Автоматическое определение рубрики текста
Введение
В предыдущих статьях, посвященных организации данных в виде рубрикатора (Использование графа, как основы для создания рубрикатора и Проблемы, подстерегающие любого создателя рубрикаторов) были описаны общие идеи по организации рубрикатора. В этой статье я опишу один из возможных алгоритмов автоматического определения тематики текста на основе заранее подготовленного графа-рубрикатора. При этом я сознательно избегаю сложных формул, чтобы донести идею, лежащую в основе алгоритма, максимально просто.Подготовка данных рубрикатора
Для начала определимся с тем, в каком виде мы будем готовить данные для рубрикатора.1. Рубрикатор — это граф, а не дерево
2. Текст, тематика которого определяется, может быть отнесен к нескольким рубрикам одновременно
3. Для каждого соотнесения с рубрикой указывается коэффициент точности определения рубрики
4. Тематика текста определяется для каждого текста отдельно, и не зависит от того как были определены рубрики других текстов ранее
Последний пункт нуждается в небольшом пояснении. Независимость определения тематики текста очень хороша, когда не требуется последующая сортировка результатов. Когда тексты просто отнесены к рубрики или нет. Но при наличии в рубрике нескольких текстов, наверняка возникнет необходимость отсортировать их по критерию наилучшего попадания в рубрику. В данной статье этот вопрос опущен для ясности.Алгоритм определения тематики текста, кратко
Описываем рубрикатор. Извлекаем из исследуемого текста ключевые слова, описанные в рубрикаторе. В результате извлечения получаем кусочки разорванного и чаще всего несвязного графа. Используем волновой (или любой другой, по желанию) алгоритм для «дотягивания» извлеченных кусочков графа до вершины «всё». Анализируем и выводим результаты.Алгоритм определения тематики текста, подробно
Создание рубрикатора было подробно описано в предыдущих статьях. На данном этапе считаем, что у нас есть расчерченный граф-рубрикатор, в листовых элементах которого присутствуют ключевые слова, а в узловых-рубрики.Осуществляем поиск всего множества ключевых слов рубрикатора в исследуемом тексте. Так как слов, которые требуется найти может быть много, рекомендую для конкретной реализации обратиться в к алгоритмам быстрого поиска массивов строк в тексте. Для затравки приведу ссылки на наиболее популярные из них: Алгоритм Ахо — КорасикАлгоритм характеризуется довольно сложной логикой построения дерева и обработки «возвратов», существует множество примеров реализации. На хабре было хорошее описание этого алгоритма.Алгоритм Рабина — Карпа. Отличительная особенность алгоритма — эффективная работа с очень большими наборами слов.В принципе, почитав описания двух, предложенных выше, алгоритмов, не составляет труда придумать на их основе свою реализацию, способную учитывать какие-то дополнительные условия. Например, требование чувствительности к регистру текста, учёту морфологии и т.п.После того, как из исследуемого текста извлечены ключевые слова, используемые в описании рубрикатора, можно приступать непосредственно к определению тематики текста.Волна
В рубрикаторе присутствует вершина «всё». Так же присутствуют найденные в тексте ключевые слова. Цель данного этапа — найти путь от каждого, найденного ключевого слова для вершины «всё».Для ключевого слова «песок», путь к корню рубрикатора будет выглядеть следующим образом: 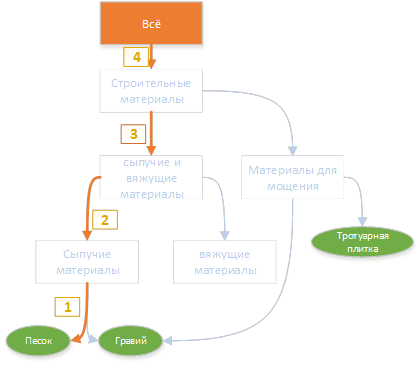 Аналогично строятся пути до вершины по всем, найденным на предыдущем шаге словам.
Аналогично строятся пути до вершины по всем, найденным на предыдущем шаге словам.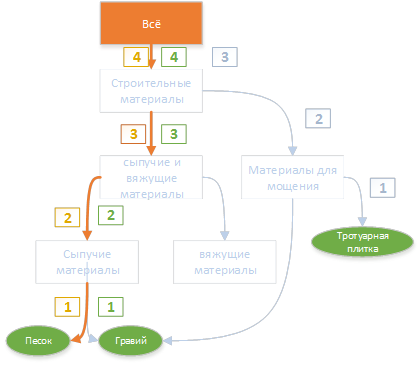 В результате такого построения для каждого ключевого слова находится путь до вершины.Определение тематики
Рассмотрим теперь, как было произведено автоматическое определение рубрики на примере статьи: «Как уложить тротуарную плитку?». Человек, даже не читая статью, может предположить, что речь будет идти о возможных способах кладки плитки и о сопутствующих материалах и технологиях.Проверим, как сработает автоматическое определение рубрики для этой статьи.Начнём, традиционно, с ключевых слов, найденных в статье и имеющих отображение в рубрикаторе.
В результате такого построения для каждого ключевого слова находится путь до вершины.Определение тематики
Рассмотрим теперь, как было произведено автоматическое определение рубрики на примере статьи: «Как уложить тротуарную плитку?». Человек, даже не читая статью, может предположить, что речь будет идти о возможных способах кладки плитки и о сопутствующих материалах и технологиях.Проверим, как сработает автоматическое определение рубрики для этой статьи.Начнём, традиционно, с ключевых слов, найденных в статье и имеющих отображение в рубрикаторе.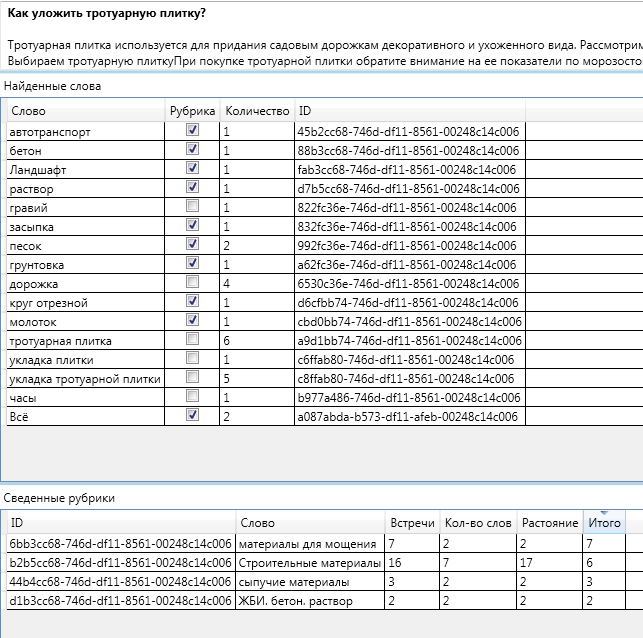 На рисунке, отметка «рубрика» означает, что данный элемент рубрикатора не является листовым. Это позволяет «совместить» название рубрики и описывающего её ключевого слова.Самое популярное слово в статье «Как уложить тротуарную плитку?» — это «тротуарная плитка», что и следовало ожидать.Ниже, часть рубрикатора, которая была задействована в примере:
На рисунке, отметка «рубрика» означает, что данный элемент рубрикатора не является листовым. Это позволяет «совместить» название рубрики и описывающего её ключевого слова.Самое популярное слово в статье «Как уложить тротуарную плитку?» — это «тротуарная плитка», что и следовало ожидать.Ниже, часть рубрикатора, которая была задействована в примере: 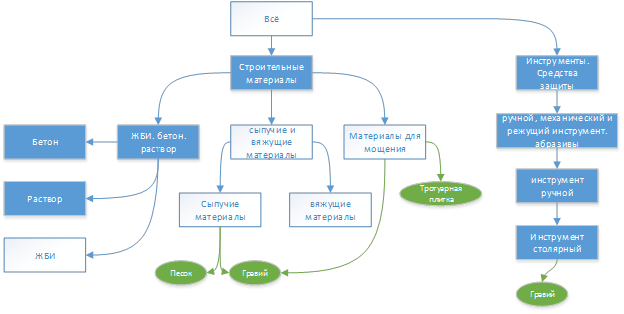 Для примера, показано что ключевое слово «гравий» отнесено к двум рубрикам, а ключевое слово «тротуарная плитка» только к одному. Так же светлым фоном выделены рубрики, названия которых в тексте не встречаются. (Помним, что ключевое слово и рубрика могут иметь одно и то же название. Подробности в предыдущих статьях)Теперь посмотрим на рубрики, к которым была отнесена статья:
Для примера, показано что ключевое слово «гравий» отнесено к двум рубрикам, а ключевое слово «тротуарная плитка» только к одному. Так же светлым фоном выделены рубрики, названия которых в тексте не встречаются. (Помним, что ключевое слово и рубрика могут иметь одно и то же название. Подробности в предыдущих статьях)Теперь посмотрим на рубрики, к которым была отнесена статья:  Первая рубрика, к которой отнесена данная статья — это рубрика «Материалы для мощения».На рисунке — выделенная строка — это рубрика с итогами и ниже табличка с данными по каждому слову.
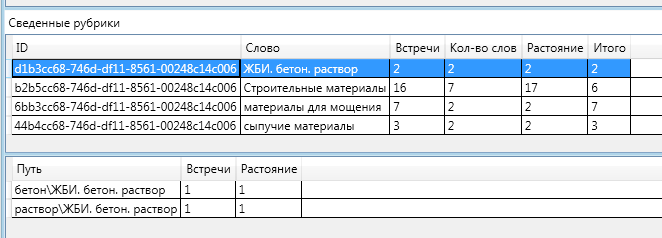
Первая рубрика, к которой отнесена данная статья — это рубрика «Материалы для мощения».На рисунке — выделенная строка — это рубрика с итогами и ниже табличка с данными по каждому слову.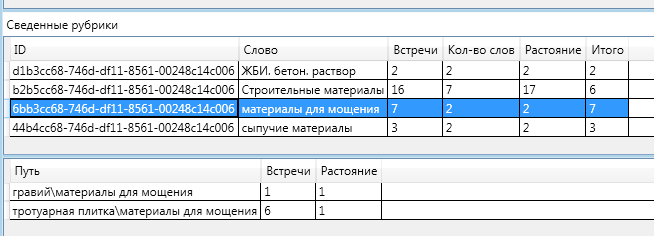 Итоговая оценка принадлежности к этой рубрике — 7. Это самая высокая оценка. Из этой рубрики в тексте встретилось 2 слова, 7 раз на суммарном расстоянии 2. Напомню, что расстоянием между двумя вершинами графа называется число рёбер в кратчайшем пути.
Итоговая оценка принадлежности к этой рубрике — 7. Это самая высокая оценка. Из этой рубрики в тексте встретилось 2 слова, 7 раз на суммарном расстоянии 2. Напомню, что расстоянием между двумя вершинами графа называется число рёбер в кратчайшем пути.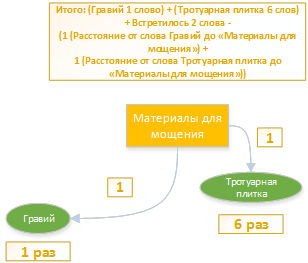 А именно, в тексте встретились ключевые слова «гравий» — один раз. И ключевое слово «тротуарная плитка» 6 раз. Оба этих слова являются дочерними по отношению к рубрике «материалы для мощения».Итого: (Гравий 1 слово) + (Тротуарная плитка 6 слов) + Встретилось 2 слова — (1 (Расстояние от слова Гравий до «Материалы для мощения») +1 (Расстояние от слова Тротуарная плитка до «Материалы для мощения»))Для полноты картины приведу схему сведения остальных рубрик:
А именно, в тексте встретились ключевые слова «гравий» — один раз. И ключевое слово «тротуарная плитка» 6 раз. Оба этих слова являются дочерними по отношению к рубрике «материалы для мощения».Итого: (Гравий 1 слово) + (Тротуарная плитка 6 слов) + Встретилось 2 слова — (1 (Расстояние от слова Гравий до «Материалы для мощения») +1 (Расстояние от слова Тротуарная плитка до «Материалы для мощения»))Для полноты картины приведу схему сведения остальных рубрик: 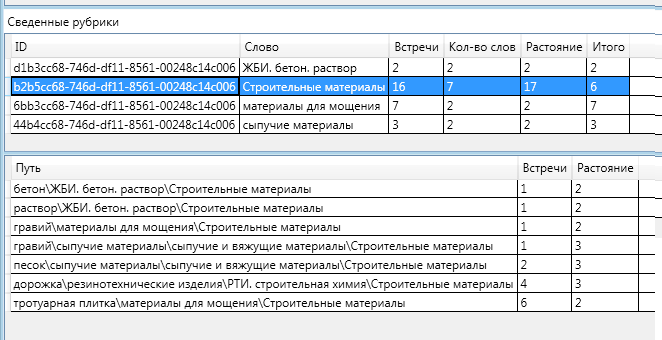
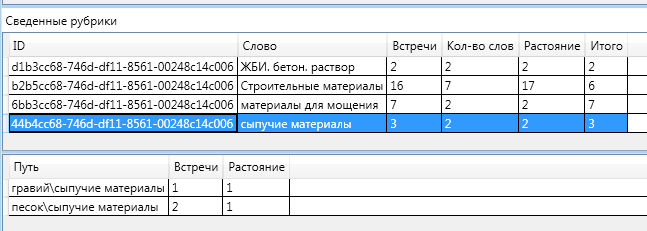
 Интересно отметить тот факт, что «на пути» к разделу «Строительные материалы» были две рубрики: «сыпучие материалы» и «сыпучие и вяжущие материалы». Одна из них попала в итоговое определение, а другая — нет.
Интересно отметить тот факт, что «на пути» к разделу «Строительные материалы» были две рубрики: «сыпучие материалы» и «сыпучие и вяжущие материалы». Одна из них попала в итоговое определение, а другая — нет.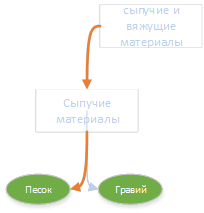 Песок и гравий вместе можно отнести к рубрике «Сыпучие материалы». «Сыпучие материалы» можно отнести к «Сыпучим и вяжущим материалам». Расстояние до более общей (верхней) рубрики больше чем расстояние до более конкретной (нижней) то по формуле вычисления релевантности «Итого» получается очень маленьким (вплоть до отрицательного.Формула
Формула для определения колонки «итого» в таблице выглядит следующим образом: Итого = «Встречи» + «Кол-во слов» — «Расстояние«Встречи — сколько всего раз были найдены ключевые слова.Количество слов — Сколько разных слов было найдено.Расстояние — суммарное расстояние от каждого слова до выбранной рубрики.И эта формула — далеко не фундаментальный постулат. И, наверняка, может быть улучшена, снабжена дополнительными элементами и т.п. (Предлагаю обсудить это в комментариях)Забегая в перед, хочу отметить, что при разработке данной системы мы специально старались избегать любых явно заданных коэффициентов, дабы не запутаться в премудростях тонкого тюнинга.Точки роста
По своей сути рубрикатор не может сразу быть составлен однородно. Наверняка, отдельные его разделу окажутся более проработанными, чем другие. Это может привести к «перекосу» графа и к увеличению расстояния от «листьев в вершине» в одной части и существенному уменьшению в другой. Этот дисбаланс может отрицательно влиять на «правильное» вычисление расстояния в графе. Здесь можно попытаться учесть количество дочерних элементов у каждого узла графа.
Песок и гравий вместе можно отнести к рубрике «Сыпучие материалы». «Сыпучие материалы» можно отнести к «Сыпучим и вяжущим материалам». Расстояние до более общей (верхней) рубрики больше чем расстояние до более конкретной (нижней) то по формуле вычисления релевантности «Итого» получается очень маленьким (вплоть до отрицательного.Формула
Формула для определения колонки «итого» в таблице выглядит следующим образом: Итого = «Встречи» + «Кол-во слов» — «Расстояние«Встречи — сколько всего раз были найдены ключевые слова.Количество слов — Сколько разных слов было найдено.Расстояние — суммарное расстояние от каждого слова до выбранной рубрики.И эта формула — далеко не фундаментальный постулат. И, наверняка, может быть улучшена, снабжена дополнительными элементами и т.п. (Предлагаю обсудить это в комментариях)Забегая в перед, хочу отметить, что при разработке данной системы мы специально старались избегать любых явно заданных коэффициентов, дабы не запутаться в премудростях тонкого тюнинга.Точки роста
По своей сути рубрикатор не может сразу быть составлен однородно. Наверняка, отдельные его разделу окажутся более проработанными, чем другие. Это может привести к «перекосу» графа и к увеличению расстояния от «листьев в вершине» в одной части и существенному уменьшению в другой. Этот дисбаланс может отрицательно влиять на «правильное» вычисление расстояния в графе. Здесь можно попытаться учесть количество дочерних элементов у каждого узла графа. Второй интересной идеей по оптимизации процесса определения тематики текста, является идея выборочного определения тематики для разных разделов текста с последующей композицией результатов.Идея основана на том, что, как правило в начале любой статьи существует раздел «введение» изобилующий самыми разными ключевыми словами, в последующих разделах идёт уточнение идеи статьи, что позволяет классифицировать каждую отдельную главу более достоверно.Как это делают другие
Интересно посмотреть, как выглядит тот же самый пример в других онлайн сервисах определения тематики.Сайт http://www.linkfeedator.ru/index.php? task=tematika даёт следующий результат:
Второй интересной идеей по оптимизации процесса определения тематики текста, является идея выборочного определения тематики для разных разделов текста с последующей композицией результатов.Идея основана на том, что, как правило в начале любой статьи существует раздел «введение» изобилующий самыми разными ключевыми словами, в последующих разделах идёт уточнение идеи статьи, что позволяет классифицировать каждую отдельную главу более достоверно.Как это делают другие
Интересно посмотреть, как выглядит тот же самый пример в других онлайн сервисах определения тематики.Сайт http://www.linkfeedator.ru/index.php? task=tematika даёт следующий результат:  Сайт: http://sm.ashmanov.com/demo/
Сайт: http://sm.ashmanov.com/demo/ Выводы
Тема автоматической категоризации-рубрикации текстов очень актуальна для поисковых системы, и систем обработки и извлечения знаний. Я надеюсь, что эта статья будет полезна не только тем, кто только начинает изучать технологии автоматической классификации, но и тем, кто съел на этом не одну собаку.Благодарности
Выражаю признательность тем, кто прочитал первые две статьи и поделился обратной связью, а также лично Андрею Бенькову за помощь в получении красивых таблиц с числами.
Выводы
Тема автоматической категоризации-рубрикации текстов очень актуальна для поисковых системы, и систем обработки и извлечения знаний. Я надеюсь, что эта статья будет полезна не только тем, кто только начинает изучать технологии автоматической классификации, но и тем, кто съел на этом не одну собаку.Благодарности
Выражаю признательность тем, кто прочитал первые две статьи и поделился обратной связью, а также лично Андрею Бенькову за помощь в получении красивых таблиц с числами.
