Асинхронный ETL-процесс на Python
Продолжаю цикл статей по разработке ETL-процессов на Python. На этот раз мы преобразуем синхронный etl-процесс из статьи Пишем ETL-процесс на Python в асинхронный.
Напомню, что нас интересует ETL-процесс (extract, transform, load) реализованный через паттерн «Цепочка обязанностей». Мы разработаем в качестве примера три обработчика, которые будут передавать данные последовательно от одного обработчика к другому. Каждый последующий обработчик решает, может ли он обработать запрос сам и стоит ли передавать запрос дальше по цепи.
Используем очереди
В традиционном «синхронном» решении мы передавали данные последовательно по цепочке из функции в функцию. Для асинхронного проекта такое решение не подойдет. Воспользуемся очередями, как промежуточным хранилищем между этапами нашего etl-процесса.
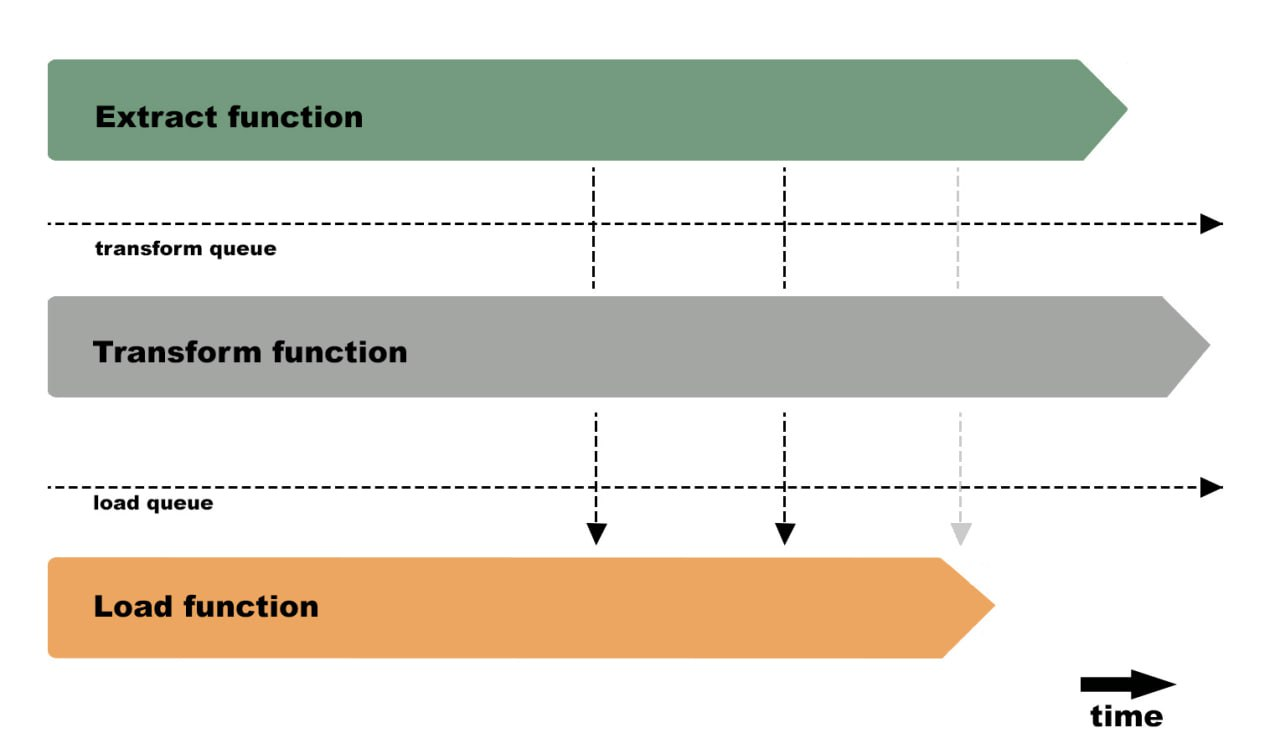
За каждый этап отвечает определенная функция. Таким образом каждая последующая функция абстрагирована от кода предыдущей функции и «смотрит» только в очередь.
Реализуем асинхронную заготовку проекта
Для технической реализации мы воспользуемся пакетом AnyIO. В пользу этого решения сыграло умение библиотеки работать с потоками объектов памяти, которые предназначены для реализации шаблона производитель-потребитель с несколькими задачами. Используя create_memory_object_stream (), мы получим пару потоков объектов: один для отправки, другой для получения. По сути, они работают как очереди, но с поддержкой закрытия и асинхронной итерации.
Ниже пример кода трех функций extract, transform и load и двух промежуточных очередей:
from anyio import create_memory_object_stream
from anyio.streams.memory import MemoryObjectSendStream, MemoryObjectReceiveStream
send_transform_stream, receive_transform_stream = create_memory_object_stream()
send_load_stream, receive_load_stream = create_memory_object_stream()
async def extract(send_stream: MemoryObjectSendStream) -> None:
""" Извлекает из БД данные и передает их в очередь
:param send_stream: очередь, в которую будут записаны результаты выполнения текущей функции
"""
async with engine.connect() as conn:
statement = select(source.c.id, source.c.number)
cursor = await conn.execute(statement)
async with send_stream:
record = cursor.fetchone() # можно использовать fetchmany, чтобы извлекать данные "пачками"
while record:
await send_stream.send(record._mapping)
record = cursor.fetchone()
async def transform(receive_stream: MemoryObjectReceiveStream, send_stream: MemoryObjectReceiveStream) -> None:
""" Пример промежуточной команды
:param receive_stream: очередь, из которой извлекаются данные для выполнения текущей функции.
:param send_stream: очередь, в которую будут записаны результаты выполнения текущей функции.
"""
async with receive_stream, send_stream:
async for record in receive_stream:
pass
await send_stream.send(record)
async def load(receive_stream: MemoryObjectReceiveStream) -> None:
""" Завершающий этап цепочки команд
:param receive_stream: очередь, из которой извлекаются данные для выполнения текущей функции
"""
async with receive_stream:
async for record in receive_stream:
passСледующая задача — запустить наши асинхронные функции. Обработка задач в AnyIO в общих чертах соответствует модели trio. Задачи могут быть созданы (порождены) с помощью групп задач. Группа задач — это асинхронный контекстный менеджер, который следит за тем, чтобы все его дочерние задачи были завершены тем или иным способом после выхода из контекстного блока. Если дочерняя задача или код во вложенном контекстном блоке вызывает исключение, все дочерние задачи отменяются. В противном случае диспетчер контекста просто ожидает завершения всех дочерних задач, прежде чем продолжить.
Возьмем за основу пример из документации:
from anyio import create_task_group, run, create_memory_object_stream
from anyio.streams.memory import MemoryObjectSendStream, MemoryObjectReceiveStream
async def main():
send_transform_stream, receive_transform_stream = create_memory_object_stream()
send_load_stream, receive_load_stream = create_memory_object_stream()
async with create_task_group() as tg:
tg.start_soon(etl.extract, send_transform_stream)
tg.start_soon(etl.transform, receive_transform_stream, send_load_stream)
tg.start_soon(etl.load, receive_load_stream)
if __name__ == '__main__':
run(main)Заполняем заготовку кода логикой
В это разделе я буду использовать те же названия подразделов, что и в предыдущей статье, чтобы можно было сравнить при желании.
Постановка задачи
Вымышленная задачка, главное «погонять» данные из функции в функцию.
В базе данных есть таблица, содержащая целые числа. ETL-процесс должен пройтись по всем записям таблицы, возвести каждое число в квадрат и отобразить в консоли. Для каждого четного числа вывести информационное сообщение «the square of an even number». Если число из базы данных равно 3, то прерываем обработку и переходим к следующему числу.
Первая функция
Задача первого обработчика из «цепочки обязанностей» в нашем вымышленном примере сделать sql-запрос к таблице, содержащей числовые строки и по одной передать их в генератор:
async def extract(send_stream: MemoryObjectSendStream) -> None:
""" Извлекает из БД строки и передает их в очередь
Args:
:param send_stream: очередь, в которую будут записаны результаты выполнения текущей функции
"""
async with engine.connect() as conn:
statement = select(source.c.id, source.c.number)
cursor = await conn.execute(statement)
async with send_stream:
while record := cursor.fetchone(): # можно использовать fetchmany, чтобы извлекать данные "пачками"
await logger.debug(f'send {record._mapping}')
await send_stream.send(record._mapping)Вторая и все промежуточные функции
У всех промежуточных функций «цепочки обязанностей» три задачи — получить объект из очереди, обработать его и передать в следующую очередь. В продолжении нашего вымышленного примера:
async def transform(receive_stream: MemoryObjectReceiveStream, send_stream: MemoryObjectReceiveStream) -> None:
""" Пример промежуточной команды
Args:
:param receive_stream: очередь, из которой извлекаются данные для выполнения текущей функции.
:param send_stream: очередь, в которую будут записаны результаты выполнения текущей функции.
"""
foo: int | str # инструкция для mypy
async with receive_stream, send_stream:
async for record in receive_stream:
await logger.debug(f'transform function received {record}')
# Логика обработки
new_number = record["number"] ** 2
if record["number"] % 2 == 0:
foo = "an even number"
await logger.info("{} {}".format(record["number"], foo))
elif record["number"] == 3:
await logger.error("{} {}".format(record["number"], "skip load stage"))
continue # Прерываем цепочку команд
else:
foo = 0
await send_stream.send((new_number, foo))Ветками if/elif/else показано, что можно управлять наборами данных, которые будут направлены на следующий этап. А также через continue можно вообще прервать выполнение цепочки обязанностей.
Заключительная функция
Технически это функция из предыдущего раздела только без инструкции по отправке объектов в следующую очередь. Завершаем нашу вымышленную цепочку:
async def load(receive_stream: MemoryObjectReceiveStream) -> None:
""" Завершающий этап цепочки команд
Args:
:param receive_stream: очередь, из которой извлекаются данные для выполнения текущей функции
"""
async with receive_stream:
async for record in receive_stream:
await logger.debug(f'load function received {record}')
match record:
case (int(number), str(bar)):
await logger.info('the square of {} = {}'.format(bar, number))
case (int(number), int(bar)):
await logger.info(number)
case _:
raise SyntaxError(f"Unknown structure of {record=}")Здесь в качестве бизнес-логики идет управление набором данных через match/case.
Делаем выводы
Асинхронный python это «сложный» python, но etl процессы на нем выглядят более читаемо (см. пример кода в разделе Реализуем асинхронную заготовку проекта), чем процессы, построенные на генераторах. Это весомый плюс при построении длинных цепочек задач.
Вы получаете преимущество, владея навыком написания асинхронного кода, как с точки зрения ревью кода, так и его производительности.
Репозиторий с учебным проектом доступен по ссылке https://github.com/s-klimov/etl-template/tree/04-async
