Apache Spark… Это База
Spark можно определить как вычислительный движок с открытым исходным кодом, функциональный подход к параллельной обработке данных на компьютерных кластерах, а также как набор библиотек и выполняемых файлов.
Apache Spark is a unified computing engine and a set of libraries for parallel data processing on computer clusters.
Spark: The Definitive Guide

AI Generated*Data Engineer using Apache Spark
Spark создан для того, чтобы решать широкий круг задач по анализу данных, начиная с загрузки данных и SQL-запросов и заканчивая машинным обучением и потоковой обработкой данных. На данный момент Spark считается одним из самых активно развивающихся и используемых средств с открытым кодом. Для понимания работы со Spark, рассмотрим его составные части.
Экосистема
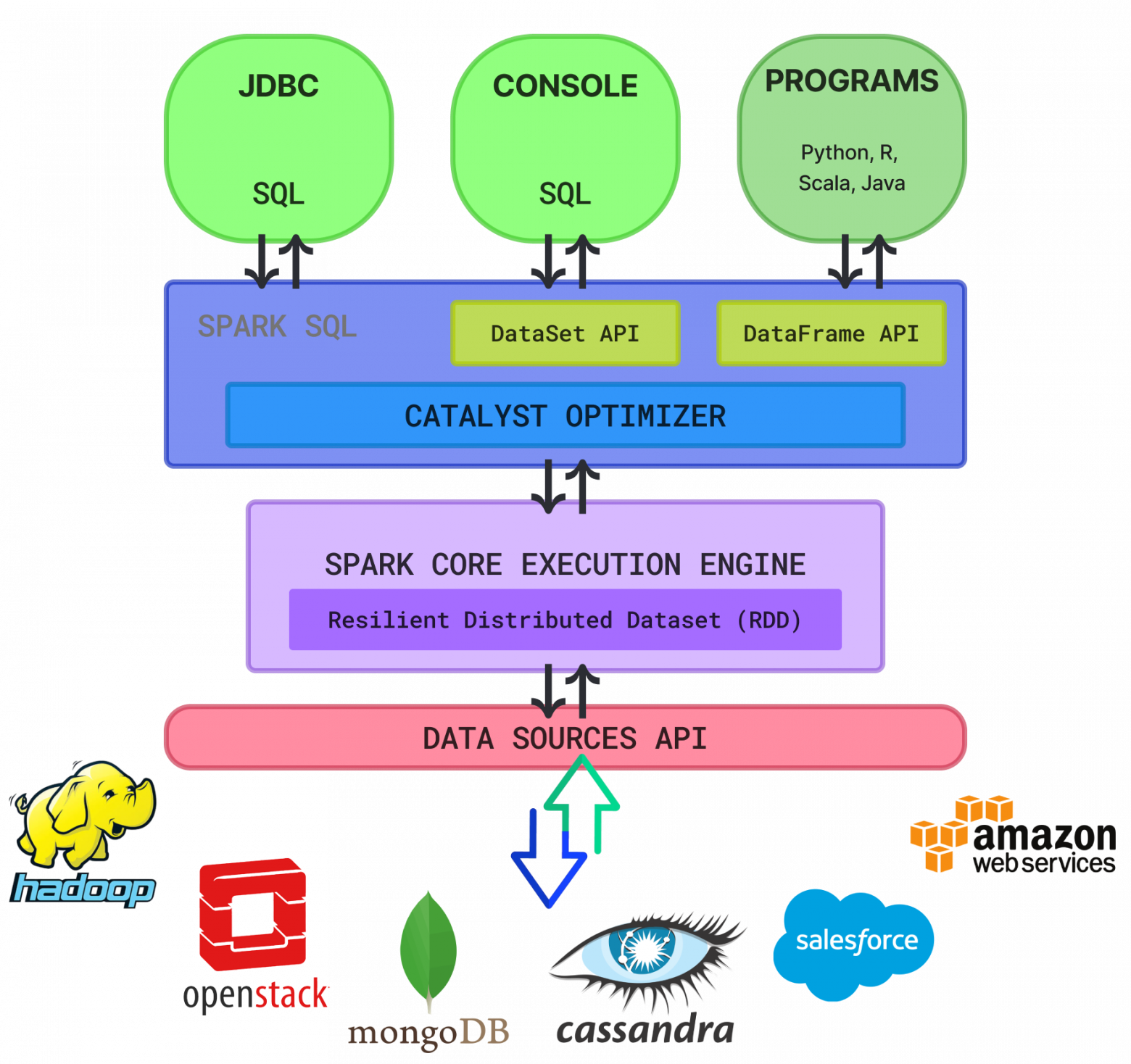
Экосистема Spark. Not AI generated
I часть. Поддержка языков программирования
Spark можно интегрировать с различными языками программирования для аналитических задач, среди которых: Java, Python, Scala и язык R.
II часть. Компоненты
Spark содержит 5 основных компонентов. Это Spark Core, Spark SQL, Spark Streaming, Spark MLlib и GraphX.
1. Spark Core включает функции управления памятью, а также восстановлению в случае аварий, планирования задач в кластере и взаимодействие с хранилищем.
2. Spark SQL — механизм запросов SQL, который поддерживает различные источники данных и использует такую структуру данных, как DataFrame.
3. Spark Streaming — обработка потоковых данных в режиме реального времени.
4. MLlib — библиотека для машинного обучения.
5. GraphX — библиотека для работы с графами.
III Часть экосистемы — Cluster Management, которым могут быть Standalone cluster, Apache Mesos и YARN.
Что касается Catalyst Optimizer, то ввиду того что Spark SQL — это наиболее частый и удобный в использовании компонент Spark, который поддерживает как SQL-запросы, так и DataFrame API, оптимизатор Catalyst использует расширенные функции языка программирования для построения более оптимальных запросов. Он позволяет добавлять новые методы и функций оптимизации, предоставляет возможности расширять функционал оптимизатора. При этом Catalyst Optimizer используется в том числе и для увеличения скорости выполнения задач, а также с целью оптимизации использования ресурсов.
Вычисления
В процесс вычислений вовлечены несколько основных его частей
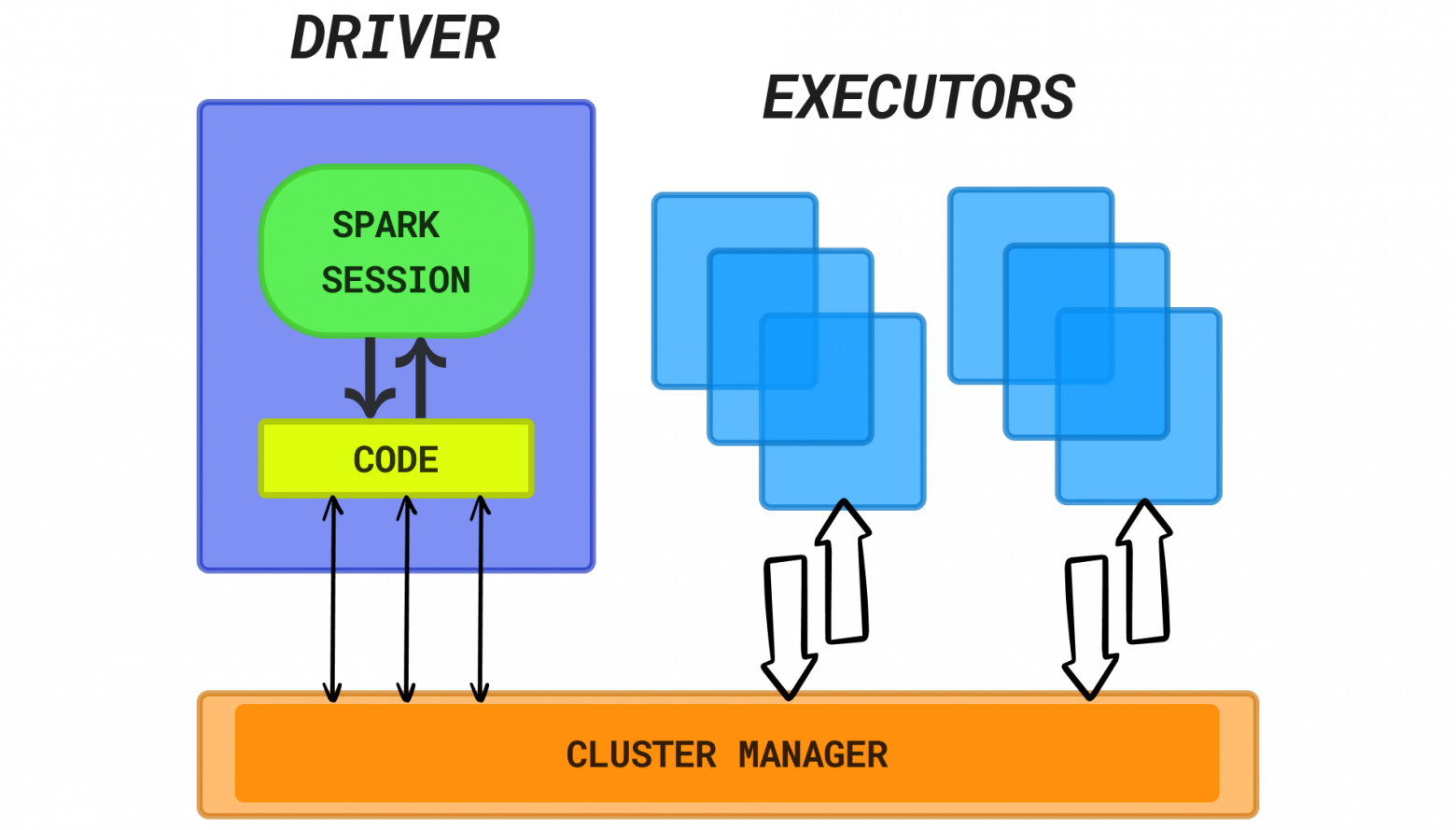
Архитектура взаимодействия. Not AI generated
DRIVER: исполнитель программы
EXECUTOR: выполняет вычисления
CLUSTER MANAGER: занимается управлением реальными машинами кластера и контролирует выделение ресурсов для Spark-приложений
Структуры данных
Хронология появления структур данных по версиям Spark
RDD — начиная с Spark 0 (Low level API)
Resilient Distributed Dataset — это определенный набор объектов, разбитых на блоки partitions. RDD может быть представлен как в виде структурированных наборов данных так и неструктурированных. Partitions могут храниться на разных узлах кластера. RDD отказоустойчивы и могут быть восстановлены в случае сбоя.
DataFrame — начиная с Spark 1.3 (Structured API)
это набор типизированных записей, разбитых на блоки. Иными словами — таблица, состоящая из строк и столбцов. Блоки могут обрабатываться на разных нодах кластера. DataFrame может быть представлен только в виде структурированных или полуструктурированных данных. Данные представлены именованным набором столбцов, напоминая таблицы в реляционных БД.
DataSet — начиная с Spark 1.6 (Structured API)
Рассмотрим поведение указанных структур данных в контексте Immutability (неизменяемости) и Interoperability (совместимости)**:
RDD состоит из набора данных, которые могут быть разбиты на блоки. Блоком, или партицией, можно считать цельную логическую неизменяемую часть данных, создать которую можно в том числе посредством преобразования (transformations) уже существующих блоков.
DataFrame можно создать из RDD. После подобного transformation вернуться к RDD уже не получится. То есть исходный RDD не подлежит восстановлению после трансформации в DataFrame.
DataSet: функционал Spark позволяет преобразовывать как RDD так и DataFrame в сам DataSet.
Источники для структур данных
Data Sources API
RDD — Data source API позволяет RDD формироваться из любых источников включая текстовые файлы, при этом необязательно даже структурированных.
DataFrame — Data source API позволяет обрабатывать разные форматы файлов (AVRO, CSV, JSON, а также из систем хранения HDFS, HIVE** таблиц, MySQL).
DataSet — Dataset API также поддерживает различные форматы данных.
Spark DataFrame может быть создан из различных источников:

Источники DF. Not AI generated
Примеры формирования Spark DataFrame:
#из файла: from pyspark.sql.types import StructType,StringType, StructField, IntegerType
fields=[ StructField("col1", IntegerType()), StructField("col2", StringType())]
schema1 = StructType(fields)
from_file_df = spark.read.csv("/directory/your_file_name", schema=schema1, sep=";", header=True.)
#для просмотра вызовем show (): from_file_df.show()
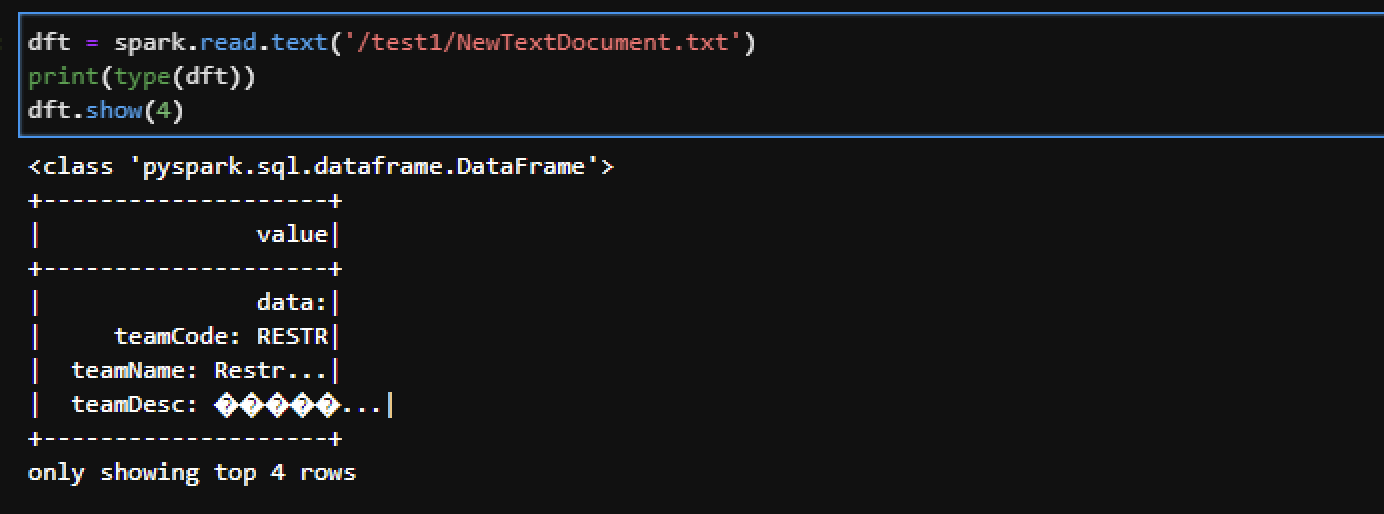
DataFrame из txt. Not AI Generated
Для json файлов желательно заранее определить схему, чтобы избежать ошибок:

DataFrame из json. Not AI Generated
Для csv файлов рекомендовано при определении DataFrame учитывать заголовки и разделители:

DataFrame из csv. Not AI Generated
#из таблицы HDFS — 2 варианта:
#Pysparkpyspark_df = spark.table("schema_name.table_name")#SQL quierysql_statement = "””SELECT * FROM schema_name.table_name”””
sql_df = spark.sql(sql_statement)
#Из Pandas DF: from_pandas_df = spark.createDataFrame(DF_Pandas)#Напрямую из RDD:
from_rdd_df = spark.createDataFrame(rdd)
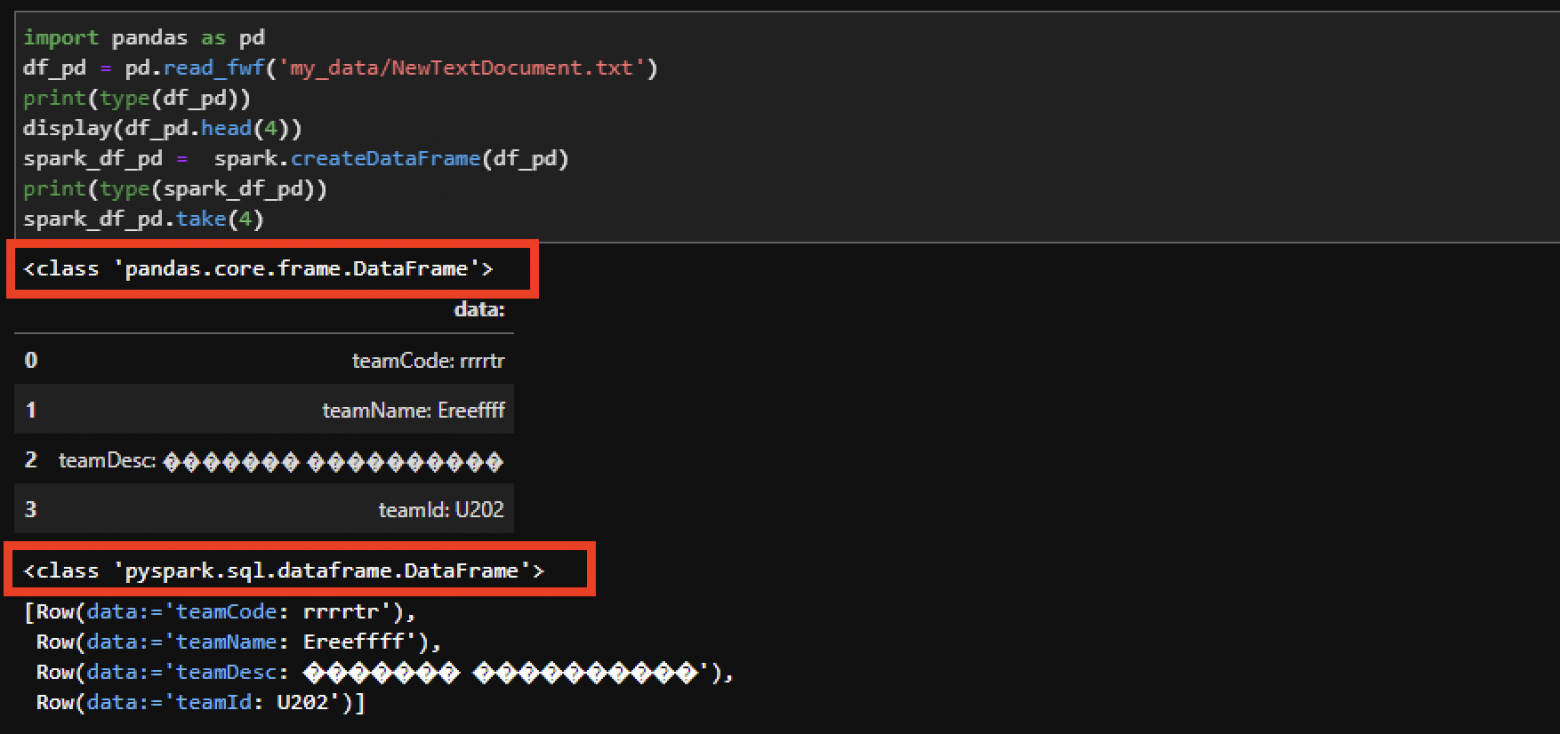
Spark DataFrame из Pandas DataFrame. Not AI Generated
Spark DataFrame обладает похожим с Pandas функционалом, таким как select (выбор колонок), filter (фильтрация), sort (сортировка), WithColumn (новые столбцы), merge (join таблиц) и прочие. Spark отчасти похож на концепт библиотеки Pandas в Python.
Lazy evaluation
Отложенные (ленивые) вычисления реализуются с RDD, DataFrame и DataSet похожим образом — в результате выполнения действия (вычисление, возвращающее результат, подразумевающий обмен данных между executors и driver). При работе с RDD результат вычисляется не в момент определения — вместо этого формируется структурная последовательность преобразований, которая была реализована над начальным RDD. При этом само преобразование будет реализовано когда необходимо отобразить или передать итог преобразований. В DataFrame и DataSet вычисления происходят похожим образом: в момент, когда требуется некое действие над ним (show (), count (), collect (), saveAs () и т.п.).

AI generated lazy evaluation
Параметры конфигурации spark сессии
Для запуска Spark сессии достаточно выполнить:
spark1 = SparkSession.builder.master("local").appName("
Настройка сессий может быть выполнена на этапе ее запуска с помощью параметров. Рассмотрим некоторые из основных****:
Параметр | Default | Описание |
|---|---|---|
spark.app.name | (none) | Имя приложения. Оно отображается в UI и логах. |
spark.driver.cores | 1 | Количество ядер для использования драйвером (для cluster mode). |
spark.driver.maxResultSize | 1g | Ограничение общего размера сериализованных результатов всех партиций для каждого Spark действия (напр. collect) в байтах. |
spark.driver.memory | 1g | Количество памяти для выполнения процессов драйвера. |
spark.executor.memory | 1g | Количество памяти для выполнения процессов executor. |
spark.executor.pyspark.memory | Not set | Количество памяти, выделенное PySpark для каждого executor. Если данный параметр указан, тогда PySpark память для executor будет ограничена указанным значением, если параметр не указан — Spark не будет ограничивать память. |
Предложенные параметры можно комбинировать с собой для оптимального выделения памяти, ускорения и сокращения промежуточных вычислений.

AI Generated Data Engineer. Понять бы где лицо…
*AI pictures Generator
**Apache Spark RDD vs DataFrame vs DataSet
***Hive Tutorial for Beginners
****Application Properties
