Ассемблер для задач симуляции. Часть 2: ядро симуляции
HCF, n. Mnemonic for «Halt and Catch Fire», any of several undocumented and semi-mythical machine instructions with destructive side-effects <...>Jargon File
В предыдущем посте я начал рассказ об областях применения ассемблера при разработке программных моделей вычислительных систем — симуляторов. Я описал работу программного декодера, а также порассуждал о методе тестирования симулятора с помощью юнит-тестов.В этой статье будет рассказано, зачем программисту нужны знания о структуре машинного кода при создании не менее важной компоненты симулятора — ядра, отвечающего за моделирования отдельных инструкций.До сих пор обсуждение в основном касалось ассемблера гостевой системы. Пришло время рассказать об ассемблере хозяйском.С ассемблером в сердце — ядро симулятора
У серьёзного симуляторного продукта должно быть многокамерное «сердце»: несколько способов для исполнения гостевого кода. В любой момент времени используется наиболее эффективный из них.В целом, выделяют три технологии: интерпретация, двоичная трансляция и прямое исполнение. И в каждом из них найдётся место для машинного кода и ассемблера.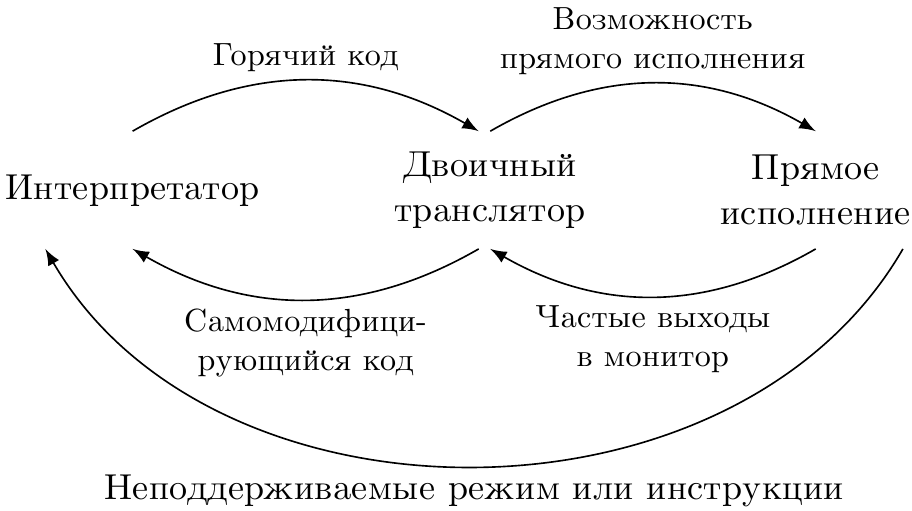 Интерпретатор и интринсики
Простейший симулятор на основе интерпретатора пишется на переносимом языке высокого уровня. Это означает, что каждая процедура, описывающая инструкцию, просто реализует её логику в Си.Большая доля машинных инструкций имеют довольно простую семантику, легко выражаемую в Си: сложить два числа, сравнить с третьим, сдвинуть вправо-влево и т.д. Привилегированные инструкции обычно сложнее из-за необходимости выполнения разнообразных проверок доступа и бросания исключений. Однако они относительно немногочисленны.Трудности появляются дальше. Вот есть инструкции, работающие с числами по стандарту IEEE 754, т.е. с плавающей запятой, «плавучка». Придётся правильно обрабатывать несколько форматов этих чисел, от float16 через float32, float64, иногда полустандартный float80 и даже float82; вроде бы ещё ни одна архитектура не поддерживает напрямую float128, хотя стандарт и их описывает. Поддерживать не-числа NaN, денормализованные числа, учитывать режимы округления и сигнализацию исключений. А также реализовать всевозможную арифметику, вроде синусов, корней, обратных величин.Некоторым подспорьем является открытая библиотека Softfloat, в которой реализовано достаточно много из стандарта.Другой пример класса инструкций, сложных для симуляции — это векторные, SIMD. Они выполняют одну операцию сразу над вектором однотипных аргументов. Во-первых, они тоже часто работают с «плавучкой», хотя и с целочисленными операндами тоже. Во-вторых, таких инструкций бывает много из-за комбинаторного эффекта: для каждой операции несколько длин векторов и форматов элементов, форматов масок, опциональное применение «перемешивающих» операций broadcast, gather/scatter и т.д. Успешно реализовав эмулирующие процедуры для всех требуемых гостевых инструкций, создатель модели, скорее всего, столкнётся с крайне низкой скоростью работы интерпретатора. И это неудивительно: то, что на реальной машине делается за одну инструкцию, в модели будет представлено в виде процедуры с циклом внутри и нетривиальной логикой, высчитывающей все краевые сценарии! Вот если бы что-то за нас реализовывало семантику инструкций, и делало это быстро!…Погодите, но ведь в хозяйском процессоре наверняка есть точно такие же или хотя бы очень похожие инструкции! Пусть не для всех, но хотя бы для части. Более того, популярные компиляторы предоставляют интерфейс для включения машинных инструкций в код — интринсики (англ. intrinsic — внутренний) — описания функций, оборачивающих машинные инструкции. Пример описания интринсиков для инструкции LZCNT из Intel SDM:
Intel C/C++ Compiler Intrinsic EquivalentLZCNT: unsigned __int32 _lzcnt_u32(unsigned __int32 src); LZCNT: unsigned __int64 _lzcnt_u64(unsigned __int64 src);
Интерпретатор и интринсики
Простейший симулятор на основе интерпретатора пишется на переносимом языке высокого уровня. Это означает, что каждая процедура, описывающая инструкцию, просто реализует её логику в Си.Большая доля машинных инструкций имеют довольно простую семантику, легко выражаемую в Си: сложить два числа, сравнить с третьим, сдвинуть вправо-влево и т.д. Привилегированные инструкции обычно сложнее из-за необходимости выполнения разнообразных проверок доступа и бросания исключений. Однако они относительно немногочисленны.Трудности появляются дальше. Вот есть инструкции, работающие с числами по стандарту IEEE 754, т.е. с плавающей запятой, «плавучка». Придётся правильно обрабатывать несколько форматов этих чисел, от float16 через float32, float64, иногда полустандартный float80 и даже float82; вроде бы ещё ни одна архитектура не поддерживает напрямую float128, хотя стандарт и их описывает. Поддерживать не-числа NaN, денормализованные числа, учитывать режимы округления и сигнализацию исключений. А также реализовать всевозможную арифметику, вроде синусов, корней, обратных величин.Некоторым подспорьем является открытая библиотека Softfloat, в которой реализовано достаточно много из стандарта.Другой пример класса инструкций, сложных для симуляции — это векторные, SIMD. Они выполняют одну операцию сразу над вектором однотипных аргументов. Во-первых, они тоже часто работают с «плавучкой», хотя и с целочисленными операндами тоже. Во-вторых, таких инструкций бывает много из-за комбинаторного эффекта: для каждой операции несколько длин векторов и форматов элементов, форматов масок, опциональное применение «перемешивающих» операций broadcast, gather/scatter и т.д. Успешно реализовав эмулирующие процедуры для всех требуемых гостевых инструкций, создатель модели, скорее всего, столкнётся с крайне низкой скоростью работы интерпретатора. И это неудивительно: то, что на реальной машине делается за одну инструкцию, в модели будет представлено в виде процедуры с циклом внутри и нетривиальной логикой, высчитывающей все краевые сценарии! Вот если бы что-то за нас реализовывало семантику инструкций, и делало это быстро!…Погодите, но ведь в хозяйском процессоре наверняка есть точно такие же или хотя бы очень похожие инструкции! Пусть не для всех, но хотя бы для части. Более того, популярные компиляторы предоставляют интерфейс для включения машинных инструкций в код — интринсики (англ. intrinsic — внутренний) — описания функций, оборачивающих машинные инструкции. Пример описания интринсиков для инструкции LZCNT из Intel SDM:
Intel C/C++ Compiler Intrinsic EquivalentLZCNT: unsigned __int32 _lzcnt_u32(unsigned __int32 src); LZCNT: unsigned __int64 _lzcnt_u64(unsigned __int64 src);
Эти же интринсики работают и в GCC. Ниже я провёл небольшой эксперимент:
$ cat lzcnt1.c
#include
int main (int argc, char **argv) { int64_t src = argc; int64_t dst = _lzcnt_u64(src); return (int)dst; } $ gcc -O3 -mlzcnt lzcnt1.c # Явно указываю архитектуру, т.к. мой процессор не поддерживает LZCNT $ objdump -d a.out <...пропускаем...> Disassembly of section .text:
00000000004003c0
Интринсики, присутствующие в компиляторах компании Microsoft, описаны в MSDN отдельно для x86 и x64. Документация к интринсикам компилятора Intel C/C++ уже несколько лет доступна в удобном интерактивном формате на веб-странице. Довольно удобно получается фильтровать их по классу расширения (SSE2, SSE3, AVX и т.д.) и по функциональности (операции над битами, логические, криптографические и т.д.), а также получать справку по семантике и по скорости работы (в тактах). Интринсики компилятора GCC для IA-32 в основном совпадают с описанными для ICC. Для Clang я не нашёл внятной документации на доступные интринсики для какой-либо архитектуры. Если у читателя есть актуальная информация по этому вопросу, то прошу поделиться ей в комментариях. По сравнению с рукописными секциями inline-ассемблера, интринсики обладают следующими преимуществами.
Вызов функции гораздо привычнее, его легче понять и меньше шансы напортачить в нём при написании. Интринсики переносят работу по выделению входных и выходных регистров на компилятор, а также позволяют ему провести проверку синтаксиса, соответствие типов и прочие полезные вещи и при необходимости сообщить о проблемах. В случае inline-кода диагностика ассемблера будет куда более загадочной. Тот, кому часто приходится выписывать clobber-спецификации для GNU as (и ошибаться в них), со мной согласится.
Интринсики не являются для компилятора «чёрными ящиками» inline-ассемблера, в которых происходят неизвестные ему обновления регистров и памяти. Соответственно его алгоритмы распределения регистров могут учитывать это в процессе обработки кода процедуры. В результате легче получить более быстрый код.
Интринсики имеют хоть и слабую, но переносимость между компиляторами (но не хозяйскими архитектурами). В крайнем случае можно написать по прототипу свой вариант реализации, если хозяйская архитектура не поддерживает инструкцию напрямую. Пример из практики: SSE2-инструкция CVTSI2SD xmm, r/m64 не имеет валидной кодировки в 32-битном режиме процессора. Соответственно нет и интринсика, тогда как в 64-битном режиме, для которого изначально разрабатывался некий инструмент, он был, и код его использовал. При компиляции кода на 32-битном хозяине выдавалась ошибка. Поскольку процедура, завязанная на этот интринсик, не была «горячей» (скорость работы приложения слабо от неё зависела), была написана своя реализация _mm_cvtsi64_sd () на Си, которая подставлялась в случае 32-битной сборки.
По этим или каким-то иным причинам компания Microsoft прекратила поддержку inline-ассемблера в MS Visual Studio 2010 и более поздних для архитектуры x64. Для вставки машинного кода в файлы с Си/C++ в этом случае остаются доступны только интринсики.Однако я пошёл бы против правды, сказав, что использование интринсиков является панацеей. Всё же необходимо приглядывать за кодом, генерируемом компилятором, особенно когда требуется выжать из него максимум производительности.Двоичный транслятор и кодогенерация
Двоичный транслятор (далее ДТ) как правило работает быстрее интерпретатора, потому что преобразует целые блоки гостевого машинного кода в эквивалентные им блоки хозяйского машинного кода, которые затем, в случае горячего кода, многократно запускаются. Интерпретатор же (если в нём не реализовано кэширование) вынужден обрабатывать каждую встретившуюся гостевую инструкцию с нуля, даже если он совсем недавно с ней работал.И, в отличие от интерпретатора, который можно от начала и до конца написать, не вникая в особенности хозяйской архитектуры, ДТ потребует знание и ассемблера, и кодировок машинных инструкций. При переносе своего симулятора на новую хозяйскую систему существенную часть его, отвечающую именно за кодогенерацию, придётся переписать. Такова цена скорости работы.В этой статье я опишу один из простых способов построения так называемого шаблонного транслятора. Если будет интерес, то как-нибудь в другой раз я постараюсь рассказать о более продвинутом способе двоичной трансляции.Получив от декодера информацию о гостевой инструкции, ДТ генерирует для неё кусочек машинного кода — капсулу. Для нескольких инструкций, исполняющихся последовательно, создаётся блок трансляции, состоящий из их капсул, записанных последовательно. В результате, когда в гостевой системе управление передаётся на первую оттранслированную инструкцию, для симуляции этой и последующих команд достаточно исполнить код из блока трансляции.Как сгенерировать код для гостевой инструкции, зная её опкод и значения операндов? По опкоду симулятор выбирает шаблон — заготовку хозяйского машинного кода, реализующую нужную семантику. От процедур, обычно создаваемых компилятором, её отличает отсутствие пролога и эпилога, так как мы напрямую «склеиваем» такие шаблоны в единый блок трансляции. Однако этого ещё недостаточно для того, чтобы пометить блок трансляции как готовый.Осталась невыполненной ещё одна задача — передать значения операндов как аргументы шаблону, таким образом его специализировав и превратив в капсулу. Причём передавать операнды чаще всего надо именно на этапе трансляции: они уже известны. То есть надо «зашить» их прямо в хозяйский код капсулы. С неявными операндами (например, лежащими на стеке значениями) это не получится, и их, конечно, придётся обрабатывать на этапе симуляции, тратя при этом время.Если размерность множества (= число комбинаций) явных операндов невелика, то их можно «вшить» в группу шаблонов для данной инструкции — по одному на каждую комбинацию. В результате для каждого гостевого опкода придётся выбирать из N шаблонов согласно тому, какие значения приняли операнды в каждом конкретном случае.К сожалению, не всё так просто. На практике чаще всего генерировать шаблоны для всевозможных значений операндов нереально из-за комбинаторного взрыва их числа. Так, трёхоперандная команда на архитектуре с 32 регистрами потребует по 32×32×32 = 2¹⁵ блоков кода. А если гостевая архитектура имеет операнды-литералы (а все важные имеют) шириной так в 32 бита, то придётся хранить 2³² вариантов капсулы. Надо что-то придумать.На самом деле нет нужды хранить кучу почти одинаковых шаблонов — все они содержат одни и те же хозяйские инструкции. При вариации гостевых операндов в них лишь изменяются некоторые хозяйские операнды (но иногда и длина инструкции, см. мой предыдущий пост), описывающие, где хранится моделируемое состояние или какой передаётся литерал. При формировании капсулы из шаблона надо «просто» пропатчить биты или байты по соответствующим смещениям:  Вопрос знатокам: какие архитектуры в примере выше используются в качестве гостевой и хозяйской? Таким образом, для каждой гостевой инструкции в составе симулятора с ДТ достаточно одного шаблона хозяйского машинного кода и одной процедуры, исправляющей исходные операнды на правильные. Естественно, для корректного патчинга шаблона надо знать смещения всех операндов относительно его начала, то есть разбираться в кодировке команд хозяйской системы. Фактически надо либо реализовывать свой собственный энкодер, либо каким-то образом научиться вычленять нужную информацию из работы стороннего инструмента.В целом процесс шаблонной трансляции представлен на следующем рисунке.
Вопрос знатокам: какие архитектуры в примере выше используются в качестве гостевой и хозяйской? Таким образом, для каждой гостевой инструкции в составе симулятора с ДТ достаточно одного шаблона хозяйского машинного кода и одной процедуры, исправляющей исходные операнды на правильные. Естественно, для корректного патчинга шаблона надо знать смещения всех операндов относительно его начала, то есть разбираться в кодировке команд хозяйской системы. Фактически надо либо реализовывать свой собственный энкодер, либо каким-то образом научиться вычленять нужную информацию из работы стороннего инструмента.В целом процесс шаблонной трансляции представлен на следующем рисунке.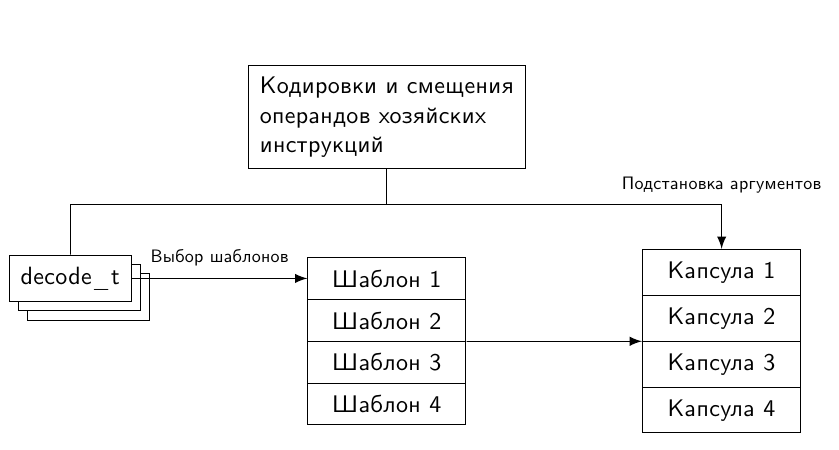
Прямое исполнение и виртуализация Третий рассматриваемый мной механизм симуляции — прямое исполнение. Принцип его работы напрямую следует из названия — симулировать гостевой код, без изменений запуская его на хозяине. Очевидно, что этот способ потенциально даёт самую высокую скорость симуляции; однако он и самый «капризный». Необходимо выполнение следующих требований.Архитектура гостя и хозяина должна совпадать. Другими словами, не получится напрямую моделировать код для ARM на MIPS и наоборот; во всяком случае, это будет уже не прямое исполнение. Хозяйская архитектура должна удовлетворять условиям эффективной виртуализации. Допустим, что гостевая архитектура удовлетворяет указанным условиям, например, это Intel IA-32/Intel 64 с расширениями Intel® VT-x. Следующая задача, возникающая при добавлении поддержки прямого исполнения в симулятор — это написание модуля ядра (драйвера) операционной системы. Без него не обойтись: симулятор необходимо будет исполнять привилегированные инструкции и манипулировать системными ресурсами, такими как таблицы страниц, физическая память, прерывания и прочее. Из пространства пользователя до них не дотянуться. С другой стороны, полностью «окапываться» в ядре вредно: программирование и отладка драйверов значительно затратнее по времени и по нервам, чем написание прикладных программ. Поэтому в ядро обычно выносят только самый минимум функциональности симулятора, к которому обращаются через интерфейсы системных вызовов. Все известные мне виртуальные машины и симуляторы, задействующие прямое исполнение, так и устроены: модуль ядра + пользовательское приложение, его использующее.Так как модуль ядра пишется к определённой ОС, необходимо понимать, что при переносе приложения на другую ОС его придётся переписывать, возможно довольно сильно. Это ещё одна причина для того, чтобы минимизировать его размер.В принципе, использование ассемблера в ядре оправдано примерно в таких же условиях, как и в юзерлэнде — то есть когда без него не обойтись. Виртуальные машины работают с системными структурами, такими как VMCS (virtual machine control structure), контрольные, отладочные и модель-специфичные регистры, которые доступны только через специализированные инструкции. Самым разумным было бы использовать для них интринсики, но…Не все машинные инструкции имеют готовые интринсики. В компиляторах, предназначенных для сборки преимущественно пользовательского кода, про нужды писателей драйверов как-то забывают. Для обращения к ним приходится использовать встроенный (inline) ассемблер. В исходном коде виртуальной машины KVM, например, есть такое определение для функции чтения полей VMCS:
#define ASM_VMX_VMREAD_RDX_RAX ».byte 0×0f, 0×78, 0xd0»
static __always_inline unsigned long vmcs_readl (unsigned long field) { unsigned long value;
asm volatile (__ex_clear (ASM_VMX_VMREAD_RDX_RAX,»%0»)
:»=a»(value) : «d»(field) : «cc»);
return value;
}
Честно говоря, я ожидал увидеть здесь вызов VMREAD по мнемонике vmread, но почему-то используется её «сырое» представление в виде байт. Может быть, таким образом авторы хотели поддержать сборку компиляторами, не знающими о такой инструкции.Кстати, пример с интринсиком для LZCNT из примера выше может быть переписан с помощью формата inline-ассемблера в следующем виде. Машинный код в этом простом случае генерируется тот же.
#include
