Архитектура процессора Эльбрус: стоит ли все это своих денег?

В России всего несколько компаний, занимающихся разработкой процессоров. Одна из этих компаний — МЦСТ с процессорами «Эльбрус». В целом, МЦСТ делает акцент на том, что их процессоры — российские, и государство всячески помогает ей. Во-первых, государство является основным потребителем «Эльбруса», поскольку обычному потребителю такой процессор на данный момент не нужен. А во-вторых, государство выдает субсидии на проекты МЦСТ и принимает инициативы, упрощающие деятельность этой компании В этой статье пойдет речь о семействе процессоров «Эльбрус» и о том, что они могут предложить вместо процессоров из-за «бугра».
Процессоры «Эльбрус»
Советский период
В конце 60-х годов 20-го века в СССР была принята государственная директива, которая обозначала дальнейший вектор развития компьютеростроения СССР как копирование наработок западных коллег, в частности компьютера IBM S/360. В целом, многие советские инженеры, в том числе и отец советской кибернетики Сергей Лебедев, отзывались скептически о таком решении. По мнению Лебедева, путь копирования по определению является дорогой отстающих. Но других вариантов никто не видел или не хотел видеть.

Сергей Алексеевич Лебедев
Если большинство советских разработок не избежало влияния данной директивы, то компьютеру «Эльбрус-1» повезло. Его можно назвать оригинальной разработкой советских ученых. В 1969 году перед инженерами была поставлена задача создать ЭВМ с производительностью 100 миллионов операций в секунду. Поскольку подобный проект диктовался военными целями, а именно гонкой вооружения, на первый план выходили вопросы отказоустойчивости и непрерывной работы системы. Как итог, «Эльбрус-1» приобрел многопроцессорность и средства распараллеливания задач. Работа над «Эльбрус-1» шла в течение 6 лет, с 1973 по 1979, а в 1980 году проект был сдан государственной комиссии. Итоговый вариант обладал производительностью в 15 миллионов операций в секунду, ОЗУ в 64 МБ и поддерживал одновременную работу до 10 процессоров.

Эльбрус-1
Идущее семимильными шагами развитие компьютеростроения привело к появлению в 1985 году ЭВМ «Эльбрус-2». Этот суперкомпьютер был на порядок мощнее — 125 миллионов операций в секунду. Всего было выпущено до 200 этих машин, некоторые из которых используются и по сей день, например в системах противоракетной обороны.

Компоненты Эльбрус-2
Помимо суперкомпьютеров, также была разработана ЭВМ общего назначения — «Эльбрус 1-КБ». КБшка создавалась для замены устаревшего «БЭСМ-6». В ней была реализована программная совместимость с «БЭСМ-6». Производительность новой ЭВМ составляла 2.5–3 миллиона операций в секунду.

Эльбрус 1-КБ
После выпуска «Эльбрус-2» началась работа над последней ЭВМ семейства — «Эльбрус-3». Под руководством Бориса Бабаяна к 1991 году работа над новой ЭВМ была закончена. Машина обладала производительностью до 1 миллиарда операций в секунду вкупе с 16 процессорами, но вышла чересчур громоздкой. Из-за своих недостатков, а также исторического и экономического контекста того периода, «Эльбрус-3» в серийное производство не попал, но заложенные в него идеи повлияли на современное поколение «Эльбрусов».
МЦСТ — эпоха современной России
После распада СССР на основе коллектива, работавшего над «Эльбрус-3», было основано ТОО «Московский центр SPARK технологий» или просто МЦСТ. Поработав некоторое время с американской компанией Sun Microsystems, ныне поглощенной Oracle, и набравшись опыта и знаний, МЦСТ решает создать процессор, основанный на идеях «Эльбрус-3». 25 февраля 1999 года Борис Бабаян (тот самый, работавший над «Эльбрус-3») на конференции Microprocessor Forum объявил о том, что его компания (МЦСТ) разработала микропроцессор «Эльбрус-2000», который по всем параметрам опережает хваленый Itanium.

Здесь стоит сделать отступление и подробнее описать Itanium. В 1989 году небезызвестная компания Intel объединила свои силы с небезызвестной компанией HP для создания процессора нового поколения — Itanium. По задумке, Itanium должен был реализовывать все самые крутые наработки того времени и стать «королём» среди процессоров. Ожидалось, что этот процессор будет доминировать на многих рынках. Ожидаемая тактовая частота составляла 800 МГц на архитектуре IA-64. Забегая вперед, стоит сказать, что процессор встретили достаточно прохладно на фоне успехов архитектуры x86.

Так или иначе, подобные заявления шокировали публику — каким образом малоизвестная компания разработала процессор круче, чем у Intel? Обещанный процессор обладал частотой в 1,2 ГГЦ, а производительность равнялась 8,9 миллиардам операций в секунду. Даже по физическим параметрам заявленный «Эльбрус» превосходил Itanium — площадь кристалла составляла 126 мм2против 300 мм2и тепловыделение 35 вт против 60 вт. И вишенкой на торте стала озвученная Бабаяном необходимая сумма для выпуска пробной партии — 60 миллионов долларов. Вкупе с тем, что никаких наработок показано не было, потенциальные инвесторы не решились вкладываться в «бумажный» флагман МЦСТ.

В 2001 году на свет выходит Itanium, который, как упоминалось выше, встречают не шибко радостно. Казалось, вот он момент, когда можно показать западным корпорациям кузькину мать. В 2002 году в интервью журналу ExtremeTech Бабаян ещё сильнее завысил планку ожидания, заявив, что процессор будет иметь тактовую частоту в 3 ГГЦ, но и сумма, необходимая для начала производства, увеличилась до рекордных 100 миллионов долларов.
Но озвученные параметры не были достигнуты. В июле 2008 года процессор «Эльбрус 2000» или «Эльбрус-3М» показали публике. Он обладал частотой в 300 МГц и в сравнительных тестах обгонял 500 МГц Pentium 3, вышедший в 1999 году. Следующие процессоры семейства «Эльбрус» развивают и совершенствуют процессор «Эльбрус 2000». Ниже представлена информация обо всех процессорах семейства «Эльбрус»:
«Эльбрус 2000»

«Эльбрус-S»

«Эльбрус-2C+»

«Эльбрус-4C»

«Эльбрус-1C+»

«Эльбрус-8C»

«Эльбрус-8CB»

На данный момент основной потребитель процессоров «Эльбрус» — государство. Оно как субсидирует проекты МЦСТ, так и является основным заказчиком. МЦСТ позиционирует семейство «Эльбрус» как мощное серверное железо, что соотносится с муниципальными потребностями на обработку большого количества информации. Со слов представителей МЦСТ они поставляют процессоры только для юридических лиц, поэтому оборот у компании относительно небольшой, что негативно влияет на стоимость одного процессора. Так, по некоторым данным, стоимость «Эльбрус-4C» достигала 400 тысяч рублей.

Источник — mcst.ru
Архитектура «Эльбрус»
Прежде всего стоит сказать, что архитектура «Эльбрус» — оригинальная российская разработка. И хоть флагманы семейства с техпроцессом 28 нм в данный момент изготавливаются на тайваньских заводах, это все же лучше, чем ничего. По заявлениям разработчиков из МЦСТ, основное преимущество Эльбрусов заключается в энергоэффективности и программно-управляемом параллелизме операций. Наверняка, те, кто интересовались темой, слышали об оптимизирующем компиляторе и «широких командах». Чтобы понять, в чем суть, разберемся с существующими путями ускорения исполнения команд в микропроцессорах.
Суперскалярные и VLIW процессоры
Простейший скалярный процессор умеет выполнять одну машинную команду за такт. Команды выстроены в цепочку, порядок которой задан в машинном коде. При этом следующая команда не начинает выполняться, пока не закончится старая. Такой подход оправдан, когда следующая команда использует результаты предыдущей. Но это совершенно необязательно: команды могут быть независимыми. Поэтому разработчики микропроцессоров стали думать о том, как ускорить исполнение команд. В результате было выработано два основных подхода.
В первом используется разбиение команды на несколько последовательных стадий: прочитать команду из памяти, декодировать её, прочитать параметры этой команды, отправить на исполнительное устройство, результат команды записать в регистр назначения. При разбитии команды на несколько разных стадий можно запускать следующую команду до того, как закончилась предыдущая. Такой подход называется конвейеризация, по аналогии с промышленным производством.
Второй путь подразумевает обнаружение в последовательности команд тех, что не пересекаются по аргументам и результатам (по используемым и определяемым ресурсам). Такую группу можно запускать на исполнение одновременно, отсюда и название подхода — параллельная группировка команд.
Если немного подумать и сопоставить описанные подходы, то можно обнаружить, что они не противоречат друг другу. Архитектуры микропроцессоров, объединяющие эти принципы, называются in-order superscalar. В 60-е годы был реализован следующий шаг — изменение последовательности команд относительно друг друга прямо в процессе исполнения. Такой подход называется out-of-order superscalar (OOOSS). Большинство современных представителей архитектур типа RISC и CISC (x86, PowerPC, SPARC, MIPS, ARM) являются OOOSS. Ниже показана эволюция подходов к параллельному исполнению множества инструкций.
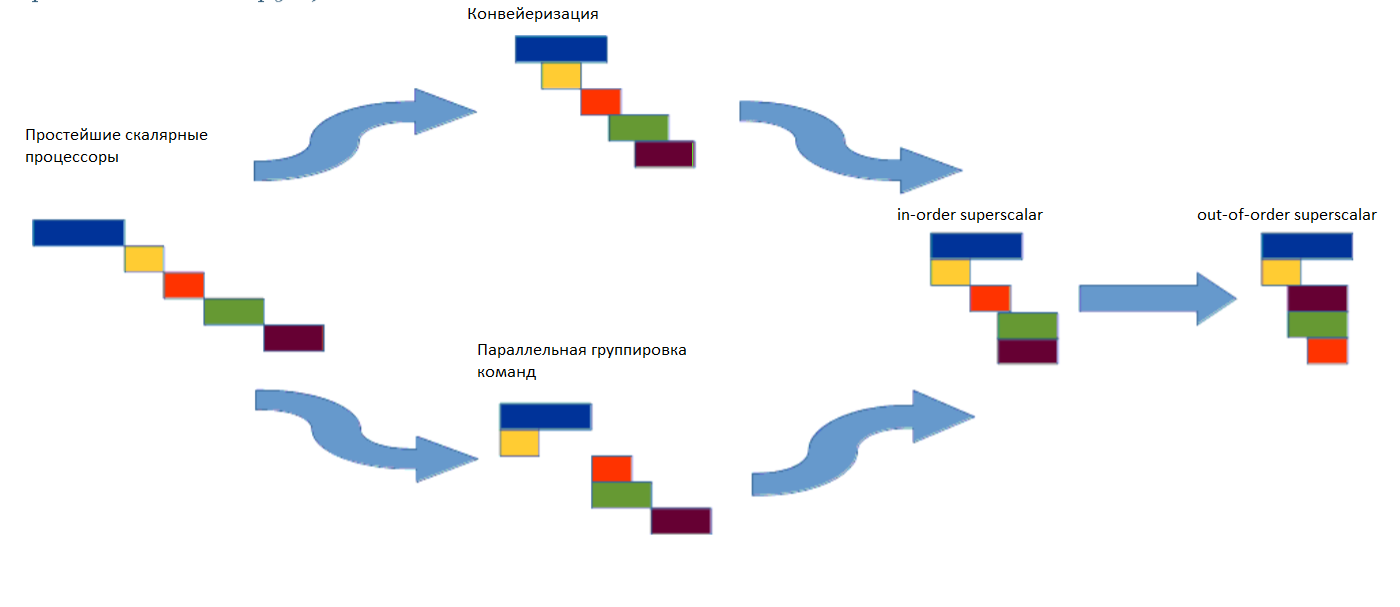
Переход от скалярных процессоров к суперскалярным с возможностью перестановки инструкций
В 80-е годы начала развиваться альтернативная архитектура процессоров. Их главной отличительной особенностью стало переупорядочивание команд не во время исполнения, а во время компиляции программы. Так же ключевой характеристикой являлось использование так называемых широких команд, которые позволяли выразить параллельность множества операций в ассемблере (это и есть программно-управляемый параллелизм операций, о котором говорилось в начале раздела). Такая архитектура называется VLIW (very long instruction word) — «очень длинная машинная команда». Именно к такому типу и относится «Эльбрус».
О «широкой команде»
В традиционных RISC и CISC ответственность за анализ зависимостей, планирование, распределение регистров лежит на аппаратной части. В Эльбрусах же эту работу выполняет компилятор. Соответственно процессору на вход поступают «широкие команды», в каждой из которых закодированы операции для всех исполнительных устройств процессора, которые должны быть запущены на данном такте. Это существенно упрощает аппаратуру, так как процессору не нужно анализировать зависимости между операндами или переставлять операции между широкими командами: все это сделает компилятор, планируя операции на основе ресурсов широкой команды. Посмотрим на структуру широкой команды.
Под широкой командой понимается набор элементарных операций Эльбрус, которые могут быть запущены на исполнение в одном такте. С точки зрения исполнительных устройств в широкой команде доступны:
- 6 арифметико-логических устройств (АЛУ), исполняющих следующие операции:
- 1 устройство для операции передачи управления (CT);
- 3 устройства для операций над предикатами (PL);
- 6 квалифицирующих предикатов (QP);
- 4 устройства для команд асинхронного чтения данных по регулярным адресам в цикле (APB);
- 4 литерала размером 32 бита для хранения константных значений (LIT);

Широкая команда «Эльбрус»
Средняя степень наполнения широкой команды полезными операциями в значительной степени отражает производительность процессора. Можно сказать, что задачей повышения производительности кода на архитектурах VLIW является статическое (во время компиляции) обнаружение параллелизма на уровне операций, планирование операций с учетом найденного параллелизма, обеспечение хорошего наполнения широкой команды полезными операциями и проведение различных оптимизаций.
Особенности архитектуры
Регистровый файл. Для параллельного выполнения операций требуется значительное число оперативных регистров. Так называемый регистровый файл содержит 256 регистров для целочисленных и вещественных данных, 32 из них предназначены для глобальных данных, остальные 224 — для стека процедур
Также в системе присутствует 32 двухразрядных регистров-предикатов, составляющих предикатный файл. Над предикатными регистрами выполняет операции предикатное устройство, причем длительность операции составляет половину такта. Поэтому в одном такте можно планировать логические операции, где вторая группа использует результаты первой.
Для ускорения программы можно выполнять операции раньше, чем становится известно направление условного перехода, или считывать данные из памяти раньше предшествующей записи. Но такие способы не всегда корректны, так как возможно недетерминированное поведение при исполнении. Например, в случае выполнения раньше условного перехода, операция, которая не должна выполняться, может вызвать прерывание. А при выполнении чтения раньше предшествующей записи из памяти может быть считано неправильное значение. Для таких ситуаций в архитектуру введены режимы спекулятивности по управлению и спекулятивности по данным.
Предварительная передача управления. Предварительная подкачка кода в направлении ветвления, а также его первичная обработка на дополнительном конвейере (на фоне выполнения основной ветви) скрывают задержку по доступу к коду программы при передачах управления. Тем самым возможна передача управления без остановки конвейера выполнения, когда уже известно условие ветвления.
Пользуясь механизмом предикатного и спекулятивного исполнения операций, можно планировать в одной широкой команде операции, относящиеся к различным ветвям управления, избавляться от дорогостоящих операций перехода и переносить арифметико-логические операции через операции перехода.
Также возможна программная конвейеризация циклов, позволяющая наиболее эффективно исполнять циклы с независимыми или слабо зависимыми итерациями. В программно-конвейеризированном цикле последовательные итерации выполняются с наложением — одна или несколько следующих итераций начинают выполняться раньше, чем заканчивается текущая. Шаг, с которым накладываются итерации, определяет общий темп их выполнения, и этот темп может быть существенно выше, чем при строго последовательном исполнении итераций. Такой способ организации выполнения цикла позволяет хорошо использовать ресурсы широкой команды и получать преимущество в производительности.
Асинхронный доступ к массивам позволяет независимо от исполнения команд основного потока буферизовать данные из памяти. Запросы к данным должны формироваться в цикле, а адреса линейно зависеть от номера итерации. Асинхронный доступ реализован в виде независимого дополнительного цикла, в котором кодируются только операции подкачки данных из памяти в FIFO-буфера. Из буфера данные забираются операциями основного цикла. Длина буфера и асинхронность независимого цикла позволяют устранить блокировки по считыванию данных в основном потоке исполнения.
Сравнение VLIW и OOOSS. Преимущества и недостатки
Кратко опишем главные отличия VLIW и OOOSS
VLIW:
- Явно выраженный в коде параллелизм исполнения элементарных операций.
- Точное последовательно исполнение широких команд.
- Особая роль оптимизирующей компиляции.
- Дополнительные архитектурные решения для повышения параллелизма операций.
OOOSS:
- Перестановка и параллельное исполнение операций обеспечивается аппаратно в пределах окна исполняемых в данный момент операций.
- Для переупорядочивания используются скрытые буфера, скрытый регистровый файл, неявная спекулятивность.
- Достаточно большое окно для поиска параллелизма в перестановки инструкций обеспечивается аппаратным предсказателем переходов.
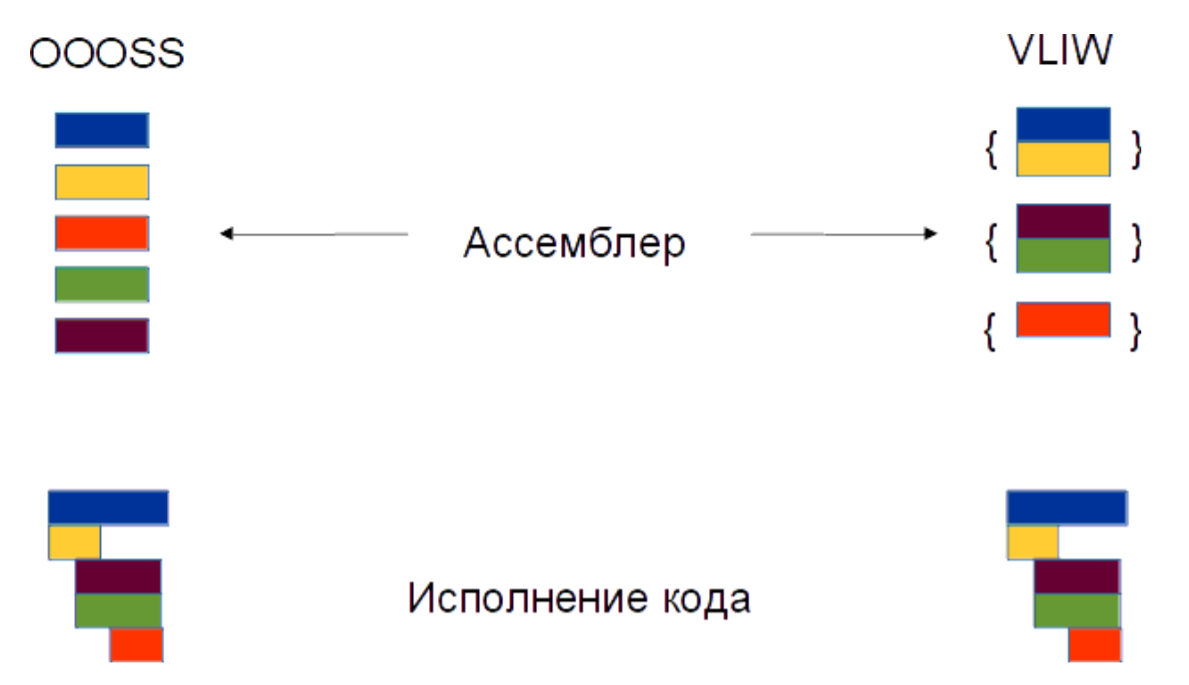
Исполнение кода в OOOSS и VLIW. Красная команда зависит от желтой и требует ей завершения, при этом коричневая и зеленая операция не зависят от желтой, поэтому их можно выполнять раньше.
Преимущества и недостатки VLIW
Преимущества и недостатки OOOSS:
В чем проблема сразу перейти на техпроцесс, как у Apple, AMD или Intel?
Процессоры «Эльбрус» производятся на тех же фабриках в Тайване, что и Apple или AMD. Почему нельзя сразу реализовать такой же техпроцесс, как и у этих компаний? Основная проблема заключается в том, что соответствующей технологии у МЦСТ на данный момент нет. Причина первая: никакая передовая компания не продаст технологию изготовления процессоров на 5 нм или 7 нм. Также производители четко следят за тем, чтобы их технологию было невозможно украсть. Причина вторая: бюджет. Разработка процессора происходит под конкретную фабрику на её лицензированном софте. Причем чем меньше техпроцесс, тем больше стоимость лицензии. А с бюджетом у МЦСТ не то, чтобы проблемы, но в золоте тоже не купаются. И это только один из экономических аспектов разработки процессора. И третья причина: для того, чтобы создать хороший процессор, основанный на технологии 5 нм или 7 нм, необходимо пройти все этапы развития: 65 нм, 40 нм, 28 нм и так далее. Конечно, можно было бы сразу сделать процессор на технологии 7 нм, однако полученный продукт не будет отличаться хорошей производительностью и вряд ли сможет стать конкурентоспособным.
Cloud VPS с быстрыми NVMе-дисками и посуточной оплатой у хостинга Маклауд.

