AutoML на практике — как делать автоматизацию, а не её иллюзию
Привет, Хабр! Меня зовут Алексей Рязанцев, я Junior Data Scientist в Лаборатории Машинного обучения Альфа-Банка. Свой путь в Лаборатории я начал со стажировки летом-осенью 2023-го года, на которой для меня была интересная задача — разработать с нуля собственный AutoML в Альфа-Банке.
Когда количество ML-моделей в компании исчисляется сотнями, процессы — десятками, а фичи — тысячами, вопрос «а нужен ли нам AutoML?» уже не стоит. Стоит другой вопрос: как сделать AutoML так, чтобы он был действительно полезен и им реально хотелось пользоваться?
В этом посте я подробно освещу путь создания нашего AutoML-сервиса: расскажу обо всех препятствиях, которые мы преодолели, и поделюсь инсайтами, полученными в ходе работы. Вместе мы пройдем полный путь практического AutoML, начиная от его первоначальной идеи и мотивации, и заканчивая текущими успехами и планами на будущее.
Рутина в Data Science и как её победить
В Альфа-Банке с каждым днём неуклонно увеличивается объём данных. Это как постоянное накапливание исторических данных, так и внедрение полностью новых источников и фичей. Такой рост даёт нам возможность расширять покрытие задач и процессов машинным обучением, а также улучшает точность уже имеющихся моделей.
Работа рядового Data Scientist«a в банке обычно складывается из трёх основных компонентов:
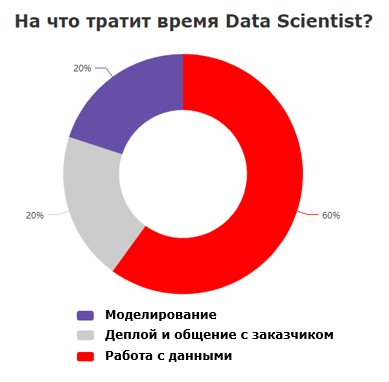
Вопреки ожиданиям, большую часть времени Data Scientist тратит не на построение сложных моделей, а на работу с данными. Причем часто это не самый захватывающий процесс. Необходимо найти данные, разобраться в документации, выгрузить их, привести к нужному виду и так далее. Этот процесс требует значительного погружения от Data Scientist«а. В такой ситуации кажется, что единственный компонент, который можно адекватно автоматизировать, это построение моделей.
Однако с появлением системы Feature Store в Альфа-Банке ситуация изменилась. Feature Store представляет собой платформу с веб-интерфейсом, в которую складываются все исследованные источники и фичи и хранятся там.
Теперь Data Scientist’ы часто обращаются к извлечению данных исключительно из Feature Store, так как в нём содержится достаточно информации для решения большинства задач. Это приводит к изменению процентного соотношения в диаграмме о затраченном времени:
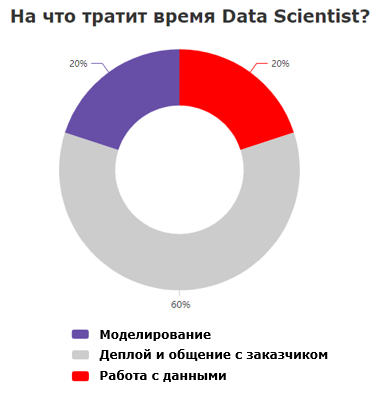
Так выглядит диаграмма здорового DS«a, работающего в компании, в которой хорошо развит Data Science. Теперь зачастую работа с данными ограничивается только сбором выборки клиентов и анализом уже имеющихся источников.
Сама концепция автоматического моделирования известна уже давно. Существуют как ряд открытых библиотек, так и множество коммерческих решений от разных компаний.
AutoML от других компаний:
Такой подход частично унифицирует процесс построения моделей, но не решает проблему того, что вся разработка ведётся в ноутбуках, а это не освобождает Data Scientist«a от постоянного копирования, использования костылей для дописывания кода и многих других рутинных задач.
Учитывая наличие удобных инструментов для работы с данными и опыт других компаний в использовании AutoML, мы пришли к мысли о необходимости создания централизованного инструмента моделирования. Такой инструмент поможет быстро решать рядовые задачи, экономя время Data Scientist«ов и позволяя им сфокусироваться на исследовании новых процессов. Также, он может значительно оптимизировать и другие процессы, не ограничиваясь лишь ролью построения базовой модели. Например, может ускорить для пользователя анализ имеющихся в Feature Store данных с помощью авто-аналитики, а также автоматизировать процесс создания сильных моделей — ансамблей.
Проблемы существующих AutoML
Существует множество AutoML-библиотек с открытым исходным кодом, каждая из которых обладает своими достоинствами и недостатками. Разработчики каждого инструмента ставили разные цели и руководствовались различными принципами. Но несмотря на широкий выбор доступных решений AutoML, на практике их применение остаётся относительно редким явлением. Почему? Есть несколько причин.
№1. Форм-фактор библиотеки не решает проблем реальной разработки.
Даже если библиотека предоставляет возможность автоматического моделирования в сыром виде, обычно требуется написание дополнительного кода и оболочки вокруг неё.
Типичный процесс разработки с библиотеками AutoML:
* 200 строчек загрузки данных, предобработки, EDA...*
#catboost.fit_predict(X, y)
automl.fit_predict(X, y) # Автоматизация!!
* 300 строчек графиков, предсказания, отбор фичей... *Это приводит к созданию громоздких ноутбуков, где Data Scientist в каждом проекте в очередной раз «на коленке» дополняет свой собственный код, изобретая велосипед. Такой подход увеличивает риск ошибок и запутанности в коде, а также, безусловно, отнимает много времени.

№2. Во всех открытых библиотеках на текущий момент есть ряд слабых мест.
Этот ряд начинается с крупных проблем, таких как отсутствие нужных моделей или низкая интерпретируемость итогового решения, и заканчивается мелочами по типу забытых гиперпараметров или банально неудобных интерфейсов использования.
№3. AutoML решения обладают низкой степенью доверия из-за плохой документации и непрозрачных процессов.
Многие библиотеки строят дико сложные ансамбли разных моделей, что делает их непригодными для использования в реальных процессах.
В нашем случае мы стремились к созданию инструмента, который не только удобен в использовании, но и реально улучшает процесс разработки и влияет на результаты бизнеса. Необходимость сервиса AutoML была очевидной.
Но как сделать его максимально эффективным и полезным? Нам нужен был инструмент, которым захотят пользоваться внутри банка, инструмент, который поможет выигрывать время, а не тратить его ещё больше на то, чтобы разобраться в принципе работы. Именно из этого стремления выросла идея создания своего AutoML в Альфе — не только библиотеки, а полноценного сервиса автоматического моделирования «от и до».
Конечно, такие сервисы тяжело делать в одиночку. Мы успешно внедряем наши решения по автоматизации процессов Data Science небольшой сплоченной командой. AutoML — это уже второй наш сервис, о котором мы рассказываем. Ранее мы презентовали сервис ANNA, предназначенный для автоматического построения нейронных сетей на последовательных данных. Решения, построенные с помощью ANNA, уже используются в реальных задачах бизнеса.
Можно сказать, что ANNA протоптала дорожку для AutoML — благодаря нашему опыту в создании сервисов автоматизации и ранее проработанных пайплайнов и бэкенда, разработка AutoML существенно упростилась. В данной статье мы сосредоточимся преимущественно на модельной части, оставив в стороне аспекты, связанные с сервисной частью, о которых можно будет подробнее прочитать в статье об ANNA.
Каким мы бы хотели видеть наш AutoML?
Конечно, прежде чем приступать к разработке, в первую очередь необходимо определиться с тем, как будет выглядеть конечный продукт и какие задачи он будет решать.
Из-за огромной вариативности задач попытка автоматизировать 100% процессов построения моделей в ML будет провальна.
Необходимо выбрать разумные пределы, найти такую точку баланса, которая позволит автоматизировать наибольшее число реальных кейсов за наименьшие усилия.
Найти эту точку баланса можно, определив на чём мы хотим сфокусироваться:
На табличных данных. Их в банке много, при этом всё необходимое уже лежит в одном месте, в Feature Store. Для нетабличных данных у нас есть ANNA.
На основных типах ML-задач. Регрессия, бинарная и многоклассовая классификация, uplift-моделирование — эти задачи встречаются чаще всего и покрывают 90% стандартных случаев.
На минимизации временных затрат. Самый дорогой ресурс — человеческий. Поэтому основная цель — упростить процесс создания моделей. В AutoML должны быть зафиксированы все конфигурации, необходимые для успешного самостоятельного построения модели с минимальным вмешательством человека.
На понятности и прозрачности. Важно, чтобы результатом работы AutoML-сервиса был не черный ящик. При этом интерпретируемыми должны быть как сами модели, так и процесс их построения — понимание, почему мы пришли именно к такому решению, к таким моделям и параметрам.
На автодеплой. Нам требовался инструмент, автоматически строящий модели, которые работают не только «на бумаге», но и могут быть быстро выведены в прод посредством процессов, уже существующих в нашем банковском контуре.
AutoML пайплайн — как делать быстро, качественно и устойчиво
Теперь предлагаю немного подробнее рассмотреть наш AutoML с технической стороны. Так выглядит упрощённая схема процессов, происходящих в нашем сервисе:
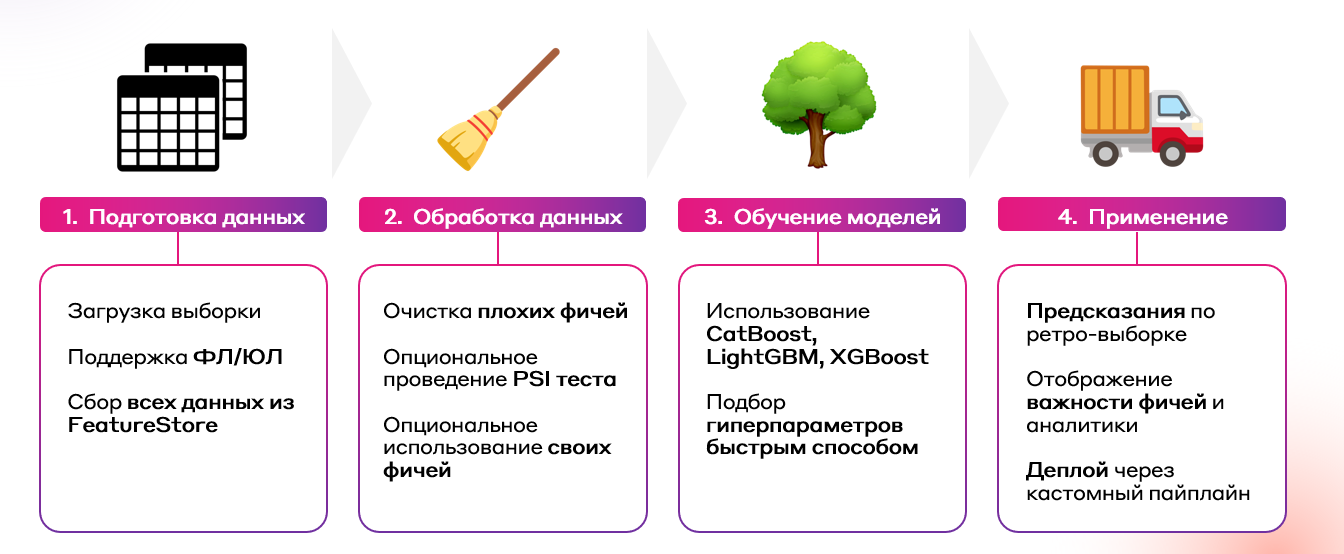
Рассмотрим каждый этап более детально.
Этап 1. Сбор данных
Пользователь загружает выборку в сервис, предварительно приведя её к простым требованиям сервиса: правильные названия колонок и типы данных.
Наш сервис поддерживает как физлиц, так и юрлиц. И в зависимости от того, кто содержится в выборке, будут собраны соответствующие витрины из Feature Store. Весь процесс сбора данных на PySpark занимает от 2 до 7 часов, в зависимости от размера выборки.
В результате для рядовой задачи получаем табличку из нескольких миллионов строк (клиентов) и более 2000 фичей из 15–20 разных источников. Конечно, в таком большом наборе неизбежно содержатся малополезные признаки, которые занимают место в памяти, и тащить их всюду с собой не хочется. Именно поэтому следующий этап — обработка и отбор данных.
Этап 2. Предобработка и предварительный отбор фичей
У нас есть огромный датафрейм, который нужно считывать в оперативную память для дальнейшего обучения моделей. AutoML как сервис должен иметь возможность строить модели для множества пользователей одновременно. Поэтому, во избежание очередей на кластере, необходимо потреблять как можно меньше ресурсов. Предварительно на PySpark мы делаем следующие шаги для снижения размера нашего датасета:
Все данные мы берём из Feature Store — платформы, в которой собрано и поддерживается большое количество витрин с фичами, собирающимися из разных источников под самые разные задачи. Все эти признаки рассчитаны с некоторой ретро-историей, а также они периодически по расписанию обновляются, актуализируя информацию на текущую дату.
Наши источники данных, к сожалению, пока что не идеальны: в них есть «плохие фичи», далеко не у всех витрин есть документация, ретро-данные нужной глубины и т.д.

Поэтому, собрав экспертизу у коллег из других команд, формируем список колонок, которые удаляем всегда. Такой список содержит фичи с различными идентификаторами, датами, а также фичи, которые едут по времени или рассчитываются некорректно.
Далее удаляем фичи с большим количеством пропусков —> Х% незаполненных значений (Х — пользовательский параметр, значение по умолчанию — 95%). Зачастую это или редкие и маловажные относительно задачи признаки, или признаки с недостаточной глубиной ретро-данных для текущей выборки. Их удаление исключает аномалии расчета данных и сокращает общее количество фичей с 2000 до ~800.
Убираем задублированные признаки (с корреляцией > 99%). Неожиданно, но таких в нашем Feature Store оказалось очень мало. Это показывает, что коллеги хорошо знают, какие данные уже есть, и не изобретают велосипед.
Кодируем категориальные признаки при помощи Target-энкодера. Конечно, их можно было бы подавать как категориальные в сами бустинги, но это имеет свойство существенно замедлять их работу, тем более, что под капотом они все равно делают примерно то же самое (см. Catboost).
Опционально проводим PSI тест и выкидываем нестабильные во времени фичи.
Отбираем топ-500 признаков при помощи RandomForest на PySpark. Даже одна итерация обучения случайного леса на дефолтных параметрах позволяет значительно снизить количество признаков. Наши эксперименты подтвердили, что наличие этого этапа также не влияет на итоговое качество.
Применяем квантизацию и преобразование числовых типов фичей, которые, по нашему опыту, практически не влияют на результаты обучения (бустинги под капотом их и так сделают).
Этап 3. Обучение моделей
Прежде чем говорить о процессе обучения, необходимо отметить, что наш сервис поддерживает все основные имплементации бустингов: CatBoost, LightGBM, XGBoost.
Рассмотрим, как у нас реализовано обучение модели и подбор гиперпараметров в общем случае:
№1. Для подбора гиперпараметров используем стандартную Optuna.
Но мы хотим немного ускорить время достижения оптимального набора. Для этого во время разработки мы зафиксировали для каждого поддерживаемого нашим сервисом бустинга несколько хороших наборов гиперпараметров «по умолчанию», которые ранее хорошо себя показали на разные задачах и размерах выборок. Именно с этих «экспертных конфигураций» мы и начинаем перебор, используя метод optuna.enqueue_trial. Такая техника позволяет прийти к оптимальному набору за существенно меньшее количество попыток
№2. Для более стабильной работы моделей даже сами подборы важно делать аккуратно (ведь мы каждый раз «заглядываем» в валидацию).
Сетки перебора для каждого типа модели у нас настроены дискретно для большей интерпретируемости процесса. Для части параметров мы выставляем возможные диапазоны особенно аккуратно во избежание краевых случаев.
№3. Также диапазоны значений подбираемых параметров (количество итераций, глубина деревьев, subsample) зависят от:
Размера выборки. Мы делим выборки на маленькие (< 7 млн сэмплов) и большие. Кроме того, что такой подход позволяет экономить время (ставить на огромной выборке размером в несколько миллионов subsample=1.0 — бессмысленно и неэффективно по времени), он ещё и работает как дополнительная регуляризация, например, диапазоны перебора максимальной глубины для больших выборок меньше.
Пользовательского параметра «Консервативная модель». При желании пользователь может поставить галочку напротив этого параметра. Тогда при обучении модели будет сделан больший упор на минимизацию разницы качества на train и test. Это реализовано за счёт наложения масок на стандартные сетки, которые либо сужают диапазон перебора параметра, либо вовсе фиксируют его.
В банке существуют кейсы, когда Data Scientist«у для подтверждения работоспособности своей модели нужно объяснять бизнес-заказчику чуть ли не каждую фичу. Такое требование со стороны заказчика опционально, но встречается довольно часто. Поэтому в нашем сервисе пользователь может самостоятельно указать желаемое количество признаков в итоговой модели, что включает вторую, более точную стадию отбора признаков:
Сократить количество признаков с 500 до 20 за одну итерацию было бы опрометчиво, поэтому наш процесс отбора — итеративный (Recursive Feature Elimination).
Берём всё те же экспертные наборы по умолчанию, обучаем на всех фичах, выбираем лучшую попытку.
Считаем feature importance по SHAP. Важно: SHAP кроме того, что намного более интерпретируем и оценивает важности точнее, ещё и позволяет считать важности именно на out of time выборке, что очень важно для отбора признаков.
Отбрасываем 30% фичей по важности с конца.
Повторяем эти шаги до тех пор, пока не дойдём до нужного пользователю количества.
Когда мы дошли до количества признаков, требуемого пользователем, можем подбирать гиперпараметры более основательно (то есть возвращаемся к общему случаю).
Я описал процесс обучения базового бустинга, но в сервисе реализован ещё и миксер всех моделей. Обычно в качестве миксера скоров используют логистическую регрессию, но она имеет множество нюансов.
В частности, реализация из sklearn иногда имеет странные проблемы со сходимостью, а также её не всегда возможно запустить с ограничением, чтобы коэффициенты смешиваемых скоров суммировались до единицы.
Наш же миксер работает очень просто, перебирая коэффициенты, суммирующиеся в единицу, с помощью Optuna. Такая реализация работает чуть дольше, но способна учитывать любые ограничения и метрики качества. Итак, обучение смешивания состоит из следующих этапов:
Обучаем каждый из трёх бустингов методом, описанным выше.
Далее собираем все скоры в один dataframe.
Оптимизируем смешивание скоров с помощью Optuna под заданную метрику.
Согласно нашему опыту, смешивание различных реализаций бустингов дополнительно увеличивает итоговое качество.
Этап 4. Результат
Когда модель обучена, пользователю важно получить результаты обучения модели. Причём нужно отобразить эти результаты так, чтобы они были легко интерпретируемы и воспроизводимы — это повысит доверие к модели и позволит легко найти возможные проблемы. Кроме подсчёта всех метрик, запрошенных пользователем, и логирования гиперпараметров моделей, мы сохраняем аналитику, специфичную для наших задач.
Список графиков варьируется в зависимости от типа задачи: регрессия, бинарная и многоклассовая классификации, аплифт-моделирование.
Но основная идея — отображать…
Важности признаков (SHAP bar plot и beeswarm plot). Причём благодаря нашему FeatureStore есть возможность отображать на графиках сразу человеческие названия: не comm_rub, а «Комиссия в рублях».
Наименее важные признаки для возможного дополнительного ручного отбора.
Важности отдельных источников данных.
Хит каждого из источников — пользователь сможет понять, для какой доли записей его выборки есть данные в том или ином источнике, меняются ли доли со временем.
Стабильность предсказаний по времени — считаем среднее значение предсказаний для каждого временного периода.
Стабильность метрики по времени — считаем метрики не на всём наборе данных, а отдельно по каждому периоду.
Распределение предсказаний по бинам — сколько предсказаний попало в каждый интервал.
И другие вспомогательные метрики и графики: precision/recall curve, вычисление оптимального threshold и тд.
Несмотря на то, что мы максимально стараемся убрать все плохие фичи, в некоторых случаях лики невозможно исключить из-за изобилия различных данных в FS. Причем качество расчета фичей тут совершенно ни при чем. Все зависит от конкретной задачи и целевой переменной.
На практике недавно возник такой кейс — задача предсказания дохода клиента. Естественно, что обучаемся мы на клиентах, доход которых нам уже известен — оказалось, что данные с доходом уже имеются и в FS. В итоге, график важности выглядит примерно так: получившаяся модель дохода на практике потребует само его значение для своего «предсказания»:
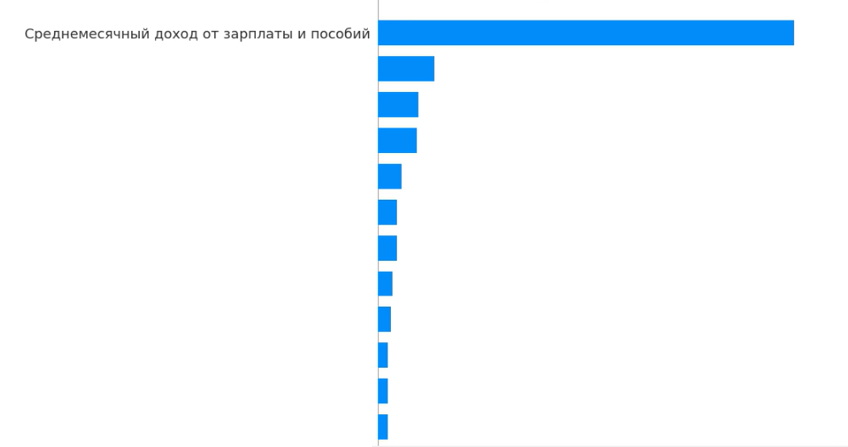
В итоге просто так скармливать AutoML любые задачи и выборки нельзя — человек должен присутствовать в любом случае, однако его вовлечение по времени на порядки меньше чем при ручном моделировании. Например, в описанном выше случае пользователю просто нужно перезапустить обучение, явно указав в поле «Признаки к удалению» фичу «доход». После того как AutoML построил модель, пользователю нужно проанализировать результаты модели, убедиться в отсутствии ликов и проблем со стабильностью.
На самом деле, множество таких проблем можно искать автоматически, например, если важность одной фичи доминирует над другими, или в тестовой выборке присутствуют классы, которых не было в обучении.
Сейчас мы как раз работаем над большой системой автоматического поиска проблем в моделях и моментального алертинга пользователей.
Если пользователь посчитал, что все ок — он может по одному нажатию кнопки задеплоить эту модель в продакшн, единая структура моделей позволяет делать это быстро и практически автоматически.
Битва титанов: AlfaAutoML vs LightAutoML
В процессе разработки нашего инструмента AutoML важно было понимать, как он работает на реальных задачах, которые решаются в банке с помощью ML: кредитный скоринг, задачи оттока, склонности к различным продуктам и т.д. Именно поэтому мы решили собрать у коллег выборки по их актуальным задачам, а также запросили метрики для сравнения. В итоге получили свой полноценный бенчмарк — набор актуальных и важных банковских задач, написали скрипт для последовательного запуска всех этих задач, добавив туда подсчёт статистик важности отдельных признаков и источников в целом.
Это позволяет нам при каждом новом обновлении модельной части нашего сервиса видеть, как изменения отражаются на результатах. А упомянутые мной статистики позволяют выявить фичи или целые источники данных, показывающие низкую или аномально высокую важность в большинстве задач — при постоянно растущем числе источников и регулярном обновлении модельной части AutoML, подобные количественные оценки очень важны для поиска проблем и принятия решений.
Когда мы убедились, что модельная часть нашего инструмента работает хорошо, оставалось провалидировать результаты непосредственно с разработчиками моделей, перенять их экспертизу (о возможности ипользования тех или иных признаков в конкретной задаче) и получить подтверждение корректности результатов.
Итоговый бенчмарк показал, что наш инструмент AutoML качественно строит модель в 75% случаев (качественно — не хуже по метрикам, чем у разработчика модели). В остальных 25% случаев играет роль или сложная специфика задачи, или отсутствие части данных в Feature Store. Такая зависимость мотивирует AutoML и Feature Store развиваться и расширяться совместно.
В самом начале статьи мы разобрались, что наиболее рутинный процесс в DataScience — это построение рядовых моделей. В итоге мы получили следующие характеристики: AutoML выполняет этот рутинный процесс в среднем за 6–7 часов, а время, требующееся от разработчика для запуска модели в сервисе — 10–20 минут.
Как можно презентовать AutoML не показав бенчмарки?
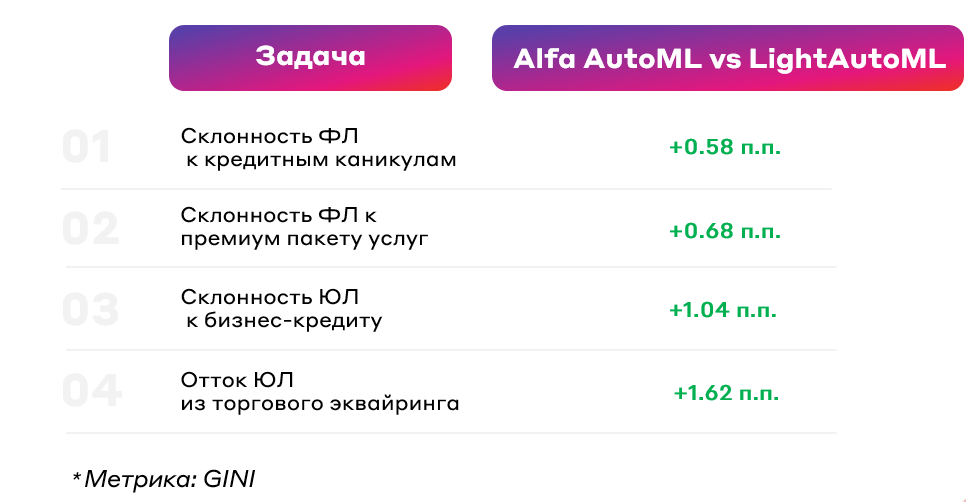
Мы решили сравнить наши результаты не только с результатами наших коллег, у которых мы заимствовали выборки, но и с потенциально лучшим открытым AutoML-решением — библиотекой LightAutoML. В процессе сравнения мы также подметили одну сложность в LightAutoML: если выставлять определенное количество фичей, то реализованный там backward отбор будет работать очень долго, поэтому для сравнения в обоих инструментах использовались базовые сценарии без отбора признаков.
Все сравнения были проведены на одинаковых выборках, на одинаковом наборе признаков. Как итог: наш процесс построения модели и подбора гиперпараметров требует больше времени, но качество получается лучше.
Текущие ограничения сервиса
Конечно, рассказав про сильные стороны нашего сервиса AutoML и неплохие результаты на реальных задачах, стоит упомянуть и о его текущих боттлнеках. Наш проект находится на стадии MVP, и мы активно работаем над улучшением функционала, а также устранением ограничений нашего сервиса.
Основной ограничитель — максимальный размер выборки, которую можно загрузить в сервис, сейчас это 10 млн. Решить проблему кроме дополнительной оптимизации сервиса с нашей стороны позволит стабилизация Spark, а также выделение большего количества ресурсов на кластере. Остальные ограничения преимущественно связаны с другими сервисами из экосистемы банковского Data Science: отсутствие части источников в FeatureStore, отсутствие ретро-данных по некоторым источникам и т.д.
Все эти задачи требуют немало времени, но мы вместе с коллегами активно прорабатываем их решение.
Планы на 2024
В заключение хотелось бы рассказать о наших планах на следующий год. Есть два очевидных пункта плана, затрагивающих только сам сервис AutoML:
Во-первых, наша цель — расширять спектр применения сервиса. Например, сделать возможным использование AutoML аналитиками. Несмотря на заинтересованность аналитиков в самостоятельном решении некоторых задач, это непростая цель, так как для её реализации потребуется провести разработку обучающих материалов, а также целое обучение по использованию инструмента. Кроме того, такой процесс требует постоянной технической поддержки.
Во-вторых, функционал сервиса, конечно, должен расширяться. Например, полезным будет добавление задач кластеризации/сегментации, поддержка новых источников данных, решение задач, в которых объектами являются не клиенты, а карты или счета и т.д.
Вообще, Лаборатория машинного обучения в Альфа Банке специализируется именно на нейронных сетях, поэтому наши предыдущие статьи посвящались использованию нейронных сетей в банковских задачах. Ни для кого не секрет, что ансамбль бустингов и нейронок даёт значительно лучшее качество, чем их использование по отдельности.
Как я уже говорил, в этом году наша команда разработала не только AutoML, но и ANNA — AutoDL сервис для автоматического построения нейронных сетей на последовательных данных: кредитных историй, карточных транзакций и транзакций расчётного счёта.
При обучении бустингов для получения табличных признаков мы неизбежно агрегируем признаки (например: средняя сумма транзакций за последние 30 дней), теряя информацию. В ANNA же каждая из трёх нейронных сетей принимает на вход не агрегированные признаки, а последовательности в сыром виде по конкретному источнику. Поэтому нейронки имеют возможность изучить детально каждую транзакцию, вытаскивая из данных максимум полезного.
Логично предположить, что дальнейшая цель — автоматизация того самого ансамбля из бустингов и нейронных сетей.
Создание такого суперсервиса позволит нам:
Использовать максимум источников: сырые последовательные данные в ANNA и обработанные специалистами признаки в AutoML.
Улучшить качество решений за счёт сильного ансамбля моделей.
Унифицированная структура всех моделей и автоматический деплой всего ансамбля.
Благодарим вас за прочтение и с радостью ответим на ваши вопросы в комментариях. Следить за развитием наших сервисов можно на Хабре, а также в нашем Телеграмм-канале «Нескучный Data Science».
К слову, в 2023 году мы запустили наш первый образовательный курс на платформе Stepik «Deep Learning in Finance» . В этом курсе мы подробно разбираем реальные задачи, которые решаются в Лаборатории Машинного обучения. Этот курс абсолютно бесплатный, и мы всегда рады видеть новых учеников.
Остаемся на связи, и до новых встреч!
