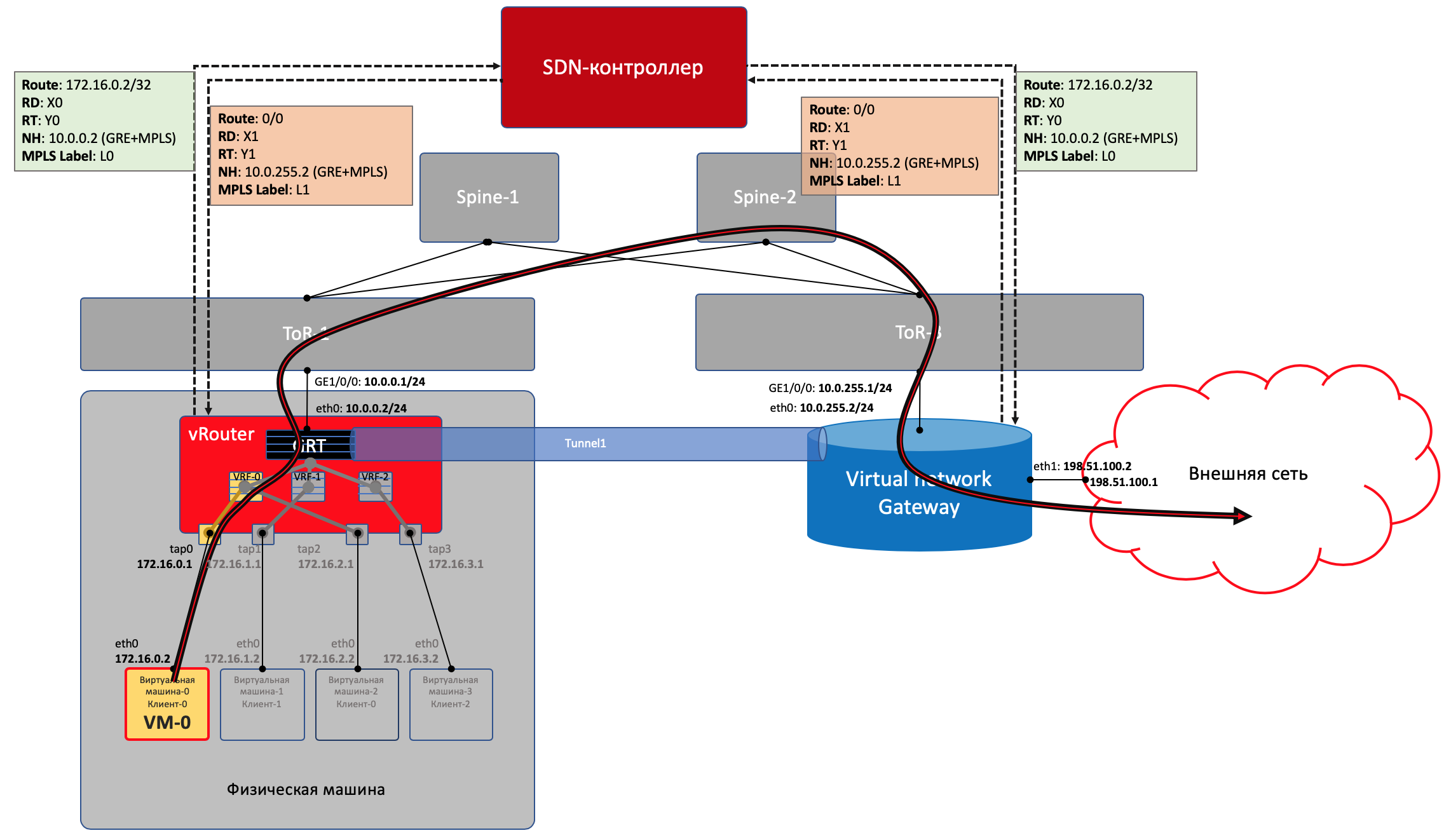
VNGW1 устанавливает BGP-соседство с SDN-контроллером, от которого он получает всю маршрутную информацию о клиентах: за каким IP-адресом (vRouter’ом) находится какой клиент, и какой MPLS-меткой он идентифицируется.
Аналогично он сам SDN-контроллеру сообщает дефолтный маршрут с меткой этого клиента, указывая себя в качестве nexthop’а. А дальше этот дефолт приезжает на vRouter’ы.
На VNGW обычно происходит агрегация маршрутов или NAT-трансляция.
И в другую сторону в сессию с бордерами или Route Reflector’ами он отдаёт именно этот агрегированный маршрут. А от них получает маршрут по умолчанию или Full-View, или что-то ещё.
В плане инкапсуляции и обмена трафиком VNGW ничем не отличается от vRouter.
Если немного расширить область, то к VNGW и vRouter’ам можно добавить другие сетевые устройства, такие как файрволы, фермы очистки или обогащения трафика, IPS итд.
И с помощью последовательного создания VRF и правильного анонса маршрутов, можно заставлять трафик петлять так, как вам хочется, что и называется Service Chaining’ом.
То есть и тут SDN-контроллер выступает в роли Route-Reflector’а между VNGW, vRouter’ами и другими сетевыми устройствами.
Но фактически контроллер спускает ещё информацию об ACL и PBR (Policy Based Routing), заставляя отдельные потоки трафика ходить не так, как им велит маршрут.
Зачем ты всё время делаешь ремарку GRE/UDP?
Ну, вообще, это, можно сказать, специфично для Tungsten Fabric — можно вообще не брать во-внимание.
Но если брать, то сам TF, ещё будучи OpenContrail’ом поддерживал обе инкапсуляции: MPLS in GRE и MPLS in UDP.
UDP хорош тем, что в Source Port в его заголовке очень легко закодировать хэш-функцию от изначальных IP+Proto+Port, что позволит делать балансировку.
В случае GRE, увы, есть только внешние заголовки IP и GRE, которые одинаковы для всего инкапсулированного трафика и речь о балансировке не идёт — мало кто может заглянуть так глубоко внутрь пакета.
До некоторого времени маршрутизаторы, если и умели в динамические туннели, то только в MPLSoGRE, и только совсем недавно, научились в MPLSoUDP. Поэтому приходится делать всегда ремарку о возможности двух разных инкапсуляций.
Справедливости ради, стоит отметить, что TF вполне поддерживает и L2-связность с помощью VXLAN.
Ты обещал провести параллели с OpenFlow.
Они и правда напрашиваются. vSwitch в том же OpenStack’е делает весьма похожие вещи, используя VXLAN, у которого, кстати, тоже UDP-заголовок.
В Data Plane они работают примерно одинаково, существенно различается Control Plane. Tungsten Fabric использует XMPP для доставки информации о маршрутах на vRouter, в то время, как в OpenStack’е работает Openflow.
А можно чуть больше про vRouter?
Он делится на две части: vRouter Agent и vRouter Forwarder.
Первый запускается в User Space хостовой ОС и общается с SDN-контроллером, обмениваясь информацией о маршрутах, VRF и ACL.
Второй реализует Data Plane — обычно в Kernel Space, но может запускаться и на SmartNIC’ах — сетевых картах с CPU и отдельным программируемым чипом коммутации, что позволяет снять нагрузку с CPU хостовой машины, а сеть сделать быстрее и более предсказуемой.
Ещё возможен сценарий, когда vRouter — это DPDK-приложение в User Space.
vRouter Agent спускает настройки на vRouter Forwarder.
Что за Virtual Network?
Я обмолвился в начале статьи о VRF, что мол каждый тенант привязывается к своему VRF. И если для поверхностного понимания работы оверлейной сети этого было достаточно, то уже на следующей итерации надо делать уточнения.
Обычно в механизмах виртуализации сущность Virtual Network (можно считать это именем собственным) вводится отдельно от клиентов/тенантов/виртуальных машин — вполне себе самостоятельная вещь. А этот Virtual Network через интерфейсы уже можно подключить в один тенант, в другой, в два, да хоть куда. Так, например, реализуется Service Chaining, когда трафик нужно пропустить через определённые ноды в нужной последовательности, просто в правильной последовательности создавая и привзявая Virtual Network’и.
Поэтому как такового прямого соответствия между Virtual Network и тенантом нет.
Это весьма поверхностное описание работы виртуальной сети с оверлеем с хоста и SDN-контроллером. Но какую бы платформу виртуализации вы сегодня ни взяли, работать она будет похожим образом, будь то VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric или Juniper Contrail. Они будут отличаться видами инкапсуляций и заголовков, протоколами доставки информации на конечные сетевые устройства, но принцип программно настраиваемой оверлейной сети, работающей поверх сравнительно простой и статичной андерлейной сети останется прежним.
Можно сказать, что области создания приватного облака на сегодняшний день SDN на основе оверлейной сети победил. Впрочем это не значит, что Openflow нет места в современном мире — он используется в OpenStacke и в той же VMWare NSX, его, насколько мне известно, использует Google для настройки андерлейной сети.
Чуть ниже я привёл ссылки на более подробные материалы, если хочется изучить вопрос глубже.
А что там наш Underlay?
А в общем-то ничего. Он всю дорогу не менялся. Всё, что ему нужно делать в случае оверлея с хоста — это обновлять маршруты и ARP’ы по мере появления и исчезновения vRouter/VNGW и таскать пакеты между ними.
Давайте сформулируем список требований к Underlay-сети.
- Уметь в какой-то протокол маршрутизации, в нашей ситуации — BGP.
- Иметь широкую полосу, желательно без переподписки, чтобы не терялись пакеты из-за перегрузок.
- Поддерживать ECMP — неотъемлемая часть фабрики.
- Уметь обеспечить QoS, в том числе хитрые штуки, вроде ECN.
- Поддерживать NETCONF — задел на будущее.
Работе самой Underlay-сети я посвятил здесь совсем мало времени. Это потому, что далее в серии я именно на ней и сосредоточусь, а Overlay мы будем затрагивать только вскользь.
Очевидно, я сильно ограничиваю нас всех, используя в качестве примера сеть ДЦ, построенную на фабрике Клоза с чистой IP-маршрутизацией и оверлеем с хоста.
Однако я уверен, что любую сеть, имеющую дизайн, можно описать в формальных терминах и автоматизировать. Просто я здесь преследую целью разобраться в подходах к автоматизации, а не запутать всех вообще, решая задачу в общем виде.
В рамках АДСМ мы с Романом Горге планируем опубликовать отдельный выпуск про виртуализацию вычислительных мощностей и её взаимодействие с виртуализацией сети. Оставайтесь на связи.
Спасибы
- Роману Горге — бывшему ведущему подкаста linkmeup, а ныне эксперту в области облачных платформ. За комментарии и правки. Ну и ждём в скором будущем его более глубокой статьи о виртуализации.
- Александру Шалимову — моему коллеге и эксперту в области разработки виртуальных сетей. За комментарии и правки.
- Валентину Синицыну — моему коллеге и эксперту в области Tungsten Fabric. За комментарии и правки.
- Артёму Чернобаю — иллюстратору linkmeup. За КДПВ.
- Александру Лимонову. За мем «automato».
