Application Insights. Про аналитику и другие новые инструменты
В этой статье я проведу еще один обзор AI, с учетом новых дополнений, и поделюсь опытом его использования на реальных проектах.
Начну с того, что я работаю в Лаборатории Касперского, в команде, которая занимается разработкой .NET сервисов. В основном в качестве хостинга мы используем облачные платформы Azure и Amazon. Наши сервисы обрабатывают довольно высокую нагрузку от миллионов пользователей и обеспечивают высокую производительность. Нам важно поддерживать хорошую репутацию сервисов, для достижения которой надо очень быстро реагировать на проблемы и находить узкие места, которые могут повлиять на производительность. Подобные проблемы могут возникать при генерации аномально высокой нагрузки или же неспецифичной пользовательской активности, различных отказах инфраструктурных (например, БД) или внешних сервисов, также никто не отменял и банальные баги в логике сервисов.
Мы пробовали использовать различные системы диагностики, но на данный момент AI показал себя как наиболее простой и гибкий инструмент для сбора и анализа телеметрии.
AI — это кроссплатформенный инструмент для сбора и визуализации диагностической телеметрии. Если у вас, например, .NET приложение, то для подключения AI вам достаточно создать контейнер AI на портале Microsoft Azure, после этого подключить к приложению nugget пакет ApplicationInsigts.
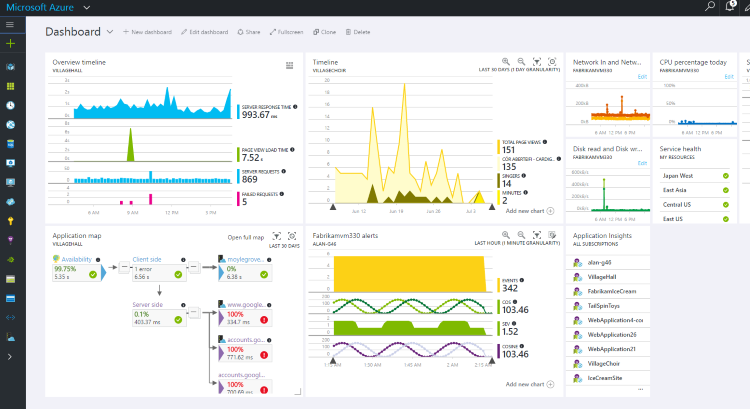
Буквально из коробки AI начнет собирать информацию по основным счетчикам производительности машины (память, процессор), на которой работает ваше приложение.
Подобную серверную телеметрию можно начать собирать и без модификации кода приложения: для этого достаточно на машину установить специальный диагностический агент. Cписок собираемых счетчиков может быть изменён правкой файла ApplicationInsights.config.
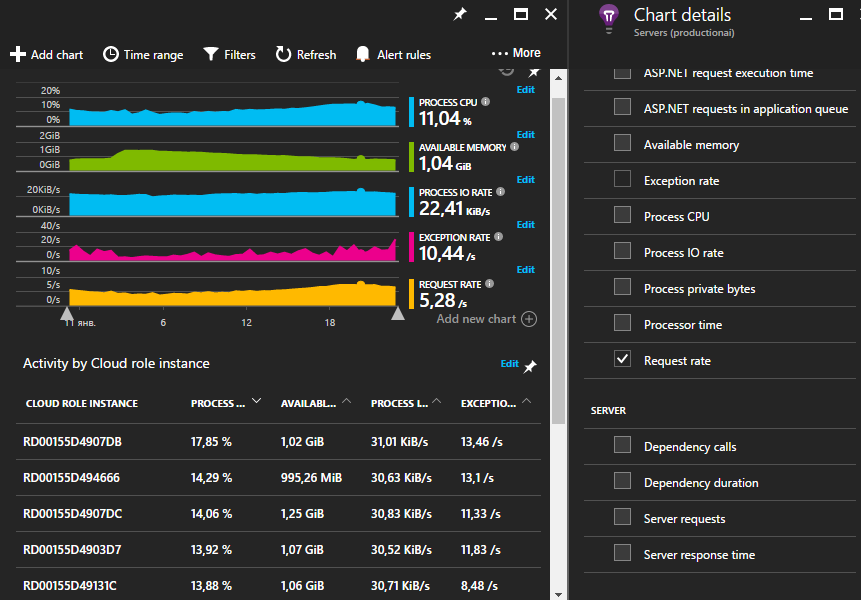
Следующий интересный момент — это «мониторинг зависимостей». AI отслеживает все исходящие внешние HTTP вызовы вашего приложения. Под внешними вызовами или зависимостям понимаются обращения вашего приложения к базе данных и другим third party сервисам. Если ваше приложение представляет собой сервис, хостящийся в инфраструктуре IIS, то AI будет перехватывать телеметрию по всем запросам к вашим сервисам, включая все внешние запросы (благодаря пробросу дополнительной диагностической информации через CallContext потока). То есть благодаря этому вы сможете найти интересующий вас запрос, а также посмотреть все его зависимости. Application Map позволяет вам посмотреть полную карту по внешним зависимостям вашего приложения.
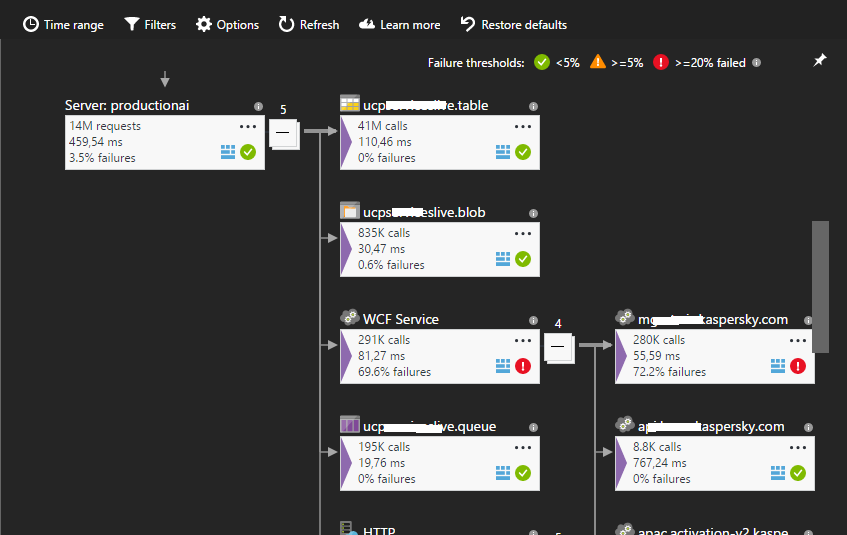
Если в вашей системе имеют место явные проблемы с внешними сервисами, то теоретически эта картинка способна дать вам некоторую информацию о проблеме.
Вы можете погрузиться глубже для более детального изучения информации по внешним запросам
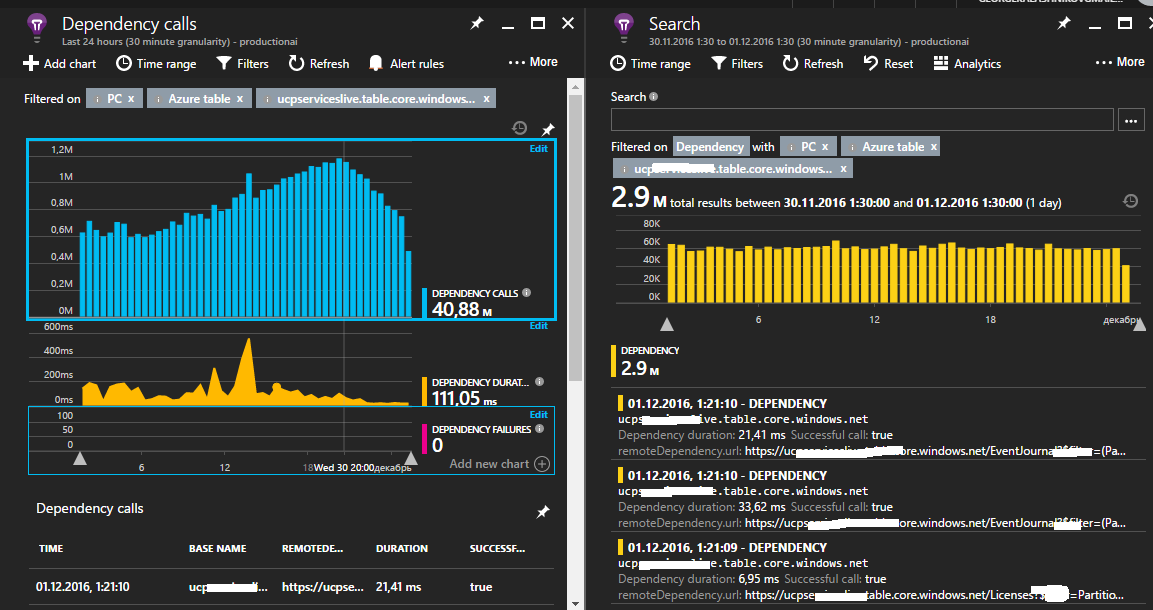
Вне зависимости от платформы вы можете подключить к вашему приложению расширяемое Application Insights API, которое позволит вам сохранять произвольную телеметрию. Это могут быть логи или какие-нибудь кастомные счетчики производительности.
Например, мы пишем в AI агрегированную информацию по всем основным методам наших сервисов, такую как количество вызовов, процент ошибок и время выполнения операций. Кроме этого мы сохраняем информацию по критически важным областям приложения, таким как производительность и доступность внешних сервисов, размеры очередей сообщений (Azure Queue, ServiceBus), пропускную способность их обработки и т.п.
Мониторинг зависимостей, о котором я писал ранее, довольно мощный инструмент, но на текущий момент он способен автоматически перехватывать только все исходящие HTTP запросы, поэтому мы вынуждены самостоятельность писать телеметрию по зависимостям, которые вызывались через другой транспорт. В нашем случае это Azure ServiceBus и RMQ, которые работают по кастомным протоколам.
Телеметрия, которую вы собираете не обязательно должна иметь плоскую структуру (counterName-counterValue). Она может содержать многоуровневую структуру с различной вложенностью. Это достигается за счет использование динамического типа данных.
{
"metric": [ ],
"context": {
...
"custom": {
"dimensions": [
{ "ProcessId": "4068" }
],
"metrics": [
{
"dispatchRate": {
"value": 0.001295,
"count": 1.0,
"min": 0.001295,
"max": 0.001295,
"stdDev": 0.0,
"sampledValue": 0.001295,
"sum": 0.001295
}
},
"durationMetric": {
"name": "contoso.org",
"type": "Aggregation",
"value": 468.71603053650279,
"count": 1.0,
"min": 468.71603053650279,
"max": 468.71603053650279,
"stdDev": 0.0,
"sampledValue": 468.71603053650279
}
} ] }
}
AI позволял писать подобную сложную телеметрию и год назад, но ее практически нельзя было использовать, т.к. в то время графики можно было строились только по простым метрикам. Единственным вариантом использования этой телеметрии были кастомные запросы, которые могли оценивать только частоту возникновения. Теперь же появился очень мощный инструмент Analytics.
Данный инструмент позволяет вам писать различные запросы к вашей телеметрии, обращаясь c помощью специального (SQL-подобного) языка к свойствам произвольных событий.
Для примера синтаксиса, можно посмотреть на запрос, который выводит 10 любых успешных запросов к вашему веб приложения за последние 10 минут:
requests | where success == "True" and timestapm > ago(10m) | take 10В комплекте данного языка имеется множество готовых операторов для анализа (агрегатные функции и соединения, поиск перцентилей, медиан, построение отчетов и т.п.) и визуализации телеметрии в виде графиков.
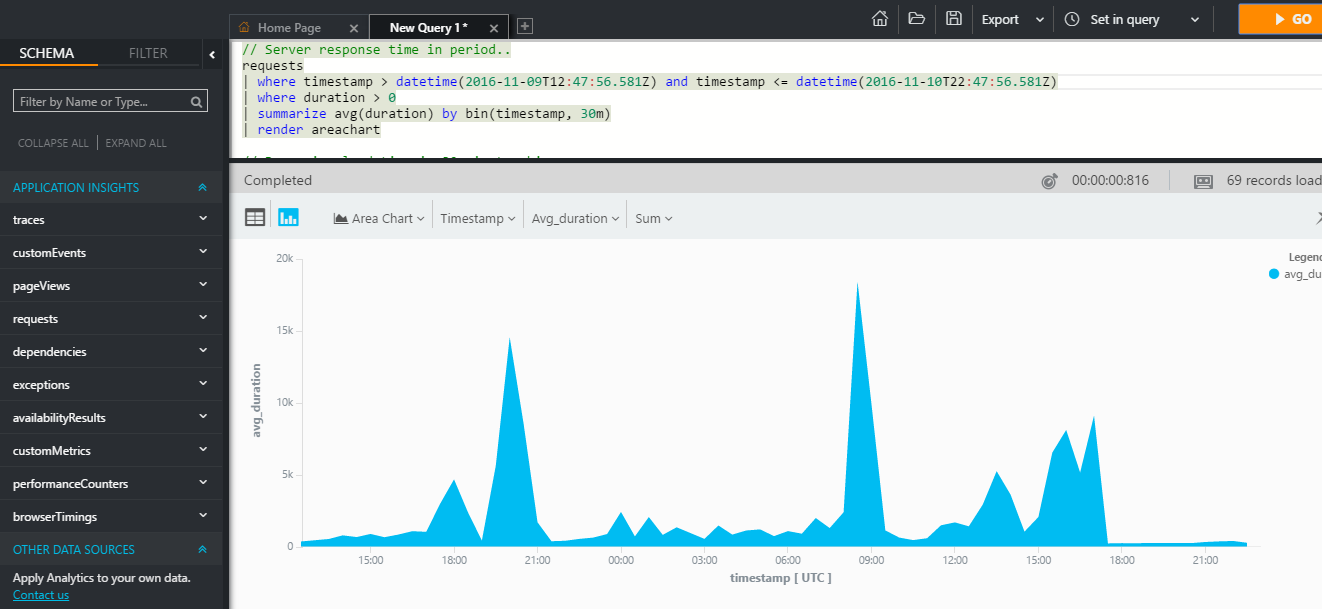

Подобная информация может быть использована как для анализа производительности, так и для получения аналитики при решении некоторых бизнес-задач. Например, если вы разрабатываете некоторый онлайн-магазин, использование аналитики AI, практически из коробки, может дать вам представление о предпочтениях клиентов в зависимости от их географического расположения.
В состав AI входит компонент ProactiveDetection, который на основе алгоритмов машинного обучения способен определять аномалии в собираемой телеметрии. Например, количество запросов к вашим сервисам резко возросло или упало, увеличилось количество ошибок или суммарная длительность некоторых операций.
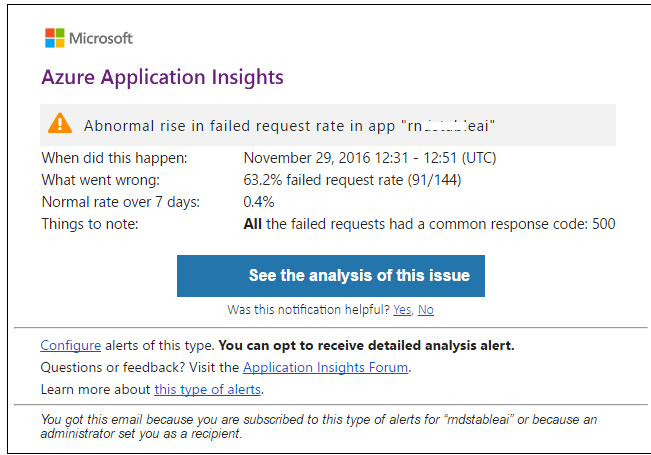
Вы также можете настроить алерты на нужные вам счетчики телеметрии.
AI сохраняет телеметрию в течении 30 дней. Если вам этого недостаточно, то вы можете воспользоваться функцией Continues Export, которая позволит вам экспортировать телеметрию в Azure Blobs. Использование Azure Stream Analytics при поиске в экспортируемой телеметрии интересующих вас закономерностей является хорошей практикой.
Power BI мощный инструмент для визуализации и анализа данных. Вы можете подключить к нему специальный Application Insights Power BI adapter и автоматически переправлять некоторую диагностику в Power BI. Для этого достаточно построить в Analytics нужный запрос и нажать кнопку экспорта. В результате этого вы получите небольшой M-скрипт, который будет использоваться в качестве источника данных AI.
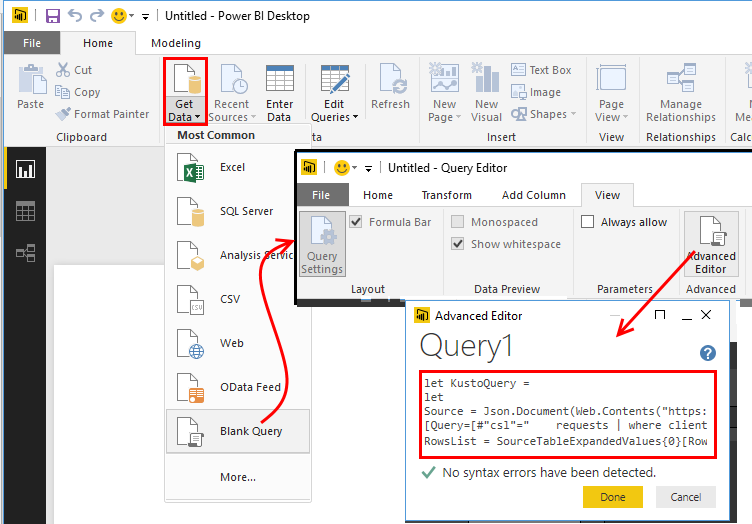

Иногда удобно понаблюдать в реальном времени за здоровьем системы. Особенно это актуально после установки обновлений. Совсем недавно в AI появился инструмент Live Metrics Stream, который дает такую возможность.

AI может также выступать и в качестве сервиса мониторинга. Вы можете импортировать тесты из Visual Studio, проверяющие работоспособность вашего приложения. Либо вы можете прямо из портала AI создать набор проверок для геораспределенной валидации доступности интересующих вас конечных точек. AI будет выполнять проверки по расписанию и выводить результаты на соответствующий график.
Существует также специальный плагин, который позволяет отображать телеметрию c отлаживаемого в дабеге приложения прямо в Visual Studio.
Это далеко не все инструменты. Рекомендуется также использовать AI и для анализа пользовательской телеметрии.
На текущий момент AI тарифицируется по количеству так называемых точек сохранения. Миллион которых стоит около 100 р. Одна точка сохранения соответствует одному диагностическому событию. Т.к. сам AI клиент не агрегирует телеметрию, то целесообразно приложению самому заботиться об агрегации.
Этой рекомендацией стоит руководствоваться и исходя из того, что троттлинг AI не даст вам сохранять более 300 диагностических событий в секунду. С зависимостями все сложнее.
Например, в наших сервисах БД вызывается примерно 10 тысяч раз в секунду. AI же сохраняет общий rate запросов, но детальная информация (длительность, URL, код возврата и т.п.) сохранится только по нескольким сотням запросов, данные по остальным запросам теряются. Несмотря на это, нам пока хватает данных для локализации возникающих проблем.
Благодаря Analytics и другим новым функциям, AI уже сейчас помог определить несколько серьезных проблем производительности наших сервисов.
Продолжаем следить за дальнейшим развитием данного инструмента.
