Асинхронность в программировании
В области разработки высоконагруженных многопоточных или распределенных приложений часто возникают дискуссии об асинхронном программировании. Сегодня мы подробно погрузимся в асинхронность и изучим, что это такое, когда она возникает, как влияет на код и язык программирования, которым мы пользуемся. Разберемся, зачем нужны Futures и Promises и затронем корутины и операционные системы. Это сделает компромиссы, возникающие во время разработки ПО, более явными.
В основе материала — расшифровка доклада Ивана Пузыревского, преподавателя школы анализа данных Яндекса.

Скрытый текст
Всем привет, меня зовут Иван Пузыревский, я работаю в компании Яндекс. Последние лет шесть я занимался инфраструктурой хранения и обработки данных, сейчас перешел в продукт — в поиск путешествий, отелей и билетов. Так как я работал долгое время в инфраструктуре, то у меня накопилось довольно много опыта, как писать разные нагруженные приложения. Наша инфраструктура работает 24*7*365 каждый день нон-стоп, непрерывно на тысячах машин. Естественно, нужно писать код так, чтобы он работал надежно и производительно и решал задачи, которые перед нами ставит компания.
Сегодня мы с вами поговорим про асинхронность. Что такое асинхронность? Это несовпадение чего-либо с чем-либо во времени. Из этого описания вообще не понятно, про что я сегодня буду говорить. Чтобы как-то пояснить вопрос, мне нужен пример а-ля «Hello, world!». Асинхронность обычно возникает в контексте написания сетевых приложений, поэтому у меня будет сетевой аналог «Hello, world!». Это приложение ping-pong. Код выглядит таким образом:
socket s;
string x;
x = read_from_socket(s, 4);
if (x == "ping") {
write_to_socket(s, "pong");
}
return;
Я создаю сокет, читаю оттуда строку, и проверяю — если это ping, то пишу в ответ pong. Очень просто и понятно. Что происходит, когда вы видите такой код на экране своего компьютера? Мы думаем об этом коде как о последовательности вот таких шагов:
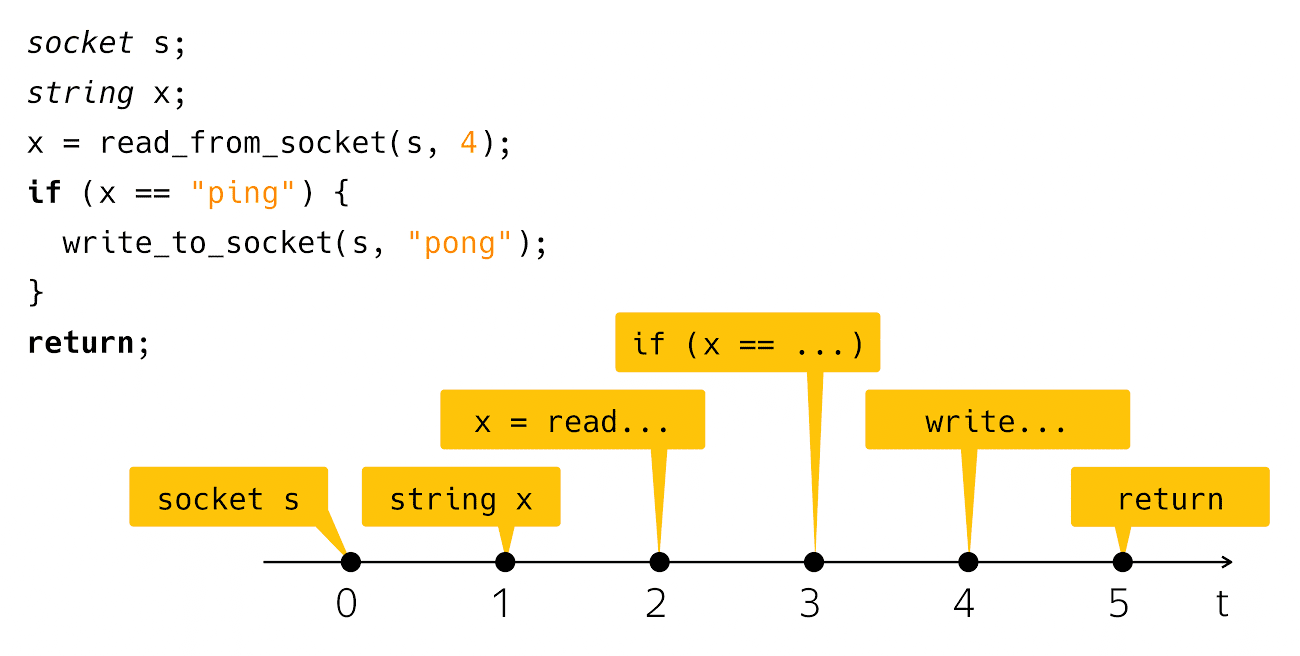
С точки зрения реального физического времени все немного смещено.

Те, кто реально такой код писал и запускал, знают, что после шага read и после шага
write идет довольно заметный интервал времени, когда наша программа вроде бы ничего не делает с точки зрения нашего кода, но под капотом работает машинерия, которую мы называем «ввод-вывод».

Во время ввода/вывода происходит обмен пакетами по сети и вся сопутствующая тяжелая низкоуровневая работа. Проведем мысленный эксперимент: возьмем такую одну программу, запустим на одном физическом процессоре и сделаем вид, что у нас нет никакой операционной системы, что получится? Процессор не может остановиться, он продолжает делать такты, не исполняя никаких инструкций, просто зря потребляя энергию.
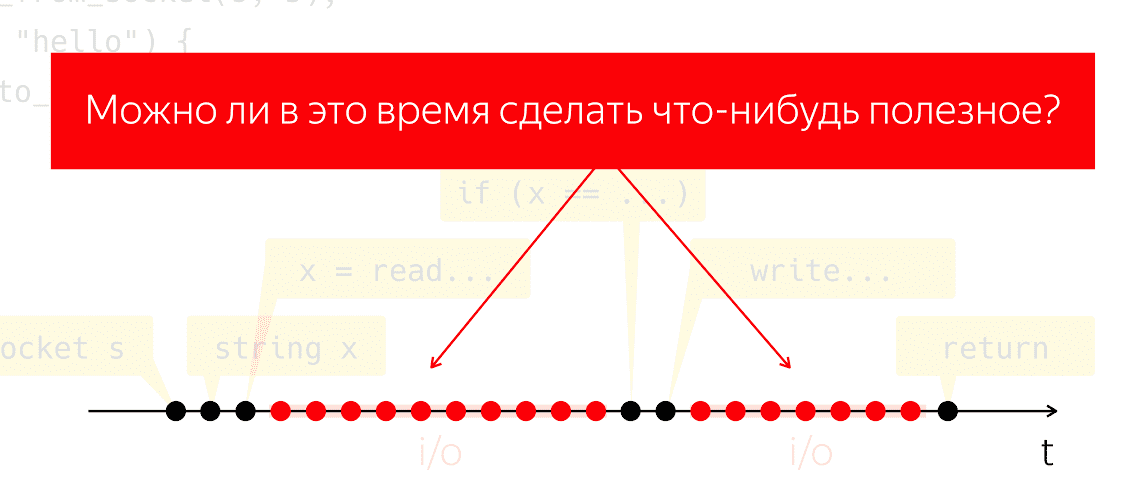
Возникает вопрос, можем ли мы в этот период времени сделать что-нибудь полезное. Очень естественный вопрос, ответ на который позволил бы нам сэкономить процессорные мощности и использовать их для чего-то полезного, пока наше приложение вроде как ничего не делает.
3.1. Поток выполнения
Как мы можем подступиться к этой задаче? Давайте согласуем понятия. Я буду говорить «поток выполнения», имея в виду некоторую осмысленную последовательность элементарных операций или шагов. Осмысленность будет определяться контекстом, в котором я говорю о потоке выполнения. То есть если мы говорим про однопоточный алгоритм (Ахо-Корасик, поиск по графу), то сам этот алгоритм — уже есть поток выполнения. Он делает какие-то шаги для решения задачи.
Если я говорю о базе данных, то одним потоком выполнения может быть часть действий, совершаемых базой данных для обслуживания одного пришедшего запроса. То же и для веб-серверов. Если я пишу какое-то мобильное или веб-приложение, то для обслуживания одной операции пользователя, например, клика на кнопку, происходят сетевые взаимодействия, взаимодействие с локальным хранилищем и так далее. Последовательность этих действий с точки зрения моего мобильного приложения будет также отдельным осмысленным потоком выполнения. С точки зрения операционной системы, процесс или нить процесса также являются осмысленным потоком выполнения.
3.2. Многозадачность и параллелизм
Краеугольный камень производительности — это умение сделать такой трюк: когда у меня есть один поток выполнения, который содержит в своей физической временной развертке пустоты, тогда заполнить эти пустоты чем-нибудь полезным — исполнить шаги других потоков выполнения.
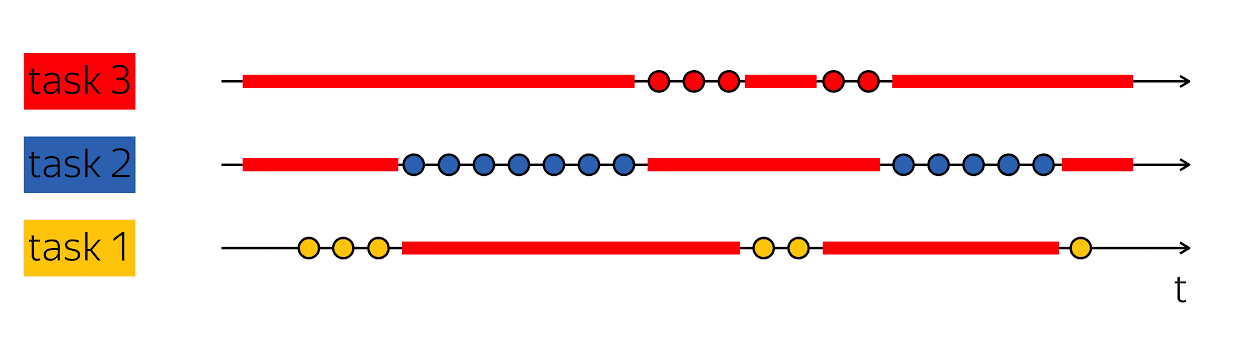
Базы данных обычно обслуживают много клиентов одновременно. Если мы можем совместить работу над несколькими потоками выполнения в рамках одного потока выполнения более высокого уровня, то это называется многозадачность. То есть многозадачность — это когда я в рамках одного более крупного потока выполнения совершаю действия, которые подчинены решению более мелких задач.
При этом важно не путать понятие многозадачности с параллелизмом. Параллелизм —
это свойства среды исполнения, которое дает возможность за один такт времени, за один шаг, совершить прогресс в разных потоках выполнения. Если у меня есть два физических процессора, то за один такт времени они могут исполнить две инструкции. Если программа запущена на одном процессоре, то ей потребуется два такта времени, чтобы исполнить эти же две инструкции.

Важно не путать эти понятия, так как они относятся к разным категориям. Многозадачность — это свойство вашей программы, что она внутри структурирована как переменная работа над разными задачами. Параллелизм — это свойство среды исполнения, которое дает вам возможность за один такт времени работать над несколькими задачами.
Во многом асинхронный код и написание асинхронного кода — это написание многозадачного кода. Основная сложность связана с тем, как мне кодировать задачи и как ими управлять. Поэтому сегодня мы будем говорить именно об этом — о написании многозадачного кода.

Начнем с какого-нибудь простого примера. Вернемся к ping-pong:
socket s;
string x;
x = read_from_socket(s, 4);
if (x == "ping") {
write_to_socket(s, "pong");
}
return;
Как мы уже обсудили, после строчек read и white поток выполнения засыпает, блокируется. Обычно мы так и говорим, «поток заблокирован».
socket s;
string x;
x = read_from_socket(s, 4);
/* thread is blocked here */
if (x == "ping") {
write_to_socket(s, "pong");
/* thread is blocked here */
}
return;
Это значит, что поток выполнения дошел до такой точки, когда для дальнейшего его продолжения необходимо наступление какого-либо события. В частности, в случае нашего сетевого приложения нужно, чтобы поступили данные по сети или, наоборот, у нас освободился буфер для записи данных в сеть. События могут быть разные. Если мы говорим про временные аспекты, то можем ждать срабатывания таймера или завершения другого процесса. События здесь — некая абстрактная вещь, про них важно понимать, что их можно ожидать.

Когда мы пишем простой код, то неявно отдаем управление ожиданием событий уровню выше. В нашем случае — операционной системе. Она, как сущность более высокого уровня, отвечает за выбор, какая задача будет исполняться далее, и она же отвечает за отслеживание наступления событий.
Наш код, который мы пишем как разработчики, структурирован в это же время относительно работы над одной задачей. Фрагмент кода из примера занимается обработкой одного соединения: он из одного соединения читает ping и в одно соединение пишет pong.
Код понятный. Его можно прочитать и понять, что он делает, как он работает, какую задачу решает, какие инварианты в нем есть и так далее. При этом мы очень слабо управляем планированием задач в такой модели. Вообще, в операционных системах есть понятия приоритетов, но если вы писали системы мягкого реального времени, то знаете, что инструментов, доступных в Linux, не хватает для создания достаточно вменяемых систем реального времени.
Далее, операционная система — штука сложная, и переключение контекста из нашего приложения в ядро стоит единицы микросекунд, что при некотором несложном подсчете дает нам оценку на порядка 20–100 тысяч переключений контекста в секунду. Это значит, что если мы пишем веб-сервер, то за одну секунду можем обработать порядка 20 тысяч запросов, предполагая, что обработка запросов стоит в десять раз дороже, чем работа системы.

4.1. Неблокирующее ожидание
Если вы приходите к ситуации, что вам нужно работает с сетью более эффективно, то вы начинаете искать помощь в интернете и приходите к использованию select/epoll. В интернете написано, что если хочется обслуживать тысячи соединений одновременно, нужен epoll, потому что это хороший механизм и так далее. Вы открываете документацию и видите что-то типа такого:
int select(int nfds, fd_set* readfds, fd_set* writefds,
fd_set* exceptfds, struct timeval* timeout);
void FD_CLR(int fd, fd_set* set);
int FD_ISSET(int fd, fd_set* set);
void FD_SET(int fd, fd_set* set);
void FD_ZERO(fd_set* set);
int epoll_ctl(int epfd, int op,
int fd, struct epoll_event* event);
int epoll_wait(int epfd, struct epoll_event* events,
int maxevents, int timeout);
Функции, в которых в интерфейсе фигурирует либо множество дескрипторов, с которыми вы работаете (в случае select), либо множество событий, которые проходят
через границы вашего приложения ядра операционной системы, которые вам нужно обрабатывать (в случае epoll).
Также стоит добавить, что можно прийти не к select/epoll, а к библиотеке типа libuv, у которой в API не будет никаких событий, но будет множество коллбэков. Интерфейс библиотеки будет говорить: «Дорогой друг, для чтения сокета предоставь коллбэк, который я позову, когда появятся данные».
int uv_timer_start(uv_timer_t* handle, uv_timer_cb cb,
uint64_t timeout, uint64_t repeat);
typedef void (*uv_timer_cb)(uv_timer_t* handle);
int uv_read_start(uv_stream_t* stream,
uv_alloc_cb alloc_cb, uv_read_cb read_cb);
int uv_read_stop(uv_stream_t*);
typedef void (*uv_read_cb)(uv_stream_t* stream,
ssize_t nread, const uv_buf_t* buf);
int uv_write(uv_write_t* req, uv_stream_t* handle,
const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb);
typedef void (*uv_write_cb)(uv_write_t* req, int status);
Что поменялось по сравнению с нашим синхронным кодом в предыдущей главе? Код стал асинхронным. Это значит, что мы в приложение забрали логику по определению момента времени, когда отслеживается наступление событий. Явные вызовы select/epoll — это точки, где мы запрашиваем у операционной системы информацию о наступивших событиях. Также мы забрали в код своего приложения выбор, над какой задачей работать дальше.

Из примеров интерфейсов можно заметить, что механизмов привнесения многозадачности принципиально есть два. Один вида «тяни», когда мы
вытягиваем множество наступивших событий, которые мы ждем, и дальше на них как-то реагируем. В таком подходе легко амортизировать накладные расходы на одно
событие и поэтому достигать высокой пропускной способности по коммуникации о множестве наступивших событий. Обычно все сетевые элементы вроде взаимодействия ядра с сетевой карточкой или взаимодействия вас и операционной системы построены на poll-механизмах.
Второй способ — это механизм вида «толкай», когда некая внешняя сущность явно приходит, прерывает поток выполнения и говорит: «Теперь, пожалуйста, обработай событие, которое сейчас наступило». Это подход с коллбэками, с uniх-сигналами, с прерываниями на уровне процессора, когда внешняя сущность явно вторгается в ваш поток выполнения и говорит: «Сейчас, пожалуйста, работаем вот над этим событием». Такой подход появился для того, чтобы уменьшить задержку между наступлением события и реакцией на него.
Зачем мы, разработчики на C++, которые пишут и решают конкретные прикладные задачи, можем захотеть притащить в свой код событийную модель? Если мы перетаскиваем в свой код работу над многими задачами и управление ими, то из-за отсутствия перехода в ядро и обратно, мы можем чуть быстрее работать и за единицу времени совершать больше полезных действий.
К чему это приводит с точки зрения кода, который мы пишем? Возьмем, к примеру, nginx — высокопроизводительный HTTP-сервер, очень распространенный. Если почитать его код, он построен по асинхронной модели. Код читать довольно сложно. Когда ты задаешься вопросом, что же конкретно происходит при обработке одного HTTP-запроса, то оказывается, что в коде есть очень много фрагментов, разнесенных по разным файлам, по разным углам кодовой базы. Каждый фрагмент совершает маленький объем работы в рамках обслуживания всего HTTP-запроса. К примеру:
static void ngx_http_request_handler(ngx_event_t *ev)
{
…
if (c->close) {
ngx_http_terminate_request(r, 0);
return;
}
if (ev->write) {
r->write_event_handler(r);
} else {
r->read_event_handler(r);
}
...
}
/* where the handler... */
typedef void (*ngx_http_event_handler_pt)(ngx_http_request_t *r);
struct ngx_http_request_s { /*... */ ngx_http_event_handler_pt read_event_handler; /* ... */ };
/* ...is set when switching to the next processing stage */
r->read_event_handler = ngx_http_request_empty_handler;
r->read_event_handler = ngx_http_block_reading;
r->read_event_handler = ngx_http_test_reading;
r->read_event_handler = ngx_http_discarded_request_body_handler;
r->read_event_handler = ngx_http_read_client_request_body_handler;
r->read_event_handler = ngx_http_upstream_rd_check_broken_connection;
r->read_event_handler = ngx_http_upstream_read_request_handler;
Есть структура request, которая пробрасывается в обработчик наступивших событий, когда сокет сигнализирует о доступности на чтение или на запись. Дальше этот обработчик постоянно по ходу работы программы переключается в зависимости от того, в каком состоянии находится обработка запроса. Либо мы читаем заголовки, либо читаем тело запроса, либо спрашиваем у upstream данные — в общем, много разных состояний.
Такой код сложновато читать, потому что он, в своей сути, описан в терминах реакции на события. Мы находимся в таком-то состоянии и реагируем определенным образом на наступившие события. Не хватает целостной картины обо всем процессе обработки HTTP-запроса.
Другой вариант — который обычно часто используется в JavaScript — это построение кода на основе коллбеков, когда мы пробрасываем в интерфейсный вызов свой коллбэк, в котором обычно есть еще какой-нибудь вложенный коллбэк на наступление события и так далее.
int LibuvStreamWrap::ReadStart() {
return uv_read_start(stream(),
[](uv_handle_t* handle, size_t suggested_size, uv_buf_t* buf) {
static_cast(handle->data)->OnUvAlloc(suggested_size, buf);
}, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) {
static_cast(stream->data)->OnUvRead(nread, buf);
});
}
/* ...for example, parsing http... */
for (p=data; p != data + len; p++) {
ch = *p;
reexecute:
switch (CURRENT_STATE()) {
case s_start_req_or_res: /*... */
case s_res_or_resp_H: /*... */
case s_res_HT: /*... */
case s_res_HTT: /* ... */
case s_res_HTTP: /* ... */
case s_res_http_major: /*... */
case s_res_http_dot: /*... */
/* ... */
Код опять сильно фрагментирован, нет понимания текущего состояния, как мы работаем над запросом. Через замыкания передается много информации, и нужно прикладывать умственные усилия, чтобы реконструировать логику обработки одного запроса.
Таким образом, привнеся в свой код многозадачность (логику выбора рабочих задач и их мультиплексирования), мы получаем эффективный код и контроль над приоритезацией задач, но очень сильно теряем в читаемости. Этот код сложно читать и сложно поддерживать.

Почему? Представим, у меня есть простой кейс, например, я читаю файл и передаю его по сети. В неблокирущем варианте этому кейсу будет соответствовать такой линейный конечный автомат:
- Начальное состояние,
- Запуск чтения файла,
- Ожидание ответа от файловой системы,
- Запись файла в сокет,
- Конечное состояние.
Теперь, допустим, я хочу к этому файлу добавить информацию из базы данных. Простой вариант:
- начальное состояние,
- читаю файл,
- прочитал файл,
- читаю из базы данных,
- прочитал из базы данных,
- работаю с сокетом,
- записал в сокет.
Вроде как линейный код, но количество состояний увеличилось.
Дальше вы начинаете думать, что было бы неплохо распараллелить два шага — чтение из файла и из базы данных. Начинаются чудеса комбинаторики: вы находитесь в начальном состоянии, запрашиваете чтение файла и данные из базы данных. Дальше вы можете прийти либо в состояние, где есть данные из базы данных, но нет файла, либо наоборот — есть данные из файла, но нет из базы данных. Далее нужно перейти в состояние, когда у вас есть одно из двух. Опять же это два состояния. Потом нужно перейти в состояние, когда у вас есть оба ингредиента. Потом писать их в сокет и так далее.
Чем сложнее приложение, тем больше состояний, тем больше фрагментов кода, которые нужно комбинировать в своей голове. Неудобно. Либо вы пишете лапшу из коллбэков, которую читать неудобно. Если пишется развесистая система, то однажды наступает момент, когда терпеть это больше нельзя.
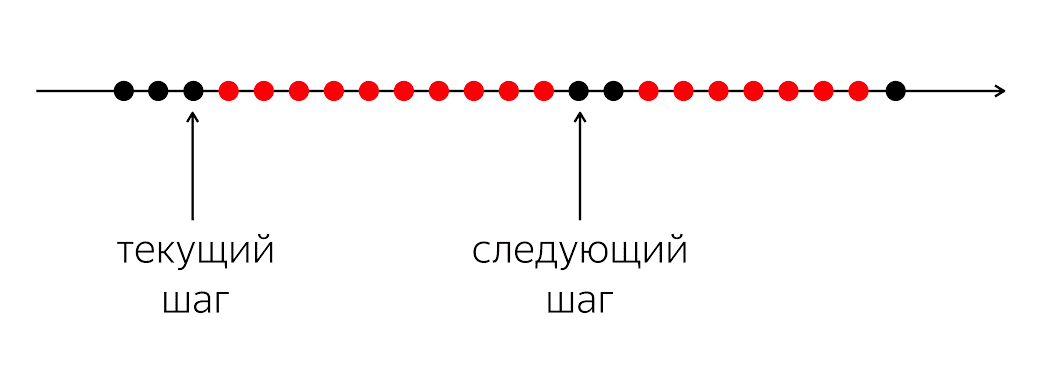
Чтобы решить проблему, нужно посмотреть на ситуацию проще.

Есть программа, в ней есть черные и красные кружочки. Наш поток выполнения — это черные кружочки; иногда они перемежаются красными, когда поток не может продолжать свою работу. Проблема в том, что для нашего черного потока выполнения нужно попасть в следующий черный кружочек, который будет неизвестно когда.
Проблема в том, что когда мы пишем код на языке программирования, мы объясняем компьютеру, что делать прямо сейчас. Компьютер — условно простая штука, которая ожидает инструкции, которые мы пишем на языке программирование. Она ожидает инструкции про следующий кружочек, и в нашем языке программирования не хватает средств, чтобы сказать: «В будущем, пожалуйста, когда наступит некоторое событие, сделай что-нибудь».

В языке программирования мы оперируем понятными сиюминутными действиями: вызов функции, арифметические операции и тд. Они описывают конкретный ближайший следующий шаг. При этом для обработки логики приложения нужно описывать не следующий физический шаг, а следующий логический шаг: что нам делать, когда появятся данные из базы данных, например.
Поэтому нужен некий механизм, как комбинировать эти фрагменты. В случае, когда мы писали синхронный код, мы скрыли вопрос полностью под капот и сказали, что этим будет заниматься операционная система, разрешили ей прерывать и перепланировать наш потоки выполнения.
В уровне 1 мы открыли этот ящик Пандоры, и он привнес в код много switch, case, условий, ветвей, состояний. Хочется какого-то компромисса, чтобы код был относительно читаемый, но сохранял все преимущества уровня 1.
К счастью для нас, в 1988 году люди, занимающиеся распределенными системами, Барбара Лисков и Люба Ширира, осознали проблему, и пришли к необходимости лингвистических изменений. В язык программирования нужно добавить конструкции, позволяющие выражать темпоральные связи между событиями — в текущем моменте времени и в неопределенном моменте в будущем.
Это назвали Promises. Концепция классная, но она двадцать лет пылилась на полке. В последнее время она набирает интерес — к примеру, товарищи в Twitter, когда рефакторили свой код с Ruby on Rails на Scala, прониклись этой концепцией достаточно глубоко, и решили, что все сервисы будут суть функция, которая берет запрос и возвращает future на ответ. Вы можете прочитать статью Your Server as a Function. Очень стройная концепция, которая позволила им очень оперативно переструктурировать весь код.
Но это Scala, а что делать нам, С++ разработчикам?
Нам нужна некая абстракция, назовем её Future. Это контейнер для значения типа T cо следующей семантикой: прямо сейчас значение в контейнере может отсутствовать, но когда-то в будущем оно появится.
template class Future
С помощью этого контейнера мы будем связывать те значения, что появятся в будущем, с теми, что есть в настоящем моменте. То есть мы, находясь в «сейчас», будем говорить, что нужно будет сделать в будущем. В дальнейшем в рассказе Future будем называть интерфейсом для «чтения», а Promise — для «записи». В других языках программирования именования могут быть другими; к примеру, в JavaScript, Promise — интерфейс для чтения и записи одновременно, а в Java — есть только Future.
Чтобы проиллюстрировать идею, я буду использовать модельную реализацию. Если вам нужен реальный код, который можно использовать в своей кодовой базе, то стоит посмотреть на boost: future (не std: future) — в нем есть большая часть того, о чем мы будем говорить.
5.1. Интерфейс Future & Promise
template class Future
{
bool IsSet() const;
const T& Get() const;
T* TryGet() const;
void Subscribe(std::function cb);
template Future Then(
std::function f);
template Future Then(
std::function(const T&)> f);
};
template Future MakeFuture(const T& value);
Это контейнер, значит, есть какое-то значение, о котором мы хотим контейнер спросить. В частности, узнать, есть ли в нем значение сейчас, достать его оттуда. И, раз значения могут появиться в будущем, было бы неплохо иметь возможность подписаться — предоставить некоторую функцию, которая будет вызвана, когда появится значения. Для выразительности добавим ещё две функции Then, о которых я буду говорить позже.
template class Promise
{
bool IsSet() const;
void Set(const T& value);
bool TrySet(const T& value);
Future ToFuture() const;
};
template Promise NewPromise();
Интерфейс для записи. Через него также можно опросить контейнер, есть ли в нем значение или нет. Можем сказать контейнеру «запиши, пожалуйста, значение, которое у меня есть в руках».
5.2. Композиция вычислений
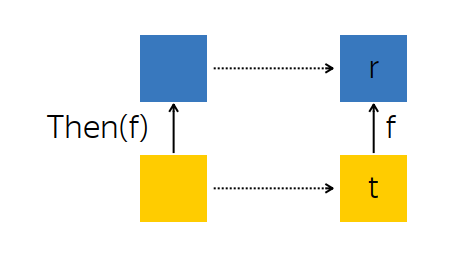
В чем крутость конструкции? Крутость начинается, когда вы пытаетесь написать комбинаторы для связывания ваших вычислений. Функция Then — это то, что позволяет делать комбинации такого рода.
Допустим, у меня сейчас есть обещание — future --, что в будущем появится какое-то значение t — на диаграмме это левый нижний желтый квадратик. Я знаю уже сейчас, что, когда значение появится, то я хочу применить к нему функцию f, которая что-то сделает и вернет значение r.
Я могу скомбинировать мое обещание в будущем получить значение t и желание применить трансформацию f. Тогда я получу обещание в настоящем моменте времени, о том, что в будущем появится значение r.
Появится каким способом: когда будет значение t, то я применю к нему функцию, получу значение r и положу в заранее подготовленный контейнер. С точки зрения кода это выглядит так:
template template
Future Future::Then(std::function f)
{
auto promise = NewPromise();
this->Subscribe([promise] (const T& t) {
auto r = f(t);
promise.Set(r);
});
return promise.ToFuture();
}
Последовательность действий:
- создаю
PromiseтипаR, - подписываюсь в текущем
Futureна появление значенияt, - когда оно появляется, то я вычисляю
r = f(t), - кладу
rв новосозданныйPromise, - в текущем моменте возвращаю новосозданный
Promise.
Идею можно развить на функцию f, которые возвращают не просто R, а Future, то есть обещает в будущем вернуть значение типа R. Получится так:
- подписаться в настоящем моменте времени на появление значения типа
T, - в обработчике, когда появится значение типа
T, вызвать функцию, которая пообещает сделать значение типаR, - сразу же подписаться еще раз, и когда появится значение типа
R, то исполнить то обещание, которое дали себе в настоящем два шага назад.
template template
Future Future::Then(std::function(const T&)> f)
{
auto promise = NewPromise();
this->Subscribe([promise] (const T& t) {
auto that = f(t);
that.Subscribe([promise] (R r) {
promise.Set(r);
});
});
return promise.ToFuture();
}
На диаграмме мы находимся в левом нижнем углу, в будущем когда-то появится значение типа t. Мы над ним в будущем позовем функцию f, и ещё дальше в будущем появится значение r, которое положим в контейнер. Верхняя дуга связывает обещание, которое даем в настоящем и то значение, которое мы получим.

С точки зрения кода, в момент вызова Then случаются три шага:
- создание контейнера
Promise, - вызов
Subscribeс некоторой лямбда-функцией, - возврат
Promise, преобразованный воFuture.
Функция работает быстро и моментально связывает, что произойдет в настоящем и в будущем. Такой подход удобен тем, что позволяет прямо сейчас сконструировать конвейер обработки, не дожидаясь никаких событий, и выносит за скобки логику ожидания событий и вызова реакции на них.
Если обратить внимание на слайды, то можно заметить, что в предыдущих примерах я только подписываюсь на появление значения, но нигде не вызываю функции-обработчики. Чтобы конструкция заработала, нужны интерфейсы, чтобы вызывать функции-обработчики, переданные в Subscribe. Нужен поток или пул потоков в фоне, в которые вы сможете, при наступлении событий, запланировать функции-обработчики на исполнение. Они будут исполнены, и вся конструкция заведется.
5.3. Примеры
Если у меня есть конкретная функция AsyncComputeValue, которая считает некоторое число на GPU, и возвращает обещание на подсчитанное в будущем число. Используя методы Then, мы можем сразу сказать, что на самом деле нас интересует число (2v+1)2 .
Future value = AsyncComputeValue();
// Подписка на результат
value.Subscribe([] (int v) {
std::cerr << "Value is: " << v << std::endl;
});
Мы это можем выразить таким сниппетом. Он утрированный, но что здесь важно: желание посчитать (2v+1)2 с точки зрения исходного кода очень локально. Мы уже в этом сниппете кода написали, что хотим сделать во все последующие моменты времени и взглядом охватить происходящее.
// Вычисление (2v+1)^2
Future anotherValue = value
.Then([] (int v) { return 2 * v; })
.Then([] (int u) { return u + 1; })
.Then([] (int w) { return w * w; });
С точки зрения времени исполнения, картинка не будет соответствовать написанному, но сейчас нас это беспокоить не должно. Мы хотим исправить проблему с понятностью кода.
Второй пример. Имеется несколько функций: первая считает ключ, по которому в БД хранятся секретные послания; вторая читает данные из БД по ключу; третья отправляет данные роверу на другой планете.
Future GetDbKey();
Future LoadDbValue(int key);
Future SendToMars(string message);
Future ExploreOuterSpace() {
return GetDbKey() // Future
.Then(&LoadDbValue) // Future
.Then(&SendToMars); // Future
}
ExploreOuterSpace().Subscribe(
[] () { std::cout << "Mission Complete!" << std::endl; });
Можно скомбинировать все три шага в новую функцию — ExploreOuterSpace. С точки зрения кода она состоит просто из цепочки вызовов Then; логика работы функции — последовательная композиция действий — помещается на один экран, её просто понять и осознать. При этом все шаги исполнения будут во времени (скорее всего) разнесены. Темпоральный характер связывания вынесен за скобки.
5.4. Any-комбинатор
Приятный бонус: если применять конструкцию с Future в среде с параллелизмом, то можно выстроить ещё более интересные комбинаторы, которых нет в однопоточном последовательном коде. Например, можем сказать, что мы бы хотели дождаться появления любого из двух значений:
template
Future Any(Future f1, Future f2) {
auto promise = NewPromise();
f1.Subscribe([promise] (const T& t) { promise.TrySet(t); });
f2.Subscribe([promise] (const T& t) { promise.TrySet(t); });
return promise.ToFuture();
} // Дождаться окончания любого вычисления
Мы создаем обещание, что в будущем посчитаем это Any-значение, и в подписке на два Future устраиваем гонку: кто первый успел, тот и молодец. То есть если в контейнере пусто, то кладем туда значение, которое появилось.
Это может понадобиться, к примеру, когда у нас есть две базы данных, и мы читаем из обеих, и смотрим, откуда быстрее пришел ответ. То есть пишем код вида «Отправить запрос в DB1, отправить запрос в DB2, и как только получили любой из ответов — делаем что-то ещё».
5.5. All-комбинатор
Симметрично можем устраивать барьеры. Если из двух баз данных мы читаем две существенно разные записи и хотим комбинировать их у себя локально, то можно один раз написать барьерную логику, создать контейнер, и заполнять его частями (пары T1 и T2), прописаться в обработчике T1 и T2 на появление значений, положить их соответствующие компоненты контейнера и завести счетчик, сколько шагов осталось.
template
Future> All(Future f1, Future f2) {
auto promise = NewPromise>();
auto result = std::make_shared< std::tuple >();
auto counter = std::make_shared< std::atomic >(2);
f1.Subscribe([promise, result, counter] (const T1& t1) {
std::get<0>(*result) = t1;
if (--(*counter) == 0) { promise.Set(*result)); }
});
f2.Subscribe([promise, result, counter] (const T2& t2) { /* аналогично */ }
return promise.ToFuture();
} // Дождаться окончания всех вычислений
Вспомним пример с nginx. Там отслеживание того, какие части обработки запросы уже закончены, был явный и привязанный к конкретному домену приложения. То есть в случае nginx были выделены стадии «разбираю заголовки», «читаю тело запроса», «пишу заголовки и ответа ответа» и так далее. В All-комбинаторе логика по отслеживанию завершенных шагов абстрагирована до подсчета того, сколько фрагментов уже закончило работу. Это позволяет схлопнуть сложность нашего приложения.
5.6. Адаптация обратного вызова
Третий плюс Future и Promises — они просто интегрируются с legacy-кодом, построенным на коллбеках. Можно элегантно подцепить существующие callback-ориентированные библиотеки в наш код, обернув их в несложную обертку, устроенную простым образом: мы создаем Future, который сразу же и возвращает, а в callback-функции заполняем Future.
// Функция вызывает cb по окончании асинхронного вычисления
void LegacyAsyncComputeStuff(std::function cb);
// Функция адаптирует старую функцию к Future
Future ModernAsyncComputeStuff()
{
auto promise = NewPromise();
LegacyAsyncComputeStuff(
[promise] (int value) { promise.Set(value); });
return promise.ToFuture();
}
Итого: мы получили простой и читаемый код, инструменты для композиции нашего кода и сохранили возможность реализовать исполнение фрагментов кода поверх Future неблокирующим образом.
Иногда возникают ситуации, когда у нас возникает понятный, но нелинейный по данным код. Рассмотрим сниппет.
Future GetRequest();
Future QueryBackend(Request req);
Future HandlePayload(Payload pld);
Future Reply(Request req, Response rsp);
// req требуется 2 раза: в QueryBackend и в Reply
GetRequest().Subscribe(
[] (Request req) {
auto rsp = QueryBackend(req)
.Then(&HandlePayload)
.Then(Bind(&Reply, req));
});
У меня есть некая обработка запроса. Я получаю структуру Request, хожу за какими-то данным в бэкэнд. Они закодированы, поэтому их нужно отдельно декодировать. А потом, чтобы прислать ответ, нужно на руках одновременно иметь и декодированные данные, и оригинальную структуру запроса. К примеру, чтобы пробросить какой-то заголовок из моего запроса в ответ.
Вроде бы, связка читаема, но выглядит не совсем аккуратно. Что делать? Типичный подход — всё рефакторить, не пробрасывать отдельно request и payload, а завести абстрактный контекст — один аргумент, который всюду будем протаскивать сквозным образом.
Например, так в Java устроена библиотека Netty. Удобно, но тогда контекст становится общей тарелкой, куда разные фрагменты кода пишут или читают значения. Сложно понять, что в этом контексте реально заполнено и когда, и что там происходит.
Если бы мы писали синхронный код, то позвали бы GetRequest, QueryBackend, HandlePayload и потом Reply от двух аргументов, если бы не было Future.
Чтобы воплотить фантазии в реальность, нужен некий метод, который принимает Future и возвращает T — назовём его WaitFor.
Future GetRequest();
Future QueryBackend(Request req);
Future HandlePayload(Payload pld);
Future Reply(Request req, Response rsp);
template T WaitFor(Future future);
// req требуется 2 раза: в QueryBackend и в Reply
GetRequest().Subscribe(
[] (Request req) {
auto rsp = QueryBackend(req)
.Then(&HandlePayload)
.Then(Bind(&Reply, req));
});
Тогда мы реформируем код таким образом:
Future GetRequest();
Future QueryBackend(Request req);
Future HandlePayload(Payload pld);
Future Reply(Request req, Response rsp);
template T WaitFor(Future future);
auto req = WaitFor(GetRequest());
auto pld = WaitFor(QueryBackend(req));
auto rsp = WaitFor(HandlePayload(pld));
WaitFor(Reply(req, rsp));
Почему стало проще: убрали обертку из Future, которую только что добавили. Код читаемый и удобный. Также теперь в нем явным образом размечены четыре точки, где мы ждем данных. Это точки разрыва нашего потока исполнения.
У нас появляется две опции. Мы в этих точках на уровне нашего приложения можем выбрать как именно мы будем связывать эти два разорванных фрагмента кода. Либо мы можем связывать а-ля уровнь 0, синхронно заблокировать наш тред через, к примеру, mutex+cvar внутри future. Либо можем поставить себе задачу сделать неблокирующее ожидание. Мы освободим квант времени в нашем приложении под другие задачи, а текущий поток исполнения заморозим.

6.1. Корутины
Это функции, в которых есть множество точек входа и выхода. Если вспомнить картинку с черными и красными кружочками, то там, где черный меняется на красный, нам надо выйти, потому что есть какие-то события, которых нужно подождать. Но если мы прерываем корутину, нам нужно выйти куда-то.
В нашем случае каждая точка ожидания — «выход» в некую сущность более высокого уровня, которая решит, какой задачей заняться далее. На уровне операционной системы это планировщик задач. У нас будет свой планировщик. Модельная имплементация: boost: asio и boost: fiber.
Чтобы переходить от текущего логического потока исполнения в планировщик, нам понадобится возможность менять контекст исполнения физического п
