Apache Kafka – мой конспект
Это мой конспект, в котором коротко и по сути затрону такие понятия Kafka как:
— Тема (Topic)
— Подписчики (consumer)
— Издатель (producer)
— Группа (group), раздел (partition)
— Потоки (streams)
Kafka — основное
При изучении Kafka возникали вопросы, ответы на которые мне приходилось эксперементально получать на примерах, вот это и изложено в этом конспекте. Как стартовать и с чего начать я дам одну из ссылок ниже в материалах.
Apache Kafka — диспетчер сообщений на Java платформе. В Kafka есть тема сообщения в которую издатели пишут сообщения и есть подписчики в темах, которые читают эти сообщения, все сообщения в процессе диспетчеризации пишутся на диск и не зависит от потребителей.
В состав Kafka входят набор утилит по созданию тем, разделов, готовые издатели, подписчики для примеров и др. Для работы Kafka необходим координатор «ZooKeeper», поэтому вначале стартуем ZooKeeper (zkServer.cmd) затем сервер Kafka (kafka-server-start.bat), командные файлы находятся в соответствующих папках bin, там же и утилиты.
Создадим тему Kafka утилитой, ходящей в состав
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic out-topic
здесь указываем сервер zookeeper, replication-factor это количество реплик журнала сообщений, partitions — количество разделов в теме (об этом ниже) и собственно сама тема — «out-topic».
Для простого тестирования можно использовать входящие в состав готовые приложения «kafka-console-consumer» и «kafka-console-producer», но я сделаю свои. Подписчики на практике объединяют в группы, это позволит разным приложениям читать сообщения из темы параллельно.
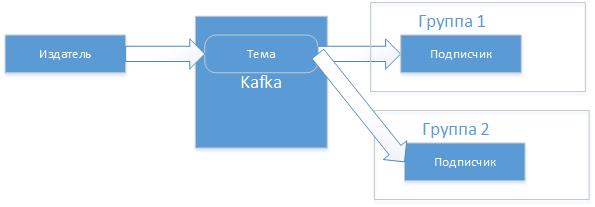
Для каждого приложения будет организованна своя очередь, читая из которой оно выполняет перемещения указателя последнего прочитанного сообщения (offset), это называется фиксацией (commit) чтения. И так если издатель отправит сообщение в тему, то оно будет гарантированно прочитано получателем этой темы если он запущен или, как только он подключится. Причем если есть разные клиенты (client.id), которые читают из одной темы, но в разных группах, то сообщения они получат не зависимо друг от друга и в то время, когда будут готовы.
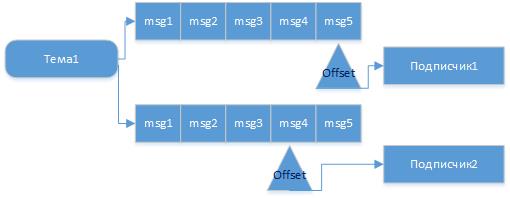
Так можно представить последователь сообщений и независимое чтение их потребителями из одной темы.
Но есть ситуация, когда сообщения в тему могут начать поступать быстрее чем уходить, т.е. потребители обрабатывают их дольше. Для этого в теме можно предусмотреть разделы (partitions) и запускать потребителей в одной группе для этой темы.
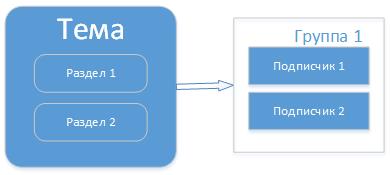
Тогда произойдет распределение нагрузки и не все сообщения в теме и группе пойдут через одного потребителя. И тогда уже будет выбрана стратегия, как распределять сообщения по разделам. Есть несколько стратегий: round-robin — это по кругу, по хэш значению ключа, или явное указание номера раздела куда писать. Подписчики в этом случае распределяются равномерно по разделам. Если, например, подписчиков будет в группе будет больше чем разделов, то кто-то не получит сообщения. Таким образом разделы делаются для улучшения масштабируемости.
Например после создания темы с одним разделом я изменил на два раздела.
kafka-topics.bat --zookeeper localhost:2181 --alter --topic out-topic --partitions 2
Запустил своего издателя и двух подписчиков в одной группе на одну тему (примеры java программ будут ниже). Конфигурировать имена групп и ИД клиентов не надо, Kafka берет это на себя.
my_kafka_run.cmd com.home.SimpleProducer out-topic (издатель)
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01 (первый подписчик)
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client02 (второй подписчик)
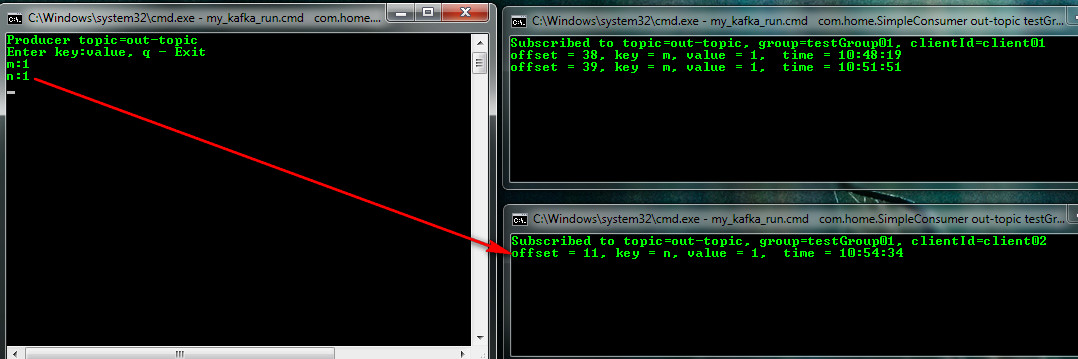
Начав вводить в издателе пары ключ: значение можно наблюдать кто их получает. Так, например, по стратегии распределения по хэшу ключа сообщение m:1 попало клиенту client01
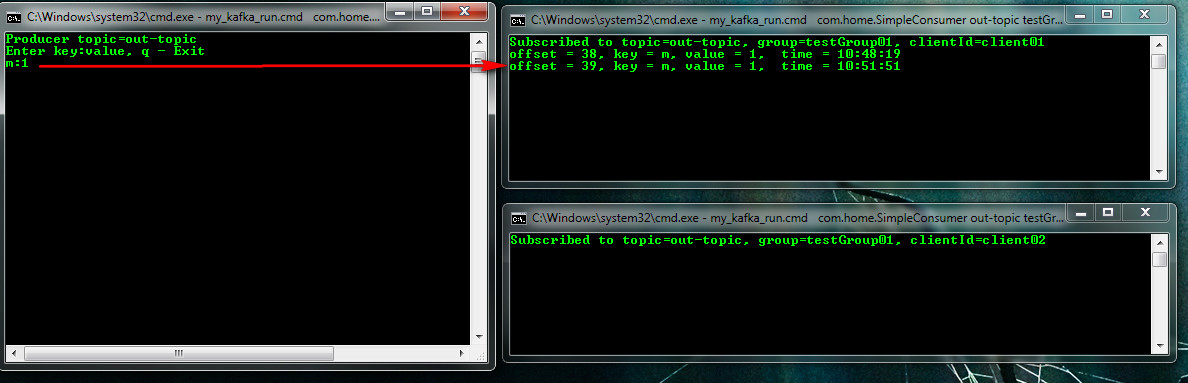
а сообщение n:1 клиенту client02
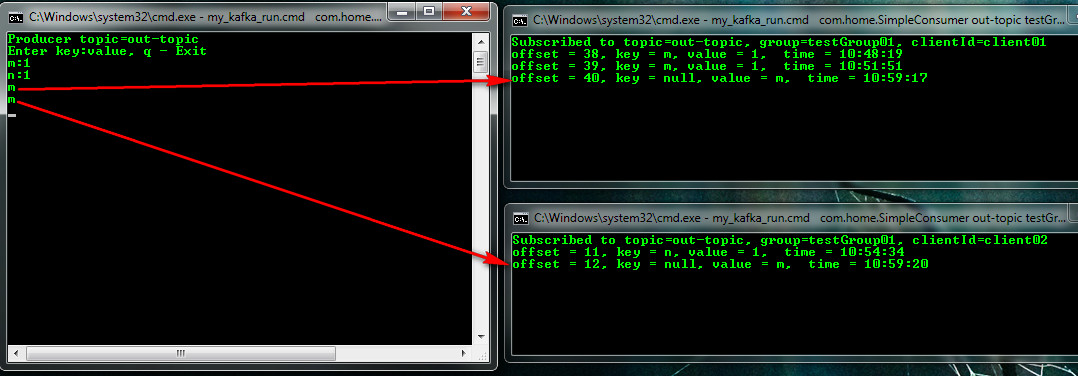
Если начну вводить без указания пар ключ: значение (такую возможность сделал в издателе), будет выбрана стратегия по кругу. Первое сообщение «m» попало client01, а уже втрое client02.
И еще вариант с указанием раздела, например в таком формате key: value: partition
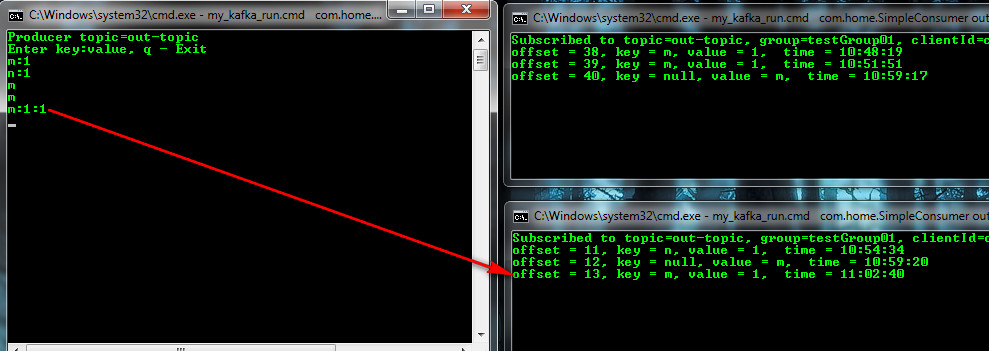
Ранее в стратегии по хэш, m:1 уходил другому клиенту (client01), теперь при явном указании раздела (№1, нумеруются с 0) — к client02.
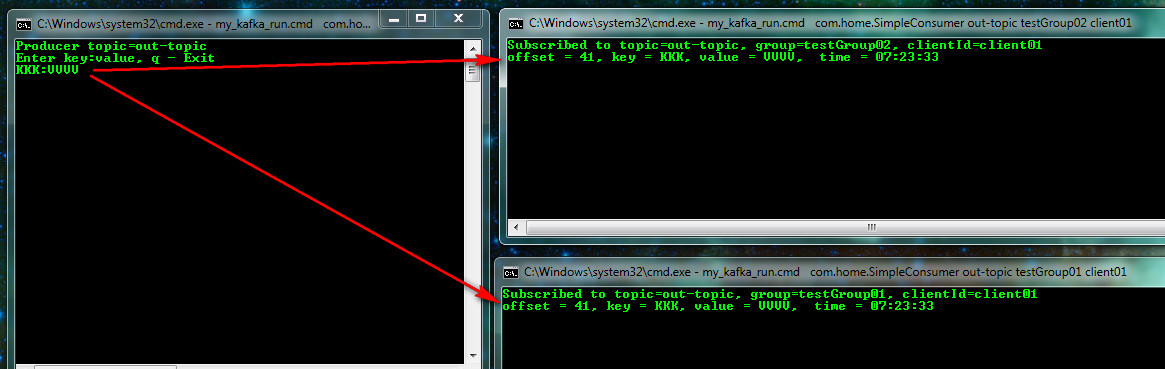
Если запустить подписчика с другим именем группы testGroup02 и для той же темы, то сообщения будут уходить параллельно и независимо подписчикам, т.е. если первый прочитал, а второй не был активен, то он прочитает, как только станет активен.
Можно посмотреть описания групп, темы соответственно:
kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --group testGroup01

kafka-topics.bat --describe --zookeeper localhost:2181 --topic out-topic

public class SimpleProducer {
public static void main(String[] args) throws Exception {
// Check arguments length value
if (args.length == 0) {
System.out.println("Enter topic name");
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
System.out.println("Producer topic=" + topicName);
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", "all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer(props);
BufferedReader br = null;
br = new BufferedReader(new InputStreamReader(System.in));
System.out.println("Enter key:value, q - Exit");
while (true) {
String input = br.readLine();
String[] split = input.split(":");
if ("q".equals(input)) {
producer.close();
System.out.println("Exit!");
System.exit(0);
} else {
switch (split.length) {
case 1:
// strategy by round
producer.send(new ProducerRecord(topicName, split[0]));
break;
case 2:
// strategy by hash
producer.send(new ProducerRecord(topicName, split[0], split[1]));
break;
case 3:
// strategy by partition
producer.send(new ProducerRecord(topicName, Integer.valueOf(split[2]), split[0], split[1]));
break;
default:
System.out.println("Enter key:value, q - Exit");
}
}
}
}
}
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.out.println("Enter topic name, groupId, clientId");
return;
}
//Kafka consumer configuration settings
final String topicName = args[0].toString();
final String groupId = args[1].toString();
final String clientId = args[2].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", groupId);
props.put("client.id", clientId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName));
//print the topic name
System.out.println("Subscribed to topic=" + topicName + ", group=" + groupId + ", clientId=" + clientId);
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
// looping until ctrl-c
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s, time = %s \n",
record.offset(), record.key(), record.value(), sdf.format(new Date()));
}
}
}
Для запуска своих программ я сделал командный файл — my_kafka_run.cmd
@echo off
set CLASSPATH="C:\Project\myKafka\target\classes";
for %%i in (C:\kafka_2.11-1.1.0\libs\*) do (
call :concat "%%i"
)
set COMMAND=java -classpath %CLASSPATH% %*
%COMMAND%
:concat
IF not defined CLASSPATH (
set CLASSPATH="%~1"
) ELSE (
set CLASSPATH=%CLASSPATH%;"%~1"
)
пример запуска:
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup02 client01
Kafka Streams
Итак, потоки в Kafka это последовательность событий, которые получают из темы, над которой можно выполнять определенные операции, трансформации и затем результат отдать далее, например, в другую тему или сохранить в БД, в общем куда угодно. Операции могут быть как например фильтрации (filter), преобразования (map), так и агрегации (count, sum, avg). Для этого есть соответствующие классы KStream, KTable, где KTable можно представить как таблицу с текущими агрегированными значениями которые постоянно обновляются по мере поступления новых сообщений в тему. Как это происходит?

Например, издатель пишет в тему события (сообщения), Kafka все сообщения сохраняет в журнале сообщений, который имеет политику хранения (Retention Policy), например 7 дней. Например события изменения котировки это поток, далее хотим узнать среднее значение, тогда создадим Stream который возьмет историю из журнала и посчитает среднее, где ключом будет акция, а значением — среднее (это уже таблица с состоянием). Тут есть особенность — операции агрегирования в отличии от операций, например, фильтрации, сохраняют состояние. Поэтому вновь поступающие сообщения (события) в тему, будут подвержены вычислению, а результат будет сохраняться (state store), далее вновь поступающие будут писаться в журнал, Stream их будет обрабатывать, добавлять изменения к уже сохраненному состоянию. Операции фильтрации не требуют сохранения состояния. И тут тоже stream будет делать это не зависимо от издателя. Например, издатель пишет сообщения, а программа — stream в это время не работает, ничего не пропадет, все сообщения будут сохранены в журнале и как только программа-stream станет активной, она сделает вычисления, сохранит состояние, выполнит смещение для прочитанных сообщений (пометит что они прочитаны) и в дальнейшем она уже к ним не вернется, более того эти сообщения уйдут из журнала (kafka-logs). Тут видимо главное, чтобы журнал (kafka-logs) и его политика хранения позволило это. По умолчанию состояние Kafka Stream хранит в RocksDB. Журнал сообщений и все с ним связанное (темы, смещения, потоки, клиенты и др.) располагается по пути указанном в параметре «log.dirs=kafka-logs» файла конфигурации «config\server.properties», там же указывается политика хранения журнала «log.retention.hours=48». Пример лога
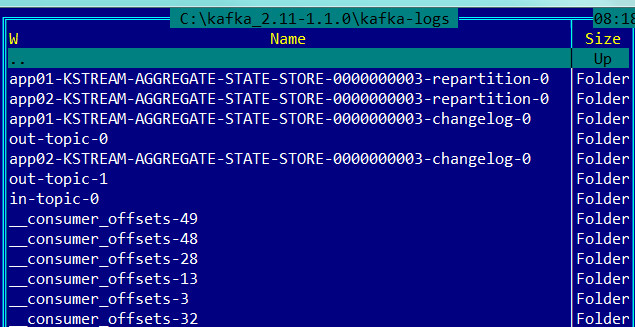
А путь к базе с состояниями stream указывается в параметре приложения
config.put (StreamsConfig.STATE_DIR_CONFIG, «C:/kafka_2.11–1.1.0/state»);
Состояния хранятся по ИД приложениям независимо (StreamsConfig.APPLICATION_ID_CONFIG). Пример

Проверим теперь как работает Stream. Подготовим приложение Stream из примера, который есть поставке (с некоторой доработкой для эксперимента), которое считает количество одинаковых слов и приложение издатель и подписчик. Писать будет в тему in-topic
my_kafka_run.cmd com.home.SimpleProducer in-topic
Приложение Stream будет читать эту тему считать кол-во одинаковых слов, не явно для нас сохранять состояние и перенаправлять в другую тему out-topic. Тут я хочу прояснить связь журнала и состояния (state store). И так ZooKeeper и сервер Kafka запущены. Запускаю Stream с App-ID = app_01
my_kafka_run.cmd com.home.KafkaCountStream in-topic app_01
издатель и подписчик соответственно
my_kafka_run.cmd com.home.SimpleProducer in-topic
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01
Вот они:

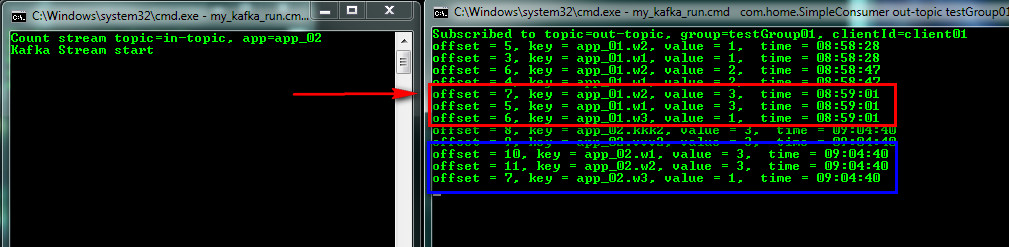
Начинаем вводить слова и видим их подсчет с указанием какой Stream App-ID их подсчитал

Работа будет идти независимо, можно остановить Stream и продолжать писать в тему, он потом при старте посчитает. А теперь подключим второй Stream c App-ID = app_02 (это тоже приложение, но с другим ИД), он прочитает журнал (последовательность событий, которая сохраняется согласно политике Retention), подсчитает кол-во, сохранит состояние и выдаст результат. Таким образом два потока начав работать в разное время пришли к одному результату.
А теперь представим наш журнал устарел (Retention политика) или мы его удалили (что бывает надо делать) и подключаем третий stream с App-ID = app_03 (я для этого остановил Kafka, удалил kafka-logs и вновь стартовал) и вводим в тему новое сообщение и видим первый (app_01) поток продолжил подсчет, а новый третий начал с нуля.
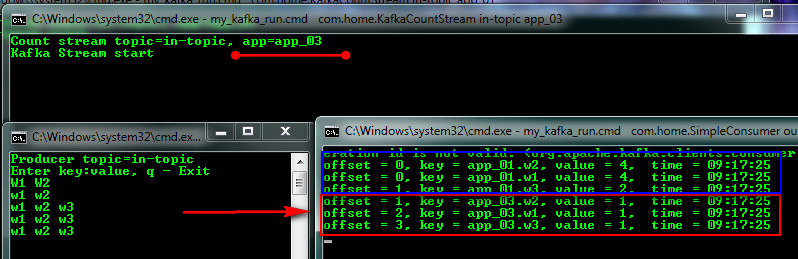
Если затем запустим поток app_02, то он догонит первый и они будут равны в значениях. Из примера стало понятно, как Kafka обрабатывает текущий журнал, добавляет к ранее сохраненному состоянию и так далее.
Тема Kafka очень обширна, я для себя сделал первое общее представление:-)
Материалы:
Как стартовать и с чего начать
