Асинхронная загрузка больших датасетов в Tensorflow
Глубокие нейронные сети сейчас модная тема.
В Сети много тюториалов и видеолекций, и других материалов обсуждающих
основные принципы, архитектуру, стратегии обучения и т.д. Традиционно, обучение нейронных сетей производится путем предявления нейронной сети пакетов
изображений из обучающей выборки и коррекции коэффициентов этой сети
методом обратного распространения ошибки. Одним из
наиболее популярных инструментов для работы с нейронными сетями является
библиотека Tensorflow от Google.
Нейронная сеть в Tensorflow представляется последовательностю операций-слоев
(таких как перемножение матриц, свертка, пулинг и т.д.). Слои нейронной сети совместно
с операциями корректировки коэффициентов образуют граф вычислений.
Процесс обучения нейронной сети при этом заключается в «предъявлении» нейронной
сети пакетов объектов, сравненнии предсказанных классов с истинными, вычисления
ошибки и модификации коэффицентов нейронной сети.
При этом Tensoflow скрывает технические подробности обучения и реализацию алгоритма корректировки
коэффицентов, и с точки зрения программиста можно говорить в основном только о графе вычислений,
производящем «передсказания».
Сравните граф выченслений о котором думает программист
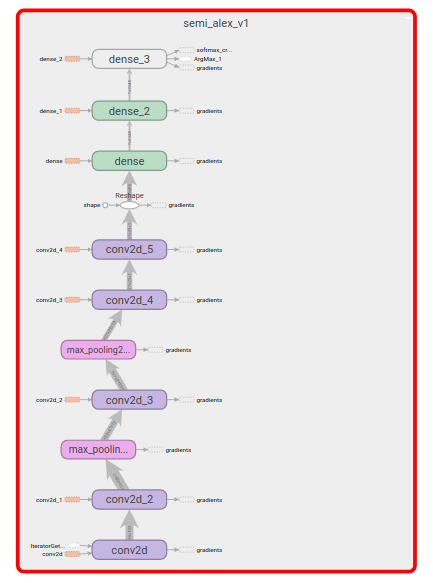
с графом который в том числе выполняет подстройку коэффициенотов
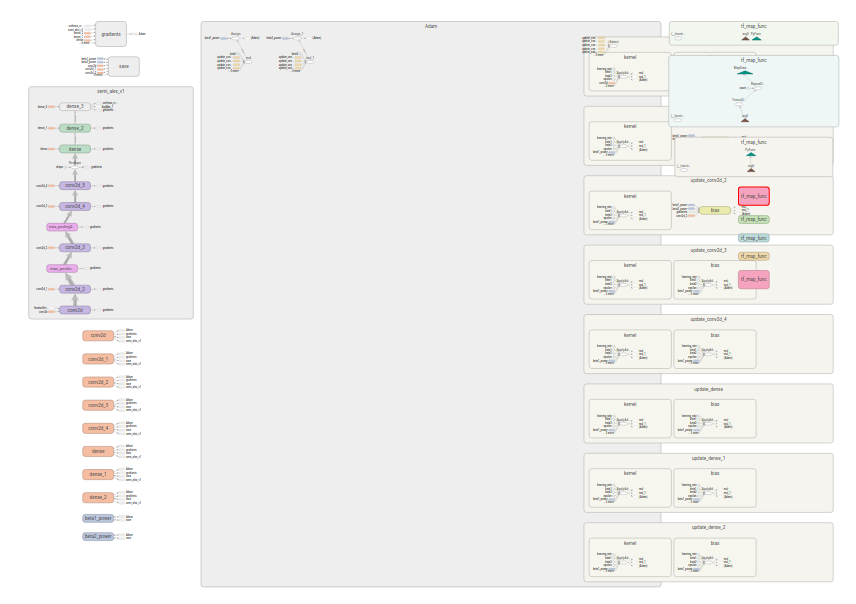 .
.
Но что Tensorflow не может сделать за программиста, так это преобразовать входной
датасет в датасет удобный для треннировки нейронной сети. Хотя библиотека имеет
представленно довольно много «базовых блоков».
Как с их использованием построить эффективный конвеер для «питания»
(англ feed) нейронной сети входными данными я и хочу расскажу в этой статье.
В качестве примера задачи будет использован датасет ImageNet
опубликованный недавно в качестве соревнования по детектированию объектов на Kaggle
Мы будем обучать сеть детектированию одного объекта, того у
которого самый большой ограничивающий прямоугольник.
Если вы еще не пробовали работать с этой библиотекой,
возможно стоит изучить основные концепции, например в статье
Библиотека глубокого обучения Tensorflow, или на официальном сайте
Подготовительные шаги
Ниже предполагается, что у вас
- установлен [Python][python_org], в примерах используется Python 2.7,
, но не должно быть сложностей с их портированием на Python 3.* - становлена библитека [Tensorflow и Python-интерфейс к ней][install_tensorflow]
- скачан и распакован [набор данных][download_dataset] из соревнования на Kaggle
Традиционные алиасы для библиотек:
import tensorflow as tf
import numpy as np
Препроцессинг данных
Для загрузки данных, мы будем использовать механизмы, предоставляемые
модулем для работы с датасетами в Tensorflow.
Для треннировки и валидации нам потребуется датасет в котором
одновременно и изображения и их описания. Но в скачаном датасете
файлы с изображениями и аннотациями аккуратно разложены по разным папочкам.
Поэтму мы сделаем итератор который итерируется по соотвествующим парам.
ANNOTATION_DIR = os.path.join("Annotations", "DET")
IMAGES_DIR = os.path.join("Data", "DET")
IMAGES_EXT = "JPEG"
def image_annotation_iterator(dataset_path, subset="train"):
"""
Yields tuples of image filename and corresponding annotation.
:param dataset_path: Path to the root of uncompressed ImageNet dataset
:param subset: one of 'train', 'val', 'test'
:return: iterator
"""
annotations_root = os.path.join(dataset_path, ANNOTATION_DIR, subset)
print annotations_root
images_root = os.path.join(dataset_path, IMAGES_DIR, subset)
print images_root
for dir_path, _, file_names in os.walk(annotations_root):
for annotation_file in file_names:
path = os.path.join(dir_path, annotation_file)
relpath = os.path.relpath(path, annotations_root)
img_path = os.path.join(
images_root,
os.path.splitext(relpath)[0] + '.' + IMAGES_EXT
)
assert os.path.isfile(img_path), \
RuntimeError("File {} doesn't exist".format(img_path))
yield img_path, pathИз этого можно уже сделать датасет и запустить «процессинг на графе»,
например извлекать имена файлов из датасета.
Создаем датасет:
files_dataset = tf.data.Dataset.from_generator(
functools.partial(image_annotation_iterator, "./ILSVRC"),
output_types=(tf.string, tf.string),
output_shapes=(tf.TensorShape([]), tf.TensorShape([]))
)Для извлечения данных из датасета нам нужен итераторmake_one_shot_iterator создаст итератор, который проходит по
данным один раз. Iterator.get_next() создает тензор в вкоторый загружаются
данне из итератора.
iterator = files_dataset.make_one_shot_iterator()
next_elem = iterator.get_next()Теперь можно создать сессию и ее «вычислить значения» тензора:
with tf.Session() as sess:
for i in range(10):
element = sess.run(next_elem)
print i, elementНо нам для использования в нейронных сетях нужны не имена файлов, а изображения
в виде «трехслойных» матриц одинаковой формы и категории этих изображений в виде
«one hot»-вектора
Кодируем категории изображений
Разбор файлов аннотаций, не очень инетересен сам по себе. Я использовал для
этого пакет BeautifulSoup. Вспомогательный класс Annotation
умеет инициализироваться из пути к файлу и хранить список объектов.
Для начала нам надо собрать список категорий, чтобы знать размер вектора для
кодирования cat_max. А так же сделать отображение строковых
категорий в номер из [0..cat_max]. Создание таких отображений тоже не очень
интрерсно, дальше будем считать что словари cat2id и id2cat содержат
прямое и обратное отображение описнное выше.
Функция преобразования имени файла в закодированный векто категорий.
Видно что добавляется еще одна категория, для фона: на некоторых изображений
не отмечен ни один объект.
def ann_file2one_hot(ann_file):
annotation = reader.Annotation("unused", ann_file)
category = annotation.main_object().cls
result = np.zeros(len(cat2id) + 1)
result[cat2id.get(category, len(cat2id))] = 1
return resultПрименим преобразование к датасету:
dataset = file_dataset.map(
lambda img_file_tensor, ann_file_tensor:
(img_file_tensor, tf.py_func(ann_file2one_hot, [ann_file_tensor], tf.float64))
)Метод map возвращает новый датасет, в котором к каждомй строчке изначального
датасета применена функция. Функция на самом деле не приеняется, пока мы
не начали итерироваться по результирующему датасету.
Так же можно заметить, что мы завернули нашу функцию в tf.py_func нужно это
т.к. в качестве параметров в функцию преобразования попадают тензоры, а не
те значения, которые в них лежат.
И чтобы работать со стороками нужна эта обретка.
Загружаем изображение
В Tensorflow есть богатая библиотека для работы с изображениями.
Воспользуемся ею для их загрузки. Нам нужно: прочитать файл, декодировать его
в матрицу, привести матрицу к стандартному размеру (например среднему),
нормализовать значения
в этой матрице.
def image_parser(file_name):
image_data = tf.read_file(file_name)
image_parsed = tf.image.decode_jpeg(image_data, channels=3)
image_parsed = tf.image.resize_image_with_crop_or_pad(image_parsed, 482, 415)
image_parsed = tf.cast(image_parsed, dtype=tf.float16)
image_parsed = tf.image.per_image_standardization(image_parsed)
return image_parsedВ отличие от предыдущей функции, здесь file_name это тензор, а значит
нам не надо эту функцию заворачивать, добавим ее в предыдущий сниппет:
dataset = file_dataset.map(
lambda img_file_tensor, ann_file_tensor:
(
image_parser(img_file_tensor),
tf.py_func(ann_file2one_hot, [ann_file_tensor], tf.float64)
)
)Проверим что наш граф вычеслений призводит что-то осмысленное:
iterator = dataset.make_one_shot_iterator()
next_elem = iterator.get_next()
print type(next_elem[0])
with tf.Session() as sess:
for i in range(3):
element = sess.run(next_elem)
print i, element[0].shape, element[1].shapeДолжно получиться:
0 (482, 415, 3) (201,)
1 (482, 415, 3) (201,)
2 (482, 415, 3) (201,)Как правило в самом начале следовало бы разделить датасет на 2 или 3 части для
треннировки/валидации/тестирования. Мы же воспользуемся разделением на
тренировочный и валидационный датасет из скачанного архива.
Конструирование графа вычислений
Мы будем треннировать сверточную нейронную сеть (англ. convolutional neural netwrok, CNN)
методом похожим на стохастический градиентный спуск, но будем использовать
улучшеную его версию Adam. Для этого нам надо объединить
наши экземпляры в «пакеты» (англ. batch). Кроме того чтобы утилизировать
многопроцессорность (а в лучшем случае наличие GPU для обучения) можно включить
фоновую подкачку данных
BATCH_SIZE = 16
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(2) Будем объдинять в пакеты по BATCH_SIZE экземпляров и подкачивать 2 таких пакета.
В ходе обучения мы хотим переодически прогонять валидацию, на выборке, которая не учасвует в
обучени. А значит нам надо повторить все манипуляции выше для еще одного датасета.
К счастью всех их можно объединить в функцию например dataset_from_file_iterator и создать два
датасета:
train_dataset = dataset_from_file_iterator(
functools.partial(image_annotation_iterator, "./ILSVRC", subset="train"),
cat2id,
BATCH_SIZE
)
valid_dataset = ... # то же самое только subset="val"Но так как мы хотим дальше использовать один и тот же граф вычислений для тренировки и валидации,
мы создадим более гибкий итератор. Такой который позволяет его переинициализировать.
iterator = tf.data.Iterator.from_structure(
train_dataset.output_types,
train_dataset.output_shapes
)
train_initializer_op = iterator.make_initializer(train_dataset)
valid_initializer_op = iterator.make_initializer(valid_dataset)Позже «выполнив» ту или иную операцию мы сможем переключать итератор с одного датасета на
другой.
with tf.Session(config=config, graph=graph) as sess:
sess.run(train_initialize_op)
# Треннируем
# ...
sess.run(valid_initialize_op)
# валидируем
# ...Для тепреь нам нужно описать нашу нейронную сеть, но не будем углубляться в этот вопрос.
Будем считать что функция semi_alex_net_v1(mages_batch, num_labels) строит нужную архитекутуру и
возвращает тензор с выходными значениями, предсказанными нейронной сетью.
Зададим функцию ошибки, и тончности, операцию оптимизации:
img_batch, label_batch = iterator.get_next()
logits = semi_alexnet_v1.semi_alexnet_v1(img_batch, len(cat2id))
loss = tf.losses.softmax_cross_entropy(
logits=logits, onehot_labels=label_batch)
labels = tf.argmax(label_batch, axis=1)
predictions = tf.argmax(logits, axis=1)
correct_predictions = tf.reduce_sum(tf.to_float(tf.equal(labels, predictions)))
optimizer = tf.train.AdamOptimizer().minimize(loss)
Цикл тренировки и валидации
Теперь можно приступить к обучению:
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
sess.run(train_initializer_op)
counter = tqdm()
total = 0.
correct = 0.
try:
while True:
opt, l, correct_batch = sess.run([optimizer, loss, correct_predictions])
total += BATCH_SIZE
correct += correct_batch
counter.set_postfix({
"loss": "{:.6}".format(l),
"accuracy": correct/total
})
counter.update(BATCH_SIZE)
except tf.errors.OutOfRangeError:
print "Finished training"
Выше мы создаем сессию, инициализируем глобальные и локальные переменные в графе, инициализируем
итератор тренировочными данными. [tqdm][tgdm] не относится к процессу обучения, это просто
удобный инструмент визуализации прогресса.
В контексте той же сессии запускаем и валидацию: цикл валидации выглядит очень похоже. Основная
разница: не запускается операция оптимизации.
with tf.Session() as sess:
# Train
# ...
# Validate
counter = tqdm()
sess.run(valid_initializer_op)
total = 0.
correct = 0.
try:
while True:
l, correct_batch = sess.run([loss, correct_predictions])
total += BATCH_SIZE
correct += correct_batch
counter.set_postfix({
"loss": "{:.6}".format(l),
"valid accuracy": correct/total
})
counter.update(BATCH_SIZE)
except tf.errors.OutOfRangeError:
print "Finished validation"Эпохи и чекпойнты
Одного простого прохода по всем изображениям конечно же не достаточно для треннировки. И нужно
код треннировки и валидации выше выполнять в цикле (внутри одной сессии).
Выполнять либо фиксированное число итераций, либо пока обучение помогает. Один проход по всему
набору данных традиционно называется эпохой (англ. epoch).
На случай непредвиденных остановок обучения и для дальнейшего использования модели, нужно ее
сохранять. Для этого при создании графа выполнения нужно создать объект класса Saver. А в ходе
тренировки сохранять сотояние модели.
# создаем граф
# ...
saver = tf.train.Saver()
# Создаем сессию
with tf.Session() as sess:
for i in range(EPOCHS):
# Train
# ...
# Validate
# ...
saver.save(sess, "checkpoint/name")
Что дальше
Мы научились создавать датасеты, преобразовывать их с использованием функций работы с
тензорами, а так же обычными функциями написанными на питоне. Научились загружать изображения
в фоновом цикле не пытаясь загрузить их в память или сохранить в разжатом виде.
Так же научились сохранять обученную модель.
Применив часть шагов из описанных выше и загрузив ее можно сделать программу
которая будет распознавать изображения.
В статье совершенно не раскрывается тем нейронных сетей как таковых, их архитектуре и методов
обучение. Для тех кто хочет в этом разобрраться могу порекомендвать курс
Deep Learning by Google на Udacity, он подойдет в том числе и совсем
новичкам, без серьёзного бэкграунда. Про применение сверточных нейронных сетей для распознавания
есть отличный курс лекций Convolutional Neural Networks for Visual Recognition
от Стэнфордского университета. Так же стоит посмотреть на курсы специализации
Deep Learning на Сoursera. Так же есть довольно много материалов на Хабрахабр,
например неплохой обзор библиотеки Tensorflow от Open Data Science.
