Архитектура хранения данных в Facetz.DCA

Что такое Facetz.DCA?
Facetz.DCA относится к компонентам programmatic-инфраструктуры, которые носят название DMP — Data Management Platform (Платформа обработки пользовательских данных). Задача DMP — имея информацию об активности пользователя построить его «тематический портрет» — множество интересов. Данный процесс называется сегментацией. Например, зная, что человек часто посещает сайты о рыбалке, можно сделать вывод о том, что он заядлый рыболов. Результат — сегменты пользователя, впоследствии могут использоваться для показа наиболее релевантных рекламных объявлений. В упрощенном виде схема работы DMP выглядит так: данные о пользовательской активности поступают в систему, она анализирует пользователей и возвращает по id множество сегментов.

Facetz.DCA хранит данные об активности более 600 млн. анонимизированных пользователей и отдает интересы пользователя в среднем менее, чем за 10 мс. Необходимость в такой высокой скорости диктуется процессом показа рекламы по технологии Real Time Bidding — ответ на запрос о показе должен быть дан в течение 50 мс.
При построении архитектуры хранения данных в DMP решаются две задачи: хранение информации о пользователях для последующего анализа и хранение результатов анализа. Решение первой должно обеспечивать высокую пропускную способность при доступе к данным — истории пользовательской активности. Вторая задача требует обеспечить минимальные задержки, те самые 10 мс. Оба решения должны быть хорошо горизонтально масштабируемы.
Хранение сырых данных
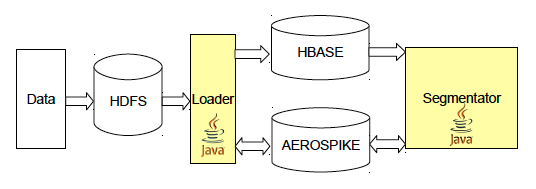
В Facetz.DCA в сутки поступают несколько терабайт логов, для их хранения мы используем распределенную файловую систему HDFS. Обработка данных происходит с использованием парадигмы MapReduce. Доступ к сырым данным организован через Apache Hive — библиотеку, транслирующую SQL-запросы в MapReduce задачи. Более подробно об этих технологиях можно прочитать в наших статьях — этой и этой.
Хранения профилей пользователей
В Facetz для хранения данных об активности пользователей используется Apache HBase. Информация о посещенных сайтах попадает туда через Map-Reduce сервис Loader, читающий сырые логи с HDFS, а также потоково через Kafka. В HBase данные хранятся в таблицах, ключом является id пользователя, колонки — различные виды фактов, например url посещенной страницы, ее название, useragent или ip-адрес. Колонки объединены в семейства — Column Family, данные из одной Column Family хранятся рядом, что увеличивает скорость выполнения GET-запросов, содержащих данные из нескольких колонок внутри одного семейства. Для каждой ячейки хранится множество версий, в нашей системы роль версии играет время события. Подробнее про Apache HBase Вы можете прочитать в этой статье.
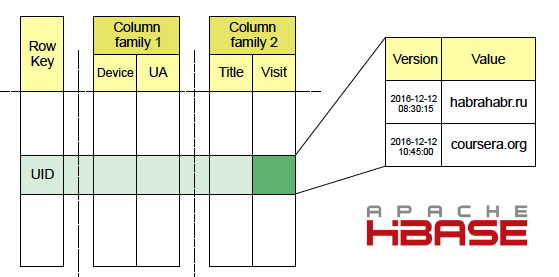
В нашем проекте используются как offline, так и realtime сегментация пользователей, что обуславливает два различных паттерна доступа к данным в HBase. Offline сегментация происходит один раз в сутки, в процессе мы проводим полный SCAN HBase-таблицы. Realtime стартует сразу после того, как новый факт о пользователе попадает в базу. Таким образом можно с минимальной задержкой видеть изменение интересов активных пользователей. При realtime сегментации используются GET-запросы в HBase. Для старта мы используем механизм триггеров на уровне БД — coprocessor в терминологии HBase. Он срабатывает при записи новых данных в HBase через операции PUT и BulkLoad. Для обеспечения максимальной скорости работы с данными в HBase у нас используются сервера с SSD дисками.
Хранение результатов сегментации пользователей
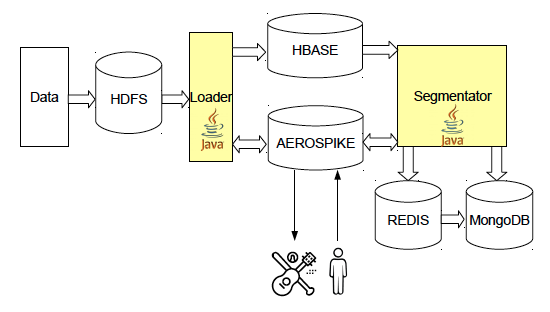
После того, как пользователь был проанализирован, результаты кладутся в отдельную базу для последующего использования. Хранилище должно обеспечивать высокую скорость как записи, так и отдачи данных, объемы которых составляют несколько терабайт — столько занимает общий объем сегментов всех пользователей. Для этих целей мы используем Aerospike — распределенное key-value хранилище, разработанное специально под SSD-диски. Эта СУБД является во многом уникальным продуктом, и одними из наиболее частых ее пользователей являются продукты в сфере programmatic. Среди других возможностей Aerospike стоит отметить поддержку UDF-функций на LUA и возможность (при помощи дополнительной библиотеки) запускать поверх базы Hadoop задачи.
Подсчет числа уникальных пользователей в сегменте
В процессе анализа DMP подсчитывает количество пользователей в каждом сегменте. Более сложной задачей является определение размеров объединений или пересечений, например, количество беременных женщин в Твери можно посчитать как объем пересечения сегментов «беременные женщины» и «живут в Твери». А число пользователей, обладающих автомобилем Нива и живущих в Вологде или Рязани, как объем пересечения сегмента «владельцы Нивы» с объединением «живут в Вологде» и «живут в Рязани». Одним из основных применений этой информации является прогнозирование охвата рекламной кампании.
Для подсчета объемов сегментов мы используем структуру данных HyperLogLog, которая реализована в key-value хранилище Redis. HLL — вероятностная структура данных, позволяющая определять количество уникальных объектов в множестве с небольшой (~0.81%) погрешностью, при этом занимающая достаточно малое количество памяти, в наших задачах это максимум 16 КБ на ключ. Отличительной особенностью HLL является возможножность подсчета числа уникальных объектов в объединении нескольких множеств без появления дополнительной ошибки. К несчастью, работа с пересечениями множеств в HLL сложнее: формула включений — исключений дает очень высокую погрешность в случае большой разницы между объемами множеств, для увеличения точности часто используют MinHash, но это требует специальных доработок и все равно дает достаточно большую ошибку. Еще одной проблемой HLL является то, что ее не всегда удобно использовать в redis-cluster, т.к. без дополнительного копирования данных можно объединять только ключи, находящиеся на одной и той же ноде. Помимо HLL мы используем Redis и для хранения счетчиков, например, числа посещений сайтов в день. Эти данные позволяют нам подсчитывать аффинитивность рекламных площадок.
Хранилище настроек и статистики
Для хранения конфигураций сервисов, статистических данных и различной мета-информации мы используем MongoDB. В формате Json удобно хранить сложные объекты, а отсутствие схемы данных позволяет легко модифицировать структуру. По факту, мы используем
лишь малую часть возможностей этой базы, которая во многих проектах используется в качестве основного хранилища.
Планы на будущее
Касательно архитектуры хранения на данный момент основным планом является улучшение качества подсчета объемов сегментов пользователей, здесь мы смотрим в сторону ClickHouse и Cloudera Impala. Обе эти базы данных позволяют проводить быстрый подсчет приблизительного количества уникальных объектов в множестве.
Резюме
NoSQL — базы данных отлично показывают себя в качестве хранилища при построении проектов сфере в онлайн рекламе. Они хорошо масштабируются и при этом позволяют обеспечить высокую скорость доступа к данным. К сожалению, не всегда можно, используя только одну технологию, решить все поставленные задачи, в Facetz.DCA мы успешно используем сразу несколько NoSQL баз данных.
