Автоматический майнинг изображений
В предыдущих статьях мы рассказали, как создать фотогалерею с собственной поисковой системой [1,2]1. Но где нам найти изображения для нашей галереи? Нам придется вручную искать источники «хороших» изображений, а затем вручную проверять, является ли каждое изображение «хорошим». Можно ли автоматизировать обе эти задачи? Ответ — да.
Источник данных
Reddit — это социальная сеть с чертами форума и агрегатора ссылок. Входит в топ 20 самых посещаемых сайтов в мире по версии SimilarWeb. Самые важные его особенности: много оригинального контента, его генерируют и курируют пользователи, а самое главное, контент легко парсить, для этого есть API и сайт индексируется поисковиками.
Данные сайта уже давно используются для составления различных датасетов для машинного обучения. Лавочку скоро закроют, но пока еще есть возможность бесплатно получать доступ к огромному количеству информации, хоть это и стало гораздо сложнее. Раньше, для обхода различных лимитов использовался Pushshift. Pushshift это проект по парсингу Reddit, который предоставлял API и расширенный поиск (с помощью Elastic Search) бесплатно и без ограничений. К сожалению Reddit забанил его за нарушение правил использования сервисом.
Придется искать какие‑то обходные пути. В Reddit API есть вот такой запрос:
https://www.reddit.com/r/{subreddit_name}/new.json?sort=new&limit=100который позволяет получить до 100 последних сообщений с определенного сабреддита. По разным оценкам на Reddit от 130к до 3 млн сабреддитов. Сделать столько запросов нам никто не даст, поэтому будем искать дальше. Существует автоматический сабреддит — /r/all, в который автоматически добавляются посты со всего Reddit, вот оттуда мы и будем выкачивать картинки.
Outlier detection
Дальше нам надо определить, является ли изображение подходящим. У меня было 10к изображений, которые лежали в прошлой версии фотогалереи, их всех можно считать хорошими. В этом нам помогут методы для детекции аномалий. Эти алгоритмы работают с векторами — признаками объектов, поэтому из изображения нужно извлечь признаки. Для это мы используем CLIP ViT B/16, т.к мы уже использовали эту модель для поиска похожих изображений.
У нас нет примеров «плохих» изображений, поэтому используем методы, где разметка не требуется — Unsupervised Anomaly Detection.
Существует отличная библиотека в которой имплементировано много современных алгоритмов для детекции аномалий — PyOD. Разработчики этой библиотеки недавно выпустили статью, где протестировали 30 алгоритмов на разных датасетах.
Результат:
None of the unsupervised methods is statistically better than the others
Так как Unsupervised методы ± равны, я решил использовать наиболее быстрый и документированный. Выбор пал на Gaussian Mixture Models.
Gaussian Mixture Models
Используем имплементацию из scikit-learn. Для того чтобы выбрать n_components, нужно воспользоваться либо каким то априорным знанием о распределении (например, вы точно знаете, что там 3 кластера, тогда используете n_components=3), либо использовать информационные критерии, такие как AIC и BIC. Выбираем такое n_components, которое минимизирует AIC или BIC.

Тест описанный выше предложил количество компонент равное 24, но путем тестов я остановился на значении 16.
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components = 16, covariance_type = 'full')
gmm.fit(features)После этого, мы можем оценить log-likelihood каждого изображения
gmm.score_samples(features)Гистограмма тренировачного датасета, ось x — gmm score.
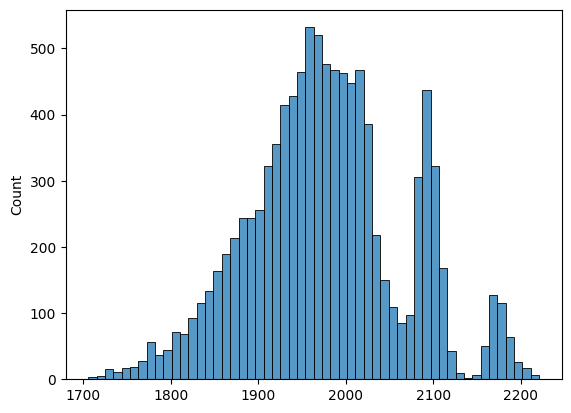
А вот гистограмма датасета, который я фильтровал (/r/EarthPorn). Оценки обрезаны на 0 и -3000 для лучшей наглядности.
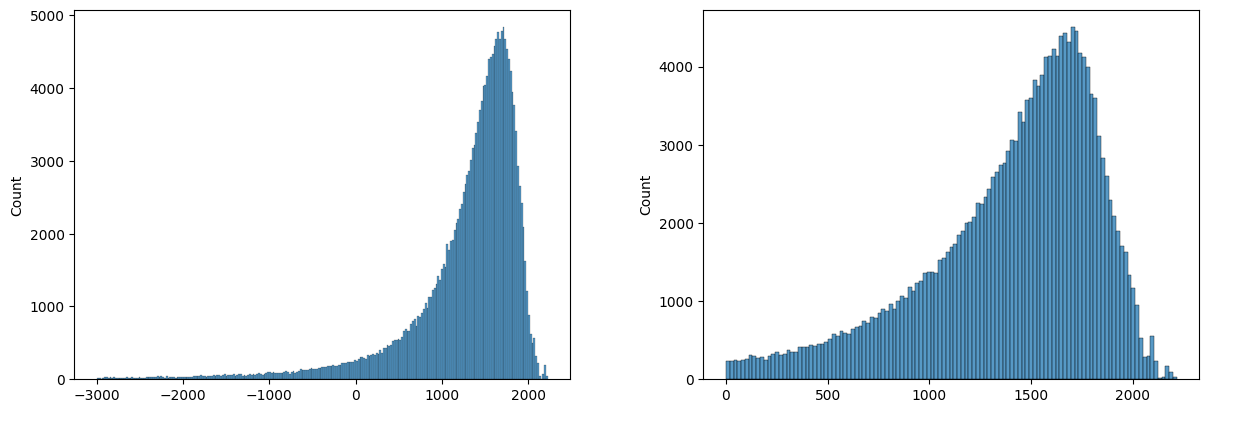
Теперь нужно выбрать threshold, по которму будем считать, подходит нам изображение или нет. Путем тестов я выяснил, что score>500 это уже хорошее изображение.
Watermark detection
К сожалению, присутствие вотермарок не сильно влияет на gmm score. Поэтому я натренировал бинарный классификатор (нет вотермарки/есть вотермарка) и также разметил датасет на 22к изображений. Датасет можно найти здесь и здесь. Интересный факт, недавно обнаружил что 3–5 индусов полностью скопировали мой датасет и выложили на Kaggle, как свой, не указав где они его взяли. Один даже был в топ 18 по миру в лидербордах по датасетам. На удивление кнопка report действительно работает и через пару дней скопированные датасеты были снесены.
CLIP
Первоначально, я посчитал неплохой идеей использовать те же фичи, что мы использовали для обнаружения аномалий. Эти признаки мы подаем в простую 3 слойную полносвязную сеть, accuracy составил 93–95 процентов и наверное можно было бы на этом и закончить. Но я хотел добиться как можно меньшего показателя ложноотрицательных срабатываний. Я заметил, что при сжатии изображения до 224×224 часть вотермарок полностью исчезает, поэтому я решил попробовать сделать вот так:
Сжать изображение до 448×448
Получить признаки каждого из квадрантов (224×224) изображения
Сконкатенировать их
Подать новый вектор в полносвязную сеть
Новая точность составила 97–98% и ложноотрицательных срабатываний стало гораздо меньше, успех!
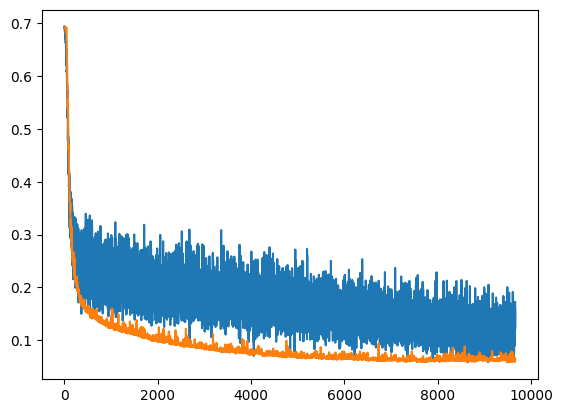
Оранжевный — test loss, синий — train loss
Также при обучении были использованы различные аугментации, такие как повороты, блюры, артефакты JPEG компрессии. Кропы не использовались, т.к мы точно не знаем в какой части изображения может быть вотермарка.
EfficientNetV2 и onnx
Так как CLIP на GPU занимает около 2 гб VRAM, а мой сервер (headless комп, который стоит на шкафу) используется не только для этого проекта, появилось желание вычислять все на CPU, используя поменьше RAM.
С помощью torch.onnx я сконвертировал visual часть модели (в CLIP есть две подсети, одна обрабатывает текст, а другая изображения) в формат onnx, а затем, чтобы полностью избавиться от torch, переписал на numpy некоторые функции, ответственные за нормализацию изображений.
Использование RAM после прогрева (visual+textual CLIP):
Фреймворк | RAM (MB) |
cpu pytorch | 1194 |
cpu onnxruntime | 748 |
Окей, памяти теперь требуется меньше, но что делать с производительностью? Вычислять признаки 4 раза для 1 изображения это как‑то расточительно, нужна отдельная модель.
Одни из самых эффективных по Parameters/FLOPs это модели семейства EfficientNet.
В 2021 вышел сиквел — EfficientNetV2, попробуем использовать самую маленькую — EfficientNetV2-B0. Имплементацию и веса возьмем из timm.
Gotta go fast
Тренируем все слои, используем изображения размером 512×512. Так сможем увидеть еще больше маленьких вотермарок. Результаты незначительно лучше, чем с CLIP.
EfficientNetV2-B0 можно найти в гитхаб репозитории и на hugging face.
anti_sus
[Github]
anti_sus это zeromq сервер для фильтрации изображений. На вход принимает batch rgb изображений (numpy массив) и вовзращает индексы хороших изображений. Он имеет 2-ступенчатую фильтрацию:
В будущем я хотел бы добавить модели, которые могут оценивать качество изображения (Image Quality Assessment, IQA) и определять, является ли изображение синтетическим, то есть сгенерированным с помощью GAN или диффузионных моделей.
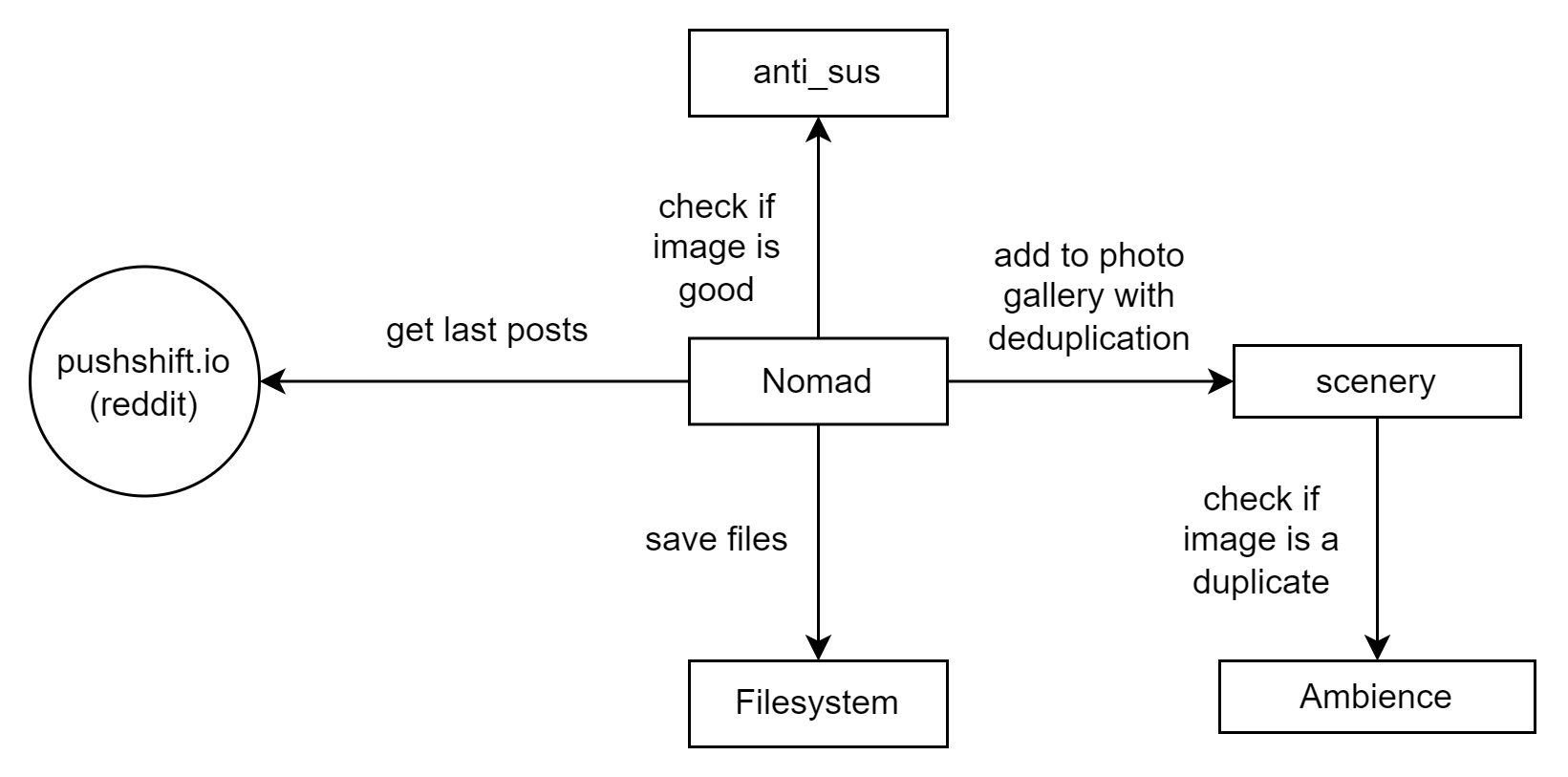
nomad
[Github]
nomad это парсер reddit, в котором прописаны различные правила, для получения изображений наилучшего качества с reddit, а также из ссылок на imgur и flickr. Поддерживет работу с anti_sus и scenery (фотогалерея).
Результаты
Примерно 154 изображения за ~14 часов, threshold == 700 (с учетом различных sleep () для уменьшения вероятности бана ip)
Интеграция с фотогалереей (scenery)
Комбинацию nomad+anti_sus можно использовать двумя различными способами: мы можем использовать ее как автономный инструмент и просто сохранять новые изображения в файловой системе, или мы можем интегрировать ее с scenery. Таким образом, новые изображения будут автоматически добавляться в нашу фотогалерею, и мы сможем использовать ambience, чтобы проверить, является ли изображение дубликатом.
Сейчас https://scenery.cx/ имеет 160к картинок, из них ~158к это отфильтрованный /r/EarthPorn.
nomad+anti_sus работают и автоматически добавляют новые изображения.
1 Более новую версию статьи про поиск изображений можно найти тут (eng.)
