Автоматически генерируем стикеры для Телеграма из фото плакатов в интернет-магазине
Всем привет!
В этой статье я расскажу, как я автоматически генерировал 42 стикера для Телеграма на основе изображений из интернет-магазина плакатов. На сайте продаются плакаты с разными забавными надписями, но соответствующих стикеров в Телеграме нет. Попробуем сделать сами. Единственная проблема состоит в следующем: чтобы сделать один стикер, нужно скачать фотографию плаката с сайта, отделить надпись от фона в фотошопе и сохранить в нужном разрешении, чтобы она соответствовала требованиям телеграма к стикерам. Поскольку изображений 42, это муторное и трудоемкое занятие. Давайте автоматизируем.
Итак, план таков:
Парсим фотографии с сайта интернет-магазина.
Отделяем текст от фона и убираем тени, делаем фото похожим на скан.
Подгоняем размер изображения под требования к стикерам, добавляем прозрачные пиксели.
Парсим фото с сайта
Первым делом, заведем список urls, который будет содержать ссылки на страницу с каждым конкретным плакатом. Это нужно, чтобы скачать хайрезы, ведь в общей галерее плакатов картинки в маленьком разрешении. Так что смотрим, куда ведут ссылки с каждой картинки в галерее.
import requests
from bs4 import BeautifulSoup
import urllib.request
url = 'https://demonpress.ecwid.com/%D0%9F%D0%BB%D0%B0%D0%BA%D0%B0%D1%82%D1%8B-c26701164'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
text = requests.get(url, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
urls = []
for i in soup.find_all('a', attrs = {"class": "grid-product__image"}):
urls += [i['href']]В галерее плакаты представлены по 15 штук, так что далее пробегаемся по страницам 2, 3 и 4.
 На сайте 4 страницы с плакатами. Чтобы спарсить все ссылки, придется зайти на каждую страницу.
На сайте 4 страницы с плакатами. Чтобы спарсить все ссылки, придется зайти на каждую страницу.
Для перехода на эти страницы достаточно добавить к адресу ? offset=15 или 30 или 45, в зависимости от того, на какую страницу хотим попасть. Это позволяет спарсить остальные ссылки.
for i in ['15','30','45']:
url_next = url + '?offset=' + i
text = requests.get(url_next, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
for i in soup.find_all('a', attrs = {"class": "grid-product__image"}):
urls += [i['href']]Теперь дело за малым, пройти по всем ссылкам из списка urls и скачать картинку из карточки товара.
for url in urls:
text = requests.get(url, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
for j in soup.find_all('img', {'class':'details-gallery__picture details-gallery__photoswipe-index-0'}):
urllib.request.urlretrieve(j['src'], j['title'].replace('/','').replace('*','').replace('?','')+'.jpg')Картинки для понятности будем называть фразами с этих плакатов, для этого убираем из названий символы »/»,»?» и »*».
Коррекция изображений
К сожалению, на сайте используются фотографии плакатов, а не сканы, так что использовать их сразу не получится. Картинки на сайте выглядят вот так:
На фото свет направлен снизу справа. Из-за этого верхняя левая часть в тени.
Свет падает сбоку, из-за этого на картинке появляется некрасивая тень. Сами буквы могут быть темнее в затененных частях изображения. Более того, из-за этого для отделения букв от фона не получится воспользоваться порогом по яркости. Буквы в светлых частях изображения могут быть светлее, чем фон в темных его частях.
Для исправления ситуации воспользуемся тем фактом, что все плакаты представляют собой красные буквы на белом фоне. Поскольку каждый пиксель — это вектор из трех чисел, можно посчитать стандартное отклонение его компонент. Если пиксель серый — стандартное отклонение будет маленьким независимо от того, темный пиксель или светлый. Если пиксель красный — стандартное отклонение будет большим, поскольку имеется доминирующая компонента. Экспериментальным путем было установлено, что хорошим пороговым значением отклонения будет 30.
Далее просто заменяем все пиксели фона на (245, 245, 245), а пиксели букв на (200, 17, 11). Фон не совсем белый, но так смотрится лучше, поскольку в реальной жизни идеально белой бумаги не бывает, а нам надо имитировать плакат.
def remove_bg(input_img: np.ndarray) -> np.ndarray:
img = input_img.copy()
for i in range(0, img.shape[0]):
for j in range(0, img.shape[1]):
if img[i][j].std() < 30:
img[i][j][0] = 245
img[i][j][1] = 245
img[i][j][2] = 245
else:
img[i][j][0] = 200
img[i][j][1] = 17
img[i][j][2] = 11
return imgНа выходе имеет такой результат:
Стало гораздо лучше
Остался последний шаг. Телеграм требует, чтобы стикеры были в формате png c разрешением 512×512. Наши картинки не квадратные, поэтому их придется дополнить прозрачными пикселями справа.
Для этого воспользуемся библиотекой PIL.
from PIL import Image
def transp_bg_and_resize(input_img: np.ndarray) -> np.ndarray:
# Меняем размер
img = input_img.copy()
a = 512/img.shape[0]
x = int(img.shape[0]*a)
y = int(img.shape[1]*a)
img = resize(img, (x, y))
# Вставляем на прозрачный фон
blank = Image.new("RGBA",(512,512), (0,0,0,0))
img = Image.fromarray((img * 255).astype(np.uint8))
blank.paste(img, (0,0))
return blankНа выходе получаем изображение 512×512 пикселей. Его можно использовать в качестве стикера.
Осталось проделать описанное выше для всех картинок и готово.
files = []
for i in os.listdir('.'):
if i[-4::] == '.jpg':
files += [i]
for file in files:
img = mpimg.imread(file).copy()
img = remove_bg(img)
img = transp_bg_and_resize(img)
img.save(f'result/{file[0:-4]}', 'png')
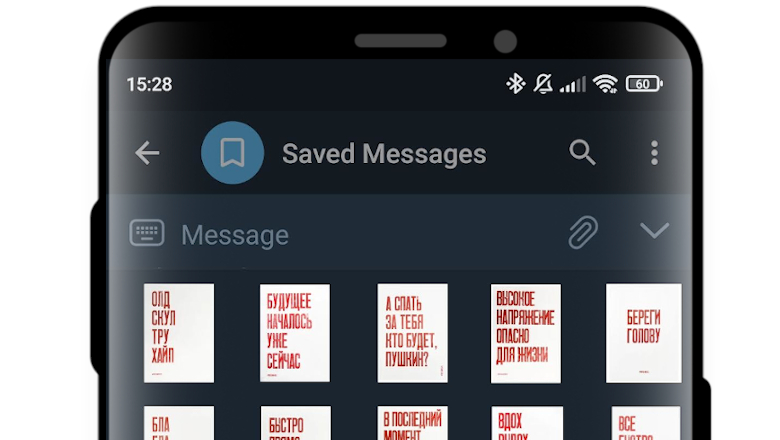
print('Done!')Получилось вот так:
Ссылка на репозиторий с кодом
